¶ 1 Конфигурирование RT.DataVision
¶ 1.1 Файл конфигурации
Чтобы настроить приложение, создайте файл superset_config.py. Добавьте этот файл в PYTHONPATH или создайте переменную среды SUPERSET_CONFIG_PATH, указав полный путь к файлу superset_config.py.
Например, при развёртывании RT.DataVision непосредственно в системе на базе Linux, где файл superset_config.py находится в каталоге /app, вы можете запустить:
export SUPERSET_CONFIG_PATH=/app/superset_config.pyЕсли вы используете собственный Dockerfile с официальным образом RT.DataVision в качестве базового образа, вы можете добавить свои переопределения, как показано ниже:
COPY --chown=superset superset_config.py /app/
ENV SUPERSET_CONFIG_PATH /app/superset_config.pyРазвёртывания docker-compose по-разному обрабатывают конфигурацию приложения. Подробности см. здесь.
Ниже приведены некоторые параметры, которые вы можете установить в файле superset_config.py:
# Конфигурация для конкретного RT.DataVision
ROW_LIMIT = 5000
# Конфигурация Flask App Builder
# Секретный ключ приложения будет использоваться для безопасной подписи cookie сессии и шифрования чувствительных данных в базе данных
# Убедитесь, что вы меняете этот ключ для развёртывания с помощью надёжного ключа
# Альтернативно вы можете установить его с помощью переменной среды `SUPERSET_SECRET_KEY`
# Вам необходимо установить ключ для производственных сред, иначе сервер не запустится, и соответственно в логах вы увидите ошибку
SECRET_KEY = 'рандомно_сгенерированный_надёжный_секретный_ключ'
# Строка подключения SQLAlchemy к базе данных
# Это подключение определяет путь к БД, в которой хранятся метаданных RT.DataVision (графики, подключения, таблицы, дашборды и пр.)
# Обратите внимание, что данными для подключения к источникам данных, которые вы хотите изучить, вы должны управлять непосредственно в UI
# Свойство check_same_thread=false гарантирует, что клиент sqlite не обеспечивает однопоточный доступ, что может привести к проблеме
SQLALCHEMY_DATABASE_URI = 'sqlite:////путь/к/rtdatavision.db?check_same_thread=false'
# Флаг Flask-WTF для CSRF
WTF_CSRF_ENABLED = True
# Добавьте эндпоинты, которые должны быть освобождены от защиты CSRF
WTF_CSRF_EXEMPT_LIST = []
# Токен CSRF, срок действия которого истекает через 1 год
WTF_CSRF_TIME_LIMIT = 60 * 60 * 24 * 365
# Установите ключ API, чтобы включить визуализацию Mapbox
MAPBOX_API_KEY = ''Все параметры и значения по умолчанию, определённые в config.py, можно переопределить в локальном файле superset_config.py. Вы можете изучить файл, чтобы понять, что можно настроить локально, а также какие значения установлены по умолчанию.
Поскольку superset_config.py действует как модуль конфигурации Flask, его можно использовать для изменения настроек самого Flask, а также расширений Flask, таких как flask-wtf, flask-caching, flask-migrate и flask-appbuilder. Веб-фреймворк Flask App Builder, используемый RT.DataVision, предлагает множество настроек конфигурации. Обратитесь к документации Flask App Builder для получения дополнительной информации о том, как его настроить.
Обязательно измените следующие параметры:
- SQLALCHEMY_DATABASE_URI — по умолчанию хранится в ~/.superset/superset.db;
- SECRET_KEY — измените на длинную случайную строку.
Если вам нужно исключить эндпоинты из CSRF (например, если вы используете кастомный эндпоинт обратной передачи аутентификации), вы можете добавить эндпоинты в WTF_CSRF_EXEMPT_LIST:
WTF_CSRF_EXEMPT_LIST = [‘’]¶ 1.2 Определение SECRET_KEY
¶ 1.2.1 Определение инициирующего SECRET_KEY
Для запуска RT.DataVision требуется определённый пользователем SECRET_KEY. Добавьте сильный SECRET_KEY в файл superset_config.py, например:
SECRET_KEY = 'рандомно_сгенерированный_надёжный_секретный_ключ'Вы можете создать надёжный безопасный ключ с помощью openssl rand -base64 42.
¶ 1.2.2 Изменение SECRET_KEY
Если вы хотите изменить существующий SECRET_KEY, выполните следующие действия:
1. Добавьте новые SECRET_KEY и PREVIOUS_SECRET_KEY в superset_config.py:
PREVIOUS_SECRET_KEY = 'текущий_ключ'
SECRET_KEY = 'сгенерированный_надёжный_новый_ключ'Вы можете найти свой текущий SECRET_KEY с помощью этих команд (если RT.DataVision работает с docker, выполните их из контейнера с приложением RT.DataVision):
superset shell
from flask import current_app; print(current_app.config["SECRET_KEY"])2. Сохраните файл superset_config.py с этими значениями.
3. Запустите superset re-encrypt-secrets.
4. Удалите параметр PREVIOUS_SECRET_KEY и его значение из superset_config.py в целях безопасности и сохраните файл.
¶ 1.3 Хранилище метаданных в производственной среде
По умолчанию RT.DataVision настроен на использование SQLite, это простой и быстрый способ начать работу (установка не требуется).
Однако в производственных средах использование SQLite крайне не рекомендуется из соображений безопасности, масштабируемости и целостности данных. Важно использовать только поддерживаемые движки баз данных и рассмотреть возможность использования другого выбранного движка базы данных на отдельном хосте или контейнере.
RT.DataVision поддерживает движки/версии баз данных, перечисленные в таблице ниже.
Таблица “Поддерживаемые движки/версии баз данных”
| Движок базы данных | Поддерживаемые версии |
|---|---|
| PostgreSQL | 10.Х, 11.Х, 12.Х, 13.Х, 14.Х, 15.Х |
| MySQL | 5.7, 8.Х |
Используйте драйверы базы данных и строки подключения, представленные в таблице.
Таблица "Драйверы БД и строки подключения"
| База данных | Пакет PyPI | Строка подключения |
|---|---|---|
| PostgreSQL | pip install psycopg2 | postgresql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
| MySQL | pip install mysqlclient | mysql://<UserName>:<DBPassword>@<Database Host>/<Database Name> |
Чтобы сконфигурировать хранилище метаданных RT.DataVision, задайте для ключа конфигурации SQLALCHEMY_DATABASE_URI в superset_config соответствующую строку подключения.
¶ 1.4 Запуск на HTTP-сервере WSGI
Вы можете запустить RT.DataVision на Nginx или Apache, но рекомендуется использовать Gunicorn в асинхронном режиме. Он обеспечивает эффективный параллелизм и довольно прост в установке и настройке. Обратитесь к документации выбранной вами технологии, чтобы настроить приложение Flask WSGI так, чтобы оно корректно работало в вашей среде. Далее приведена асинхронная настройка, которая успешно работает в производственной среде:
-w 10 \
-k gevent \
--worker-connections 1000 \
--timeout 120 \
-b 0.0.0.0:6666 \
--limit-request-line 0 \
--limit-request-field_size 0 \
--statsd-host localhost:8125 \
"superset.app:create_app()"Обратитесь к документации Gunicorn для получения дополнительной информации. Обратите внимание, что веб-сервер разработки (superset run или flask run) не предназначен для использования в производственной среде.
Если вы не используете Gunicorn, вы можете отключить использование flask-compress, установив COMPRESS_REGISTER = False в superset_config.py.
В настоящее время sdk Python Google BigQuery несовместим с gevent из-за динамических свойств манкипатчинга в основной библиотеке Python со стороны gevent. Итак, когда вы используете BigQuery в качестве источника данных в RT.DataVision с сервером gunicorn, вам необходимо использовать отличный от gevent тип воркера.
¶ 1.5 Конфигурация HTTPS
Вы можете настроить восходящий поток HTTPS через балансировщик нагрузки или обратный прокси-сервер (например, nginx) и выполнить разгрузку SSL\TLS до того, как трафик достигнет приложения RT.DataVision. В этой настройке локальный трафик от воркера Celery, выполняющего снапшот графика для Оповещений и отчётов (Alerts & Reports), может получить доступ к RT.DataVision по URL-адресу http:// из-за точки входа. Вы также можете настроить SSL в Gunicorn (веб-сервере Python), если используете официальный docker-образ RT.DataVision.
¶ 1.6 Конфигурация балансировщика нагрузки
Если вы используете RT.DataVision за балансировщиком нагрузки или обратным прокси-сервером (например, Nginx или ELB на AWS), вам может потребоваться использовать эндпоинт проверки работоспособности, чтобы ваш балансировщик нагрузки знал, работает ли ваш инстанс RT.DataVision. Такая функциональность предоставляется в эндпоинте /health, который вернёт ответ 200, содержащий ОК, если веб-сервер работает.
Если балансировщик нагрузки вставляет заголовки X-Forwarded-For/X-Forwarded-Proto, вам следует установить ENABLE_PROXY_FIX = True в файле конфигурации RT.DataVision (superset_config.py), чтобы извлекать и использовать заголовки.
В случае, если обратный прокси-сервер используется для обеспечения SSL-шифрования, может потребоваться явное определение X-Forwarded-Proto. Для веб-сервера Apache это можно настроить следующим образом:
RequestHeader set X-Forwarded-Proto "https"¶ 1.7 Кастомная конфигурация OAuth2
RT.DataVision построен на Flask-AppBuilder (FAB), который поддерживает множество провайдеров “из коробки” (GitHub, Twitter, LinkedIn, Google, Azure и т.д.). Помимо этого, RT.DataVision можно настроить для соединения с другими имплементациями сервера авторизации OAuth2, которые поддерживают авторизацию с помощью «кода».
Убедитесь, что пакет pip Authlib установлен на веб-сервере.
Сначала сконфигурируйте авторизацию RT.DataVision в superset_config.py:
from flask_appbuilder.security.manager import AUTH_OAUTH
# Установите тип аутентификации на OAuth
AUTH_TYPE = AUTH_OAUTH
OAUTH_PROVIDERS = [
{ 'name':'egaSSO',
'token_key':'access_token', # Имя токена в ответе access_token_url
'icon':'fa-address-card', # Иконка для провайдера
'remote_app': {
'client_id':'myClientId', # Идентификатор клиента (идентификация приложения RT.DataVision)
'client_secret':'MySecret', # Секрет для этого идентификатора клиента (идентификация приложения RT.DataVision)
'client_kwargs':{
'scope': 'read' # Область авторизации
},
'access_token_method':'POST', # Метод HTTP для вызова access_token_url
'access_token_params':{ # Дополнительные параметры для вызовов access_token_url
'client_id':'myClientId'
},
'access_token_headers':{ # Дополнительные заголовки для вызовов access_token_url
'Authorization': 'Basic Base64EncodedClientIdAndSecret'
},
'api_base_url':'https://myAuthorizationServer/oauth2AuthorizationServer/',
'access_token_url':'https://myAuthorizationServer/oauth2AuthorizationServer/token',
'authorize_url':'https://myAuthorizationServer/oauth2AuthorizationServer/authorize'
}
}
]
# Разрешить самостоятельную регистрацию пользователей, что позволит создавать пользователей Flask из авторизованных пользователей
AUTH_USER_REGISTRATION = True
# Роль самостоятельной регистрации пользователя по умолчанию
AUTH_USER_REGISTRATION_ROLE = "Public"Затем создайте CustomSsoSecurityManager, который расширяет SupersetSecurityManager и переопределяет oauth_user_info:
import logging
from superset.security import SupersetSecurityManager
class CustomSsoSecurityManager(SupersetSecurityManager):
def oauth_user_info(self, provider, response=None):
logging.debug("Oauth2 provider: {0}.".format(provider))
if provider == 'egaSSO':
# Например, эта строка запрашивает GET для base_url + '/' + userDetails с Bearer Authentication,
# и ожидает, что сервер авторизации проверит токен и ответит данными пользователя
me = self.appbuilder.sm.oauth_remotes[provider].get('userDetails').data
logging.debug("user_data: {0}".format(me))
return { 'name' : me['name'], 'email' : me['email'], 'id' : me['user_name'], 'username' : me['user_name'], 'first_name':'', 'last_name':''}
...Данный файл должен находиться в том же каталоге, что и superset_config.py, с именем custom_sso_security_manager.py. Далее добавьте следующие 2 строки в superset_config.py:
from custom_sso_security_manager import CustomSsoSecurityManager
CUSTOM_SECURITY_MANAGER = CustomSsoSecurityManagerУчитывайте следующие примечания:
- URL-адрес редиректа будет https://<superset-webserver>/oauth-authorized/<provider-name> при настройке провайдера авторизации OAuth2, если это необходимо. Например, для приведённой выше конфигурации URL-адрес редиректа будет https://<superset-webserver>/oauth-authorized/egaSSO.
- Если сервер авторизации OAuth2 поддерживает OpenID Connect 1.0, вы можете настроить только его URL-адрес документа конфигурации, не указывая api_base_url, access_token_url, authorize_url и другие необходимые параметры, такие как эндпоинт информации о пользователе, jwks uri и т.д. Например:
OAUTH_PROVIDERS = [
{ 'name':'egaSSO',
'token_key':'access_token', # Имя токена в ответе access_token_url
'icon':'fa-address-card', # Иконка для провайдера
'remote_app': {
'client_id':'myClientId', # Идентификатор клиента (идентификация приложения RT.DataVision)
'client_secret':'MySecret', # Секрет для идентификатора клиента (идентификация приложения RT.DataVision)
'server_metadata_url': 'https://myAuthorizationServer/.well-known/openid-configuration'
}
}
]¶ 1.8 LDAP-аутентификация
Flask-AppBuilder (FAB) поддерживает аутентификацию учётных данных пользователя на сервере LDAP.
Чтобы использовать LDAP, вам необходимо установить пакет python-ldap. Обратите внимание, что пакет python-ldap поставляется с RT.DataVision версии ≥ 1.3.1.
Подробности смотрите в документации FAB по LDAP.
¶ 1.9 Маппинг групп LDAP\OAUTH на роли RT.DataVision
AUTH_ROLES_MAPPING в Flask-AppBuilder — это справочник, который осуществляет маппинг имён групп LDAP/OAUTH на роли FAB. Он используется для назначения ролей пользователям, которые проходят аутентификацию с помощью LDAP или OAuth.
¶ 1.9.1 Маппинг групп OAUTH на роли RT.DataVision
Следующий справочник AUTH_ROLES_MAPPING выполняет маппинг группы OAUTH superset_users на роли RT.DataVision Gamma и Alpha, а группу OAUTH superset_admins на роль RT.DataVision Admin:
AUTH_ROLES_MAPPING = { "superset_users": ["Gamma","Alpha"], "superset_admins": ["Admin"], }¶ 1.9.2 Маппинг групп LDAP на роли RT.DataVision
Следующий справочник AUTH_ROLES_MAPPING выполняет маппинг DN LDAP cn=superset_users,ou=groups,dc=example,dc=com на роли RT.DataVision Gamma и Alpha, а также DN LDAP cn=superset_admins,ou=groups,dc=example,dc=com на роль RT.DataVision Admin:
AUTH_ROLES_MAPPING = { "cn=superset_users,ou=groups,dc=example,dc=com": ["Gamma","Alpha"], "cn=superset_admins,ou=groups,dc=example,dc=com": ["Admin"], }
Примечание. Для выполнения маппинга необходимо установить AUTH_LDAP_SEARCH. Для получения более подробной информации обратитесь к документации FAB Security.
¶ 1.9.3 Синхронизация ролей при входе в систему
Вы также можете использовать переменную конфигурации AUTH_ROLES_SYNC_AT_LOGIN, чтобы контролировать, как часто Flask-AppBuilder синхронизирует роли пользователя с группами LDAP/OAUTH. Если для AUTH_ROLES_SYNC_AT_LOGIN установлено значение True, Flask-AppBuilder будет синхронизировать роли пользователя при каждом входе в систему. Если для AUTH_ROLES_SYNC_AT_LOGIN установлено значение False, Flask-AppBuilder будет синхронизировать роли пользователя только при их первой регистрации.
¶ 1.10 Конфигурация hook приложения Flask
FLASK_APP_MUTATOR — это функция конфигурации, которая может быть предоставлена в вашей среде, получает объект приложения и может изменять его любым способом. Например, добавьте FLASK_APP_MUTATOR в свой superset_config.py, чтобы установить срок действия cookie-файла сессии на 24 часа:
from flask import session
from flask import Flask
def make_session_permanent():
'''
Enable maxAge for the cookie 'session'
'''
session.permanent = True
# Установите максимальный срок сессии на 24 часа
PERMANENT_SESSION_LIFETIME = timedelta(hours=24)
def FLASK_APP_MUTATOR(app: Flask) -> None:
app.before_request_funcs.setdefault(None, []).append(make_session_permanent)¶ 1.11 Флаги функций
Для поддержки разнообразного набора пользователей в RT.DataVision есть некоторые функции, которые не включены по умолчанию. Например, у одних пользователей более строгие ограничения безопасности, а у других нет. Таким образом, RT.DataVision позволяет пользователям включать или отключать некоторые функции с помощью конфигурации. Для владельцев функций вы можете добавить дополнительные функции в RT.DataVision, но они будут затронуты только подмножеством пользователей.
Вы можете включить или отключить функции с помощью флага из superset_config.py:
FEATURE_FLAGS = {
'PRESTO_EXPAND_DATA': False,
}Текущий список флагов функций можно найти в RESOURCES/FEATURE_FLAGS.md.
¶ 1.12 Конфигурационные настройки RT DataVision
| Настройка | Описание | Значение по умолчанию | |
|---|---|---|---|
| STATS_LOGGER | Логгер для статистики. | DummyStatsLogger() | |
| EVENT_LOGGER | Логгер для событий в RT DataVision. | DBEventLogger() | |
| SUPERSET_LOG_VIEW | Логгер статистики в реальном времени, реализован StatsD. | True | |
| BASE_DIR | Базовая директория приложения. | pkg_resources.resource_filename("superset", "") | |
| VERSION_INFO_FILE | Путь к файлу version_info.json для RT DataVision. | str(files("superset") / "static/version_info.json") | |
| PACKAGE_JSON_FILE | Путь к файлу package.json для RT DataVision. | str(files("superset") / "static/assets/package.json") | |
| ALEMBIC_SKIP_LOG_CONFIG | Если значение True, то вызов для загрузки конфигурации логгера, найденной в alembic.ini, будет пропущен. | False | |
| VERSION_STRING | Строка версии RT DataVision, извлекаемая из файлов. | _try_json_readversion(VERSION_INFO_FILE) or _try_json_readversion(PACKAGE_JSON_FILE ) | |
| VERSION_SHA_LENGTH | Длина сокращённого хэша версии приложения, используемого для отображения в интерфейсе или логах. | 8 | |
| VERSION_SHA | SHA-1 хеш версии. | _try_json_readsha(VERSION_INFO_FILE, VERSION_SHA_LENGTH) | |
| BUILD_NUMBER | Номер сборки, отображаемый в разделе "О программе", если он доступен. Это значение может быть заменено во время сборки, чтобы отобразить информацию о версии сборки. | None | |
| DEFAULT_VIZ_TYPE | Визуализация по умолчанию, используемая в исследователе графиков и в SQL Lab. | "table" | |
| ROW_LIMIT | Лимит строк по умолчанию при запросе данных для графика. | 50000 | |
| SAMPLES_ROW_LIMIT | Лимит строк по умолчанию при запросе выборок из источника данных в режиме исследования. | 1000 | |
| NATIVE_FILTER_DEFAULT_ROW_LIMIT | Лимит строк по умолчанию для нативных фильтров. | 1000 | |
| FILTER_SELECT_ROW_LIMIT | Максимальное количество строк, возвращаемое автозаполнением выбора фильтра. | 10000 | |
| DEFAULT_TIME_FILTER | Фильтр времени по умолчанию в режиме исследования. Значения могут быть, например, "Last day", "Last week", "<ISO date> : now" и т.д. | NO_TIME_RANGE | |
| SUPERSET_WEBSERVER_TIMEOUT | Это важная настройка, и её значение должно быть ниже, чем настройки тайм-аутов для вашего [балансировщика нагрузки / прокси / Envoy / Kong / ...]. Также убедитесь, что тайм-аут для вашего WSGI-сервера (например, gunicorn, nginx, apache, ...) настроен на значение, не превышающее это значение. | int(timedelta(minutes=1).total_seconds()) | |
| SUPERSET_DASHBOARD_PERIODICAL_REFRESH_LIMIT | Эти две настройки используются функцией принудительного периодического обновления дашборда. Когда пользователь выбирает частоту автоматического принудительного обновления, которая меньше значения SUPERSET_DASHBOARD_PERIODICAL_REFRESH_LIMIT, он увидит предупреждающее сообщение в модальном окне выбора интервала обновления. |
0 | |
| SUPERSET_DASHBOARD_PERIODICAL_REFRESH_WARNING_MESSAGE | None | ||
| SUPERSET_DASHBOARD_POSITION_DATA_LIMIT | Лимит данных о положении виджетов на дашборде в RT DataVision. Используется для ограничения размера данных, связанных с размещением элементов на дашборде. | 65535 | |
| CUSTOM_SECURITY_MANAGER | Настройка для указания пользовательского менеджера безопасности. Она позволяет внедрить собственную логику управления безопасностью, заменяя стандартный механизм безопасности в RT DataVision. | None | |
| SQLALCHEMY_TRACK_MODIFICATIONS | Опция отслеживания изменений в SQLAlchemy. Когда установлена в True, SQLAlchemy отслеживает изменения объектов и управляет дополнительной нагрузкой на ресурсы. Обычно рекомендуется оставлять её False для повышения производительности. | False | |
| SECRET_KEY |
Секретный ключ приложения. Убедитесь, что он переопределен в superset_config.py или используется через переменную окружения SUPERSET_SECRET_KEY. Используйте сильную сложную строку, состоящую из букв и цифр, и воспользуйтесь инструментами для генерации случайных последовательностей, например, командой openssl rand -base64 42. |
os.environ.get("SUPERSET_SECRET_KEY") or CHANGE_ME_SECRET_KEY | |
| SQLALCHEMY_DATABASE_URI | URI базы данных для SQLAlchemy. | 'postgresql://superset:superset@localhost/superset' | |
| SQLALCHEMY_CUSTOM_PASSWORD_STORE | Функция для подключения пользовательского хранилища паролей для всех соединений SQLAlchemy. Функция должна принимать единственный аргумент типа sqla.engine.url и возвращать пароль. | None | |
| DEMO_DATA_REPO | Ссылка на репозиторий с демо данными без указания протокола. | "" | |
| DEMO_DATA_LOGIN | Логин для доступа к репозиторию с демо данными. | "" | |
| DEMO_DATA_PASSWORD | Пароль для логина, используемого для доступа к репозиторию с демо данными. | "" | |
| SQLALCHEMY_ENCRYPTED_FIELD_TYPE_ADAPTER | Используется для построения моделей SQLAlchemy, которые включают чувствительные поля, подлежащие шифрованию перед отправкой в базу данных. | (SQLAlchemyUtilsAdapter) | |
| QUERY_SEARCH_LIMIT | Лимит количества запросов для поиска по запросам. | 1000 | |
| WTF_CSRF_ENABLED | Флаг для CSRF защиты в Flask-WTF. | True | |
| WTF_CSRF_EXEMPT_LIST | Список конечных точек, которые не нуждаются в CSRF защите. |
|
|
| DEBUG | Режим отладки для веб-сервера. | os.environ.get("FLASK_DEBUG") | |
| FLASK_USE_RELOAD | Флаг для режима отладки Flask. | True | |
| PROFILING | Включает профилирование Python-вызовов. Чтобы просмотреть стек вызовов, добавьте ?_instrument=1 к URL страницы. | False | |
| SHOW_STACKTRACE | Разрешает отображение трассировки Python для пользователя. В целях безопасности рекомендуется отключить в production. | False | |
| ENABLE_PROXY_FIX | Использовать все заголовки X-Forwarded, когда эта опция включена. | False | |
| PROXY_FIX_CONFIG | Настройки для проксирования при использовании заголовков X-Forwarded. |
|
|
| SCHEDULED_QUERIES | Настройка для планирования запросов из SQL Lab, представляющая собой словарь с ключами типа str и значениями произвольного типа (dict[str, Any]). По умолчанию это пустой словарь, который можно заполнить для задания параметров и правил планирования выполнения SQL-запросов. | {} | |
| Настройки ограничения скорости для предотвращения атак DDoS. | |||
| RATELIMIT_ENABLED | Настройка для включения функции ограничения скорости в Flask. | True | |
| RATELIMIT_APPLICATION | Настройка для определения ограничения скорости запросов к приложению. | "50 per second" | |
| AUTH_RATE_LIMITED | Настройка, которая определяет, требуется ли аутентификация для доступа к приложению с ограничением скорости. Если установлено значение True, то аутентификация является обязательной, и если установлено значение False, то она не требуется. | True | |
| AUTH_RATE_LIMIT | Настройка для определения ограничения скорости для аутентифицированного пользователя. | "5 per second" | |
| RATELIMIT_STORAGE_URI | Настройка, определяющая местоположение хранилища для ограничения скорости. Это URI, указывающее на хранилище, которое используется для хранения информации о запросах. Например, для использования Redis это может быть строка вида "redis://host:port". Схема хранения должна соответствовать спецификации, указанной в документации для библиотеки limits. Например: "redis://host:port" | None | |
| RATELIMIT_REQUEST_IDENTIFIER | Настройка, которая определяет уникальный идентификатор для каждого запроса. Это callable объект, возвращающая идентификатор текущего запроса. Чаще всего используется для отслеживания количества запросов, сделанных определенным пользователем или на определенный ресурс. Например: flask.Request.endpoint | None | |
| Глобальные настройки для конструктора приложения | |||
| APP_NAME | Настройка для задания названия приложения. Это имя будет использоваться для отображения в пользовательском интерфейсе или других местах, где необходимо указать название приложения. | "Superset" | |
| APP_ICON | Логотип приложения. | "/static/assets/images/superset-logo-horiz.png" | |
| LOGO_TARGET_PATH | Ссылка, на которую будет переходить пользователь, кликнув по логотипу. | None | |
| LOGO_TOOLTIP | Подсказка, отображаемая при наведении на иконку или логотип приложения. | "" | |
| LOGO_RIGHT_TEXT |
Текст, отображаемый справа от логотипа. Этот текст может быть как строкой, так и функцией, которая возвращает строку при вызове. Тип данных: Callable[[], str] | str. |
"" | |
| FAB_API_SWAGGER_UI | Включает Swagger UI для спецификации. Принимает значения True или False. | True | |
| Настройки аутентификации | |||
| AUTH_TYPE |
Настройка для выбора типа аутентификации:
|
AUTH_DB | |
| AUTH_ROLE_ADMIN | Название роли, которая будет обладать всеми правами в системе. Например: “Admin”. | None | |
| AUTH_ROLE_PUBLIC | Название публичной роли, доступной без аутентификации. Публичная роль может использоваться для пользователей, не прошедших аутентификацию. Например: “Public”. | None | |
| AUTH_USER_REGISTRATION | Позволяет разрешить пользователям регистрироваться самостоятельно в системе. Принимает значения True или False. | False | |
| AUTH_USER_REGISTRATION_ROLE | Роль, которая будет присваиваться пользователям при их саморегистрации в системе. Например: “Public”. | None | |
| AUTH_LDAP_SERVER | URL-адрес LDAP-сервера для настройки аутентификации через LDAP. Например: "ldap://ldapserver.new". | None | |
| AUTH_LDAP_EMAIL_FIELD | Название поля на LDAP-сервере, содержащее Email пользователя. Например: “mail”. | None | |
| AUTH_LDAP_SEARCH | Базовый DN для поиска на LDAP-сервере. Например: “DC=DOMAIN,DC=RU”. | None | |
| AUTH_LDAP_UID_FIELD | Название поля на LDAP-сервере, содержащее имя пользователя при поиске учетной записи для привязки. Например: “sAMAccountName”. | None | |
| AUTH_LDAP_BIND_USER | DN пользователя, из-под которого RT.DataVision будет производить поиск пользователей на LDAP-сервере при попытке аутентификации. Например: “CN=TUZUser,OU=ServiceAccounts,DC=DOMAIN,DC=RU”. | None | |
| AUTH_LDAP_BIND_PASSWORD | Пароль для пользователя, указанного в параметре AUTH_LDAP_BIND_USER. | None | |
| AUTH_LDAP_GROUP_FIELD | Название поля на LDAP-сервере, содержащее список групп пользователя. Например: "memberOf”. | None | |
| AUTH_ROLES_MAPPING |
Маппинг ролей на сервере аутентификации к ролям RT.Datavision. Записывается в виде словаря, где ключ - название группы (для LDAP это DN группы) на сервере аутентификации, а значение - список ролей, уже созданных в RT.DataVision, которые будут назначены пользователю, если он член группы на сервере аутентификации. Например:
|
{} | |
| OAUTH_PROVIDERS |
Список провайдеров OAUTH, через которые можно выполнить вход в RT.DataVision. Полное описание доступно в документации FAB. Например:
|
[] | |
| AUTH_ROLES_SYNC_AT_LOGIN | Синхронизировать роли пользователя с сервером аутентификации при каждом входе в RT.DataVision. | False | |
| PERMANENT_SESSION_LIFETIME | Время жизни сессии пользователя в секундах. | 360 | |
| OPENID_PROVIDERS |
Список провайдеров OpenID, через которые можно выполнить вход в RT.DataVision. Полное описание доступно в документации FAB. Например:
|
[] | |
| Конфигурация ролей | |||
| PUBLIC_ROLE_LIKE |
Настройка, задающая роль, для которой публичный доступ будет предоставлен с теми же правами, что и у выбранной встроенной роли. Это позволяет разрешить анонимным пользователям просматривать дашборды, но явные права на конкретные датасеты остаются обязательными. Тип данных: str | None. Значение может быть строкой (имя роли) или None для отключения такой настройки. |
None | |
| Настройки локализации с Babel | |||
| BABEL_DEFAULT_LOCALE | Язык приложения по умолчанию. | "ru" | |
| BABEL_DEFAULT_FOLDER | Путь для хранения переводов приложения. | "superset/translations" | |
| LANGUAGES | Языки для приложения. |
|
|
| LANGUAGES | Флаг для отключения i18n по умолчанию, если переводы неполные. |
|
|
| D3_FORMAT |
Переопределяет формат для локализации в D3 (например, для разделителей тысяч, десятичных знаков, валютных символов и т. д.). Подробнее см. в разделе Настройка формата D3. |
{} | |
| Функциональные флаги | |||
| DEFAULT_FEATURE_FLAGS |
Контейнер для всех флагов, которые управляют активацией или деактивацией функций. Настройка представляет собой словарь dict[str, Union[bool, str, list]]. |
||
| CLIENT_CACHE |
Настройка устарела. Включает экспериментальный функционал кеширования на стороне клиента (браузера). |
False | |
| DISABLE_DATASET_SOURCE_EDIT | Настройка устарела. | False | |
| DRUID_JOINS | Включает поддержку JOIN-запросов для новых версий Druid. | False | |
| DYNAMIC_PLUGINS | Включает поддержку динамических плагинов. | False | |
| DISABLE_LEGACY_DATASOURCE_EDITOR | Отключение редактора устаревших источников данных. | True | |
| ENABLE_EXPLORE_JSON_CSRF_PROTECTION |
Настройка устарела. Настройка предназначена для усиления защиты от CSRF-атак (межсайтовой подделки запроса) при отправке запросов к explore_json endpoint. Если значение настройки установлено на true, все запросы к этому endpoint через метод GET будут запрещены, и пользователи смогут использовать только POST-запросы. Эта мера может быть полезна для защиты от злоупотребления GET-запросами, так как flask-csrf по умолчанию защищает только POST-запросы. |
False | |
| ENABLE_TEMPLATE_PROCESSING | Включает обработку шаблонов в запросах или отчетах системы. | False | |
| ENABLE_TEMPLATE_REMOVE_FILTERS |
Настройка устарела. Включает обработку шаблонов и автоматически удаляет фильтры, используемые в визуализациях или отчетах. |
True | |
| ENABLE_JAVASCRIPT_CONTROLS | Включает поддержку компонентов управления с возможностью ввода JavaScript и настройки графиков. | False | |
| KV_STORE | Включает поддержку хранения данных в формате ключ-значение. | False | |
| PRESTO_EXPAND_DATA | Включает расширение вложенных типов данных в Presto. | False | |
| THUMBNAILS | Включает API для вычисления миниатюр. | False | |
| DASHBOARD_CACHE |
Настройка устарела. Включает использование кэша для панелей мониторинга. |
False | |
| REMOVE_SLICE_LEVEL_LABEL_COLORS |
Настройка устарела. Отключает использование индивидуальных цветов для меток уровня среза в визуализациях. |
False | |
| SHARE_QUERIES_VIA_KV_STORE | Включает возможность сохранять и делиться выполненными запросами через хранилище KV. | False | |
| TAGGING_SYSTEM | Включает поддержку системы тегов для упрощения классификации и фильтрации объектов в RT DataVision. | False | |
| SQLLAB_BACKEND_PERSISTENCE | Включает возможность сохранять запросы и результаты SQL Lab в бекенд-хранилище для последующего восстановления. | True | |
| LISTVIEWS_DEFAULT_CARD_VIEW | Включает отображение данных в виде карточек по умолчанию в представлениях списка. | False | |
| ESCAPE_MARKDOWN_HTML | Включает экранирование HTML-кода в компонентах Markdown, предотвращая его выполнение. | False | |
| DASHBOARD_NATIVE_FILTERS | Включение нативных фильтров для дашбордов. | True | |
| DASHBOARD_CROSS_FILTERS | Включает поддержку перекрестных фильтров на дашбордах. | True | |
| DASHBOARD_NATIVE_FILTERS_SET | Включает возможность использования предустановленных фильтров для панелей мониторинга. | False | |
| DASHBOARD_FILTERS_EXPERIMENTAL | Включает экспериментальные фильтры в панели мониторинга. | False | |
| DASHBOARD_VIRTUALIZATION | Включает виртуализацию для оптимизации рендеринга панелей мониторинга с большим количеством компонентов. | False | |
| GLOBAL_ASYNC_QUERIES | Включает возможность выполнения глобальных асинхронных запросов. | False | |
| VERSIONED_EXPORT | Включает возможность экспорта версии конфигурации, данных или метаданных RT DataVision. | True | |
| EMBEDDED_SUPERSET | Включает возможность встраивания RT DataVision в сторонние приложения. | False | |
| ALERT_REPORTS | Включает новую реализацию системы оповещений и отчетов. | False | |
| ENABLE_EXPLORE_DRAG_AND_DROP | Включает возможность перетаскивания объектов и элементов в интерфейсе проводника панели мониторинга. | True | |
| ENABLE_ADVANCED_DATA_TYPES | Включает поддержку расширенных типов данных в RT DataVision. | False | |
| ALERTS_ATTACH_REPORTS | Включает отправку скриншотов и ссылок вместе с уведомлениями и отчетами. | True | |
| ALLOW_FULL_CSV_EXPORT | Включает возможность полного экспорта CSV для таблиц. | False | |
| ALLOW_FULL_EXCEL_EXPORT | Включает возможность полного экспорта данных из RT DataVision в формате Excel, включая всю информацию в таблицах или визуализациях. | False | |
| GENERIC_CHART_AXES | Включает отображение общих осей на диаграммах. | True | |
| ALLOW_ADHOC_SUBQUERY | Включает выполнение подзапросов в AdHoc-фильтрах. | False | |
| USE_ANALAGOUS_COLORS | Включает использование аналогичных цветов для визуализаций. | False | |
| RLS_IN_SQLLAB | Включает применение правил RLS (политики безопасности строк) к запросам в SQL Lab. | False | |
| CACHE_IMPERSONATION | Включает кэширование на основе ключа маскировки (например, имени пользователя). | False | |
| CACHE_QUERY_BY_USER | Включает кэширование запросов по ключу пользователя. | False | |
| ENABLE_PDF_EXPORT | Включает возможность экспорта отчетов и панелей мониторинга в формате PDF. | False | |
| ENABLE_FOLDERS_VIEW | Включает возможность просмотра и управления папками в интерфейсе. | False | |
| SENDING_BY_FTP | Включает возможность отправки данных или отчетов по FTP-соединению. | False | |
| ENABLE_SENTRY_DEBUG | Включает отладку RT.DataVision через приложение Sentry. | False | |
| EMBEDDABLE_CHARTS | Включает возможность встраивания диаграмм в другие приложения. | True | |
| DRILL_TO_DETAIL | Включает возможность перехода к деталям данных из визуализации. | True | |
| DRILL_BY | Включает функцию Drill By (просмотр данных через иерархические фильтры). | False | |
| DATAPANEL_CLOSED_BY_DEFAULT | Закрывает панель данных по умолчанию на панелях мониторинга. | False | |
| HORIZONTAL_FILTER_BAR | Включает отображение горизонтальной панели фильтров. | False | |
| ESTIMATE_QUERY_COST | Включает оценку стоимости выполнения запросов. | False | |
| SSH_TUNNELING | Включает возможность настройки SSH-туннелей при создании базы данных. | False | |
| AVOID_COLORS_COLLISION | Включает предотвращение конфликта цветов в визуализациях. | True | |
| MENU_HIDE_USER_INFO | Скрывает информацию о пользователе в меню. | False | |
| ENABLE_SUPERSET_META_DB | Включает возможность использования метабазы RT DataVision. | False | |
| PLAYWRIGHT_REPORTS_AND_THUMBNAILS | Включает использование Playwright вместо Selenium для генерации отчетов и миниатюр. | False | |
| SENTRY_DEBUG | Настройки интеграции с Sentry. Используется при включенном флаге ENABLE_SENTRY_DEBUG. | ||
| SENTRY_HOSTNAME | Имя хоста сервера. | "" | |
| SENTRY_SERVER_NAME | Идентификатор сервера. | "" | |
| SENTRY_FLASK_DSN | URL подключения Sentry для бэкенда на Flask. | "" | |
| SENTRY_CELERY_DSN | URL подключения Sentry для задач Celery. | "" | |
| SENTRY_REACT_DSN | URL подключения Sentry для фронтенда на React. | "" | |
| SENTRY_FLASK_TRACE_RATE | Процент запросов Flask, включаемых в трассировку. | 0.0 | |
| SENTRY_FLASK_SAMPLE_RATE | Доля запросов Flask, используемых для мониторинга. | 0.0 | |
| SENTRY_FLASK_PROFILES_SAMPLE_RATE | Процент запросов Flask для глубокого профилирования. | 0.0 | |
| SENTRY_CELERY_TRACE_SAMPLE_RATE | Доля задач Celery, отслеживаемых для анализа. | 0.0 | |
| SENTRY_REACT_TRACE_RATE | Процент пользовательских действий на фронтенде, включённых в трассировку. | 0.0 | |
| SENTRY_REACT_PROFILES_RATE | Доля действий React, отслеживаемых для анализа производительности. | 0.0 | |
| SENTRY_REACT_REPLAYS_SESSION_RATE | Частота записи пользовательских сессий для повторного воспроизведения. | 0.0 | |
| SENTRY_REACT_REPLAYS_ONERROR_RATE | Частота записи повторов ошибок фронтенда. | 0.0 | |
| SENTRY_TRACE_PROPAGATION_TARGETS | Определяет сервисы, куда передаются трассировки. | ["localhost", "https://youserver.io/api"] | |
| DASHBOARDS_LOGOS_PATHS | Пути к изображениям логотипов для отображения в интерфейсе приложения. |
|
|
| DG_LOGO_PATH | Путь к изображениям логотипов RT Data Governance для отображения в интерфейсе приложения. |
|
|
| Настройки SSH-туннелей | |||
| SSH_TUNNEL_MANAGER_CLASS | Класс менеджера SSH туннелей. | "superset.extensions.ssh.SSHManager" | |
| SSH_TUNNEL_LOCAL_BIND_ADDRESS | Локальный адрес привязки для SSH туннелей. | "127.0.0.1" | |
| SSH_TUNNEL_TIMEOUT_SEC | Тайм-аут для соединения SSH туннеля. | 10.0 | |
| SSH_TUNNEL_PACKET_TIMEOUT_SEC | Тайм-аут для пакетов SSH туннеля. | 1.0 | |
| EXTRA_CATEGORICAL_COLOR_SCHEMES |
Настройка, позволяющая добавлять пользовательские цветовые схемы для визуализаций. Схемы задаются в виде словаря, где ключами являются названия схем, а значениями — списки цветов. Это расширяет стандартный набор цветовых схем RT DataVision, предоставляя возможность использовать уникальные палитры для анализа данных. Тип данных: list[dict[str, Any]] Пример:
|
[] | |
| THEME_OVERRIDES |
Настройка, позволяющая задавать пользовательские значения для ключей темы, таких как цвета, шрифты, размеры и другие элементы визуального оформления. Изменения, внесённые в этот словарь, применяются поверх базовой темы, позволяя кастомизировать интерфейс без изменения исходного кода. Тип данных: dict[str, Any] Пример:
|
{} | |
| EXTRA_SEQUENTIAL_COLOR_SCHEMES |
Настройка, позволяющая добавлять настраиваемые цветовые палитры для создания последовательных градиентов, которые применяются к различным типам графиков и диаграмм. Цветовые схемы вносятся в виде словарей, где указываются название схемы и её значения. Тип данных: list[dict[str, Any]] Пример:
|
[] | |
| Конфигурация миниатюр (зависит от функционального флага) | |||
| THUMBNAIL_EXECUTE_AS | Список типов исполнителей для рендеринга миниатюр. | [ExecutorType.CURRENT_USER, ExecutorType.SELENIUM] | |
| THUMBNAIL_SELENIUM_USER | Имя пользователя для создания миниатюр через Selenium. | "admin" | |
| THUMBNAIL_CACHE_CONFIG | Конфигурация кеша для миниатюр. |
|
|
| SCREENSHOT_LOCATE_WAIT | Время ожидания, чтобы Selenium дождался появления элемента на странице для скриншота. | int(timedelta(seconds=10).total_seconds()) | |
| SCREENSHOT_LOAD_WAIT | Время ожидания для исчезновения всех DOM элементов с классом "loading". | int(timedelta(minutes=1).total_seconds()) | |
| SCREENSHOT_SELENIUM_RETRIES | Количество попыток перезапуска Selenium при сбое. | 5 | |
| SCREENSHOT_SELENIUM_HEADSTART | Время (в секундах), которое Selenium будет ждать до начала захвата скриншота. | 3 | |
| SCREENSHOT_SELENIUM_ANIMATION_WAIT | Время (в секундах), которое Selenium будет ждать для завершения анимации на графике. | 5 | |
| SCREENSHOT_REPLACE_UNEXPECTED_ERRORS | Включает замену неожиданных ошибок в процессе создания скриншотов на информативные сообщения об ошибках. | False | |
| SCREENSHOT_WAIT_FOR_ERROR_MODAL_VISIBLE | Время (в секундах), которое Selenium будет ждать, чтобы увидеть модальное окно с ошибкой. | 5 | |
| SCREENSHOT_WAIT_FOR_ERROR_MODAL_INVISIBLE | Время (в секундах), которое Selenium будет ждать, чтобы модальное окно с ошибкой исчезло. | 5 | |
| SCREENSHOT_PLAYWRIGHT_WAIT_EVENT | Событие Playwright, на которое он будет ожидать при загрузке новой страницы. | "load" | |
| SCREENSHOT_PLAYWRIGHT_DEFAULT_TIMEOUT | Тайм-аут по умолчанию для всех операций в контексте браузера Playwright. | int(timedelta(seconds=30).total_seconds() * 1000 ) | |
| Конфигурация изображений и файлов | |||
| UPLOAD_FOLDER | Папка для загрузки файлов. | BASE_DIR + "/app/static/uploads/" | |
| UPLOAD_CHUNK_SIZE | Максимальный размер фрагмента данных (в байтах), который может быть загружен за один раз. | 4096 | |
| IMG_UPLOAD_FOLDER | Папка для загрузки изображений. | BASE_DIR + "/app/static/uploads/" | |
| IMG_UPLOAD_URL | URL для доступа к загруженным изображениям | "/static/uploads/" | |
| IMG_SIZE |
Максимальный размер изображения, который может быть обработан или сохранен в системе. Например: (300, 200, True) |
() | |
| CACHE_DEFAULT_TIMEOUT | Время ожидания по умолчанию для кеша. | int(timedelta(days=1).total_seconds()) | |
| CACHE_CONFIG | Конфигурация кеша для объектов RT DataVision. | {"CACHE_TYPE": "NullCache"} | |
| DATA_CACHE_CONFIG | Конфигурация кеша для метаданных и результатов запросов. | {"CACHE_TYPE": "NullCache"} | |
| FILTER_STATE_CACHE_CONFIG | Конфигурация кеша для состояния фильтров дашбордов. |
|
|
| CACHE_TYPE | Тип используемого кэша | "SupersetMetastoreCache" | |
| CACHE_DEFAULT_TIMEOUT | Время (в секундах), в течение которого кэшированные данные остаются актуальными. | int(timedelta(days=90).total_seconds()) | |
| REFRESH_TIMEOUT_ON_RETRIEVAL | Включает обновление времени жизни (таймаута) кэшированных данных при их извлечении. | True | |
| CODEC | Определяет способ сериализации и десериализации данных для хранения в кэше. | JsonKeyValueCodec() | |
| EXPLORE_FORM_DATA_CACHE_CONFIG | Конфигурация кеша для состояния данных форм исследования (Explore). |
|
|
| CACHE_TYPE | Тип используемого кэша | "SupersetMetastoreCache" | |
| CACHE_DEFAULT_TIMEOUT | Время (в секундах), в течение которого кэшированные данные остаются актуальными. | int(timedelta(days=7).total_seconds()) | |
| REFRESH_TIMEOUT_ON_RETRIEVAL | Включает обновление времени жизни (таймаута) кэшированных данных при их извлечении. | True | |
| CODEC | Определяет способ сериализации и десериализации данных для хранения в кэше. | JsonKeyValueCodec() | |
| STORE_CACHE_KEYS_IN_METADATA_DB | Включает сохранение ключей кеша в базе данных метаданных для дальнейшей обработки и аннулирования кеша. | False | |
| ENABLE_CORS | Включает поддержку CORS (кросс-оригинальных запросов). | False | |
| CORS_OPTIONS |
Опции для настройки CORS. Тип данных: dict[Any, Any] |
{ } | |
| HTML_SANITIZATION | Включает или выключает санитацию HTML контента для предотвращения XSS атак при рендеринге markdown. | True | |
| HTML_SANITIZATION_SCHEMA_EXTENSIONS |
Позволяет расширить схему санитации HTML, например, для добавления атрибутов или протоколов. Тип данных: dict[str, Any] Пример:
|
{} | |
| SUPERSET_WEBSERVER_DOMAINS | Разрешенные домены для выполнения кросс-доменных запросов. | None | |
| EXCEL_EXTENSIONS | Разрешенные расширения файлов для загрузки на страницу базы данных (форматы Excel). | {"xlsx", "xls"} | |
| CSV_EXTENSIONS | Разрешенные расширения файлов для загрузки на страницу базы данных (форматы CSV). | {"csv", "tsv", "txt"} | |
| COLUMNAR_EXTENSIONS | Разрешенные расширения файлов для загрузки на страницу базы данных (форматы для колонковых данных). | {"parquet", "zip"} | |
| ALLOWED_EXTENSIONS | Объединяет разрешенные расширения для всех типов загрузок (Excel, CSV, Columnar). | {*EXCEL_EXTENSIONS, *CSV_EXTENSIONS, *COLUMNAR_EXTENSIONS} | |
| CSV_UPLOAD_MAX_SIZE | Максимальный размер файла для загрузки CSV в байтах. | None | |
| CSV_EXPORT |
Опции для экспорта CSV, передаваемые в метод DataFrame.to_csv. Тип данных: dict[str, Any] |
|
|
| EXCEL_EXPORT |
Опции для экспорта Excel, передаваемые в метод DataFrame.to_excel. Тип данных: dict[str, Any] |
|
|
| EXCEL_DATA_WORKSHEET_NAME | Имя листа Excel, которое будет использоваться по умолчанию при экспорте данных из RT DataVision. | "Data" | |
| EXCEL_CHART_WORKSHEET_NAME | Имя рабочего листа Excel, содержащего диаграмму, при экспорте данных. | "Chart" | |
| Конфигурации временной гранулярности | |||
| TIME_GRAIN_DENYLIST |
Список временных интервалов (time grain), использование которых запрещено. Эти интервалы не будут отображаться в интерфейсе RT DataVision и не будут доступны для выбора в фильтрах и визуализациях. Тип данных: list[str] Пример: ['PT1S'] |
[] | |
| TIME_GRAIN_ADDONS |
Настройка, позволяющая добавлять пользовательские временные интервалы (time grain) для использования в RT DataVision. Это расширяет стандартный набор интервалов, предоставляя возможность настройки временной детализации для анализа данных. Тип данных: dict[str, str] Пример: {'PT2S': '2 second'} |
{} | |
| TIME_GRAIN_ADDON_EXPRESSIONS |
Настройка, позволяющая добавлять пользовательские выражения для временных интервалов (time grain) в запросах к базе данных. Эти выражения задают форматирование временных данных на уровне базы, предоставляя гибкость при обработке нестандартных временных интервалов. Тип данных: dict[str, str] Пример:
|
{} | |
| TIME_GRAIN_JOIN_COLUMN_PRODUCERS |
Настройка, определяющая функции, которые могут быть использованы для генерации колонок с временными интервалами (time grain) в операциях объединения данных (join). Тип данных: dict[str, Callable[[str], str]] Пример: {"P1F": join_producer} |
{} | |
| Ограничение типов визуализаций | |||
| VIZ_TYPE_DENYLIST |
Настройка, определяющая список визуализаций, которые должны быть недоступны для использования в интерфейсе пользователя. Тип данных: list[str] Пример: ['pivot_table', 'treemap'] |
[] | |
| VIZ_TYPE_NO_AUTO_MIGRATE_LIST |
Настройка, позволяющая задать список типов визуализаций, для которых следует отключить автоматическое обновление типа визуализации при импорте из .zip архива. Тип данных: list[str] Пример: ['pivot_table_v2'] |
[] | |
| Модули, источники данных и промежуточное ПО для регистрации | |||
| DEFAULT_MODULE_DS_MAP | Сопоставление модулей с источниками данных, которые будут зарегистрированы по умолчанию. |
|
|
| ADDITIONAL_MODULE_DS_MAP |
Дополнительные модули и источники данных, которые будут зарегистрированы. Тип данных: dict[str, list[str]] |
{} | |
| ADDITIONAL_MIDDLEWARE |
Список дополнительных промежуточных слоев (middleware), которые будут зарегистрированы. Тип данных: list[Callable[..., Any]] |
[] | |
| LOGGING_CONFIGURATOR | Конфигуратор для настройки логирования, использующий параметры LOG_*. | DefaultLoggingConfigurator() | |
| LOG_FORMAT | Формат записи в журнал логирования. | "%(asctime)s:%(levelname)s:%(name)s:%(message)s" | |
| LOG_LEVEL | Уровень логирования (DEBUG, INFO, WARNING, ERROR, CRITICAL). | "DEBUG" | |
| Включение обработчика логов с временной ротацией | |||
| LOG_LEVEL | Уровень логирования (DEBUG, INFO, WARNING, ERROR, CRITICAL). | DEBUG | |
| ENABLE_TIME_ROTATE | Включает поддержку ротации логов по времени. | False | |
| TIME_ROTATE_LOG_LEVEL | Уровень логирования для времени ротации. | "DEBUG" | |
| FILENAME | Путь к файлу логирования. | os.path.join(DATA_DIR, "superset.log") | |
| ROLLOVER | Включает ротацию логов на основе времени или объема данных. | "midnight" | |
| INTERVAL | Интервал ротации логов. | 1 | |
| BACKUP_COUNT | Количество резервных копий для ротации логов. | 30 | |
| QUERY_LOGGER | Управляет логированием SQL-запросов, выполненных в SQL Lab и при генерации диаграмм/дашбордов. | None | |
| MAPBOX_API_KEY | API ключ для использования визуализаций Mapbox. | os.environ.get("MAPBOX_API_KEY", "") | |
| MAP_CONNECTIONS | Настройка для синхронизации карт с другими элементами дашборда. | [] | |
| SQL_MAX_ROW | Максимальное количество строк, возвращаемых для любого аналитического запроса в базе данных. | 100000 | |
| FULL_CSV_MAX_ROW | Настройка ограничивает количество строк, которые могут быть экспортированы в CSV-файл при полном экспорте данных. | 100000 | |
| FULL_EXCEL_MAX_ROW | Настройка ограничивает количество строк, которые могут быть экспортированы в EXCEL-файл при полном экспорте данных. | 100000 | |
| DISPLAY_MAX_ROW | Максимальное количество строк, отображаемых в SQL Lab UI. | 10000 | |
| DEFAULT_SQLLAB_LIMIT | Стандартный лимит строк для запросов в SQL Lab. | 1000 | |
| SUPERSET_META_DB_LIMIT | Ограничивает количество данных, возвращаемых из мета-базы данных при работе с несколькими источниками. | 1000 | |
| SQLLAB_SAVE_WARNING_MESSAGE | Предупреждение, отображаемое при сохранении запроса в SQL Lab. | None | |
| SQLLAB_SCHEDULE_WARNING_MESSAGE | Предупреждение, отображаемое при планировании запроса в SQL Lab. | None | |
| DASHBOARD_AUTO_REFRESH_MODE |
Настройка, которая управляет режимом автоматического обновления данных на панели мониторинга. Тип данных: Literal["fetch", "force"] |
"force" | |
| DASHBOARD_AUTO_REFRESH_INTERVALS | Список интервалов для автоматического обновления дашборда. |
|
|
| CELERY_BEAT_SCHEDULER_EXPIRES | Время жизни задачи планировщика Celery, используемое как временное решение для задачи "alerts & reports". | timedelta(weeks=1) | |
| CELERY_CONFIG | Настройка конфигурации для Celery, отвечающая за параметры обработки фоновых задач | CeleryConfig | |
| DEFAULT_HTTP_HEADERS |
Стандартные HTTP-заголовки для сервера RT DataVision. Тип данных: dict[str, Any] |
{} | |
| OVERRIDE_HTTP_HEADERS |
Заголовки HTTP, которые будут переопределять стандартные значения. Тип данных: dict[str, Any] |
{} | |
| HTTP_HEADERS |
Итоговые HTTP-заголовки, которые будут отправляться с ответами сервера. Тип данных: dict[str, Any] |
{} | |
| DEFAULT_DB_ID | Идентификатор базы данных по умолчанию для SQL Lab. | None | |
| SQLLAB_TIMEOUT | Время ожидания для синхронных запросов в SQL Lab. | int(timedelta(seconds=3000).total_seconds()) | |
| SQLLAB_VALIDATION_TIMEOUT | Время ожидания для проверки запросов в SQL Lab. | int(timedelta(seconds=1000).total_seconds()) | |
| SQLLAB_DEFAULT_DBID | Идентификатор базы данных по умолчанию для SQL Lab. | None | |
| SQLLAB_ASYNC_TIME_LIMIT_SEC | Максимальное время выполнения асинхронного запроса в SQL Lab. | int(timedelta(hours=6).total_seconds()) | |
| SQLLAB_QUERY_COST_ESTIMATE_TIMEOUT | Время ожидания для запроса оценки стоимости выполнения в SQL Lab. | int(timedelta(seconds=1000).total_seconds()) | |
| QUERY_COST_FORMATTERS_BY_ENGINE |
Настройка для определения форматирования стоимости запросов в зависимости от типа используемой базы данных. Тип данных: dict[str, Callable[[list[dict[str, Any]]], list[dict[str, Any]]]] Пример: {"postgresql": postgres_query_cost_formatter} |
{} | |
| SQLLAB_CTAS_NO_LIMIT | Настройка, регулирующая возможность отключения ограничения на количество строк при выполнении запросов типа CREATE TABLE AS (CTAS). | False | |
| SQLLAB_CTAS_SCHEMA_NAME_FUNC |
Настройка, представляющая функцию, которая позволяет динамически определять схему для запросов типа CREATE TABLE AS (CTAS) в SQL Lab. Тип данных: None | (Callable[[Database, models.User, str, str], str]) |
None | |
| RESULTS_BACKEND |
Включает сохранение результатов долгих запросов, запущенных через Run Async в SQL Lab. Тип данных: BaseCache | None |
None | |
| RESULTS_BACKEND_USE_MSGPACK | Если True, для сериализации результатов будет использоваться формат MessagePack вместо JSON. | True | |
| CSV_TO_HIVE_UPLOAD_S3_BUCKET | Имя S3 бакета для хранения внешних таблиц Hive, созданных из CSV файлов. | None | |
| CSV_TO_HIVE_UPLOAD_DIRECTORY | Папка в S3, в которой будут храниться внешние таблицы. | "EXTERNAL_HIVE_TABLES/" | |
| UPLOADED_CSV_HIVE_NAMESPACE |
Пространство имен Hive для таблиц, созданных из загруженных CSV файлов. Тип данных: str | None |
None | |
| CSV_DEFAULT_NA_NAMES | Список значений, которые следует воспринимать как NULL при загрузке CSV. | list(STR_NA_VALUES) | |
| JINJA_CONTEXT_ADDONS |
Словарь дополнительных функций для контекста Jinja в SQL Lab. Эти функции могут быть использованы в запросах, но требуют осторожности с точки зрения безопасности. Тип данных: dict[str, Callable[..., Any]] |
{} | |
| CUSTOM_TEMPLATE_PROCESSORS |
Словарь макросов для обработки шаблонов, зависящих от используемой СУБД. Позволяет определить пользовательскую логику обработки запросов на уровне конкретного движка. Тип данных: dict[str, type[BaseTemplateProcessor]] |
{} | |
| DEFAULT_META_DATABASE_ENABLED_ADAPTERS |
Настройка определяет статусы (включен/выключен) адаптеров для библиотеки Shillelagh, доступных для обработки запросов к базе метаданных. Тип данных: dict[str, bool] |
|
|
| META_DATABASE_ENABLED_ADAPTERS |
Список баз данных, которые поддерживаются платформой по умолчанию. Тип данных: dict[str, bool] |
{} | |
| ROBOT_PERMISSION_ROLES | Роли, управляемые API / RT DataVision, которые не должны изменяться вручную. | ["Public", "Gamma", "Alpha", "Admin", "sql_lab"] | |
| CONFIG_PATH_ENV_VAR | Переменная окружения, которая указывает путь к конфигурационному файлу RT DataVision. | "SUPERSET_CONFIG_PATH" | |
| FLASK_APP_MUTATOR | Настройка, позволяющая передать функцию (callable), которая будет вызываться при запуске приложения Flask. | None | |
| ENABLE_ACCESS_REQUEST | Настройка, определяющая, могут ли пользователи запрашивать или предоставлять доступ к источникам данных другим пользователям. Если значение установлено в False, такие действия будут недоступны. | False | |
| FTP_CONNECTIONS | Настройка, управляющая параметрами для интеграции с FTP-серверами. Она позволяет настраивать соединение для загрузки или выгрузки файлов через FTP, включая указание хоста, порта, имени пользователя, пароля и других параметров безопасности. | [] | |
| EMAIL_NOTIFICATIONS | Включение уведомлений по электронной почте. | False | |
| SMTP_HOST | Адрес SMTP-сервера для отправки уведомлений. | "localhost" | |
| SMTP_STARTTLS | Использование TLS для подключения к SMTP-серверу. | True | |
| SMTP_SSL | Использование SSL для подключения к SMTP-серверу. | False | |
| SMTP_USER | Имя пользователя для подключения к SMTP-серверу. | "superset" | |
| SMTP_PORT | Порт для подключения к SMTP-серверу. | 25 | |
| SMTP_PASSWORD | Пароль для подключения к SMTP-серверу. | "superset" | |
| SMTP_MAIL_FROM | Адрес отправителя для почтовых уведомлений. | "superset@superset.com" | |
| SMTP_SSL_SERVER_AUTH | Использование SSL-сертификата для подключения. | False | |
| ENABLE_CHUNK_ENCODING | Включение кодирования с использованием чанков. | False | |
| SILENCE_FAB | Уменьшение количества логов, генерируемых Flask App Builder (FAB). Если True, уровень логирования FAB будет повышен до ERROR. | True | |
| FAB_ADD_SECURITY_VIEWS | Включение стандартных страниц безопасности в RT DataVision для управления пользователями и ролями. | True | |
| FAB_ADD_SECURITY_PERMISSION_VIEW | Добавление представления безопасности для управления разрешениями. | False | |
| FAB_ADD_SECURITY_VIEW_MENU_VIEW | Добавление представления безопасности для меню. | False | |
| FAB_ADD_SECURITY_PERMISSION_VIEWS_VIEW | Добавление представления безопасности для разрешений на представления. | False | |
| TROUBLESHOOTING_LINK | Ссылка на страницу с инструкциями по устранению ошибок. | "" | |
| WTF_CSRF_TIME_LIMIT | Время жизни CSRF-токена в секундах. | int(timedelta(weeks=1).total_seconds()) | |
| PERMISSION_INSTRUCTIONS_LINK | Ссылка на страницу с инструкциями по получению доступа к источникам данных в случае ошибки разрешений. | "" | |
| BLUEPRINTS |
Позволяет интегрировать внешние модули (Blueprints) в приложение, добавляя их в список. Эти модули автоматически подключаются к основному приложению во время его настройки. Тип данных: list[Blueprint] |
[] | |
| TRACKING_URL_TRANSFORMER | Трансформация URL-ов для отслеживания запросов. Например, преобразования URL для Hadoop или Presto. | lambda url: url | |
| DB_POLL_INTERVAL_SECONDS |
Словарь, который задает интервалы между опросами для каждого движка базы данных. Тип данных: dict[str, int] |
{} | |
| PRESTO_POLL_INTERVAL | Интервал опроса для подключения к серверу Presto. | int(timedelta(seconds=1).total_seconds()) | |
| ALLOWED_EXTRA_AUTHENTICATIONS |
Дополнительные методы аутентификации для каждого движка базы данных. Тип данных: dict[str, dict[str, Callable[..., Any]]] |
{} | |
| DASHBOARD_TEMPLATE_ID | ID шаблона панели, который будет копироваться для каждого нового пользователя. | None | |
| DB_CONNECTION_MUTATOR | Позволяет динамически изменять параметры подключения, например, использовать адрес электронной почты пользователя в качестве имени пользователя для подключения. | None | |
| MUTATE_AFTER_SPLIT | Указывает, применять ли изменения через SQL_QUERY_MUTATOR до или после разбиения SQL-запроса на отдельные операторы | False | |
| EXCLUDE_USERS_FROM_LISTS |
Список пользователей, которые будут исключены из всех выпадающих списков пользователей, например, при создании графиков или отчетов. Тип данных: list[str] | None |
None | |
| DBS_AVAILABLE_DENYLIST |
Словарь с базами данных, которые не должны отображаться в списке доступных для подключения в интерфейсе. Тип данных: dict[str, set[str]] |
{} | |
| MACHINE_AUTH_PROVIDER_CLASS | Определяет механизм аутентификации для фона, который может быть переопределен пользователями для поддержания кастомных механизмов аутентификации. | "superset.utils.machine_auth.MachineAuthProvider" | |
| ALERT_REPORTS_CRON_WINDOW_SIZE | Размер скользящего окна cron для оповещений и отчетов (минус 1 секунда от конфигурации celery). | 59 | |
| ALERT_REPORTS_WORKING_TIME_OUT_KILL | Завершение задачи, если она превысит время работы. | True | |
| ALERT_REPORTS_EXECUTE_AS |
Список ролей пользователей, от имени которых будут выполняться оповещения/отчеты. Тип данных: list[ExecutorType] |
[ExecutorType.OWNER] | |
| ALERT_REPORTS_WORKING_TIME_OUT_LAG | Настройка для задания дополнительного времени ожидания сверх основного тайм-аута работы оповещений и отчетов. Это значение добавляется к стандартному рабочему тайм-ауту, чтобы учесть возможные задержки в процессе выполнения задач. | int(timedelta(seconds=10).total_seconds()) | |
| ALERT_REPORTS_WORKING_SOFT_TIME_OUT_LAG | Дополнительное время ожидания, которое добавляется к "мягкому" тайм-ауту задач оповещений и отчетов. Это значение учитывает возможные незначительные задержки, не приводя к немедленному завершению задачи. | int(timedelta(seconds=1).total_seconds()) | |
| ALERT_REPORTS_DEFAULT_WORKING_TIMEOUT | Задает стандартное время ожидания для выполнения задач оповещений и отчетов. Это время используется в качестве базового при создании новых задач. | 3600 | |
| ALERT_REPORTS_DEFAULT_RETENTION | Определяет стандартный срок хранения данных отчетов и оповещений, после которого они будут удалены или архивированы. | 90 | |
| ALERT_REPORTS_DEFAULT_CRON_VALUE | Значение cron для периодичности выполнения отчетов (по умолчанию - каждый день). | "0 * * * *" | |
| ALERT_REPORTS_NOTIFICATION_DRY_RUN | Включение тестового режима для уведомлений об оповещениях и отчетах. | False | |
| ALERT_REPORTS_QUERY_EXECUTION_MAX_TRIES | Максимальное количество попыток выполнения запроса перед возвратом ошибки. | 1 | |
| ALERT_REPORTS_MIN_CUSTOM_SCREENSHOT_WIDTH | Задает минимальную ширину пользовательских скриншотов, которые можно использовать в задачах оповещений и отчетов. | 600 | |
| ALERT_REPORTS_MAX_CUSTOM_SCREENSHOT_WIDTH | Определяет максимальную допустимую ширину пользовательских скриншотов для тех же задач. | 2400 | |
| EMAIL_REPORTS_SUBJECT_PREFIX | Префикс для темы письма отчетов. | "[Report] " | |
| EMAIL_REPORTS_CTA | Текст кнопки действия в email-уведомлениях отчетов. | "Explore in Superset" | |
| SLACK_API_TOKEN |
API токен для Slack отчетов. Тип данных: Callable[[], str] | str | None |
None | |
| SLACK_PROXY | Прокси-сервер для интеграции с Slack. | None | |
| WEBDRIVER_TYPE | Тип веб-драйвера для создания миниатюр и отчетов. | "firefox" | |
| WEBDRIVER_WINDOW | Настройки окна браузера для веб-драйвера. |
|
|
| WEBDRIVER_AUTH_FUNC | Аутентификация для использования с Selenium или Playwright в отчетах и миниатюрах. | None | |
| WEBDRIVER_CONFIGURATION |
Дополнительные настройки для webdriver, передаваемые как словарь. Тип данных: dict[Any, Any] |
{"service_log_path": "/dev/null"} | |
| WEBDRIVER_OPTION_ARGS | Задаёт дополнительные параметры, которые передаются объекту конфигурации веб-драйвера. Например, для работы с браузером Chrome можно добавить аргумент "--marionette". | ["--headless"] | |
| WEBDRIVER_BASEURL | URL для веб-драйвера Selenium. | "http://0.0.0.0:8080/" | |
| WEBDRIVER_BASEURL_USER_FRIENDLY | Базовый URL, используемый для создания гиперссылок в email-отчётах. | WEBDRIVER_BASEURL | |
| EMAIL_PAGE_RENDER_WAIT | Время ожидания, в течение которого Selenium будет ждать загрузки и отрисовки страницы, используемой для создания email-отчёта. Это время учитывается перед созданием снимка или извлечением данных. | int(timedelta(seconds=30).total_seconds()) | |
| BUG_REPORT_URL | Ссылка, по которой пользователи могут сообщать об ошибках. | None | |
| BUG_REPORT_TEXT | Текст ссылки для отчета об ошибке. | "Report a bug" | |
| BUG_REPORT_ICON | Иконка для ссылки на отчет об ошибке (рекомендуемый размер: 16x16). | None | |
| DOCUMENTATION_URL | Ссылка на документацию RT DataVision. | None | |
| DOCUMENTATION_TEXT | Текст ссылки для документации. | "Documentation" | |
| DOCUMENTATION_ICON | Иконка для ссылки на документацию (рекомендуемый размер: 16x16). | None | |
| DEFAULT_RELATIVE_START_TIME | Определяет начальное время для фильтра "Последние N дней". Установка на "сегодня" означает, что началом будет полночь (00:00:00) локального часового пояса. Используется для создания временных рамок с фиксированной или плавающей точкой отсчёта. | "today" | |
| DEFAULT_RELATIVE_END_TIME | Определяет конечное время для фильтра "Последние N дней". Установка на "сейчас" делает окончание временного периода относительным к моменту выполнения запроса. Если начало и конец установлены на "сейчас", фильтр создаёт скользящее временное окно. | "today" | |
| SQL_VALIDATORS_BY_ENGINE | Определяет, какой валидатор SQL будет использоваться для каждой базы данных. |
|
|
| PREFERRED_DATABASES |
Список предпочитаемых баз данных для отображения в диалоге "Добавить базу данных". Тип данных: list[str] |
|
|
| TEST_DATABASE_CONNECTION_TIMEOUT | Время ожидания для тестирования подключения к базе данных. | timedelta(seconds=30) | |
| CONTENT_SECURITY_POLICY_WARNING | Включение или отключение предупреждений по безопасности контента (CSP). | True | |
| TALISMAN_ENABLED | Включение или отключение использования Talisman для защиты приложения. | utils.cast_to_boolean(os.environ.get("TALISMAN_ENABLED", True)) | |
| TALISMAN_CONFIG | Основные настройки политики Talisman - безопасности контента, включая CSP и настройку для HTTP/HTTPS. |
|
|
| TALISMAN_DEV_CONFIG | Конфигурация Talisman для разработки, где включены настройки для работы с eval, что необходимо для React в режиме разработки. |
|
|
| SESSION_COOKIE_HTTPONLY | Указывает, что cookie не может быть прочитано JavaScript. | True | |
| SESSION_COOKIE_SECURE | Указывает, что cookie передаются только по HTTPS. | False | |
| SESSION_COOKIE_SAMESITE |
Устанавливает политику SameSite для cookies (предотвращает отправку cookies в запросах с других сайтов). Тип данных: Literal["None", "Lax", "Strict"] | None |
"Lax" | |
| SESSION_SERVER_SIDE | Включает серверное хранение сессий с использованием Flask-сессий. | False | |
| SESSION_USE_SIGNER | Активирует использование подписанных cookie-файлов для сессий, чтобы защитить данные от подделки. | False | |
| SESSION_TYPE | Определяет хранилище для данных сессии. Например, "redis" для использования Redis, "filesystem" для локального хранения, "null" для отключения сессий. | None | |
| SESSION_REDIS |
Содержит настройки подключения к серверу Redis, который используется для хранения данных сессии при выборе соответствующего типа. Пример: Redis(host="localhost", port=6379, db=0) |
None | |
| SEND_FILE_MAX_AGE_DEFAULT | Время хранения кеша для статических ресурсов. | int(timedelta(days=365).total_seconds()) | |
| SQLALCHEMY_EXAMPLES_URI | URI для базы данных, в которой хранится пример данных. | "sqlite:///" + os.path.join(DATA_DIR, "examples.db") | |
| STATIC_ASSETS_PREFIX | Добавляет необязательный префикс ко всем путям статических ресурсов при рендеринге интерфейса пользователя. | "" | |
| PREVENT_UNSAFE_DB_CONNECTIONS | Запрещает использование небезопасных соединений с базой данных. | True | |
| PREVENT_UNSAFE_DEFAULT_URLS_ON_DATASET | Запрещает использование небезопасных URL для загрузки данных. | True | |
| ALLOWED_IMPORT_URL_DOMAINS |
Определяет список разрешенных URL-адресов для импорта данных датасетов (v1). Пример:
|
||
| DATASET_IMPORT_ALLOWED_DATA_URLS | Регулярные выражения для разрешенных URL-адресов для импорта данных. | [r".*"] | |
| SSL_CERT_PATH |
Путь к хранилищу SSL сертификатов. Тип данных: str | None |
None | |
| SQLA_TABLE_MUTATOR | Функция для изменения объектов таблиц в базе данных перед их использованием. | lambda table: table | |
| GLOBAL_ASYNC_QUERY_MANAGER_CLASS | Класс для управления асинхронными запросами. | ("superset.async_events.async_query_manager.AsyncQueryManager" ) | |
| GLOBAL_ASYNC_QUERIES_REDIS_CONFIG | Конфигурация Redis для хранения данных асинхронных запросов. |
|
|
| GLOBAL_ASYNC_QUERIES_REDIS_STREAM_PREFIX | Префикс для Redis stream, используемого для асинхронных запросов. | "async-events-" | |
| GLOBAL_ASYNC_QUERIES_REDIS_STREAM_LIMIT | Ограничение на количество событий в Redis stream. | 1000 | |
| GLOBAL_ASYNC_QUERIES_REDIS_STREAM_LIMIT_FIREHOSE | Ограничивает максимальное количество записей, сохраняемых в Redis для потока запросов Firehose в асинхронном режиме. | 1000000 | |
| GLOBAL_ASYNC_QUERIES_REGISTER_REQUEST_HANDLERS | Включает регистрацию обработчиков запросов для асинхронного выполнения. | True | |
| GLOBAL_ASYNC_QUERIES_JWT_COOKIE_NAME | Название cookie для хранения JWT токена асинхронных запросов. | "async-token" | |
| GLOBAL_ASYNC_QUERIES_JWT_COOKIE_SECURE | Указывает, будет ли cookie с JWT передаваться только по HTTPS (для обеспечения безопасности). | False | |
| GLOBAL_ASYNC_QUERIES_JWT_COOKIE_SAMESITE |
Определяет политику отправки cookie в кросс-доменных запросах для защиты от атак CSRF. Тип данных: None | ( Literal["None", "Lax", "Strict"] ) |
None | |
| GLOBAL_ASYNC_QUERIES_JWT_COOKIE_DOMAIN | Устанавливает домен для доступности cookie, например, для всех поддоменов. | None | |
| GLOBAL_ASYNC_QUERIES_JWT_SECRET | Секрет для подписи JWT. | "test-secret-change-me" | |
| GLOBAL_ASYNC_QUERIES_TRANSPORT | Протокол транспортировки асинхронных запросов, может быть polling или ws (websocket). | "polling" | |
| GLOBAL_ASYNC_QUERIES_POLLING_DELAY | Задержка для опроса в режиме polling, в миллисекундах. | int(timedelta(milliseconds=500).total_seconds() * 1000 ) | |
| GLOBAL_ASYNC_QUERIES_WEBSOCKET_URL | Указывает URL для подключения к WebSocket серверу, используемому для асинхронных запросов. | "ws://127.0.0.1:8080/" | |
| GUEST_ROLE_NAME | Имя роли для гостей (неавторизованных пользователей). | "Public" | |
| GUEST_TOKEN_JWT_SECRET | Секрет для подписи токенов гостя. | "test-guest-secret-change-me" | |
| GUEST_TOKEN_JWT_ALGO | Определяет алгоритм подписи для JSON Web Token (JWT), который используется для создания токенов гостей. | "HS256" | |
| GUEST_TOKEN_HEADER_NAME | Название заголовка для передачи токена гостя. | "X-GuestToken" | |
| GUEST_TOKEN_JWT_EXP_SECONDS | Время жизни токена гостя в секундах. | 300 | |
| GUEST_TOKEN_JWT_AUDIENCE |
Определяет целевую аудиторию (audience) для гостевого токена JWT в embedded RT DataVision. Тип данных: Callable[[], str] | str | None |
None | |
| DATASET_HEALTH_CHECK |
Проверка состояния датасета (например, проверки, если запросы работают только с одной таблицей). Тип данных: Callable[[SqlaTable], str] | None |
None | |
| ADVANCED_DATA_TYPES |
Ключ для указания расширенных типов данных, который должен соответствовать значению, заданному в метаданных столбца. Тип данных: dict[str, AdvancedDataType] |
|
|
| WELCOME_PAGE_LAST_TAB | Конфигурация для отображаемой вкладки на приветственной странице. | (Literal["examples", "all"] | tuple[str, list[dict[str, Any]]] ) = "all" | |
| ZIPPED_FILE_MAX_SIZE | Максимально допустимый размер загружаемого сжатого файла. | 100 * 1024 * 1024 | |
| ZIP_FILE_MAX_COMPRESS_RATIO | Максимальное допустимое сжатие для загружаемого файла. | 200.0 | |
| ENVIRONMENT_TAG_CONFIG | Конфигурация для отображения тега окружения на панели навигации. Устанавливает цвет и текст в зависимости от окружения. |
|
|
| EXTRA_RELATED_QUERY_FILTERS |
Фильтры, которые можно применить к связанным объектам в UI. Пример: {"user": user_filter} |
{} | |
| OSM_CONNECTIONS |
Интеграция данных и сервисов OpenStreetMap с приложением. Пример:
|
[] | |
| EXTRA_DYNAMIC_QUERY_FILTERS |
Фильтры, которые могут быть применены к объектам в UI до применения других фильтров. Пример: {"database": initial_database_filter} |
{} | |
¶ 1.12.1 Настройка фавикона (favicon)
Фавикон — это небольшая иконка, которая отображается рядом с заголовком страницы в браузере, на вкладках, в закладках, а также в некоторых местах интерфейса, где используется изображение для представления веб-сайта.
Настройка, отвечающая за фавикон – FAVICONS:
FAVICONS = [{"href": "/static/assets/images/favicon.png"}]При необходимости, существует возможность задать несколько фавиконов.
Свойство href обязательно для заполнения, так как в нем указывается путь к файлу изображения фавикона. Свойства sizes, type и rel являются опциональными.
Пример:
{
"href":path/to/image.png",
"sizes": "16x16",
"type": "image/png"
"rel": "icon"
}¶ 1.12.2 Настройка формата D3
Настройка D3_FORMAT используется для изменения формата чисел и валюты в приложении. Она позволяет настроить, как будут отображаться числа в визуализациях, используя библиотеку D3.
По умолчанию формат включает следующие параметры:
- decimal: символ для разделения десятичных чисел (например, "." в большинстве стран);
- thousands: символ, используемый для разделения тысяч (например, ",");
- grouping: определяет группировку цифр, обычно [3], что означает разделение после каждой третьей цифры (например, 1,000);
- currency: список с двумя строками — символом валюты, который ставится перед или после числа (например, ["$", ""] для долларов).
Настройка D3_FORMAT в системе по умолчанию:
class D3Format(TypedDict, total=False):
decimal: str
thousands: str
grouping: list[int]
currency: list[str]
D3_FORMAT: D3Format = {}
CURRENCIES = ["USD", "EUR", "GBP", "INR", "MXN", "JPY", "CNY"]¶ 1.12.3 Обновление функциональных флагов
Метод DEFAULT_FEATURE_FLAGS.update() обновляет функциональные флаги, используя переменные окружения с префиксом SUPERSET_FEATURE_. Эти переменные предоставляют возможность динамически изменять функциональность приложения без необходимости редактирования кода или перезапуска сервера. Значения флагов интерпретируются как булевы (True/False) с помощью функции parse_boolean_string.
DEFAULT_FEATURE_FLAGS.update(
{
k[len("SUPERSET_FEATURE_"):]: parse_boolean_string(v)
for k, v in os.environ.items()
if re.search(r"^SUPERSET_FEATURE_\w+", k)
}
)
DEFAULT_FEATURE_FLAGS.update(DASHBOARDS_LOGOS_PATHS)
DEFAULT_FEATURE_FLAGS.update(DG_LOGO_PATH)
DEFAULT_FEATURE_FLAGS.update(SENTRY_DEBUG)¶ 1.12.4 Обработка функциональных флагов
Функция GET_FEATURE_FLAGS_FUNC предназначенная для обработки словаря функциональных флагов. Она позволяет кастомизировать их значения и задавать поведение приложения на основе текущих конфигураций. Функция принимает словарь с флагами и возвращает модифицированный словарь. Не рекомендуется использовать её одновременно с IS_FEATURE_ENABLED_FUNC, чтобы избежать конфликтов при оценке флагов.
GET_FEATURE_FLAGS_FUNC: Callable[[
dict[str, bool]], dict[str, bool]] | None = None¶ 1.12.5 Проверка функциональных флагов
Функция IS_FEATURE_ENABLED_FUNC выполняет проверку состояния отдельного функционального флага. Она принимает два параметра: имя флага и необязательное значение по умолчанию.
IS_FEATURE_ENABLED_FUNC: Callable[[str, bool | None], bool] | None = None¶ 1.12.6 Переопределение общих настроек Bootstrap
Функция COMMON_BOOTSTRAP_OVERRIDES_FUNC предназначена для изменения или переопределения общих параметров Bootstrap, используемых в приложении. Позволяет настроить такие элементы, как стили, темы или дополнительные параметры, обеспечивая уникальные настройки интерфейса.
COMMON_BOOTSTRAP_OVERRIDES_FUNC: Callable[
[dict[str, Any]], dict[str, Any]
] = lambda data: {} # default: empty dict¶ 1.12.7 Функции для генерации идентификаторов миниатюр
Функция THUMBNAIL_DASHBOARD_DIGEST_FUNC предназначена для вычисления уникального хеш-суммы для миниатюр дашбордов. Получает объект дашборда, тип исполнителя и имя пользователя.
THUMBNAIL_DASHBOARD_DIGEST_FUNC: None | (
Callable[[Dashboard, ExecutorType, str], str]
) = NoneФункция THUMBNAIL_CHART_DIGEST_FUNC предназначена для вычисления уникальной хеш-суммы для миниатюр графиков. Получает объект графика, тип исполнителя и имя пользователя.
THUMBNAIL_CHART_DIGEST_FUNC: Callable[[
Slice, ExecutorType, str], str] | None = None¶ 1.12.8 Настройка фоновых задач с использованием Celery
Класс CeleryConfig отвечает за настройку фоновой обработки задач с использованием библиотеки Celery. Он включает следующие параметры для конфигурации:
- broker_url – указывает адрес брокера сообщений, например, для использования базы данных SQLite.
- imports – список импортируемых задач, например, для SQL Lab или планировщика.
- result_backend – хранилище для результатов задач (по умолчанию SQLite).
- worker_prefetch_multiplier – количество задач, которые могут быть загружены для одного рабочего процесса.
- task_acks_late – определяет момент подтверждения выполнения задачи (до или после ее завершения).
- task_annotations – настройки для ограничения скорости выполнения задач (например, "100/s" для SQL-запросов).
- beat_schedule – периодические задачи, выполняемые по расписанию (например, выполнение отчетов).
class CeleryConfig: # pylint: disable=too-few-public-methods
broker_url = "sqla+sqlite:///celerydb.sqlite"
imports = ("superset.sql_lab", "superset.tasks.scheduler")
result_backend = "db+sqlite:///celery_results.sqlite"
worker_prefetch_multiplier = 1
task_acks_late = False
task_annotations = {
"sql_lab.get_sql_results": {
"rate_limit": "100/s",
},
}
beat_schedule = {
"reports.scheduler": {
"task": "reports.scheduler",
"schedule": crontab(minute="*", hour="*"),
"options": {"expires": int(CELERY_BEAT_SCHEDULER_EXPIRES.total_seconds())},
},
"reports.prune_log": {
"task": "reports.prune_log",
"schedule": crontab(minute=0, hour=0),
},
}¶ 1.12.9 Форматирование стоимости запросов
Функция postgres_query_cost_formatter демонстрирует, как можно форматировать данные о стоимости запросов для PostgreSQL. Она вычисляет относительную стоимость и определяет её позицию в рамках заранее заданных пороговых значений, возвращая отформатированный результат.
Эта функция полезна для наглядного анализа производительности запросов, показывая, как запросы сравниваются с заранее определёнными уровнями затрат.
# def postgres_query_cost_formatter(
# result: List[Dict[str, Any]]
# ) -> List[Dict[str, str]]:
# # 25, 50, 75% percentiles
# percentile_costs = [100.0, 1000.0, 10000.0]
#
# out = []
# for row in result:
# relative_cost = row["Total cost"]
# percentile = bisect.bisect_left(percentile_costs, relative_cost) + 1
# out.append({
# "Relative cost": relative_cost,
# "Percentile": str(percentile * 25) + "%",
# })
#
# return out¶ 1.12.10 Настройка схем для CTAS-запросов
Настройка SQLLAB_CTAS_SCHEMA_NAME_FUNC позволяет задавать пользовательскую логику определения целевой схемы для операций CREATE TABLE AS (CTAS) в SQL Lab. Она принимает функцию, которая динамически определяет схему назначения на основе переданных параметров, таких как база данных, пользователь, исходная схема и SQL-запрос.
# postgres_query_cost_formatterSQLLAB_CTAS_SCHEMA_NAME_FUNC = lambda database, user, schema, sql: user.username
# This is move involved example where depending on the database you can leverage data
# available to assign schema for the CTA query:
# def compute_schema_name(database: Database, user: User, schema: str, sql: str) -> str:
# if database.name == 'mysql_payments_slave':
# return 'tmp_superset_schema'
# if database.name == 'presto_gold':
# return user.username
# if database.name == 'analytics':
# if 'analytics' in [r.name for r in user.roles]:
# return 'analytics_cta'
# else:
# return f'tmp_{schema}'¶ 1.12.11 Динамическая директория для загрузки CSV
Функция CSV_TO_HIVE_UPLOAD_DIRECTORY_FUNC формирует путь для загрузки CSV-файлов в зависимости от базы данных, пользователя и схемы. Возвращает путь с завершающим слэшем, включая уникальный идентификатор базы данных и имя схемы, если указано.
def CSV_TO_HIVE_UPLOAD_DIRECTORY_FUNC( # pylint: disable=invalid-name
database: Database,
user: models.User, # pylint: disable=unused-argument
schema: str | None,
) -> str:
# Note the final empty path enforces a trailing slash.
return os.path.join(
CSV_TO_HIVE_UPLOAD_DIRECTORY, str(database.id), schema or "", ""
)¶ 1.12.12 Допустимые схемы для загрузки CSV
Функция ALLOWED_USER_CSV_SCHEMA_FUNC определяет список разрешённых схем для загрузки CSV-файлов. Итоговый набор включает схемы, указанные в конфигурации базы данных, и результат выполнения этой функции. Если задана переменная UPLOADED_CSV_HIVE_NAMESPACE, возвращает её значение в виде списка.
ALLOWED_USER_CSV_SCHEMA_FUNC: Callable[[Database, models.User], list[str]] = (
lambda database, user: [UPLOADED_CSV_HIVE_NAMESPACE]
if UPLOADED_CSV_HIVE_NAMESPACE
else []
)¶ 1.12.13 Обновление адаптеров с поддержкой базы данных Meta по умолчанию
Функция DEFAULT_META_DATABASE_ENABLED_ADAPTERS.update позволяет обновлять список поддерживаемых баз данных для Meta по умолчанию. Она проверяет доступные адаптеры, применяет условия фильтрации и добавляет их в конфигурацию приложения.
DEFAULT_META_DATABASE_ENABLED_ADAPTERS.update(
{
k[len("SUPERSET_META_DATABASE_ENABLE_"):]: parse_boolean_string(v)
for k, v in os.environ.items()
if re.search(r"^SUPERSET_META_DATABASE_ENABLE_\w+", k)
}
)¶ 1.12.14 Функция для изменения SQL-запросов перед выполнением
Функция SQL_QUERY_MUTATOR используется для внесения изменений в SQL-запросы, такие как добавление комментариев с информацией о пользователе, времени или контексте выполнения.
def SQL_QUERY_MUTATOR( # pylint: disable=invalid-name,unused-argument
sql: str, **kwargs: Any
) -> str:
return sql¶ 1.12.15 Функция для изменения заголовков исходящих email-сообщений
Функция EMAIL_HEADER_MUTATOR позволяет модифицировать заголовки email-сообщений, например, для добавления информации о том, кто отправил уведомление, когда оно было отправлено, или для настройки email в соответствии с требованиями конкретной системы.
def EMAIL_HEADER_MUTATOR( # pylint: disable=invalid-name,unused-argument
msg: MIMEMultipart, **kwargs: Any
) -> MIMEMultipart:
return msg¶ 1.12.16 Модификация таблиц SQLAlchemy
Функция SQLA_TABLE_MUTATOR предназначена для изменения схемы или структуры таблиц SQLAlchemy перед их использованием в базе данных. Она предоставляет возможность настроить или изменить данные таблицы перед их сохранением, что полезно для сложных операций с данными, таких как добавление, преобразование или валидация данных в момент их сохранения.
def SQLA_TABLE_MUTATOR(table): return table¶ 1.12.17 Функция для проверки состояния датасетов
Функция DATASET_HEALTH_CHECK предназначена для проверки состояния SQL-датасетов в RT DataVision. Если включена, рекомендуется использовать кэширование (memoization) для улучшения производительности. Это позволяет избежать повторных затратных операций при многократных проверках.
# @cache_manager.cache.memoize(timeout=0)
# def DATASET_HEALTH_CHECK(datasource: SqlaTable) -> Optional[str]:
# if (
# datasource.sql and
# len(sql_parse.ParsedQuery(datasource.sql, strip_comments=True).tables) == 1
# ):
# return (
# "This virtual dataset queries only one table and therefore could be "
# "replaced by querying the table directly."
# )
#
# return None¶ 1.12.18 Мутатор приложения Flask
Функция FLASK_APP_MUTATOR используется для очистки кэша источников данных, если изменился код функции обратного вызова (callback). После инициализации приложения и кэша эта функция проверяет, был ли изменён код функции, и если это так, очищает соответствующий кэш, чтобы гарантировать, что изменения вступят в силу.
# def FLASK_APP_MUTATOR(app: Flask) -> None:
# name = "DATASET_HEALTH_CHECK"
# func = app.config[name]
# code = func.uncached.__code__.co_code
#
# if cache_manager.cache.get(name) != code:
# cache_manager.cache.delete_memoized(func)
# cache_manager.cache.set(name, code, timeout=0)¶ 1.12.19 Настройка фильтров для связанных объектов
Функция user_filter позволяет ограничивать отображение объектов в пользовательском интерфейсе (UI) на основе заданных условий.
# def user_filter(query: Query, *args, *kwargs):
# from superset import security_manager
#
# user_model = security_manager.user_model
# filters = [
# user_model.username == "admin",
# user_model.username.ilike("b%"),
# ]
# return query.filter(or_(*filters))Класс ExtraRelatedQueryFilters используется для настройки пользовательских фильтров на уровне ключей, таких как role и user. Это позволяет ограничивать список ролей, пользователей или других связанных объектов, отображаемых в UI.
class ExtraRelatedQueryFilters(TypedDict, total=False):
role: Callable[[Query], Query]
user: Callable[[Query], Query]¶ 1.12.20 Дополнительные динамические фильтры запросов
Функция initial_database_filter используется для создания начального фильтра для базы данных, который применяется перед другими стандартными фильтрами. Она ограничивает отображение объектов (например, баз данных) в интерфейсе, основываясь на заданных условиях.
# def initial_database_filter(query: Query, *args, *kwargs):
# from superset.models.core import Database
#
# filter = Database.database_name.startswith('b')
# return query.filter(filter)Класс ExtraDynamicQueryFilters — это типизированный словарь (TypedDict), который задаёт структуру для определения пользовательских фильтров на уровне динамических запросов. Эти фильтры позволяют ограничивать данные, отображаемые в пользовательском интерфейсе (UI), ещё до применения стандартных фильтров.
class ExtraDynamicQueryFilters(TypedDict, total=False):
databases: Callable[[Query], Query]¶ 1.13 Интеграция с Sentry
¶ 1.13.1 Возможности интеграции
Начиная с версии 2.3.0 RT.DataVision поддерживает интеграцию с Sentry — платформой для мониторинга ошибок, анализа производительности и управления обратной связью. Эта интеграция позволяет:
- Получать уведомления об ошибках в продукте и передавать их в Sentry;
- Принимать обратную связь и отслеживать проблемы производительности;
- Быстрее реагировать на инциденты и оперативно их решать.
¶ 1.13.2 Включение интеграции
Для включения интеграции:
1. Добавьте блок настроек SENTRY_DEBUG в конфигурационный файл RT.DataVision (если отсутствует):
SENTRY_DEBUG = {
"SENTRY_HOSTNAME": "sentry-hostname",
"SENTRY_SERVER_NAME": "your-hostname",
"SENTRY_FLASK_DSN": "",
"SENTRY_CELERY_DSN": "",
"SENTRY_REACT_DSN": "",
"SENTRY_FLASK_TRACE_RATE": 1.0,
"SENTRY_FLASK_SAMPLE_RATE": 1.0,
"SENTRY_FLASK_PROFILES_SAMPLE_RATE": 1.0,
"SENTRY_CELERY_TRACE_SAMPLE_RATE": 1.0,
"SENTRY_REACT_TRACE_RATE": 1.0,
"SENTRY_REACT_PROFILES_RATE": 1.0,
"SENTRY_REACT_REPLAYS_SESSION_RATE": 1.0,
"SENTRY_REACT_REPLAYS_ONERROR_RATE": 1.0,
"SENTRY_TRACE_PROPAGATION_TARGETS": ["your-hostname"]
}2. Измените значения в следующих настройках:
| Изменение значений обязательно | ||
| SENTRY_HOSTNAME | Доменное имя сервера Sentry. | |
| SENTRY_SERVER_NAME | Доменное имя или IP адрес в случае отсутствия доменного имени стенда с RT.DV, например: vm-prod-dv.rt.ru. | |
| SENTRY_FLASK_DSN | DSN приложения типа Flask в Sentry. | |
| SENTRY_CELERY_DSN | DSN приложения типа Celery в Sentry. | |
| SENTRY_REACT_DSN | DSN приложения типа React в Sentry. | |
| Изменение значений опционально | ||
| SENTRY_FLASK_TRACE_RATE | Процент транзакций, отправляемых в Sentry с серверной части продукта RT.DataVision. Значение от 0.0 до 1.0. | |
| SENTRY_FLASK_SAMPLE_RATE | Процент ошибок, отправляемых в Sentry с серверной части продукта RT.DataVision, значение от 0.0 до 1.0. Ошибки выбирают случайным образом. | |
| SENTRY_FLASK_PROFILES_SAMPLE_RATE | Процент профайлов, а также стек-трейсов, отправляемых в Sentry с серверной части продукта RT.DataVision. Значение от 0.0 до 1.0. Имеет прямую зависимость от SENTRY_FLASK_TRACE_RATE, т.е. работает при SENTRY_FLASK_TRACE_RATE > 0. | |
| SENTRY_CELERY_TRACE_SAMPLE_RATE | Процент транзакций, отправляемых в Sentry с Celery-воркеров RT.DataVision. Значение от 0.0 до 1.0. | |
| SENTRY_REACT_TRACE_RATE | Процент транзакций, отправляемых в Sentry с пользовательской части продукта RT.DataVision. Значение от 0.0 до 1.0. | |
| SENTRY_REACT_PROFILES_RATE | Процент профайлов, а также стек-трейсов, отправляемых в Sentry с пользовательской части продукта RT.DataVision. Значение от 0.0 до 1.0. Имеет прямую зависимость от SENTRY_REACT_TRACE_RATE, т.е. работает при SENTRY_REACT_TRACE_RATE > 0. | |
| SENTRY_REACT_REPLAYS_SESSION_RATE | Процент повторов сессий пользователей, отправляемых в Sentry с пользовательскойчасти продукта RT.DataVision. Значение от 0.0 до 1.0. | |
| SENTRY_REACT_REPLAYS_ONERROR_RATE | Процент повторов сессий пользователей во время появления ошибки, отправляемых в Sentry с пользовательской части продукта RT.DataVision. Значение от 0.0 до 1.0. | |
3. Включите Feature-флаг ENABLE_SENTRY_DEBUG в конфигурационном файле RT.DataVision.
FEATURE_FLAGS = { "ENABLE_SENTRY_DEBUG": True, } 4. Перезапустите RT.DataVision.
¶ 1.14 Интеграция с Prometheus
RT.DataVision поддерживает интеграцию с Prometheus для сбора детальных метрик по SQL-запросам, проходящим через SQLAlchemy. Это позволяет отслеживать длительность выполнения запросов, их количество и анализировать нагрузку на базу данных.
Для работы интеграции в приложении используются следующие библиотеки:
- Prometheus Flask Exporter – для экспорта метрик в Prometheus.
- Logging – для логирования запросов.
Добавляемые метрики:
| Метрика | Описание |
|---|---|
| sqlalchemy_engine_query_duration_seconds | Среднее время выполнения SQL-запроса через SQLAlchemy |
| sqlalchemy_engine_query_count | Количество выполненных SQL-запросов через SQLAlchemy |
| sqlalchemy_engine_query_max_duration_seconds | Максимальное время выполнения SQL-запроса |
| sqlalchemy_engine_query_min_duration_seconds | Минимальное время выполнения SQL-запроса |
| sqlalchemy_engine_query_median_duration_seconds | Медианное время выполнения SQL-запроса |
Логика работы:
- В приложение добавлены функции для сбора детальных метрик и логов по SQL-запросам.
- Prometheus Flask Exporter добавляет новый GET-эндпоинт /metrics для получения метрик через Prometheus.
- Используется модуль Logging для логирования.
¶ 2 Дополнительные настройки сети
¶ 2.1 CORS
Чтобы настроить CORS (совместное использование ресурсов разных источников, Cross-Origin Resource Sharing), необходимо установить следующую зависимость:
pip install rt.datavision[cors]Для настройки CORS можно указать следующие ключи в superset_config.py:
- ENABLE_CORS — должно быть установлено значение True, чтобы включить CORS;
- CORS_OPTIONS — параметры, переданные в Flask-CORS (ознакомьтесь с документацией).
¶ 2.2 Шардинг доменов
Chrome позволяет одновременно открывать до 6 подключений к одному домену. Когда на дашборде более 6 графиков, запросы на выборку стоят в очереди продолжительное время и ждут следующего доступного сокета. Функция шардинга домена может быть включена только в конфигурации (по умолчанию RT.DataVision не разрешает междоменные запросы).
Добавьте следующий параметр в файл superset_config.py:
- SUPERSET_WEBSERVER_DOMAINS — список разрешённых имён хостов для функции шардинга домена.
Создайте шарды домена в качестве поддоменов вашего основного домена, чтобы авторизация работала корректно на новых доменах. Например:
SUPERSET_WEBSERVER_DOMAINS=['superset-1.mydomain.com','superset-2.mydomain.com','superset-3.mydomain.com','superset-4.mydomain.com']Или добавьте следующий параметр в файл superset_config.py, если шарды домена не являются поддоменами основного домена:
SESSION_COOKIE_DOMAIN = '.mydomain.com'¶ 2.3 Middleware-компонент
RT.DataVision позволяет добавлять middleware-компоненты (т.е. промежуточное ПО). Чтобы добавить middleware-компонент, обновите ключ ADDITIONAL_MIDDLEWARE в файле superset_config.py. ADDITIONAL_MIDDLEWARE должен быть списком ваших дополнительных классов middleware-компонентов.
Например, чтобы использовать AUTH_REMOTE_USER из-за прокси-сервера, такого как Nginx, вам нужно добавить простой класс middleware-компонента, чтобы добавить значение HTTP_X_PROXY_REMOTE_USER (или любой другой кастомный заголовок из прокси) в переменную среды REMOTE_USER Gunicorn.
¶ 3 Кэширование
RT.DataVision использует Flask-Caching для кэширования. Flask-Caching поддерживает различные бэкенды кэширования, включая Redis (рекомендуется), Memcached, SimpleCache (в памяти) или локальную файловую систему. Также поддерживаются кастомные бэкенды кэширования.
Кэширование можно настроить, предоставив справочники в superset_config.py, соответствующие спецификациям конфигурации Flask-Caching.
Таким образом можно настроить следующие конфигурации кэша:
- FILTER_STATE_CACHE_CONFIG — состояние фильтра дашборда [опционально].
- EXPLORE_FORM_DATA_CACHE_CONFIG — исследование данных формы диаграммы [опционально].
- CACHE_CONFIG — кэш метаданных [опционально].
- DATA_CACHE_CONFIG — данные диаграммы, запрошенные из датасетов [опционально].
Например, чтобы настроить кэш состояний фильтра с помощью Redis:
FILTER_STATE_CACHE_CONFIG = {
'CACHE_TYPE': 'RedisCache',
'CACHE_DEFAULT_TIMEOUT': 86400,
'CACHE_KEY_PREFIX': 'superset_filter_cache',
'CACHE_REDIS_URL': 'redis://localhost:6379/0'
}¶ 3.1 Зависимости
Чтобы использовать выделенные хранилища кэша, необходимо установить дополнительные библиотеки Python:
- Для Redis — рекомендуется pyton-пакет redis.
- Для Memcached — рекомендуется использовать клиентскую библиотеку pylibmc, поскольку python-memcached некорректно обрабатывает хранение бинарных данных.
Эти библиотеки можно установить с помощью pip.
¶ 3.2 Резервное хранилище кэша
Обратите внимание, что требуется определённая форма кэширования Состояний фильтров (Filter State) и Исследовать (Explore). Если какой-либо из этих кэшей не определён, RT.DataVision возвращается к использованию встроенного кэша, который хранит данные в БД метаданных. Рекомендуется использовать выделенный кэш, но встроенный кэш также можно использовать для кэширования других данных.
Например, чтобы использовать встроенный кэш для хранения данных графиков, используйте следующую конфигурацию:
DATA_CACHE_CONFIG = {
"CACHE_TYPE": "SupersetMetastoreCache",
"CACHE_KEY_PREFIX": "superset_results", # убедитесь, что эта строка уникальна, чтобы избежать коллизий
"CACHE_DEFAULT_TIMEOUT": 86400, # 60 секунд * 60 минут * 24 часа
}¶ 3.3 Таймаут кэша графиков
Таймаут кэша для графиков может быть переопределён настройками отдельного графика, датасета или базы данных. Каждая из этих конфигураций будет проверена по порядку, прежде чем вернуться к значению по умолчанию, определённому в DATA_CACHE_CONFIG.
Обратите внимание, что, установив для таймаута кэша значение -1, кэширование данных графиков можно отключить либо для каждого графика, датасета или базы данных, либо по умолчанию, если оно установлено в DATA_CACHE_CONFIG.
¶ 3.4 Результаты запросов Лаборатории SQL
Кэширование результатов запросов Лаборатории SQL (SQL Lab) используется, когда асинхронные запросы включены и настраиваются с помощью RESULTS_BACKEND.
Обратите внимание, что эта конфигурация не использует для своей конфигурации справочник flask-caching, а вместо этого требует объект cachelib.
Подробности см. в п. 6 Асинхронные запросы через Celery.
¶ 3.5 Кэширование миниатюр
Кэширование миниатюр — дополнительная функция, которую можно включить, активировав соответствующий флаг в конфигурации:
FEATURE_FLAGS = {
"THUMBNAILS": True,
"THUMBNAILS_SQLA_LISTENERS": True,
}По умолчанию миниатюры отображаются для каждого пользователя, а для анонимных пользователей они возвращаются к пользователю Selenium. Чтобы всегда отображать миниатюры от имени фиксированного пользователя (в данном примере admin), используйте следующую конфигурацию:
from superset.tasks.types import ExecutorType
THUMBNAIL_SELENIUM_USER = "admin"
THUMBNAIL_EXECUTE_AS = [ExecutorType.SELENIUM]Для этой функции вам понадобится система кэширования и воркеры Celery. Все миниатюры хранятся в кэше и обрабатываются воркерами асинхронно.
Пример конфигурации, в которой изображения хранятся на S3, может быть следующим:
from flask import Flask
from s3cache.s3cache import S3Cache
...
class CeleryConfig(object):
broker_url = "redis://localhost:6379/0"
imports = (
"superset.sql_lab",
"superset.tasks.thumbnails",
)
result_backend = "redis://localhost:6379/0"
worker_prefetch_multiplier = 10
task_acks_late = True
CELERY_CONFIG = CeleryConfig
def init_thumbnail_cache(app: Flask) -> S3Cache:
return S3Cache("bucket_name", 'thumbs_cache/')
THUMBNAIL_CACHE_CONFIG = init_thumbnail_cache
# Асинхронная selenium-задача миниатюры будет использовать следующего пользователя
THUMBNAIL_SELENIUM_USER = "Admin"При использовании приведённого выше примера ключи кэша для дашбордов будут иметь вид superset_thumb__dashboard__{ID}. Вы можете переопределить базовый URL-адрес для selenium следующим образом:
WEBDRIVER_BASEURL = "https://superset.company.com"Дополнительную конфигурацию веб-диска Selenium можно установить с помощью WEBDRIVER_CONFIGURATION. Вы можете имплементировать кастомную функцию для selenium-аутентификации. Функция по умолчанию использует cookie сессии flask-login. Ниже приведён пример сигнатуры кастомной функции:
def auth_driver(driver: WebDriver, user: "User") -> WebDriver:
passИ для конфигурации:
WEBDRIVER_AUTH_FUNC = auth_driver¶ 4 Логирование
¶ 4.1 Логирование событий
RT.DataVision по умолчанию логирует события специальных действий в своей внутренней базе данных (DBEventLogger). Доступ к этим логам можно получить в пользовательском интерфейсе, выбрав Безопасность (Security) > Журнал действий (Action Log). Вы можете свободно кастомизировать эти логи, имплементируя свой собственный класс лога событий. Когда кастомный класс лога включён, DBEventLogger отключается, и логи перестают заполняться в представлении логов в интерфейсе. Чтобы архивировать все логи, кастомный класс логов должен расширять встроенный класс логов DBEventLogger.
Ниже приведён пример простого класса JSON-to-stdout:
def log(self, user_id, action, *args, **kwargs):
records = kwargs.get('records', list())
dashboard_id = kwargs.get('dashboard_id')
slice_id = kwargs.get('slice_id')
duration_ms = kwargs.get('duration_ms')
referrer = kwargs.get('referrer')
for record in records:
log = dict(
action=action,
json=record,
dashboard_id=dashboard_id,
slice_id=slice_id,
duration_ms=duration_ms,
referrer=referrer,
user_id=user_id
)
print(json.dumps(log))После внесения изменений обновите конфигурацию, чтобы применить инстанс логгера, который вы хотите использовать:
EVENT_LOGGER = JSONStdOutEventLogger()¶ 4.2 Логирование StatsD
При желании RT.DataVision можно настроить для логирования событий в StatsD. Большинство обращений к эндпоинтам, а также ключевые события, такие как начало и завершение запросов, регистрируются в Лаборатории SQL (SQL Lab).
Чтобы настроить логирование StatsD, необходимо сконфигурировать логгер в файле superset_config.py.
from superset.stats_logger import StatsdStatsLogger
STATS_LOGGER = StatsdStatsLogger(host='localhost', port=8125, prefix='superset')Обратите внимание, что вы также можете имплементировать свой собственный логгер, производный от superset.stats_logger.BaseStatsLogger.
¶ 5 Обновление RT.DataVision
¶ 5.1 Обновление через Docker Compose
Чтобы обновить RT.DataVision, развёрнутый в docker-контейнере, выполните:
1. Сначала обязательно завершите работающие контейнеры в Docker Compose:
docker compose down2. Затем обновите папку, реплицирующую репозиторий superset, через git:
cd superset/
git pull origin master3. Затем перезапустите контейнеры, и все изменённые docker-образы будут автоматически удалены:
docker compose up¶ 5.2 Обновление вручную
Чтобы обновить RT.DataVision в собственной установке, выполните следующие команды:
pip install apache-superset --upgrade
superset db upgrade
superset initОбычно при обновлении RT.DataVision дашборды и графики не удаляются, но всё-таки рекомендуется сделать резервную копию БД метаданных перед обновлением. Перед обновлением производственной среды рекомендуется выполнить обновление в промежуточной среде и, наконец, обновить производственную среду во время непикового использования.
¶ 6 Асинхронные запросы через Celery
¶ 6.1 Celery
Для больших аналитических баз характерен запуск запросов, которые выполняются в течение продолжительного количества минут или даже часов. Чтобы включить поддержку длительных запросов, которые выполняются за пределами типичного времени ожидания веб-запроса (30-60 секунд), необходимо сконфигурировать асинхронный бэкенд для RT.DataVision, который состоит из:
- одного или несколько воркеров RT.DataVision (которые имплементированы как воркеры Celery), и они могут быть запущены с помощью команды celery worker. Выполните celery worker --help, чтобы просмотреть соответствующие параметры;
- celery-брокера (очереди сообщений), для которого рекомендуется использовать Redis или RabbitMQ;
- бэкенд результатов, который определяет, где воркер будет сохранять результаты запроса.
Для конфигурирования Celery необходимо определить CELERY_CONFIG в файле superset_config.py. Процессы веб-сервера и воркеров должны иметь одинаковую конфигурацию.
class CeleryConfig(object):
broker_url = "redis://localhost:6379/0"
imports = (
"superset.sql_lab",
"superset.tasks.scheduler",
)
result_backend = "redis://localhost:6379/0"
worker_prefetch_multiplier = 10
task_acks_late = True
task_annotations = {
"sql_lab.get_sql_results": {
"rate_limit": "100/s",
},
}
CELERY_CONFIG = CeleryConfigЧтобы запустить воркера Celery для использования конфигурации, выполните следующую команду:
celery --app=superset.tasks.celery_app:app worker --pool=prefork -O fair -c 4Чтобы запустить джоб, который планирует запуск периодических фоновых джобов, выполните следующую команду:
celery --app=superset.tasks.celery_app:app beatЧтобы настроить бэкенд результатов, вам нужно передать инстанс производной от flask_caching.backends.base в ключ конфигурации RESULTS_BACKEND в вашем superset_config.py. Вы можете использовать Memcached, Redis, S3, память или файловую систему (в рамках однонодового развёртывания или в целях тестирования) или написать свой собственный интерфейс кэширования. superset_config.py может выглядеть примерно так:
# Для S3
from s3cache.s3cache import S3Cache
S3_CACHE_BUCKET = 'foobar-superset'
S3_CACHE_KEY_PREFIX = 'sql_lab_result'
RESULTS_BACKEND = S3Cache(S3_CACHE_BUCKET, S3_CACHE_KEY_PREFIX)
# Для Redis
from flask_caching.backends.rediscache import RedisCache
RESULTS_BACKEND = RedisCache(
host='localhost', port=6379, key_prefix='superset_results')Для повышения производительности MessagePack или PyArrow теперь используются для сериализации результатов. Это можно отключить, установив RESULTS_BACKEND_USE_MSGPACK = False в superset_config.py, если возникнут какие-либо проблемы. При обновлении существующей среды очистите хранилище кэша от существующих результатов.
Учитывайте следующие примечания:
- Важно, чтобы все ноды воркеров и веб-серверы в кластере RT.DataVision использовали общую БД метаданных. Это означает, что SQLite не будет работать в этом контексте, поскольку имеет ограниченную поддержку параллелизма и обычно находится в локальной файловой системе;
- Во всей вашей установке должен быть запущен только один инстанс Celery Beat. В противном случае фоновые джобы могут быть запланированы и запущены несколько раз, что может привести к странному поведению (например, двойная доставка отчётов, более высокая нагрузка/трафик и т.д.);
- Лаборатория SQL (SQL Lab) будет выполнять ваши запросы асинхронно, только если вы включите Асинхронное выполнение запроса (Asynchronous Query Execution) в настройках вашей базы данных (Настройки (Settings) > Database Connections > окно Редактировать базу данных (Edit Database) > вкладка Расширенные (Advanced) > Представление (Perfomance)).
¶ 6.2 Celery Flower
Flower является веб-инструментом для мониторинга кластера Celery. Вы можете установить Flower из pip:
pip install flowerЧтобы запустить Flower, выполните:
celery --app=superset.tasks.celery_app:app flower¶ 7 Оповещения и рассылки
Функциональность Оповещения и отчеты (Alerts & Reports) в RT.DataVision позволяет пользователям легко создавать уведомления, инициируемые событиями (т.е. оповещения) или запланированные уведомления (т.е. рассылка).
Рассылка содержит снапшот дашборда или графика вместе со ссылкой, которая позволяет получателям перейти непосредственно к RT.DataVision для дальнейшего изучения визуализации или дашборда. Оповещения предоставляют настраиваемую ссылку, которая облегчает просмотр и дальнейшее изучение.
- Оповещение предоставляет настраиваемую ссылку на график или весь дашборд, срабатывающее при возникновении события. Событие — это логическое состояние ваших данных, например, неудачная попытка входа в систему. Оповещения доставляются через определённый канал уведомлений. В настоящее время доступна отправка по e-mail и FTP.
- В рассылке содержится снапшот графика или всего дашборда, а также ссылка для дальнейшего разделения запроса. Рассылка может запускаться по определённому расписанию (например, в 16:00 каждый день, каждую неделю и т.д.). Рассылка доставляется по определённому каналу уведомлений. В настоящее время отправка доступна по e-mail и FTP.
¶ 7.1 Переход к оповещениям и отчетам
На панели инструментов перейдите в раздел Настройки (Settings) и выберите пункт Оповещения и Отчеты (Alerts & Reports).
¶ 7.2 Интерфейс
Для открытия формы Оповещения (Alerts) перейдите в Настройки (Settings) > Оповещения и отчеты (Alerts & Reports) > вкладка Оповещения (Alerts). Вкладка Оповещения (Alerts) отображается по умолчанию при переходе в раздел Оповещения и отчеты (Alerts & Reports).
Для открытия формы Отчеты (Reports) перейдите в Настройки (Settings) > Оповещения и отчеты (Alerts & Reports) > вкладка Отчеты (Reports).
В левом верхнем углу форм Оповещения (Alerts) и Отчеты (Reports) находится информация о Последнем обновлении (Last Updated) данных на странице. Для обновления отображаемых данных воспользуйтесь кнопкой обновления на форме.
На вкладках Оповещения (Alerts) и Отчеты (Reports) располагаются фильтры и функции поиска, предназначенные для оперативного поиска необходимых оповещений или рассылок по заданным параметрам.
Доступные фильтры включают следующее:
- Владелец (Owner) — выберите пользователя, чтобы отобразить оповещения и рассылки, владельцем которых он является;
- Создан (Created By) — выберите пользователя для отображения оповещений или рассылок, созданных этим пользователем;
- Статус (Status) — выберите параметр для отображения оповещений или рассылок, соответствующих выбранному статусу. Доступные варианты статуса включают в себя:
- Любой (по умолчанию) — отображаются все записи независимо от статуса;
- Успешно (Success) — отображаются успешно выполненные записи;
- Работа (Working) — отображаются записи, которые в настоящее время обрабатываются;
- Ошибка (Error)— отображаются записи, которые не были успешно запущены;
- Не сработал (Not Triggered) — отображаются записи, для которых запускающее событие (триггер) ещё не активировано;
- На милость (On Grace) — отображаются записи, для которых в настоящее время установлена отсрочка запуска.
Для поиска записей воспользуйтесь полем Поиск (Search):
- Укажите необходимое значение в поле поиска.
- Нажмите клавишу Enter или на значок лупы на форме. В таблице появится список записей, которые включают ваши критерии поиска.
Информация на вкладках Оповещения (Alerts) и Отчеты (Reports) представляет собой таблицы, которые содержат следующие заголовки столбцов:
- Последнее изменение (Last run) – дата, время и разница в часах UTC, когда запись выполнялась в последний раз;
- Имя (Name) – имя оповещения или рассылки, заданное при добавлении или редактировании записи;
- Параметры (Schedule) – определённое расписание оповещения или рассылки (например, каждый час, каждую минуту и т.д.);
- Метод уведомления (Notification method) – значок, указывающий, какой канал уведомлений используется для отправки;
- Создан (Created by) – пользователь, который создал оповещение или рассылку;
- Владельцы (Owners) – значки, указывающие на владельца (владельцев) оповещения или рассылки;
- Последнее изменение (Modified) – сколько времени назад оповещение или рассылка были изменены;
- Активный (Active) – переключатель, который указывает, включено ли оповещение или рассылка в данный момент или нет;
- Действие (Activity) – значки, отображаемые при наведении курсора и позволяющие получить доступ к журналу выполнения, отредактировать или удалить запись.
¶ 7.3 Создание оповещения
В данном разделе, в качестве примера, будет описан процесс создания оповещения, которое срабатывает при неудачной попытке входа пользователя в систему в течение последних 24 часов. Для создания такого оповещения:
1. Перейдите в Настройки (Settings) > Оповещения и Отчеты (Alerts & Reports) > вкладка Оповещения (Alerts).
2. Нажмите кнопку + Оповещение (+ Alert). Откроется окно создания нового оповещения.
3. Укажите основные сведения об оповещении в следующих полях:
- Имя оповещения (Alert Name)* – введите имя нового оповещения;
- Владельцы (Owners)* – выберите одного или нескольких владельцев оповещения. Владелец имеет возможность редактировать оповещение;
- Описание (Description) – введите описание оповещения;
- Переключатель Активный (Active) включается автоматически.
4. Укажите Условия оповещения (Alert condition) для определения события, которое запускает активацию и уведомление о оповещении. Для этого заполните следующие поля:
- База данных (Database)* – выберите базу данных, которую будет анализировать оповещение;
- SQL запрос (SQL Query)* – введите оператор SQL, определяющий характер оповещения. В описываемом примере оператор SQL указывает RT.DataVision подсчитать количество неудачных попыток входа в выбранный источник данных;
- Сделать оповещение, если... (Trigger Alert If)* – выберите необходимое условие. Значение для этого условия указывается в поле Значение (Value)*;
- Значение (Value)* – введите соответствующее значение выбранного условия. В описываемом примере оповещение срабатывает, когда значение больше 0 (т.е. обнаружена неудачная попытка входа в систему).
5. Укажите Расписание условия оповещения (Alert Condition Schedule)* для определения частоты, с которой данные проверяются на предмет выполнения заданного условия. Для этого:
- Выберите из двух вариантов расписание условия оповещения:
- Каждый (Every) — позволяет указать детализированное расписание на основе необходимых требований. Данные можно проверять каждую минуту, час, день, неделю, месяц или год. После установки расписания, поле Расписание CRON (CRON Schedule) будет автоматически заполнено эквивалентным выражением CRON, представляющим указанное расписание;
- Расписание CRON (CRON Schedule) — укажите выражение CRON, соответствующее требуемому расписанию.
- В поле Часовой пояс (Timezone) выберите необходимый часовой пояс.
6. Укажите Настройки расписания (Schedule Settings) в следующих полях:
- Сохранение журнала (Log Retention)* – введите количество дней, в течение которых оповещение будет храниться в журнале выполнения. По умолчанию установлено значение 90 дней;
- Тайм-аут при работе (Working Timeout)* – введите время в секундах, в течение которого может выполняться задание оповещения, прежде чем оно приведёт к автоматическому таймауту. По умолчанию установлено значение 3600 секунд;
- Льготный период (Grace Period) – введите количество секунд, которое должно пройти до того, как оповещение сработает, по сравнению с тем, когда было активировано предыдущее оповещение. Если оповещение сработает в течение этого периода, его статус будет На милость (On Grace), а оценка оповещения начнётся по истечении этого периода. По умолчанию установлено значение 14400 секунд.
7. Укажите Содержимое сообщения (Message Content)*. Для этого:
- Отметьте поле Дашборд (Dashboard) или График (Chart) и выберите из раскрывающегося списка необходимое значение. Кастомная ссылка будет подготовлена и отправлена на основе определённого метода уведомления;
- Если выбрано поле Дашборд, то при необходимости установите флажок Игнорировать кэш при создании скриншота (Ignore Cash when Generating Screenshort), чтобы получать некэшированные данные в реальном времени.
- Если выбрано поле График (Chart), то отметьте необходимый формат отправки уведомления:
- Отправить в формате PNG (Send as PNG);
- Отправить в формате CSV (Send as CSV);
- Send as Excel.
8. Укажите Метод уведомления (Notification method)*. Вы можете указать несколько методов. Для этого:
- Нажмите кнопку + Добавить метод уведомления (+ Add Notification Method);
- Выберите необходимый метод (Email или FTP) в отобразившемся раскрывающемся поле Выберите способ доставки (Select Delivery Method);
- В зависимости от выбора метода, в поле Email или FTP укажите одного или нескольких получателей уведомления используя разделители “,” или “;”.
9. Нажмите кнопку Добавить (Add) для завершения создания оповещения. После создания оповещение отобразится в общей таблице оповещений.
¶ 7.4 Создание отчета
В данном разделе, в качестве примера, будет описан процесс создания отчета со статистикой по пользователям, которая будет отправляться по электронной почте каждый день в 15:00. Для создания такого отчета:
1. Перейдите в Настройки (Settings) > Оповещения и отчеты (Alerts & Reports) > вкладка Отчеты (Reports).
2. Нажмите кнопку + Рассылка (+ Report). Откроется окно Добавить отчет (Add Report).
2. Укажите основные сведения о рассылке в следующих полях:
- Имя отчёта (Report Name)* – введите имя новой рассылки;
- Владельцы (Owners)* – выберите одного или нескольких владельцев рассылки. Владелец имеет возможность редактировать рассылку;
- Описание (Description) – введите описание рассылки;
- Переключатель Активный (Active) включается автоматически.
2. Настройте Расписание отчета (Report Schedule)* для определения того, как часто рассылка будет отправляться на определённый канал уведомлений. Для этого:
- Выберите из двух вариантов расписание условия оповещения:
- Каждый (Every)— позволяет указать детализированное расписание на основе необходимых требований. Данные можно проверять каждую минуту, час, день, неделю, месяц или год. После установки расписания, поле Расписание CRON (CRON Schedule) будет автоматически заполнено эквивалентным выражением CRON, представляющим указанное расписание;
- Расписание CRON (CRON Schedule) — укажите выражение CRON, соответствующее требуемому расписанию.
- В поле Часовой пояс (Timezone) выберите необходимый часовой пояс.
3. Укажите Настройки расписания (Schedule Settings) в следующих полях:
- Сохранение журнала (Log Retention)* – введите количество дней, в течение которых рассылка будет храниться в журнале выполнения. По умолчанию установлено значение 90 дней;
- Тайм-аут при работе (Working Timeout)* – введите время в секундах, в течение которого может выполняться задание рассылки, прежде чем оно приведёт к автоматическому таймауту. По умолчанию установлено значение 3600 секунд.
4. Укажите Содержимое сообщения (Message Content)*. Для этого:
- Отметьте поле Дашборд (Dashboard) или График (Chart) и выберите из раскрывающегося списка необходимое значение;
- При необходимости установите флажок Игнорировать кэш при создании скриншота (Ignore Cash when Generating Screenshort), чтобы получать некэшированные данные в реальном времени.
- Если выбрано поле График (Chart), то выберите необходимый формат отправки графика:
- Отправить в формате PNG (Send as PNG);
- Отправить в формате CSV (Send as CSV);
- Send as Excel.
5. Укажите Метод уведомления (Notification Method)*. Вы можете указать несколько методов. Для этого:
- Нажмите кнопку + Добавить метод уведомления (+ Add Notification Method);
- Выберите необходимый метод (Email или FTP) в раскрывающемся поле Выберите способ доставки (Select Delivery Method);
- В зависимости от выбора метода, в поле Email или FTP укажите одного или нескольких получателей уведомления используя разделители “,” или “;”.
9. Нажмите кнопку Добавить (Add) для завершения создания отчета. После создания отчет отобразится в общей таблице отчетов.
¶ 7.5 Настройка расписания из интерфейса дашборда или графика
Интерфейс дашборда или графика также позволяет запланировать рассылку отчета. Для этого:
1. Перейдите в разделы Дашборы или Графики и нажмите на название необходимого графика или дашборда. Откроется форма выбранного элемента.
2. Нажмите кнопку … и выберите пункт Настройте отчет по электронной почте (Set up an email report). Откроется окно Запланировать новый отчет по электронной почте (Schedule a new email report).
3. В открывшемся окне Запланировать новый отчет по электронной почте (Schedule a new email report) настройте рассылку:
- В поле Report Name* введите имя новой рассылки.
- В поле Описание (Description) введите краткое описание рассылки;
- Настройте расписание рассылки в разделе Параметры (Schedule):
- Укажите периодичность рассылки: Каждый (Every) – Год (Year), Месяц (Month), Неделя (Week), День (Day), Час (Hour), Минута (Minute);
- Выберите необходимый вариант расписания рассылки, предложенный планировщиком.
- В поле Часовой пояс (Timezone) выберите необходимый часовой пояс.
- При создании рассылки для графика укажите Содержимое сообщения (Message Content), выбрав один из предложенных вариантов:
- Изображение (PNG), встроенное в электронное письмо (Image (PNG) Embedded in Email) позволяет получить график в виде изображения, которое непосредственно встроено в тело сообщения электронной почты;
- Форматированный CSV, прикрепленный в электронном письме (Formatted CSV Attached in Email) позволяет получить необработанные данные графика в виде файла CSV, который будет прикреплён к электронному письму;
- Нажмите кнопку Добавить (Save).
Для проверки результата перейдите в Настройки (Settings ) > Оповещения и Отчеты (Alerts & Reports) > вкладка Отчеты (Reports) и убедитесь в наличии созданной рассылки.
¶ 7.6 Лог выполнения для просмотра ошибок
Лог выполнения — это список всех отдельных исполнений оповещения или рассылки. Для просмотра журнала выполнения:
1. Перейдите в Настройки (Settings ) > Оповещения и Отчеты (Alerts & Reports) на вкладку Оповещения (Alerts) или Отчеты (Reports).
2. Найдите необходимое оповещение или отчет и нажмите соответствующую ему кнопку Журнал выполнения (Execution Log), расположенную в столбце Действие (Activity). Откроется лог выполнения для выбранного оповещения или рассылки.
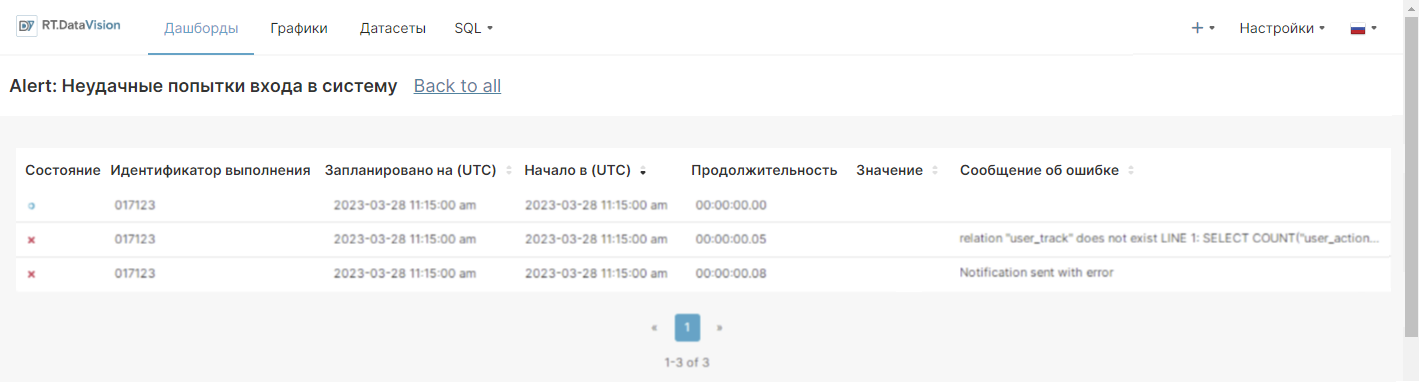
Описание столбцов в таблице лога:
- Состояние (State) — состояние операции, обозначенное значком (например, Рассылка отправлена (Report Sent), Рассылка выполняется (Report Sending) и прочие);
- Идентификатор выполнения (Execution ID) — идентификатор операции;
- Запланировано на (UTC) (Scheduled at) — дата и время, когда был запланирован запуск оповещения или рассылки (для отчета) или проверка условия срабатывания (для оповещения);
- Начало в (UTC) (Start at) — дата и время выполнения оповещения или рассылки;
- Продолжительность (Duration) — продолжительность выполнения операции;
- Значение (Value) — значение, возвращаемое определённым условием (для оповещения);
- Сообщение об ошибке (Error Message) — любые сообщения об ошибках, созданные при выполнении.
Определения значков:
- Синий кружок Alert running — оповещение активно выполнялось или было зарегистрировано как срабатывающее.
- Желтый треугольник Alert Triggered, In Grace Period или Alert Triggered, Notification Sent — пороговое значение оповещения было превышено, поэтому оповещение было активировано. В зависимости от установленного льготного периода оповещение могло привести к отправке уведомления.
- Красный крест Alert failed — оповещение не удалось успешно запустить.
- Зеленая галочка Nothing triggered — оповещение успешно выполнено, пороговое значение НЕ превышено.
Описание сообщений лога представлено ниже:
- Report Schedule is still working, refusing to re-compute — оповещение/рассылка начали свою оценку, но последнее состояние Working, поэтому оно отказывается продолжать. Предотвращает одновременные оповещения и рассылки, если предыдущий запрос оповещения занимает больше времени, чем фактический цикл cron, запросы могут начать накапливаться;
- Report Schedule reached a working timeout — оповещение/рассылка начали свою оценку, но последнее состояние Working, но он работает дольше, чем значение рабочего таймаута. Текущее состояние оповещения изменяется на Nothing triggered, чтобы отключить рабочее состояние;
- Alert fired during grace period — оценка оповещения началась, но её последним состоянием было Alert Triggered, если это состояние произошло в течение отсрочки. Затем оно не будет продолжаться и зарегистрирует это сообщение;
- Alert query returned more than one row — SQL-запрос оповещения должен возвращать только 1 строку;
- Alert query returned more then one column — SQL-запрос оповещения должен возвращать только 1 столбец;
- Alert query returned a non-number value — конфигурация оповещения проверяется числовым сравнением, но SQL вернул нечисловое значение (например, строку).
Все остальные сообщения должны быть ошибками из-за недопустимых SQL-запросов.
Если оповещение или рассылка не могут быть выполнены, владелец оповещения или рассылки получит уведомление по электронной почте (независимо от исходного метода уведомления) об ошибке. Получатели оповещений или рассылок не будут уведомлены об ошибках во время выполнения. Затем владельцы могут использовать логи для проверки сообщения об ошибке на предмет устранения.
¶ 7.7 Редактирование оповещения или отчета
Для редактирования оповещения или отчета:
1. Перейдите в Настройки (Settings ) > Оповещения и Отчеты (Alerts & Reports) на вкладку Оповещения (Alerts) или Отчеты (Reports).
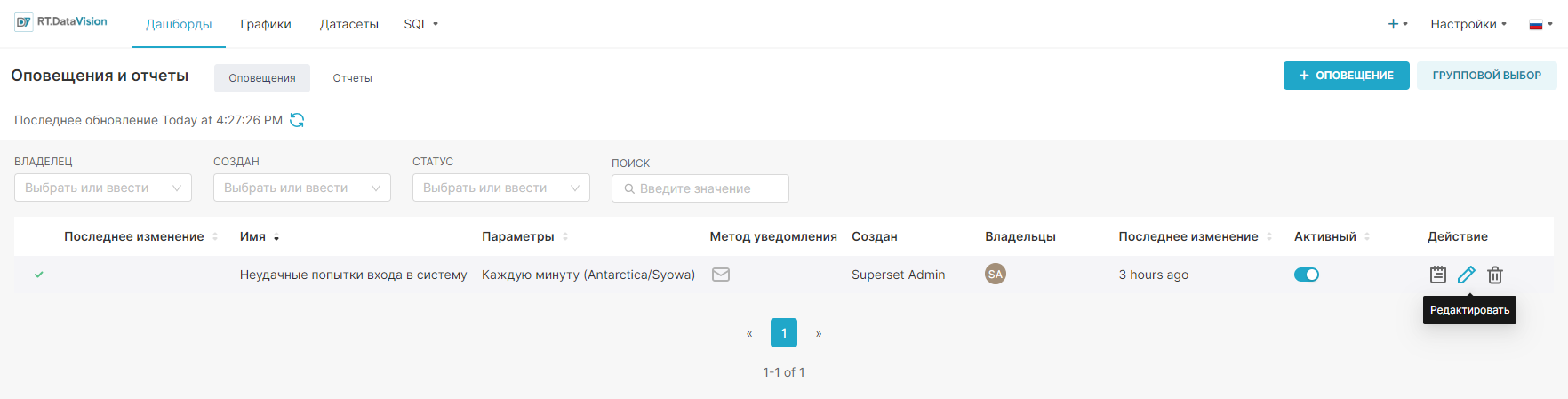
2. Найдите необходимое оповещение или отчет и нажмите соответствующую ему кнопку Редактировать (Edit), расположенную в столбце Действие (Activity). Откроется окно редактирования выбранного оповещения или отчета.
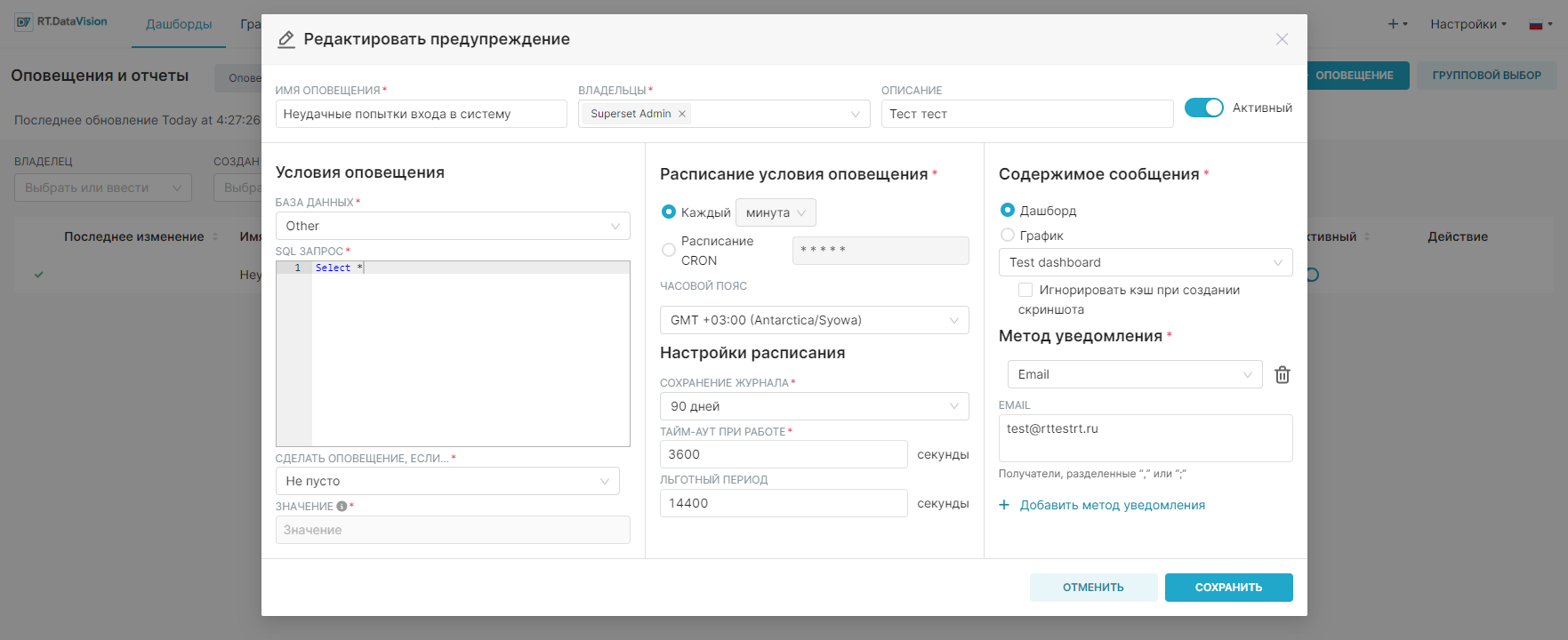
3. Внесите необходимые изменения и нажмите кнопку Сохранить (Save).
¶ 7.8 Удаление оповещения или отчета
Для удаления оповещения или отчета:
1. Перейдите в Настройки (Settings ) > Оповещения и Отчеты (Alerts & Reports) на вкладку Оповещения (Alerts) или Отчеты (Reports).
2. Найдите необходимое оповещение или отчет и нажмите соответствующую ему кнопку Удалить (Delete), расположенную в столбце Действие (Activity). Откроется окно удаления выбранного оповещения или отчета.
3. Для подтверждения действия введите УДАЛИТЬ и нажмите кнопку Удалить (Delete).
¶ 7.9 Массовое удаление оповещений или отчетов
Для массового удаления оповещений или отчетов:
1. Перейдите в Настройки (Settings ) > Оповещения и Отчеты (Alerts & Reports) на вкладку Оповещения (Alerts) или Отчеты (Reports).
2. Нажмите кнопку Групповой выбор (Bulk Select).
3. Отметьте флажками все записи, требующие удаления, и нажмите кнопку Удалить (Delete). Откроется окно подтверждения удаления.
4. Для подтверждения действия введите УДАЛИТЬ и нажмите кнопку Удалить (Delete).
¶ 7.10 Настройки в конфигурационном файле
Для корректной работы рассылки при использовании протокола HTTPS необходимо чтобы были выполнены следующие настройки в конфигурационном файле superset_config.py:
# В следующих переменных указывайте адрес с использованием протокола HTTPS и в формате FQDN
# Доменное имя должно быть прописано в сертификате безопасности
# Вся цепочка сертификатов должна быть размещена в хранилище сертификатов на сервере приложения
# Это ссылка для внутреннего использования
WEBDRIVER_BASEURL = "https://rtdatavision.mydomain.ru"
# Это ссылка, отправленная получателю
WEBDRIVER_BASEURL_USER_FRIENDLY = "https://rtdatavision.mydomain.ru"
# Конфигурация электронной почты
SMTP_HOST = "smtp.sendgrid.net" # замените на ваш хост
SMTP_STARTTLS = False
SMTP_SSL_SERVER_AUTH = False # если вы используете SMTP-сервер с валидным сертификатом
SMTP_SSL = False
SMTPUSER = "ваш_пользователь" # используйте пустую строку "" при использовании неаутентифицированного SMTP-сервера
SMTP_PORT = 25 # ваш порт, например 587
SMTP_PASSWORD = "ваш_пароль" # используйте пустую строку "" при использовании неаутентифицированного SMTP-сервера
SMTP_MAIL_FROM = "noreply@youremail.com"
SCREENSHOT_LOCATE_WAIT = 100
SCREENSHOT_LOAD_WAIT = 600
# Конфигурация веб-драйвера
# Если вы используете Firefox, вы можете придерживаться значений по умолчанию
# Если вы используете Chrome, добавьте следующие WEBDRIVER_TYPE и WEBDRIVER_OPTION_ARGS
WEBDRIVER_TYPE = "chrome"
WEBDRIVER_OPTION_ARGS = [
"--force-device-scale-factor=2.0",
"--high-dpi-support=2.0",
"--headless",
"--disable-gpu",
"--disable-dev-shm-usage",
"--no-sandbox",
"--disable-setuid-sandbox",
"--disable-extensions",
]
¶ 8 Шаблоны SQL
¶ 8.1 Шаблоны Jinja
Лаборатория SQL (SQL Lab) и Исследовать (Explore) поддерживает шаблоны Jinja в запросах. Чтобы включить шаблоны, необходимо включить флаг функции ENABLE_TEMPLATE_PROCESSING в superset_config.py. Когда шаблоны включены, python-код можно встраивать в виртуальные датасеты и в Custom SQL в фильтрах и элементах управления метриками в Исследовать (Explore). По умолчанию в контексте Jinja доступны следующие переменные:
- columns — столбцы, которые группируются в запросе;
- filter — фильтры, применяемые в запросе;
- from_dttm — начальное значение datetime из выбранного диапазона времени (None, если не определено);
- to_dttm — конечное значение datetime из выбранного диапазона времени (None, если не определено);
- groupby — столбцы, по которым группируется запрос [устарело];
- metrics — агрегатные выражения в запросе;
- row_limit — ограничение строки запроса;
- row_offset — смещение строки запроса;
- table_columns — столбцы, доступные в датасете;
- time_column — временной столбец запроса (None, если не определено);
- time_grain — выбранная гранулярность времени (None, если не определено).
Например, чтобы добавить диапазон времени в виртуальный датасет, вы можете написать следующее:
SELECT *
FROM tbl
WHERE dttm_col > '{{ from_dttm }}' and dttm_col < '{{ to_dttm }}'Можно использовать логику Jinja, чтобы сделать запрос устойчивым к очистке фильтра временного диапазона:
SELECT *
FROM tbl
WHERE (
{% if from_dttm is not none %}
dttm_col > '{{ from_dttm }}' AND
{% endif %}
{% if to_dttm is not none %}
dttm_col < '{{ to_dttm }}' AND
{% endif %}
true
)Обратите внимание, как параметры Jinja вызываются в двойных скобках в запросе и без в логических блоках.
Чтобы добавить кастомную функциональность в контекст Jinja, необходимо перегрузить контекст Jinja по умолчанию в среде, определив JINJA_CONTEXT_ADDONS в конфигурации RT.DataVision (superset_config.py). Объекты, на которые есть ссылки в справочнике, доступны для использования пользователями там, где доступен контекст Jinja.
JINJA_CONTEXT_ADDONS = {
'my_crazy_macro': lambda x: x*2,
}Значения по умолчанию для шаблонов Jinja можно указать в разделе Параметры (Parameters) в интерфейсе Лаборатории SQL (SQL Lab). В пользовательском интерфейсе вы можете назначить набор параметров в формате JSON. Чтобы указать параметры шаблона перейдите в раздел Лаборатория SQL (SQL Lab), нажмите на троеточие и выберите пункт Параметры (Parameters). Откроется форма Параметры шаблона (Template parameters):

{
"my_table": "foo"
}Параметры становятся доступными в вашем SQL (пример: SELECT * FROM {{ my_table }}) с помощью синтаксиса шаблонов Jinja. Параметры шаблона Лаборатории SQL (SQL Lab) хранятся вместе с датасетом как TEMPLATE PARAMETERS.
Существует специальный параметр _filters, который можно использовать для проверки фильтров, используемых в шаблоне Jinja.
Пример параметра:
{
"_filters": [
{
"col": "action_type",
"op": "IN",
"val": ["sell", "buy"]
}
]
}Пример запроса:
SELECT action, count(*) as times
FROM logs
WHERE action in {{ filter_values('action_type'))|where_in }}
GROUP BY actionПример запроса после обработки jinja:
SELECT count(*) AS count
FROM
(SELECT action,
count(*) as times
FROM "logs"
WHERE action_type in ("sell", "buy")
GROUP BY action) AS virtual_table
ORDER BY count DESC
LIMIT 1000;
Примечание. _filters не сохраняется вместе с датасетом. Он используется только в пользовательском интерфейсе Лаборатории SQL (SQL Lab).
Помимо шаблонов Jinja по умолчанию, Лаборатория SQL (SQL Lab) также поддерживает самоопределяемый процессор шаблонов, устанавливая CUSTOM_TEMPLATE_PROCESSORS в вашей конфигурации RT.DataVision. Значения в этом справочнике переопределяют процессоры шаблонов Jinja по умолчанию для указанного движка базы данных. В приведённом ниже примере настраивается кастомный процессор шаблонов presto, который имплементирует собственную логику обработки шаблона макроса с парсингом регулярных выражений (regex). Он использует макрос стиля $ вместо стиля {{ }} в шаблонах Jinja.
Настроив его с помощью CUSTOM_TEMPLATE_PROCESSORS, шаблон SQL в базе данных presto обрабатывается кастомным, а не шаблоном по умолчанию.
def DATE(
ts: datetime, day_offset: SupportsInt = 0, hour_offset: SupportsInt = 0
) -> str:
"""Текущий день в виде строки."""
day_offset, hour_offset = int(day_offset), int(hour_offset)
offset_day = (ts + timedelta(days=day_offset, hours=hour_offset)).date()
return str(offset_day)
class CustomPrestoTemplateProcessor(PrestoTemplateProcessor):
"""Кастомный процессор шаблонов presto."""
engine = "presto"
def process_template(self, sql: str, **kwargs) -> str:
"""Обрабатывает шаблон sql с макросом стиля $, используя регулярное выражение."""
# Добавляет кастомные функции макросов.
macros = {
"DATE": partial(DATE, datetime.utcnow())
} # type: Dict[str, Any]
# Обновляет с помощью макросов, определённых в context и kwargs.
macros.update(self.context)
macros.update(kwargs)
def replacer(match):
"""Расширяет макросы в стиле $ соответствующими вызовами функций."""
macro_name, args_str = match.groups()
args = [a.strip() for a in args_str.split(",")]
if args == [""]:
args = []
f = macros[macro_name[1:]]
return f(*args)
macro_names = ["$" + name for name in macros.keys()]
pattern = r"(%s)\s*\(([^()]*)\)" % "|".join(map(re.escape, macro_names))
return re.sub(pattern, replacer, sql)
CUSTOM_TEMPLATE_PROCESSORS = {
CustomPrestoTemplateProcessor.engine: CustomPrestoTemplateProcessor
}Лаборатория SQL (SQL Lab) также включает функцию валидации запросов в реальном времени с плагинами бэкенда. Вы можете сконфигурировать, какая имплементация валидации с каким движком базы данных используется, добавив блок, подобный следующему, в файл конфигурации:
FEATURE_FLAGS = {
'SQL_VALIDATORS_BY_ENGINE': {
'presto': 'PrestoDBSQLValidator',
}
}Доступные валидаторы можно найти в sql_validators.
¶ 8.1.1 Макросы Jinja
Макросы Jinja добавляются в двойных фигурных скобках ( {{ }} ). Параметры добавляются внутри круглых скобок:
{{ имя_макроса(параметр) }}Доступные следующие макросы:
- current_username() – возвращает имя пользователя, вошедшего в систему в данный момент;
- current_user_id() – возвращает user_id текущего пользователя, вошедшего в систему;
- url_param() – определяет произвольные параметры URL-адреса и ссылается на них в коде SQL.
- filter_values() – получает значение для определенного фильтра в виде списка;
- get_filters() – возвращает фильтры, примененные к данному столбцу.
¶ 8.1.1.1 Макрос current_username()
Макрос current_username() возвращает значение имени пользователя, вошедшего в систему. Это глобальное значение (одинаковое для всех рабочих областей) и оно не может быть изменено. Тип данных – String.
Пример:
SELECT * FROM sales WHERE employee = ' {{ current_username() }} 'Если в конфигурации RT DataVision включено кэширование, то по умолчанию значение username будет использоваться при вычислении ключа кэша. Для отключения включения значения username в вычисление ключа кэша необходимо добавить в код Jinja следующий параметр:
{{ current_username(add_to_cache_keys=False) }}
Примечание. Ключ кэша (cache key) — это уникальный идентификатор, который определяет, произойдет ли попадание в кэш и сможет ли RT DataVision получить кэшированные данные.
¶ 8.1.1.2 Макрос current_user_id()
Макрос current_user_id() возвращает значение идентификатора вошедшего в систему пользователя. Идентификатор является локальным для рабочей области (один пользователь будет иметь разные идентификаторы в каждой рабочей области) и не может быть изменен. Тип данных – Integer.
Пример:
SELECT * FROM sales WHERE employee_id = {{ current_user_id() }}Если в конфигурации RT DataVision включено кэширование, то по умолчанию значение user_id будет использоваться при вычислении ключа кэша. Для отключения включения значения user_id в вычисление ключа кэша необходимо добавить в код Jinja следующий параметр:
{{ current_user_id(add_to_cache_keys=False) }}¶ 8.1.1.3 Макрос url_param()
Макрос url_param() получает значения параметров из URL-адреса дашборда. При использовании этого макроса необходимо указать имя параметра. В URL-адресе можно указать несколько параметров с помощью “&”. Тип данных – String.
Пример:
URL-адрес дашборда: https://abcd1234.us2a.app.preset.io/superset/dashboard/1/?location=US&month=8
SELECT * FROM "Vehicle Sales"
WHERE country = '{{ url_param('location') }}' -- location — это имя параметра, указанное в URL-адресе.
AND month = {{ url_param('month') }} -- month – это имя параметра, указанное в URL-адресе.¶ 8.1.1.4 Макрос filter_values()
Макрос filter_values() возвращает информацию из фильтра дашборда. Для его использования необходимо указать имя столбца, на котором работает фильтр. Результатом будет массив всех примененных значений ( ["first_value_applied", "second_value_applied", ...]). Можно вернуть только определенную позицию (например, использовать [0] для возврата первого примененного значения) или использовать |where_in для возврата значений, разделенных запятыми, в кавычках.
Пример:
SELECT * FROM "Vehicle Sales"
WHERE country in ({{ filter_values('country')|where_in }})
-- country — это имя столбца, используемого в фильтре дашборда.
-- |where_in вернет результаты в правильном синтаксисе SQL -> 'США', 'Бельгия', 'Канада' вместо ['США', 'Бельгия', 'Канада']¶ 8.1.1.5 Макрос get_filters()
Макрос get_filters() возвращает фильтры, примененные к данному столбцу. Помимо возврата значений (аналогично тому, как это происходит в filter_values()), get_filters() возвращает оператор, указанный в пользовательском интерфейсе Explore.
Пример:
WITH RECURSIVE
superiors(employee_id, manager_id, full_name, level, lineage) AS (
SELECT
employee_id,
manager_id,
full_name,
1 as level,
employee_id as lineage
FROM employees
WHERE 1=1
{%- for filter in get_filters('full_name', remove_filter=True) -%}
{%- if filter.get('op') == 'IN' -%}
AND full_name IN {{ filter.get('val')|where_in }}
{%- endif -%}
{%- if filter.get('op') == 'LIKE' -%}
AND full_name LIKE {{ "'" + filter.get('val') + "'" }}
{%- endif -%}
{%- endfor -%}
UNION ALL
SELECT
e.employee_id,
e.manager_id,
e.full_name,
s.level + 1 as level,
s.lineage
FROM
employees e, superiors s
WHERE s.manager_id = e.employee_id
)
SELECT
employee_id,
manager_id,
full_name,
level,
lineage
FROM superiors
ORDER BY lineage, level¶ 8.1.1.6 Явное включение значений в ключ кэша
Функция {{ cache_key_wrapper() }} явно указывает RT.DataVision добавить значение в накопленный список значений, используемых при вычислении ключа кэша.
Эта функция необходима только в том случае, если вы хотите обернуть возвращаемые значения собственной кастомной функции в ключ кэша. Вы можете получить больше информации здесь.
Обратите внимание, что эта функция обеспечивает кэширование значений user_id и username в вызовах функций current_user_id() и current_username() (если у вас включено кэширование).
¶ 8.1.1.7 Датасеты
С помощью макроса dataset можно запрашивать физические и виртуальные датасеты.
Это может быть полезным, если вы определили вычисляемые столбцы и метрики в своих датасетах и хотите повторно использовать определение в adhoc-запросах SQL Lab.
Чтобы использовать макрос, сначала вам нужно найти идентификатор датасета. Это можно сделать, перейдя к представлению, показывающему все датасеты, наведя указатель мыши на интересующий вас датасет и просмотрев его URL-адрес. Например, если URL-адрес датасета https://superset.example.org/superset/explore/table/42/, его идентификатор равен 42.
Получив идентификатор, вы можете запросить его, как если бы это была таблица:
SELECT * FROM {{ dataset(42) }} LIMIT 10Если вы хотите выбрать определения метрик, помимо столбцов, вам необходимо передать дополнительный аргумент ключевого слова:
SELECT * FROM {{ dataset(42, include_metrics=True) }} LIMIT 10Поскольку метрики являются агрегатами, результирующее выражение SQL будет сгруппировано по всем столбцам, не являющимся метриками. Вместо этого вы можете указать подмножество столбцов для группировки:
SELECT * FROM {{ dataset(42, include_metrics=True, columns=["ds", "category"]) }} LIMIT 10¶ 8.1.2 Логические утверждения
Логические операторы можно использовать для выполнения различных действий на основе результатов проверки, а также для выполнения циклов итерации. Логический оператор должен быть добавлен внутри фигурных скобок и знака процента ({% %}). Всегда необходимо начинать и заканчивать блок:
{% if something %}
SQL syntax
{% else %}
SQL syntax
{% endif %}Пример:
SELECT * FROM "Vehicle Sales"
WHERE country
{% if filter_values('operation')[0] == 'Equals' %} -- выполняется, если первое значение, примененное к этому фильтру дашборда, равно "Equals"
= '{{ filter_values('location')[0] }}'
{% elif filter_values('operation') == 'In' %} -- если первое условие не выполнено, то проверяем установлено ли значение фильтра "In"
in ({{ filter_values('location')|where_in }})
{% else %} -- выполняется, если ни одно из вышеперечисленных условий не выполнено
not in ({{ filter_values('location')|where_in }})
{% endif %} -- завершающий блок¶ 9 SSH-туннелирование
Чтобы настроить SSH-туннелирование, выполните:
1. Включите флаг функции:
- Измените SSH_TUNNELING на True.
- Для повышения безопасности пользователям разрешается перезаписывать класс SSHTunnelManager здесь.
- Вы также можете установить SSH_TUNNEL_LOCAL_BIND_ADDRESS — адрес хоста, на котором туннель будет доступен на вашем VPC.
2. Создайте базу данных с включенным туннелем ssh.
- При включённом флаге функции вы должны увидеть переключатель SSH в окне Подключение к базе данных (Connect a database).
- Нажмите на переключатель, чтобы включить туннелирование SSH, и добавьте свои учётные данные соответствующим образом.
RT.DataVision позволяет использовать два разных типа аутентификации (базовый + закрытый ключ). Эти учётные данные должны быть получены от вашего провайдера услуг.
3. Убедитесь, что данные передаются.
- После включения туннелирования SSH перейдите в Лабораторию SQL (SQL Lab) и напишите запрос, чтобы убедиться, что данные передаются корректно.
¶ 10 Подключения к базам данных
¶ 10.1 Установка драйверов баз данных
Для работы RT.DataVision требуется установить драйверы базы данных Python DB-API и диалект SQLAlchemy для каждого хранилища данных, к которому вы хотите подключиться.
¶ 10.2 Поддерживаемые базы данных и зависимости
RT.DataVision не поставляется в комплекте с возможностью подключения к базам данных (исключения представлены ниже). Вам необходимо будет установить необходимые пакеты для базы данных, которую вы хотите использовать в качестве БД метаданных, а также пакеты, необходимые для подключения к базам данных, к которым вы хотите получить доступ через RT.DataVision.
Ниже представлен список баз данных, поддержка которых была протестирована в RT.DataVision и подключение к которым доступно “из коробки”:
- Dremio;
- Microsoft SQL Server;
- MySQL;
- Oracle;
- Postgres;
- SAP Hana.
О том, как подключить поддерживаемые “из коробки” БД, представленные в списке выше, и возможные для подключения к RT.DataVision БД, описано в п. 11 Настройки подключения БД. Общая информация о подключении БД дана в п. 10.3 Подключение к базе данных и п. 10.4 Расширенные настройки подключения БД.
Обратите внимание, что поддерживаются многие другие базы данных, основными критериями которых являются наличие функциональности диалекта SQLAlchemy и драйвера Python. Поиск по ключевым словам sqlalchemy + [имя базы данных] должен помочь вам найти необходимую информацию.
Если вы хотите создать коннектор базы данных для интеграции RT.DataVision, прочитайте следующее руководство.
¶ 10.3 Подключение к базе данных
¶ 10.3.1 Выбор базы данных
Чтобы выбрать базу данных, выполните следующее:
1. На панели инструментов наведите курсор на Настройки (Settings), а затем в раскрывающемся меню выберите Database Connections.
2. Откроется окно Базы данных (Databases), которое содержит список всех подключённых к RT.DataVision баз данных. Нажмите + База данных (+ Database).
2. Появится окно Подключение к базе данных (Connect a database). Выберите соответствующую плитку базы данных.
Или, если ваша база данных не входит в их число, выберите базу данных из раскрывающегося списка Поддерживаемые базы данных (Supported Databases).
Внимание. RT.DataVision “из коробки” поддерживает следующие базы данных: SQLite, PostgreSQL, Dremio, Oracle, MySQL, SAP Hana, ClickHouse, SQL Server.
Но вы можете подключить базы данных, перечисленные в пп. 11.1 — 11.44.
¶ 10.3.2 Способы подключения к БД
Вы можете настроить подключение к базе данных двумя следующими способами в зависимости от типа базы данных:
1. Через определение учётных данных для подключения — если вы подключаетесь к одной из следующих баз данных (Google BigQuery, PostgreSQL, Snowflake, MySQL, Amazon Redshift, Google Sheets), вы можете подключиться к ней, указав учётные данные (хост, порт и т.д.) и/или другие сведения о подключении.
2. Через предоставление URI SQLAlchemy — если вашей базы данных нет в списке выше, вы можете подключиться к ней, указав URI SQLAlchemy.
¶ 10.3.2.1 Способ 1. Определение учётных данных
Для демонстрации первого способа подключения к БД используется PostgreSQL. Выполните следующее:
1. Выберите в окне Подключение к базе данных (Connect a database) плитку PostgreSQL.
2. Откроется форма с полями для заполнения учётными данными.
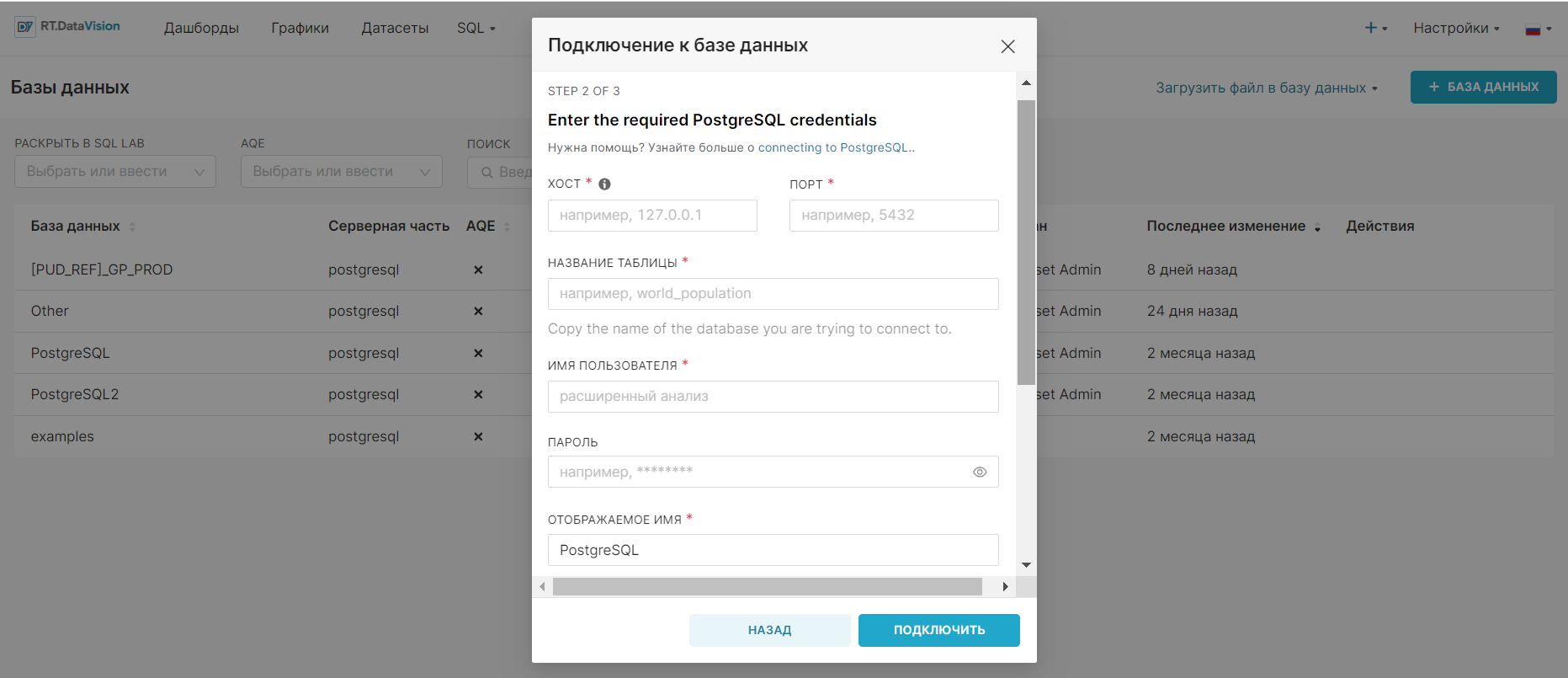
Поля для определения учётных данных включают (обязательные поля отмечены *):
- Хост (Host)* — хост, определяемый либо как IP-адрес, либо как домен;
- Порт (Port)*— введите релевантный номер порта для подключения. Если вы не знаете номер порта, используйте значение порта по умолчанию для базы данных. В этом случае используйте следующие значения по умолчанию: Redshift (порт по умолчанию — 5439), PostgreSQL (порт по умолчанию — 5432) и MySQL (порт по умолчанию — 3306);
- Название таблицы (Database name)* — имя базы данных, к которой вы подключаетесь;
- Имя пользователя (Username)* — имя пользователя, связанное с учётной записью пользователя;
- Пароль (Password) — пароль, связанный с учётной записью пользователя;
- Отображаемое имя (Display name)* — алиас для базы данных (используется для отображения в RT.DataVision);
- Дополнительные параметры (Additional parameters) — любые дополнительные пользовательские параметры, если это необходимо;
- SSL — можно активировать свитч, чтобы запрашивать SSL-подключение.
3. После заполнения полей нажмите Подключить (Connect), чтобы подключить базу данных PostgreSQL к RT.DataVision. Если значения полей были указаны корректно, то БД будет подключена.
Примечание. RT.DataVision может предложить указать дополнительные параметры конфигурации. Обратитесь за информацией к п. 10.4 Расширенные настройки подключения БД.
¶ 10.3.2.2 Способ 2. Предоставление SQLAlchemy URI
Большинство поддерживаемых баз данных подключаются через SQLAlchemy URI. Для получения детальной информации обратитесь к пп. 11.1 — 11.44.
Для демонстрации данного способа используется SQLite. Выполним следующее:
1. Выберите плитку SQLite в окне Подключение к базе данных (Connect a database).
2. Откроется форма для заполнения, на которой есть только два обязательных для заполнения поля Отображаемое имя (Display name)* и SQLAlchemy URI* для подключения к базе данных.
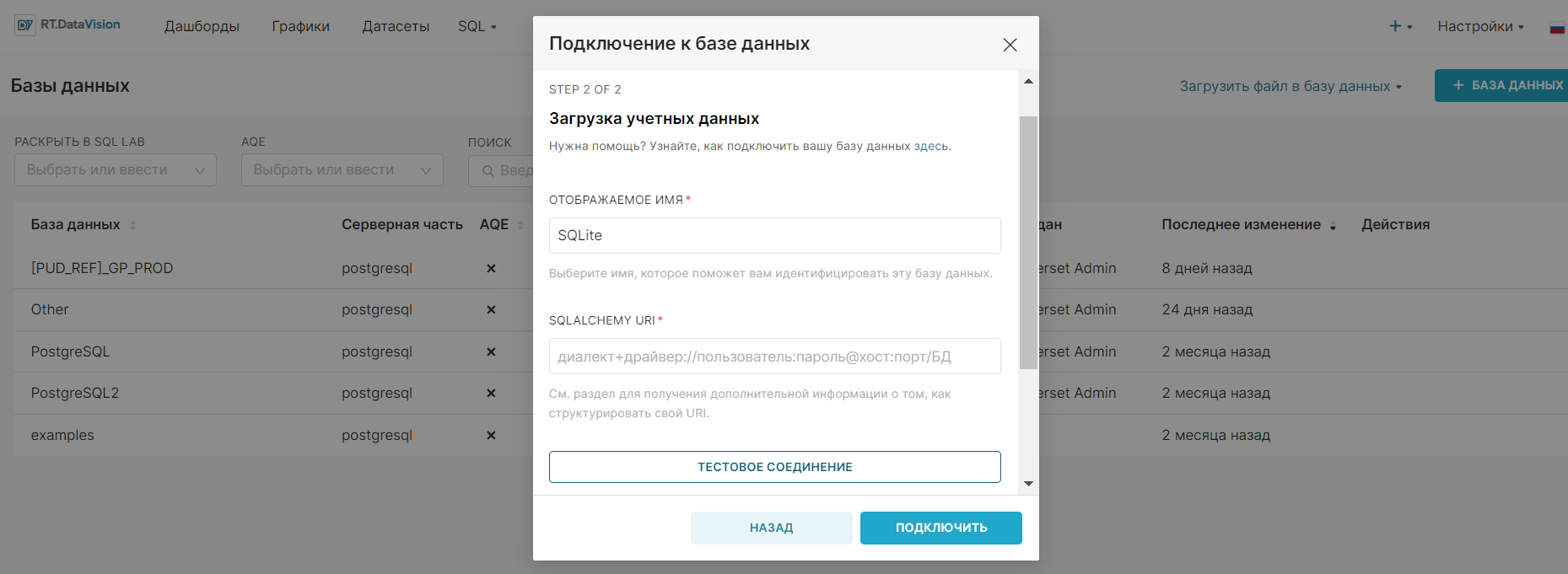
3. После заполнения формы нажмите Тестовое соединение (Test connection), чтобы проверить, работает ли подключение. Если подключение корректно, появится уведомление о валидном подключении.
4. Если никаких дополнительных настроек подключения не требуется, то нажмите Подключить (Connect). База данных SQLite будет подключена к RT.DataVision.
¶ 10.4 Расширенные настройки подключения БД
Иногда при желании вы можете настроить для подключения к базе данных дополнительные параметры. Но для некоторых баз данных настройка дополнительных параметров является обязательным требованием для осуществления подключения. Примером могут служить следующие БД:
- Databricks;
- Private Google Sheet;
- Apache Druid;
- Snowflake.
Давайте посмотрим, как использовать интерфейс дополнительных настроек.
¶ 10.4.1 Настройка расширенных параметров
Независимо от того, подключили ли вы свою базу данных, предоставив учётные данные или использовав URI SQLAlchemy, вам будет предоставлена возможность указать расширенные параметры в окне Подключение к базе данных (Connect a database).
Ниже будет подробно рассмотрена каждая группа расширенных параметров.
¶ 10.4.2 Расширенные параметры Лаборатории SQL
Для начала нажмите на группу Лаборатория SQL (SQL Lab) в окне Подключение к базе данных (Connect a database) на вкладке Расширенные (Advanced), чтобы развернуть группу. Отобразившиеся параметры Лаборатории SQL будут использоваться для настройки того, как ваша база данных будет взаимодействовать с Лабораторией SQL.
Расширенные параметры Лаборатории SQL содержат:
- Раскрыть базу данных в SQL Lab (Expose database in SQL Lab) — выберите, чтобы убедиться, что база данных доступна для выбора в инструменте SQL Lab. При выборе параметра предоставляется доступ к остальным параметрам конфигурации:
- Разрешить CREATE TABLE AS (Allow CREATE TABLE AS) — разрешает создание новых таблиц на основе запросов SQL;
- Разрешить CREATE TABLE AS (Allow CREATE VIEW AS) — разрешает создание новых представлений на основе запросов SQL;
- CTAS & CVAS SCHEMA — позволяет принудительно создавать все таблицы и представления в указанной в этом поле схеме при нажатии CTAS или CVAS в Лаборатории SQL (SQL Lab). Параметр становится доступным для заполнения, если активированы параметры Разрешить CREATE TABLE AS (Allow CREATE TABLE AS) и\или Разрешить CREATE TABLE AS (Allow CREATE VIEW AS);
- Разрешить DML (Allow DML) — позволяет использовать DML для управления базой данных с помощью операторов, отличных от SELECT, таких как UPDATE, DELETE и CREATE таблицы;
- Включить оценку стоимости запроса (Enable query cost estimation) — для Presto и PostgreSQL отображает кнопку, позволяющую вычислить стоимость запроса перед его выполнением;
- Разрешите исследовать эту базу данных (Allow this database to be explored) — позволяет пользователям визуализировать результаты Лаборатории SQL (SQL Lab) с помощью интерфейса Исследовать (Explore);
- Отключение запросов предварительного просмотра данных SQL Lab (Disable SQL Lab data preview queries) — позволяет отключить предварительный просмотр данных при извлечении метаданных таблицы в Лабораторию SQL (SQL Lab), чтобы избежать проблем с производительностью браузера при использовании баз данных с очень широкими таблицами.
¶ 10.4.3 Расширенные параметры производительности БД
Следующая группа Представления (Perfomance) используется для настройки параметров производительности вашей базы данных.
Параметры Представления (Perfomance) содержат:
- Таймаут кэша графика (Chart Cache Timeout) — устанавливает продолжительность таймаута кэширования для графиков этой базы данных в секундах. Таймаут, равный 0, указывает, что срок действия кэша никогда не истекает. Обратите внимание, что, если для этого параметра не установлено значение, то для этой базы данных будет использоваться глобальный параметр таймаута;
- Таймаут кэша схемы (Schema Cache Timeout) — устанавливает продолжительность таймаута кэширования метаданных для схем, используемых в этой базе данных, в секундах. Если для параметра не указать значение, то срок действия кэша никогда не истечёт;
- Таймаут кэша таблиц (Table Cache Timeout) — определяет продолжительность в секундах таймаута кэширования метаданных для таблиц, используемых в этой базе данных. Если для параметра не указать значение, то срок действия кэша никогда не истечёт;
- Асинхронное выполнение запроса (Asynchronous Query Execution) — позволяет включить запуск базы данных в асинхронном режиме. Это означает, что запросы выполняются на удалённых воркерах, а не на веб-сервере. Этот режим предполагает, что у вас есть настроен Celery-воркер, а также бэкенд результатов. Если эта функция включена, она может предотвратить ошибку 504 Time Out при выполнении запросов в Редакторе SQL (SQL Editor);
- Отмена запроса на событие выгрузки окна (Cancel query on window unload event) — позволяет прекращать выполнение запросов при закрытии окна браузера или переходе на другую страницу. Параметр доступен только для следующих баз данных: Presto, Hive, MySQL, PostgreSQL и Snowflake.
¶ 10.4.4 Расширенные параметры безопасности
Группа Безопасность (Security) используется для включения расширенных сведений о подключении в соответствии с типом вашей базы данных.
Расширенные параметры Безопасности (Security) позволяют:
- Безопасность (Secure Extra) — используется для ввода строки JSON с любыми дополнительными конфигурациями подключения. Параметр обычно требуется для систем, которые не соответствуют синтаксису username:password, используемому URI SQLAlchemy, например Hive, Presto и BigQuery;
- Корневой сертификат (Root Certificate) — используется для ввода любого необходимого содержимого CA_BUNDLE, необходимого для проверки HTTPS-запросов. Параметр доступен только для определённых движков баз данных;
- Выдать себя за вошедшего пользователя (Presto, Trino, Drill, Hive, and GSheets) (Impersonate logged in user (Presto, Trino, Drill, Hive, and GSheets)) — позволяет выполнять запросы из-под технической учётной записи, деперсонализируя текущего пользователя, вошедшего в систему;
- Allow data upload — позволяет пользователям загружать данные в схемы, определённые в параметре Schemas Allowed for File Upload. Если этот параметр включён, для пользователей без прав администратора будут отображаться параметры загрузки базы данных (Загрузить CSV (Upload a CSV), Загрузить фал со столбцами (Upload a Columnar File) и Загрузить файл Excel (Upload Excel));
- Schemas Allowed for File Upload — список схем, разделённых запятыми, в которые разрешено загружать файлы. Параметр становится доступным, если активирован параметр Allow data upload, позволяющий сам факт загрузки данных в схемы.
¶ 10.4.5 Другие расширенные параметры
Группа расширенных параметров Другое (Other) используется для указания дополнительных настроек (например, параметров и версий), если это необходимо.
Расширенные параметры группы Другое (Other):
- Параметры метаданных (Metadata Parameters) — позволяет ввести объект metadata_params, который будет распакован в вызове sqlalchemy.MetaData;
- Параметры движка (Engine Parameters) — позволяет ввести объект engine_params, который будет распакован в вызове sqlalchemy.create_engine;
- Версия (Version) — позволяет ввести версию вашей базы данных. Параметр необходим при использовании базы данных Presto, чтобы убедиться в правильности синтаксиса.
¶ 10.5 Настройка предпочтительных баз данных
Ниже представлен параметр конфигурации, в котором администратор может определить предпочтительные, выводимые в интерфейсе базы данных:
# Список предпочитаемых баз данных по порядку.
# Эти базы данных будут отображаться в окне Подключение к базе данных (Connect a database).
# Используйте атрибут "engine_name" соответствующей спецификации движка БД в `superset/db_engine_specs/`.
PREFERRED_DATABASES: List[str] = [
"PostgreSQL",
"Presto",
"MySQL",
"SQLite",
]
Примечание. По причинам авторского права логотипы для каждой базы данных не распространяются вместе с RT.DataVision.
¶ 10.6 Настройка изображений
Чтобы настроить изображение предпочитаемой базы данных, администраторы должны создать маппинг в файле superset_text.yml с движком и расположением изображения. Изображение может быть размещено локально внутри вашего статического\файлового каталога или онлайн (например, S3).
DB_IMAGES:
postgresql: "path/to/image/postgres.jpg"
bigquery: "path/to/s3bucket/bigquery.jpg"
snowflake: "path/to/image/snowflake.jpg"¶ 10.7 Добавление новых движков баз данных в эндпоинт доступных
В настоящее время поддерживаются следующие базы данных:
- Postgres.
- Redshift.
- MySQL.
- BigQuery.
Когда пользователь выбирает базу данных, которой нет в данном списке, он увидит устаревшее диалоговое окно, запрашивающее URI SQLAlchemy. Новые базы данных можно добавлять постепенно в новый поток. Для поддержки расширенной конфигурации спецификация ядра БД должна иметь следующие атрибуты:
- parameters_schema — схема Marshmallow, определяющая параметры, необходимые для конфигурирования базы данных. Для Postgres это включает имя пользователя, пароль, хост, порт и т.д. (описание).
- default_driver — имя рекомендуемого драйвера для спецификации движка БД. Многие диалекты SQLAlchemy поддерживают несколько драйверов, но обычно один из них является официальной рекомендацией. Для Postgres используется psycopg2.
- sqlalchemy_uri_placeholder — строка, которая помогает пользователю ввести URI напрямую.
- encryption_parameters — параметры, используемые для создания URI, когда пользователь выбирает зашифрованное соединение. Для Postgres это {"sslmode": "require"}.
Кроме того, спецификация движка БД должна имплементировать следующие методы класса:
- build_sqlalchemy_uri(cls, parameters, encrypted_extra) — метод получает отдельные параметры и строит из них URI.
- get_parameters_from_uri(cls, uri, encrypted_extra) — метод делает обратное, извлекая параметры из заданного URI.
- validate_parameters(cls, parameters) — метод используется для валидации onBlur формы. Он должен вернуть список SupersetError, указывающий, какие параметры отсутствуют, а какие параметры явно некорректны (пример).
Для таких баз данных, как MySQL и Postgres, которые используют стандартный формат engine+driver://user:password@host:port/dbname, всё, что вам нужно сделать, это добавить BasicParametersMixin в спецификацию движка БД, а затем определить параметры 2-4 из перечня выше (parameters_schema уже присутствует).
Для других баз данных вам необходимо имплементировать методы самостоятельно. Спецификация движка BigQuery DB — хороший пример того, как это сделать.
¶ 11 Настройки подключения БД
¶ 11.1 Amazon Athena
¶ 11.1.1 PyAthenaJDBC
PyAthenaJDBC — это оболочка, совместимая с Python DB 2.0, для драйвера JDBC Amazon Athena.
Пакет PyPI для установки БД:
pip install "PyAthenaJDBC>1.0.9
Строка подключения для Amazon Athena выглядит следующим образом:
awsathena+jdbc://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...Обратите внимание, что вам нужно будет экранировать и кодировать при формировании строки подключения следующим образом:
s3://... -> s3%3A//...¶ 11.1.2 PyAthena
Вы также можете использовать библиотеку PyAthena (Java не требуется).
Пакет PyPI для установки БД используется следующий:
pip install "PyAthena>1.2.0И следующая строка подключения:
awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...¶ 11.2 Amazon DynamoDB
¶ 11.2.1 PyDynamoDB
PyDynamoDB — клиент Python DB API 2.0 (PEP 249) для Amazon DynamoDB.
Пакет PyPI для установки Amazon DynamoDB:
pip install pydynamodbСтрока подключения для Amazon DynamoDB выглядит следующим образом:
dynamodb://{aws_access_key_id}:{aws_secret_access_key}@dynamodb.{region_name}.amazonaws.com:443?connector=supersetЧтобы получить дополнительную информацию, обратитесь к PyDynamoDB WIKI.
¶ 11.3 Amazon Redshift
Библиотека sqlalchemy-redshift — рекомендуемый способ подключения к Redshift через SQLAlchemy.
Для корректной работы этого диалекта требуется либо redshift_connector, либо psycopg2.
Пакет PyPI для установки Redshift:
pip install sqlalchemy-redshiftДля формирования строки подключения вам понадобятся следующие значения параметров:
- userName — имя пользователя;
- DBPassword — пароль;
- AWS End Point — хост базы данных;
- Database Name — имя базы данных;
- Port — по умолчанию 5439.
¶ 11.3.1 psycopg2
Вот как выглядит URI SQLAlchemy:
redshift+psycopg2://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name>¶ 11.3.2 redshift_connector
Вот как выглядит URI SQLAlchemy:
redshift+redshift_connector://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name>¶ 11.3.2.1 Использование учётных данных на основе IAM с кластером Redshift
Кластер Amazon Redshift также поддерживает создание временных учётных данных пользователя базы данных на основе IAM.
Роль IAM вашего приложения RT.DataVision должна иметь разрешения на вызов операции redshift:GetClusterCredentials.
Вам необходимо определить следующие аргументы для подключения БД Redshift в интерфейсе окно Подключение к базе данных (Connect a database) > вкладка Расширенные (Advanced) > Другое (Other) > Параметры движка (Engine Parameters):
{"connect_args":{"iam":true,"database":"<database>","cluster_identifier":"<cluster_identifier>","db_user":"<db_user>"}}И URI SQLAlchemy должен быть установлен на:
redshift+redshift_connector://¶ 11.3.2.2 Использование учётных данных на основе IAM с бессерверной системой Redshift:
Бессерверная система Redshift поддерживает подключение с использованием ролей IAM.
Роль IAM вашего приложения RT.DataVision должна иметь разрешения redshift-serverless:GetCredentials и redshift-serverless:GetWorkgroup для бессерверной рабочей группы Redshift.
Вам необходимо определить следующие аргументы для подключения БД Redshift в интерфейсе: окно Подключение к базе данных (Connect a database) > вкладка Расширенные (Advanced) > Другое (Other) > Параметры движка (Engine Parameters):
{"connect_args":{"iam":true,"is_serverless":true,"serverless_acct_id":"<aws account number>","serverless_work_group":"<redshift work group>","database":"<database>","user":"IAMR:<superset iam role name>"}}¶ 11.4 Apache Doris
Библиотека sqlalchemy-doris — рекомендуемый способ подключения к Apache Doris через SQLAlchemy.
Пакет PyPI для установки Doris:
pip install pydorisДля формирования строки подключения вам потребуются следующие значения параметров:
- User — имя пользователя;
- Password — пароль;
- Host — хост Doris FE;
- Port — порт Doris FE;
- Catalog — название каталога;
- Database — имя базы данных.
Вот как выглядит строка подключения:
doris://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database>¶ 11.5 Apache Drill
¶ 11.5.1 SQLAlchemy
Рекомендуемый способ подключения к Apache Drill — через SQLAlchemy. Вы можете использовать пакет sqlalchemy-drill:
pip install sqlalchemy-drillКак только это будет сделано, вы можете подключиться к Drill двумя способами: либо через интерфейс REST, либо с помощью JDBC. Если вы подключаетесь через JDBC, у вас должен быть установлен драйвер Drill JDBC.
Базовая строка подключения для Drill выглядит так:
drill+sadrill://<username>:<password>@<host>:<port>/<storage_plugin>?use_ssl=TrueЧтобы подключиться к Drill, работающему на локальной машине, работающей во встроенном режиме, вы можете использовать следующую строку подключения:
drill+sadrill://localhost:8047/dfs?use_ssl=False¶ 11.5.2 JDBC
Подключение к Drill через JDBC является более сложным, рекомендуется следовать этому руководству.
Строка подключения выглядит так:
drill+jdbc://<username>:<password>@<host>:<port>¶ 11.5.3 ODBC
Рекомендуется прочитать документацию Apache Drill и прочитать файл README GitHub, чтобы узнать, как работать с Drill через ODBC.
¶ 11.6 Apache Druid
Родной коннектор для Druid поставляется с RT.DataVision (флаг DRUID_IS_ACTIVE).
Но он постепенно устаревает в пользу коннектора SQLAlchemy/DBAPI, доступного в библиотеке pydruid:
pip install pydruidСтрока подключения выглядит так:
druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sqlНиже разбивка ключевых компонентов этой строки подключения:
- User — имя пользователя, часть учётных данных, необходимых для подключения к вашей базе данных;
- Password — пароль, часть учётных данных, необходимых для подключения к вашей базе данных;
- Host — IP-адрес (или URL-адрес) хост-машины, на которой работает ваша база данных;
- Port — конкретный порт, который открыт на вашей хост-машине, на которой работает ваша база данных.
¶ 11.6.1 Настройка подключения к Druid
При добавлении подключения к Druid вы можете настроить подключение несколькими способами в окне Подключение к базе данных (Connect a database).
¶ 11.6.1.1 Кастомный сертификат
Вы можете добавить сертификаты в поле Корневой сертификат (Root Certificate) при конфигурировании нового подключения базы данных к Druid.

При использовании кастомного сертификата pydruid автоматически использует схему https.
¶ 11.6.1.2 Отключение проверки SSL
Чтобы отключить проверку SSL, добавьте следующее в поле Extras:
engine_params:
{"connect_args":
{"scheme": "https", "ssl_verify_cert": false}}¶ 11.6.2 Агрегации
Общие агрегации или метрики Druid могут быть определены и использованы в RT.DataVision. Первый и более простой вариант использования — использовать матрицу чекбоксов, отображаемую в редактируемом представлении источника данных (окно Подключение к базе данных (Connect a database) → вкладка Список столбцов Druid (List Druid Column)).
Если отметить чекбоксы GroupBy и Filterable, столбец появится в соответствующих раскрывающихся списках в представлении Исследовать (Explore). Отметки в Count Distinct, Min, Max или Sum приведут к созданию новых метрик, которые появятся на вкладке Список показателей Druid (List Druid Metric) после сохранения источника данных.
После редактирования этих метрик их элемент JSON будет соответствовать определению агрегации Druid. Вы можете создать свои собственные агрегации вручную на вкладке Список показателей Druid (List Druid Metric), следуя документации Druid.
¶ 11.6.3 Постагрегации
Druid поддерживает постагрегацию, и это работает в RT.DataVision. Всё, что вам нужно сделать, это создать метрику, как если бы вы создавали агрегацию вручную, но указать postagg для Metric Type. Затем вы должны предоставить валидное определение постагрегации json (как указано в документации Druid) в поле JSON.
¶ 11.7 Apache Hive
Библиотека pyhive — рекомендуемый способ подключения к Hive через SQLAlchemy:
pip install pyhiveОжидаемая строка подключения имеет следующий формат:
hive://hive@{hostname}:{port}/{database}¶ 11.8 Apache Impala
Рекомендуемая библиотека подключения к Apache Impala — impyla:
pip install impylaОжидаемая строка подключения имеет следующий формат:
impala://{hostname}:{port}/{database}¶ 11.9 Apache Kylin
Рекомендуемая библиотека коннекторов для Apache Kylin — kylinpy:
pip install kylinpyОжидаемая строка подключения имеет следующий формат:
kylin://<username>:<password>@<hostname>:<port>/<project>?<param1>=<value1>&<param2>=<value2>¶ 11.10 Apache Pinot
Рекомендуемая библиотека коннекторов для Apache Pinot — pinotdb:
pip install pinotdbОжидаемая строка подключения имеет следующий формат:
pinot+http://<pinot-broker-host>:<pinot-broker-port>/query?controller=http://<pinot-controller-host>:<pinot-controller-port>/``Ожидаемая строка подключения с использованием имени пользователя и пароля имеет следующий формат:
pinot://<username>:<password>@<pinot-broker-host>:<pinot-broker-port>/query/sql?controller=http://<pinot-controller-host>:<pinot-controller-port>/verify_ssl=true``¶ 11.11 Apache Solr
Библиотека sqlalchemy-solr предоставляет интерфейс Python\SQLAlchemy для Apache Solr:
pip install sqlalchemy-solrСтрока подключения для Solr выглядит так:
solr://{username}:{password}@{host}:{port}/{server_path}/{collection}[/?use_ssl=true|false]¶ 11.12 Apache Spark SQL
Рекомендуемая библиотека коннекторов для Apache Spark SQL — pyhive:
pip install pyhiveОжидаемая строка подключения имеет следующий формат:
hive://hive@{hostname}:{port}/{database}¶ 11.13 Ascend.io
Рекомендуемая библиотека коннекторов к Ascend.io — impyla:
pip install impylaОжидаемая строка подключения имеет следующий формат:
ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true¶ 11.14 ClickHouse
Чтобы использовать ClickHouse с RT.DataVision, вам потребуется добавить следующую библиотеку Python:
clickhouse-connect>=0.6.8Если вы запускаете RT.DataVision с помощью Docker Compose, добавьте в файл ./docker/requirements-local.txt следующее:
clickhouse-connect>=0.6.8Рекомендуемая библиотека коннекторов для ClickHouse — clickhouse-connect:
pip install clickhouse-connectОжидаемая строка подключения имеет следующий формат:
clickhousedb://<user>:<password>@<host>:<port>/<database>[?options…]clickhouse://{username}:{password}@{hostname}:{port}/{database}Вот пример реальной строки подключения:
clickhousedb://demo:demo@github.demo.trial.altinity.cloud/default?secure=trueЕсли вы используете Clickhouse локально на своем компьютере, вы можете обойтись без использования http-протокола в URL-адресе, который использует пользователя по умолчанию без пароля (и не шифрует соединение):
clickhousedb://localhost/default¶ 11.15 CockroachDB
Рекомендуемая библиотека коннекторов для CockroachDB — sqlalchemy-cockroachdb:
pip install cockroachdbОжидаемая строка подключения имеет следующий формат:
cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable¶ 11.16 CrateDB
Рекомендуемая библиотека коннекторов для CrateDB — crate.
Вам также необходимо установить дополнительные компоненты для этой библиотеки. Рекомендуется добавить в файл требований примерно следующий текст:
crate[sqlalchemy]==0.26.0Ожидаемая строка подключения имеет следующий формат:
crate://crate@127.0.0.1:4200¶ 11.17 Databend
Рекомендуемая библиотека коннекторов для Databend — databend-sqlalchemy. RT.DataVision был протестирован на databend-sqlalchemy>=0.2.3.
Рекомендуемая строка подключения:
databend://{username}:{password}@{host}:{port}/{database_name}Вот пример строки подключения RT.DataVision к базе данных Databend:
databend://user:password@localhost:8000/default?secure=false¶ 11.18 Databricks
Databricks предлагает собственный драйвер DB API 2.0, databricks-sql-connector, который можно использовать с диалектом sqlalchemy-databricks. Вы можете установить оба с помощью:
pip install "apache-superset[databricks]"Чтобы использовать коннектор Hive, вам потребуется следующая информация из вашего кластера:
- Имя хоста сервера;
- Порт;
- HTTP-путь.
Получив всю эту информацию, добавьте базу данных типа Databricks Native Connector и используйте следующий URI SQLAlchemy:
databricks+connector://token:{access_token}@{server_hostname}:{port}/{database_name}Вам также необходимо добавить следующую конфигурацию в окно Подключение к базе данных (Connect a database) > вкладка Расширенные (Advanced) > Другое (Other) > поле Engine Parameters с указанием вашего HTTP-пути:
{
"connect_args": {"http_path": "sql/protocolv1/o/****"}
}¶ 11.18.1 Устаревший драйвер
Первоначально RT.DataVision использовал databricks-dbapi для подключения к Databricks. Вы можете попробовать его, если у вас возникли проблемы с официальным коннектором Databricks:
pip install "databricks-dbapi[sqlalchemy]"Существует два способа подключения к Databricks при использовании databricks-dbapi: с помощью коннектора Hive или коннектора ODBC. Оба способа работают одинаково, но для подключения к эндпоинтам SQL можно использовать только ODBC.
¶ 11.18.1.1 Hive
Чтобы подключиться к кластеру Hive, добавьте базу данных типа Databricks Interactive Cluster в RT.DataVision и используйте следующий URI SQLAlchemy:
databricks+pyhive://token:{access_token}@{server_hostname}:{port}/{database_name}Вам также необходимо добавить следующую конфигурацию в окно Подключение к базе данных (Connect a database) → вкладка Расширенные (Advanced) → Другое (Other) → поле Engine Parameters с указанием вашего HTTP-пути:
{"connect_args": {"http_path": "sql/protocolv1/o/****"}}¶ 11.18.1.2 ODBC
Для ODBC сначала необходимо установить драйверы ODBC для вашей платформы.
Для обычного подключения используйте следующее в качестве URI SQLAlchemy после выбора Databricks Interactive Cluster или Databricks SQL Endpoint для базы данных, в зависимости от вашего варианта использования:
databricks+pyodbc://token:{access_token}@{server_hostname}:{port}/{database_name}И для аргументов подключения:
{"connect_args": {"http_path": "sql/protocolv1/o/****", "driver_path": "/path/to/odbc/driver"}}Путь к драйверу должен быть:
- /Library/simba/spark/lib/libsparkodbc_sbu.dylib — для Mac OS.
- /opt/simba/spark/lib/64/libsparkodbc_sb64.so — Linux.
Для подключения к эндпоинту SQL вам необходимо использовать HTTP-путь от эндпоинта:
{"connect_args": {"http_path": "/sql/1.0/endpoints/****", "driver_path": "/path/to/odbc/driver"}}¶ 11.19 Dremio
Рекомендуемая библиотека коннекторов для Dremio — sqlalchemy_dremio:
pip install sqlalchemy_dremioОжидаемая строка подключения для ODBC (порт по умолчанию — 31010) имеет следующий формат:
dremio://{username}:{password}@{host}:{port}/{database_name}/dremio?SSL=1Ожидаемая строка подключения для Arrow Flight (Dremio 4.9.1+, порт по умолчанию — 32010) имеет следующий формат:
dremio+flight://{username}:{password}@{host}:{port}/dremioДанный пост в блоге от Dremio содержит дополнительные полезные инструкции по подключению RT.DataVision к Dremio.
¶ 11.20 Elasticsearch
Рекомендуемая библиотека коннекторов для Elasticsearch — elasticsearch-dbapi:
pip install elasticsearch-dbapiСтрока подключения для Elasticsearch выглядит так:
elasticsearch+http://{user}:{password}@{host}:9200/¶ 11.20.1 Использование HTTPS
elasticsearch+https://{user}:{password}@{host}:9200/Elasticsearch имеет ограничение по умолчанию в 10000 строк, поэтому вы можете увеличить это ограничение в своём кластере или установить ограничение строк RT.DataVision в конфигурации.
ROW_LIMIT = 10000Например, вы можете запросить несколько индексов в Лаборатории SQL (SQL Lab).
SELECT timestamp, agent FROM "logstash"Но чтобы использовать визуализации для нескольких индексов, вам необходимо создать индекс алиаса в вашем кластере.
POST /_aliases
{
"actions" : [
{ "add" : { "index" : "logstash-**", "alias" : "logstash_all" } }
]
}Затем зарегистрируйте свою таблицу с алиасом logstash_all.
¶ 11.20.2 Часовой пояс
По умолчанию RT.DataVision использует часовой пояс UTC для запроса Elasticsearch. Если вам нужно уточнить часовой пояс, внесите изменения в подключённую базу данных в окне Подключение к базе данных (Connect a database) и введите настройки указанного часового пояса в параметре по пути: вкладка Расширенные (Advanced) > Другое (Other) > Параметры движка (Engine Parameters):
{
"connect_args": {
"time_zone": "Asia/Shanghai"
}
}Ещё одна проблема, связанная с часовым поясом, заключается в том, что до версии elasticsearch7.8, если вы хотите преобразовать строку в объект DATETIME, вам нужно использовать функцию CAST, но эта функция не поддерживает настройку time_zone. Поэтому рекомендуется обновиться до более поздней версии чем elasticsearch7.8. С версией более elasticsearch7.8 вы можете использовать функцию DATETIME_PARSE для решения этой проблемы. Функция DATETIME_PARSE предназначена для поддержки параметра time_zone, при этом вам необходимо указать номер версии elasticsearch в параметре по пути: вкладка Расширенные (Advanced) > Другое (Other) > поле Версия (Version). RT.DataVision будет использовать для преобразования функцию DATETIME_PARSE.
¶ 11.20.3 Отключение верификации SSL
Чтобы отключить верификацию SSL, добавьте следующее в параметр по пути: окно Подключение к базе данных (Connect a database) > вкладка Базовые (Basic) > поле SQLAlchemy URI:
elasticsearch+https://{user}:{password}@{host}:9200/?verify_certs=False¶ 11.21 Exasol
Рекомендуемая библиотека коннекторов для Exasol — sqlalchemy-exasol:
pip install sqlalchemy-exasolСтрока подключения для Exasol выглядит так:
exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC¶ 11.22 Firebird
Рекомендуемая библиотека коннекторов для Firebird — sqlalchemy-firebird. RT.DataVision протестирован на sqlalchemy-firebird>=0.7.0, <0.8.
Рекомендуемая строка подключения:
firebird+fdb://{username}:{password}@{host}:{port}//{path_to_db_file}Вот пример строки подключения RT.DataVision к локальной базе данных Firebird:
firebird+fdb://SYSDBA:masterkey@192.168.86.38:3050//Library/Frameworks/Firebird.framework/Versions/A/Resources/examples/empbuild/employee.fdb¶ 11.23 Firebolt
Рекомендуемая библиотека коннекторов для Firebolt — firebolt-sqlalchemy. RT.DataVision протестирован на firebolt-sqlalchemy>=0.0.1.
Рекомендуемая строка подключения:
firebolt://{username}:{password}@{database}?account_name={name}
или
firebolt://{username}:{password}@{database}/{engine_name}?account_name={name}Также возможно подключение с использованием аккаунта сервиса:
firebolt://{client_id}:{client_secret}@{database}?account_name={name}
или
firebolt://{client_id}:{client_secret}@{database}/{engine_name}?account_name={name}¶ 11.24 Google BigQuery
Рекомендуемая библиотека коннекторов для BigQuery — sqlalchemy-bigquery:
pip install shillelagh[gsheetsapi]¶ 11.24.1 Подключение к BigQuery
При добавлении нового подключения BigQuery в RT.DataVision вам потребуется добавить файл учётных данных аккаунта сервиса GCP (в формате JSON).
1. Создайте свой аккаунт сервиса через панель управления Google Cloud Platform, предоставьте ей доступ к соответствующим датасетам BigQuery и загрузите файл конфигурации JSON для аккаунта сервиса.
2. В RT.DataVision вы можете:
- загрузить этот JSON — в окне Подключение к базе данных (Connect a database) в поле How do you want to enter service account credentials* выберите значение Upload JSON file, а затем в поле Upload credentials* загрузите JSON.
- добавить blob JSON в следующем формате — в окне Подключение к базе данных (Connect a database) в поле How do you want to enter service account credentials* выберите значение Copy and paste JSON credentials, а затем в поле Service account* вставьте содержимое вашего JSON-файла учётных данных.
{
"type": "service_account",
"project_id": "...",
"private_key_id": "...",
"private_key": "...",
"client_email": "...",
"client_id": "...",
"auth_uri": "...",
"token_uri": "...",
"auth_provider_x509_cert_url": "...",
"client_x509_cert_url": "..."
}3. Или вместо этого вы можете подключиться через SQLAlchemy URI.
- В этом случае строка подключения для BigQuery выглядит так:
bigquery://{project_id}
- В окне Подключение к базе данных (Connect a database) добавьте blob JSON по пути: вкладка Расширенные (Advanced) > Безопасность (Security) > поле Secure Extra в форме конфигурации базы данных в следующем формате:
{
"credentials_info": <contents of credentials JSON file>
}Полученный файл должен иметь следующую структуру:
{
"credentials_info": {
"type": "service_account",
"project_id": "...",
"private_key_id": "...",
"private_key": "...",
"client_email": "...",
"client_id": "...",
"auth_uri": "...",
"token_uri": "...",
"auth_provider_x509_cert_url": "...",
"client_x509_cert_url": "..."
}
}После этого вы сможете подключиться к своим датасетам BigQuery.
Чтобы иметь возможность загружать файлы CSV или Excel в BigQuery в RT.DataVision, вам также необходимо добавить библиотеку pandas_gbq.
В настоящее время sdk Python Google BigQuery несовместим с gevent из-за динамических свойств манкипатчинга в основной библиотеке Python со стороны gevent. Итак, когда вы развёртываете RT.DataVision с сервером gunicorn, вам необходимо использовать отличный от gevent тип воркера.
¶ 11.25 Google Sheets
Google Sheets имеют очень ограниченный SQL API. Рекомендуемая библиотека коннекторов для Google Sheets — shillelagh:
pip install shillelagh[gsheetsapi]Чтобы подключить RT.DataVision к Google Sheets, необходимо выполнить несколько шагов. Данная инструкция содержит самые последние инструкции по настройке подключения.
¶ 11.26 Hologres
Hologres — интерактивный аналитический сервис в режиме реального времени, разработанный Alibaba Cloud. Он полностью совместим с PostgreSQL 11 и легко интегрируется с экосистемой больших данных:
pip install psycopg2Строка подключения выглядит так:
postgresql+psycopg2://{username}:{password}@{host}:{port}/{database}Параметры подключения Hologres:
- username — ID AccessKey вашей учётной записи Alibaba Cloud;
- password — секрет AccessKey вашей учётной записи Alibaba Cloud;
- host — общедоступный эндпоинт инстанса Hologres;
- database — имя базы данных Hologres;
- port — номер порта инстанса Hologres.
¶ 11.27 IBM DB2
Библиотека IBM_DB_SA предоставляет интерфейс Python/SQLAlchemy для IBM Data Servers:
pip install ibm_db_saВот рекомендуемая строка подключения:
db2+ibm_db://{username}:{passport}@{hostname}:{port}/{database}В SQLAlchemy имплементированы две версии диалекта DB2. Если вы подключаетесь к версии DB2 без синтаксиса LIMIT [n], рекомендуемая строка подключения для возможности использования Лаборатории SQL (SQL Lab):
ibm_db_sa://{username}:{passport}@{hostname}:{port}/{database}¶ 11.28 IBM Netezza Performance Server
Библиотека nzalchemy предоставляет интерфейс Python/SQLAlchemy для Netezza:
pip install nzalchemyВот рекомендуемая строка подключения:
netezza+nzpy://{username}:{password}@{hostname}:{port}/{database}¶ 11.29 Kusto
Рекомендуемая библиотека соединителей для Kusto — sqlalchemy-kusto>=2.0.0.
Строка подключения для Kusto (диалект sql) выглядит следующим образом:
kustosql+https://{cluster_url}/{database}?azure_ad_client_id={azure_ad_client_id}&azure_ad_client_secret={azure_ad_client_secret}&azure_ad_tenant_id={azure_ad_tenant_id}&msi=FalseСтрока подключения для Kusto (диалект kql) выглядит следующим образом:
kustokql+https://{cluster_url}/{database}?azure_ad_client_id={azure_ad_client_id}&azure_ad_client_secret={azure_ad_client_secret}&azure_ad_tenant_id={azure_ad_tenant_id}&msi=FalseУбедитесь, что у пользователя есть права доступа и использования всех необходимых баз данных/таблиц/представлений.
¶ 11.30 Microsoft SQL Server
Рекомендуемая библиотека коннекторов для SQL Server — pymssql:
pip install pymssqlСтрока подключения для SQL Server выглядит так:
mssql+pymssql://<Username>:<Password>@<Host>:<Port-default:1433>/<Database Name>/?Encrypt=yesТакже возможно подключение с помощью pyodbc с параметром odbc_connect.
Пример строки подключения для SQL Server:
mssql+pyodbc:///?odbc_connect=Driver%3D%7BODBC+Driver+17+for+SQL+Server%7D%3BServer%3Dtcp%3A%3Cmy_server%3E%2C1433%3BDatabase%3Dmy_database%3BUid%3Dmy_user_name%3BPwd%3Dmy_password%3BEncrypt%3Dyes%3BConnection+Timeout%3D30¶ 11.31 MySQL
Рекомендуемая библиотека коннекторов для MySQL — mysqlclient:
pip install mysqlclientВот строка подключения:
mysql://{username}:{password}@{host}/{database}Хост:
- Для Localhost — localhost или 127.0.0.1;
- Для Docker под управлением Linux — 172.18.0.1;
- Для предварительной среды — IP-адрес или имя хоста;
- Для Docker под управлением OS X — docker.for.mac.host.internal, порт 3306 по умолчанию.
Одна из проблем с mysqlclient заключается в том, что он не сможет подключиться к более новым базам данных MySQL, используя caching_sha2_password для аутентификации, поскольку плагин не включён в клиент. В этом случае вместо этого следует использовать mysql-connector-python:
mysql+mysqlconnector://{username}:{password}@{host}/{database}¶ 11.32 Ocient DB
Рекомендуемая библиотека коннекторов для Ocient — sqlalchemy-ocient:
pip install sqlalchemy-ocient¶ 11.32.1 Подключение к Ocient
Формат строки подключения к Ocient:
ocient://user:password@[host][:port][/database][?param1=value1&...]Пример строки подключения к базе данных exampledb, расположенной по адресу examplehost:4050, с включённым TLS:
ocient://admin:abc123@examplehost:4050/exampledb?tls=onТ.е. для строки подключения необходимо ввести учётные данные user и password, по умолчанию для хоста используется localhost, для порта по умолчанию — 4050, для базы данных по умолчанию — system, а для tls по умолчанию — unverified.
¶ 11.32.2 Контроль доступа пользователей
Убедитесь, что у пользователя есть права доступа и использования всех необходимых баз данных, схем, таблиц, представлений и хранилищ, поскольку движок Ocient SQLAlchemy по умолчанию не проверяет права пользователя или роли.
¶ 11.33 Oracle
Рекомендуемая библиотека коннекторов — cx_Oracle:
pip install cx_OracleСтрока подключения имеет следующий формат:
oracle://<username>:<password>@<hostname>:<port>¶ 11.34 Postgres
Обратите внимание, что библиотека коннектора Postgres psycopg2 поставляется вместе с RT.DataVision.
Строка подключения выглядит так:
postgresql://{username}:{password}@{host}:{port}/{database}Хост:
- Для Localhost — localhost или 127.0.0.1;
- Для предварительной среды — IP-адрес или имя хоста;
- Для эндпоинта — AWS.
Порт — по умолчанию 5432.
Вы можете запросить SSL, добавив ?sslmode=require в конце:
postgresql://{username}:{password}@{host}:{port}/{database}?sslmode=requireВы можете прочитать о других режимах SSL, которые поддерживает Postgres, в Таблице 31-1 из этой документации.
Дополнительную информацию о параметрах подключения к PostgreSQL можно найти в документах SQLAlchemy и PostgreSQL.
¶ 11.35 Presto
Библиотека pyhive — рекомендуемый способ подключения к Presto через SQLAlchemy:
pip install pyhiveОжидаемая строка подключения имеет следующий формат:
presto://{hostname}:{port}/{database}Вы также можете передать имя пользователя и пароль:
presto://{username}:{password}@{hostname}:{port}/{database}Вот пример строки подключения со значениями:
presto://datascientist:securepassword@presto.example.com:8080/hiveПо умолчанию RT.DataVision предполагает, что при запросе к источнику данных используется самая последняя версия Presto. Если вы используете более старую версию Presto, вы можете настроить её в окне Подключение к базе данных (Connect a database) в дополнительном параметре по пути: вкладка Расширенные (Advanced) > Другое (Other) > поле Версия (Version):
{
"version": "0.123"
}¶ 11.36 RisingWave
Рекомендуемая библиотека коннекторов для RisingWave — sqlalchemy-risingwave.
Ожидаемая строка подключения имеет следующий формат:
risingwave://root@{hostname}:{port}/{database}?sslmode=disable¶ 11.37 Rockset
Пакет для установки драйвера БД:
pip install rockset-sqlalchemyСтрока подключения для Rockset:
rockset://{api key}:@{api server}Получите ключ API из консоли Rockset. Найдите свой сервер API в справочнике API. Опустите https:// часть URL-адреса.
Чтобы настроить строку подключения на конкретный виртуальный инстанс, используйте следующий формат URI:
rockset://{api key}:@{api server}/{VI ID}Для получения более полных инструкций рекомендуется обратиться к документации Rockset.
¶ 11.38 SAP Hana
Рекомендуемая библиотека коннекторов — sqlalchemy-hana:
pip install hdbcli sqlalchemy-hana
pip install apache-superset[hana]Строка подключения имеет следующий формат:
hana://{username}:{password}@{host}:{port}¶ 11.39 Snowflake
Рекомендуемая библиотека коннекторов для Snowflake — snowflake-sqlalchemy:
pip install snowflake-sqlalchemyСтрока подключения для Snowflake выглядит следующим образом:
snowflake://{user}:{password}@{account}.{region}/{database}?role={role}&warehouse={warehouse}Схема не требуется в строке подключения, так как она определяется для таблицы/запроса. Роль и хранилище можно не указывать, если для пользователя определены значения по умолчанию, т.е.:
snowflake://{user}:{password}@{account}.{region}/{database}Убедитесь, что у пользователя есть права доступа и использования всех необходимых баз данных/схем/таблиц/представлений/хранилищ, поскольку движок Snowflake SQLAlchemy по умолчанию не проверяет права пользователя/роли во время создания движка. Однако при нажатии кнопки Тестовое соединение (Test connection) в окне Подключение к базе данных (Connect a database) учётные данные пользователя/роли проверяются путём передачи validate_default_parameters:True методу connect() во время создания движка. Если пользователю/роли не разрешён доступ к базе данных, в логах RT.DataVision фиксируется ошибка.
Если вы хотите подключить Snowflake с аутентификацией по паре ключей, убедитесь, что у вас есть пара ключей и открытый ключ зарегистрирован в Snowflake. Чтобы подключить Snowflake с аутентификацией по паре ключей, вам необходимо добавить следующие параметры в поле Secure Extra.
Обратите внимание, что вам необходимо объединить многострочное содержимое закрытого ключа в одну строку и вставить \n между каждой строкой.
{
"auth_method": "keypair",
"auth_params": {
"privatekey_body": "-----BEGIN ENCRYPTED PRIVATE KEY-----\n...\n...\n-----END ENCRYPTED PRIVATE KEY-----",
"privatekey_pass":"Your Private Key Password"
}
}Если ваш закрытый ключ хранится на сервере, вы можете заменить в параметре privatekey_body на privatekey_path.
{
"auth_method": "keypair",
"auth_params": {
"privatekey_path":"Your Private Key Path",
"privatekey_pass":"Your Private Key Password"
}
}¶ 11.40 StarRocks
Библиотека sqlalchemy-starrocks — рекомендуемый способ подключения к StarRocks через SQLAlchemy:
pip install starrocksВот как выглядит строка подключения:
starrocks://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database>¶ 11.41 TimescaleDB
TimescaleDB — реляционная база данных с открытым исходным кодом для анализа временных рядов и анализа, позволяющая создавать мощные приложения с интенсивным использованием данных.
TimescaleDB — расширение PostgreSQL, и для подключения к базе данных можно использовать стандартную библиотеку коннекторов PostgreSQL psycopg2:
pip install psycopg2psycopg2 поставляется вместе с RT.DataVision.
Строка подключения выглядит так:
postgresql://{username}:{password}@{host}:{port}/{database name}Хост:
- Для Localhost — localhost или 127.0.0.1;
- Для предварительной среды — IP-адрес или имя хоста;
- Для сервиса Timescale Cloud — имя хоста;
- Для сервиса Managed Service for TimescaleDB — имя хоста.
Порт — по умолчанию 5432 или порт сервиса.
Вы можете запросить SSL, добавив ?sslmode=require в конце (например, если вы используете Timescale Cloud):
postgresql://{username}:{password}@{host}:{port}/{database name}?sslmode=requireЧтобы узнать больше о TimescaleDB, изучите документацию.
¶ 11.42 Teradata
Рекомендуемая библиотека коннекторов — teradatasqlalchemy:
pip install teradatasqlalchemyСтрока подключения для Teradata выглядит так:
teradatasql://{user}:{password}@{host}¶ 11.42.1 ODBC-драйвер
Существует также более старый коннектор sqlalchemy-teradata, который требует установки драйверов ODBC. Драйверы Teradata ODBC доступны здесь.
Вот необходимые переменные среды:
export ODBCINI=/.../teradata/client/ODBC_64/odbc.ini
export ODBCINST=/.../teradata/client/ODBC_64/odbcinst.iniРекомендуется использовать первую библиотеку из-за отсутствия требований к драйверам ODBC и потому, что она регулярно обновляется.
¶ 11.43 Trino
Поддерживается версия Trino 352 и выше:
pip install trino¶ 11.43.1 Строка подключения
Формат строки подключения следующий:
trino://{username}:{password}@{hostname}:{port}/{catalog}Если вы используете Trino с docker на локальной машине, используйте следующий URL подключения:
trino://trino@host.docker.internal:8080¶ 11.43.2 Аутентификации
1. Базовая аутентификация.
Вы можете указать username/password следующими способами:
- В строке подключения:
trino://{username}:{password}@{hostname}:{port}/{catalog}
- В окне Подключение к базе данных (Connect a database) по пути: вкладка Расширенные (Advanced) > Безопасность (Security) > поле Secure Extra:
{
"auth_method": "basic",
"auth_params": {
"username": "<username>",
"password": "<password>"
}
}Если указаны оба параметра, поле Secure Extra всегда имеет более высокий приоритет.
2. Аутентификация Kerberos.
Настройте, как указано ниже, в окне Подключение к базе данных (Connect a database) по пути: вкладка Расширенные (Advanced) > Безопасность (Security) > поле Secure Extra:
{
"auth_method": "kerberos",
"auth_params": {
"service_name": "superset",
"config": "/path/to/krb5.config",
...
}
}Все поля в auth_params передаются непосредственно классу KerberosAuthentication.
Примечание. Аутентификация Kerberos требует локальной установки trino-python-client с дополнительными функциями all или kerberos, т.е. установки trino[all] или trino[kerberos] соответственно.
3. Аутентификация по сертификату.
Настройте, как указано в примере ниже, в окне Подключение к базе данных (Connect a database) по пути: вкладка Расширенные (Advanced) > Безопасность (Security) > поле Secure Extra:
{
"auth_method": "certificate",
"auth_params": {
"cert": "/path/to/cert.pem",
"key": "/path/to/key.pem"
}
}Все поля в auth_params передаются непосредственно в класс CertificateAuthentication.
4. JWT-аутентификация.
Настройте auth_method и укажите токен в окне Подключение к базе данных (Connect a database) по пути: вкладка Расширенные (Advanced) > Безопасность (Security) > поле Secure Extra:
{
"auth_method": "jwt",
"auth_params": {
"token": "<your-jwt-token>"
}
}¶ 11.44 Vertica
Рекомендуемая библиотека коннекторов — sqlalchemy-vertica-python.:
pip install sqlalchemy-vertica-pythonСтрока подключения имеет следующий формат:
vertica+vertica_python://{username}:{password}@{host}/{database}Хост Vertica:
- Для Localhost — localhost или 127.0.0.1;
- Для предварительной среды — IP-адрес или имя хоста;
- Для облака — IP-адрес или имя хоста.
Порт — по умолчанию 5433.
Балансировщик нагрузки — резервный хост.
¶ 11.45 YugabyteDB
YugabyteDB — это распределённая база данных SQL, надстроенная над PostgreSQL.
Библиотека коннектора Postgres psycopg2 поставляется вместе с RT.DataVision:
pip install psycopg2Строка подключения выглядит так:
postgresql://{username}:{password}@{host}:{port}/{database}¶ 12 Безопасность и управление доступом
¶ 12.1 Общая информация
Безопасность в RT.DataVision обеспечивается Flask AppBuilder (FAB), фреймворком разработки приложений, созданным поверх Flask. FAB обеспечивает аутентификацию, управление пользователями, разрешениями и ролями. Для получения детальной информации ознакомьтесь с документацией по безопасности FAB.
Для работы с объектами и функциями RT.DataVision нужны разрешения (permission).
Для разрешений нужен контейнер, в котором будет определяться какими объектами и функциями в совокупности можно воспользоваться. Такими контейнерами являются роли (role).
Роли присваиваются пользователям (users).

¶ 12.2 Роли по умолчанию
RT.DataVision поставляется с набором ролей по умолчанию. Данные роли по умолчанию могут обновляться по мере развития RT.DataVision, т.е. в новых версиях.
Не рекомендуется изменять разрешения, определённые для каждой роли (например, добавлять новые разрешения или удалять существующие). Разрешения, определённые для каждой роли, повторно синхронизируются с исходными значениями при выполнении команды superset init (команда выполняется при обновлении версии RT.DataVision).
Набор ролей по умолчанию:
- Admin — пользователи с данной ролью имеют все возможные разрешения, в т.ч. предоставление или отзыв прав у других пользователей и изменение чужих срезов и дашбордов.
- Alpha — пользователи Alpha имеют доступ ко всем источникам данных, но не могут предоставлять или отзывать доступ другим пользователям. Также пользователь Alpha ограничен в изменении объектов, которыми он владеет. Пользователь Alpha может добавлять и изменять источники данных.
- Gamma — пользователи Gamma имеют ограниченный доступ. Пользователи Gamma могут потреблять только данные, поступающие из источников данных, к которым им предоставлен доступ через другую дополнительную роль. У них есть доступ только для просмотра срезов и дашбордов, созданных из источников данных, к которым у них есть доступ. Пользователи Gamma не могут изменять или добавлять источники данных. Предполагается, что они в основном потребители контента, хотя могут создавать срезы и дашборды. Также обратите внимание, что, когда пользователи Gamma просматривают перечень дашбордов и срезов, они видят только те объекты, к которым у них есть доступ.
- sql_lab — роль sql_lab предоставляет доступ к SQL Lab. Обратите внимание, что, хотя пользователи Admin по умолчанию имеют доступ ко всем базам данных, а пользователям Alpha и Gamma необходимо предоставить доступ для каждой базы данных отдельно.
- Public — чтобы предоставить разлогиненным пользователям доступ к некоторым функциям RT.DataVision, вы можете использовать параметр конфигурации PUBLIC_ROLE_LIKE и назначить его другой роли, чьи разрешения вы хотите передать этой роли.
Например, установив PUBLIC_ROLE_LIKE = "Gamma" в файле superset_config.py, вы предоставляете роли Public тот же набор разрешений, что и для роли Gamma. Это полезно, если вы хотите разрешить анонимным пользователям просматривать дашборды. Явное предоставление для определённых датасетов по-прежнему требуется, а это означает, что вам необходимо отредактировать роль Public и добавить общедоступные источники данных в роль вручную.
¶ 12.3 Разрешения
Все права представляют из себя пары вида <действие> on <сущность> и разделяются по типу действия следующие категории:
- разрешения на взаимодействие с сущностями;
- разрешения на отдельные элементы-страницы интерфейса Superset. Если пользователю дано право на элемент, он сможет видеть и открывать соответствующие страницы;
- разрешения на доступ к источникам данных: можно выдать доступ как к отдельным источникам (datasource), схемам или к целой БД (database).
¶ 12.3.1 Доступ к разделам
Доступ к разделам и элементам меню RT.DataVision предоставляется в виде menu_access on <сущность>:
| Сущность | Описание | ||
|---|---|---|---|
| Access requests | Запросы на регистрацию | ||
| Home | Домашняя страница | ||
| Меню Настройки | |||
| Security | Раздел Безопасность | ||
| List Users | Пункт меню Список пользователей | ||
| List Roles | Пункт меню Список ролей | ||
| Row Level Security | Пункт меню Безопасность на уровне строк | ||
| Action Log | Пункт меню Журнал действий | ||
| User Registration | Пункт меню Регистрация пользователей | ||
| Manage | Раздел Управление | ||
| CSS Templates | Пункт меню CSS шаблоны | ||
| Alerts & Report | Пункт меню Оповещения и отчеты | ||
| Annotation Layers | Пункт меню Слои аннотаций | ||
| Вкладки верхнего меню | |||
| Dashboards | Вкладка Дашборды | ||
| Import Dashboards | Кнопка Импорт дашборда | ||
| Charts | Вкладка Графики | ||
| SQL Lab | Вкладка Лаборатория SQL | ||
| SQL Editor | Редактор SQL | ||
| Saved Queries | Раздел Сохраненные запросы | ||
| Query Search | Раздел История запросов | ||
| Data | Вкладка Данные | ||
| Databases | Пункт меню Базы данных | ||
| Datasets | Пункт меню Датасеты | ||
| Upload a CSV | Пункт меню Загрузка CSV в базу данных | ||
| Upload a Columnar file | Пункт меню Загрузка колоночного файла в базу данных | ||
| Druid Datasources | |||
| Druid Clusters | |||
| Scan New Datasources | |||
| Refresh Druid Metadata | |||
| Dashboard Email Schedules | |||
| Chart Emails | |||
| Alerts | |||
| Plugins | |||
¶ 12.3.1.1 Доступ к основным действиям
Доступ к действиям в RT.DataVision предоставляется в виде <действие> on superset:
| Действие | Описание доступа |
|---|---|
| can_schemas | |
| can_sqllab_table_viz | |
| can_results | |
| can_fave_dashboards | |
| can_publish | |
| can_explore_json | |
| can_explore | |
| can_tables | Отображение списка таблиц в редакторе SQL |
| can_datasources | |
| can_approve | |
| can_schemas_access_for_file_upload | |
| can_filter | |
| can_validate_sql_json | |
| can_stop_query | |
| can_testconn | |
| can_extra_table_metadata | |
| can_import_dashboards | |
| can_estimate_query_cost | |
| can_profile | Доступ в Профиль в разделе Пользователь меню Настройки |
| can_annotation_json | |
| can_log | |
| can_save_dash | Сохранение дашборда |
| can_sqllab | Доступ в редактор SQL |
| can_created_slices | |
| can_user_slices | |
| can_created_dashboards | |
| can_sync_druid_source | |
| can_copy_dash | |
| can_warm_up_cache | |
| can_csrf_token | |
| can_sqllab_history | |
| can_csv | |
| can_select_star | |
| can_sql_json | |
| can_add_slices | |
| can_sqllab_viz | |
| can_queries | |
| can_fave_dashboards_by_username | |
| can_search_queries | |
| can_slice | |
| can_fave_slices | |
| can_request_access | |
| can_available_domains | |
| can_fetch_datasource_metadata | |
| can_dashboard | |
| can_slice_json | |
| can_favstar | |
| can_override_role_permissions | |
| can_recent_activity | Отображение недавней активности на главной странице |
| can_share_dashboard | |
| can_share_chart | |
| can_dashboard_permalink | |
| can_create_folder |
¶ 12.3.1.2 Разрешения на взаимодействие с данными
Доступы к данным, находящимся в таблицах различных разделов RT.DataVision. Доступ предоставляется в виде <действие> on <сущность> :
| Сущность | Описание сущности | Основные действия | Прочие действия | |||||
|---|---|---|---|---|---|---|---|---|
|
can_list (просмотр списка) |
can_show (просмотр элемента) |
can_edit (редактирование элемента) |
can_add (добавление элемента) |
can_delete (удаление элемента) |
muldelete (выбор и удаление нескольких элементов) |
|||
| UserDBModelView | Список пользователей | + | + | + | + | + |
|
|
| UserLDAPModelView | Список пользователей LDAP | + | + | + | + | + |
|
|
| RegisterUserModelView | Список запросов на регистрацию | + | + | + | ||||
| RoleModelView | Список ролей | + | + | + | + | + | copyrole (копировать роль) | |
| SwaggerView | + | |||||||
| AsyncEventsRestApi | + | |||||||
| FilterSets | + | + | + | + | ||||
| DynamicPlugin | + | + | + | + | + |
|
||
| RowLevelSecurityFiltersModelView | Фильтр на уровне строк | + | + | + | + | + | + | can_download |
| DashboardEmailScheduleView | Рассылка дашбордов | + | + | + | + | + | + | |
| SliceEmailScheduleView | Рассылка чартов | + | + | + | + | + | + | |
| AlertModelView | Оповещения | + | + | + | + | + | ||
| AlertLogModelView | Журнал оповещений | + | + | |||||
| AlertObservationModelView | + | + | ||||||
| AccessRequestsModelView | + | + | + | + | + | + | ||
| DruidDatasourceModelView | + | + | + | + | + | + | yaml_export | |
| DruidClusterModelView | + | + | + | + | + | + | yaml_export | |
| DruidMetricInlineView | + | + | + | + | ||||
| DruidColumnInlineView | + | + | + | + | ||||
¶ 12.3.1.3 Доступы к элементам
Доступы к элементам RT.DataVision. Доступ предоставляется в виде <действие> on <сущность> :
| Сущность | Описание сущности | Основные действия | Прочие действия | ||
|---|---|---|---|---|---|
|
can_get (загрузить объект) |
can_post (создать новый объект) |
can_delete (удалить объект) |
|||
| Datasource | Датасеты, в том числе виртуальные | + |
|
||
| OpenApi | + | ||||
| MenuApi | + | ||||
| TabStateView | Вкладка в SQL редакторе | + | + | + |
|
| TagView | + | + | + |
|
|
| TableSchemaView | + | + | can_expanded | ||
¶ 12.3.2 Доступы к основным объектам
Доступы к основным объектам RT.DataVision. Доступ предоставляется в виде <действие> on <сущность> :
| Сущность | Описание сущности | Основные действия | Прочие действия | ||
|---|---|---|---|---|---|
|
can_read (доступ на чтение) |
can_write (доступ на запись) |
can_export (доступ на экспорт, не работает без can_write) |
|||
| SavedQuery | Сохраненный запрос | + | + | + | |
| Query | Запрос | + | |||
| CssTemplate | CSS шаблон | + | + | ||
| ReportSchedule | Оповещения и отчеты | + | + | ||
| Chart | График | + | + | + | |
| Annotation | Слои аннотаций | + | + | ||
| Dataset | Датасет | + | + | + | |
| Log | Журнал действий | + | + | ||
| Dashboard | Дашборд | + | + | + |
|
| EmbeddedDashboard | + | ||||
| Database | База данных | + | + | + | |
| SecurityRestApi | + | can_grant_guest_token | |||
| DashboardFilterStateRestApi | + | + | |||
| DashboardPermalinkRestApi | + | + | |||
| ExploreFormDataRestApi | + | + | |||
| ExplorePermalinkRestApi | + | + | |||
| Folder | + | + |
|
||
| DynamicPlugin | + | ||||
| ImportExportRestApi | + | can_import_ | |||
| AdvancedDataType | + | ||||
¶ 12.3.2.1 Доступы к формам
Доступы к формам RT.DataVision. Доступ предоставляется в виде <действие> on <сущность> :
| Сущность | Описание сущности | Действия | |
|---|---|---|---|
|
can_this_form_get (просмотр формы) |
can_this_form_post (отправка формы) |
||
| ResetPasswordView | Форма смены пароля любого пользователя (в разделе Список пользователей) | + | + |
| ResetMyPasswordView | Форма смены своего пароля (в разделе Пользователь → Инфо) | + | + |
| UserInfoEditView | Форма смены своих данных (в разделе Пользователь → Инфо). Для изменения доступно только имя и фамилия | + | + |
| CsvToDatabaseView | Форма загрузки CSV | + | + |
| ExcelToDatabaseView | Форма загрузки файлов Excel | + | + |
| ColumnarToDatabaseView | Форма загрузки файлов со столбцами | + | + |
¶ 12.3.3 Прочие действия
Прочите действия в RT.DataVision. Доступ предоставляется в виде <действие> on <сущность> :
| Действие | Сущность | Описание |
| can_invalidate | CacheRestApi | |
| can_time_range | Api | |
| can_query | Api | |
| can_query_form_data | Api | |
| can_external_metadata | Datasource | |
| can_save | Datasource | |
| can_external_metadata_by_name | Datasource | |
| can_store | KV | |
| can_get_value | KV | |
| can_shortner | R | |
| can_my_queries | SqlLab | |
| can_expanded | TableSchemaView | |
| can_scan_new_datasources | Druid | |
| can_refresh_datasources | Druid | |
| can_import_ | ImportExportRestApi |
¶ 12.3.4 Доступы к источникам данных
Для получения доступа используется один из трёх видов прав:
- database access on [<имя БД>];
- schema access on [<имя БД>].[<имя схемы>];
- datasource access on [<имя БД>].[<имя источника>].
При создании подключения к БД автоматически генерируются все права второго (доступ к схеме) и третьего (доступ к источнику) типа.
Для роли администраторов или схожей по правам можно предоставить доступ ко всем объектам:
- all_database_access on all_database_access – доступ ко всем БД;
- all_datasource_access on all_datasource_access – доступ ко всем источникам;
- all_query_access on all_query_access – доступ ко всем запросам.
¶ 12.4 Управление доступом к источникам данных для ролей Gamma
В разделе описано, как предоставить пользователям доступ только к определённым датасетам. Сначала убедитесь, что пользователям с ограниченным доступом назначена только роль Gamma. Во-вторых, создайте новую роль (Настройки (Settings) > Список ролей (List Roles)) и нажмите значок +.
Открывшееся окно позволит вам дать этой новой роли имя и выбрать таблицы в раскрывающемся списке Права (Permissions). Чтобы выбрать источники данных, которые вы хотите связать с этой ролью, щёлкните раскрывающийся список и используйте ввод для поиска имён таблиц.
Затем вы можете подтвердить с помощью пользователей, которым назначена роль Gamma, что они видят объекты (дашборды и графики), связанные с таблицами, которые вы только что расширили.
¶ 12.5 Кастомизация разрешений
Разрешения, предоставляемые FAB, очень детализированы и обеспечивают высокий уровень кастомизации. FAB автоматически создаёт множество разрешений для каждой создаваемой модели (can_add, can_delete, can_show, can_edit, …), а также для каждого представления. Кроме того, RT.DataVision может предоставлять более детальные разрешения, такие как all_datasource_access.
Внимание. Не рекомендуется изменять базовые роли, поскольку существует набор допущений, на которых построен RT.DataVision. Однако вы можете создавать свои собственные роли и объединять их с существующими.
¶ 12.6 Ограничение доступа к подмножеству источников данных
Рекомендуется предоставить пользователю роль Gamma, а также любые другие роли, которые добавят доступ к определённым источникам данных. Рекомендуется создавать отдельные роли для каждого профиля доступа. Например, пользователи группы Finance могут иметь доступ к набору баз данных и источников данных; эти разрешения могут быть объединены в одной роли. Затем пользователям с этим профилем необходимо назначить роль Gamma в качестве основы для моделей и представлений, к которым они могут получить доступ, и роль Finance, которая представляет собой набор разрешений для объектов данных.
С пользователем может быть связано несколько ролей. Например, руководителю группы Finance могут быть предоставлены роли Gamma, Finance и Executive. Роль Executive может предоставлять доступ к набору источников данных и дашбордов, доступных только для руководителей. В представлении Dashboards пользователь может видеть только те, к которым у него есть доступ, в зависимости от назначенных ролей и разрешений.
¶ 12.7 Безопасность на уровне строк
¶ 12.7.1 Общее описание правила
Безопасность на уровне строк (Row Level Security) — это предустановленная функция, использующаяся вместе с ролями доступа к данным (DAR), для осуществления детального контроля над тем, кто запрашивает и просматривает определенную информацию в выбранных датасетах. Правила безопасности ограничивают доступ определенных групп пользователей к данным.
Используя правила Безопасность на уровне строк (RLS) (в меню Настройки (Settings)), можно создавать фильтры, которые назначаются конкретной таблице, а также набору ролей. Например, если необходимо, чтобы члены группы Finance имели доступ только к строкам, в которых department = "finance", выполните:
- Создайте правило Безопасность на уровне строк (RLS) с этим условием department = "finance" в поле Положение.
- Укажите роль Finance и таблицу, к которой применяется это условие.
В поле Положение, которое может содержать произвольный текст, добавляется оператор WHERE. Таким образом, существует возможность создания правила за последние 30 дней и применения его к определённой роли с таким условием, как date_field > DATE_SUB(NOW(), INTERVAL 30 DAY). Который также может поддерживать несколько условий: client_id = 6 и advertiser="foo" и т.д.
Все соответствующие правила безопасности на уровне строк будут объединены вместе (внутри различные предложения SQL объединяются с помощью операторов AND). Это означает, что можно создать ситуацию, когда две роли конфликтуют таким образом, что подмножество таблиц может быть пустым.
Например, условия client_id=4 и client_id=5, применённые к роли, приведут к тому, что пользователи этой роли будут иметь client_id=4 AND client_id=5, добавленные к их запросу, что никогда не может быть true.
Примечание. Безопасность на уровне строк (RLS) не применимы к редактору SQL. Несмотря на то, что пользователь не может просматривать графики, защищенные правилом RLS, роль рабочей области ограниченного участника и выше все равно сможет запрашивать данные через редактор SQL.
Правило RLS используется для определения того, какие данные в датасете могут быть запрошены. После создания правила RLS его можно назначить для роли доступа к данным. Чтобы создать правило RLS:
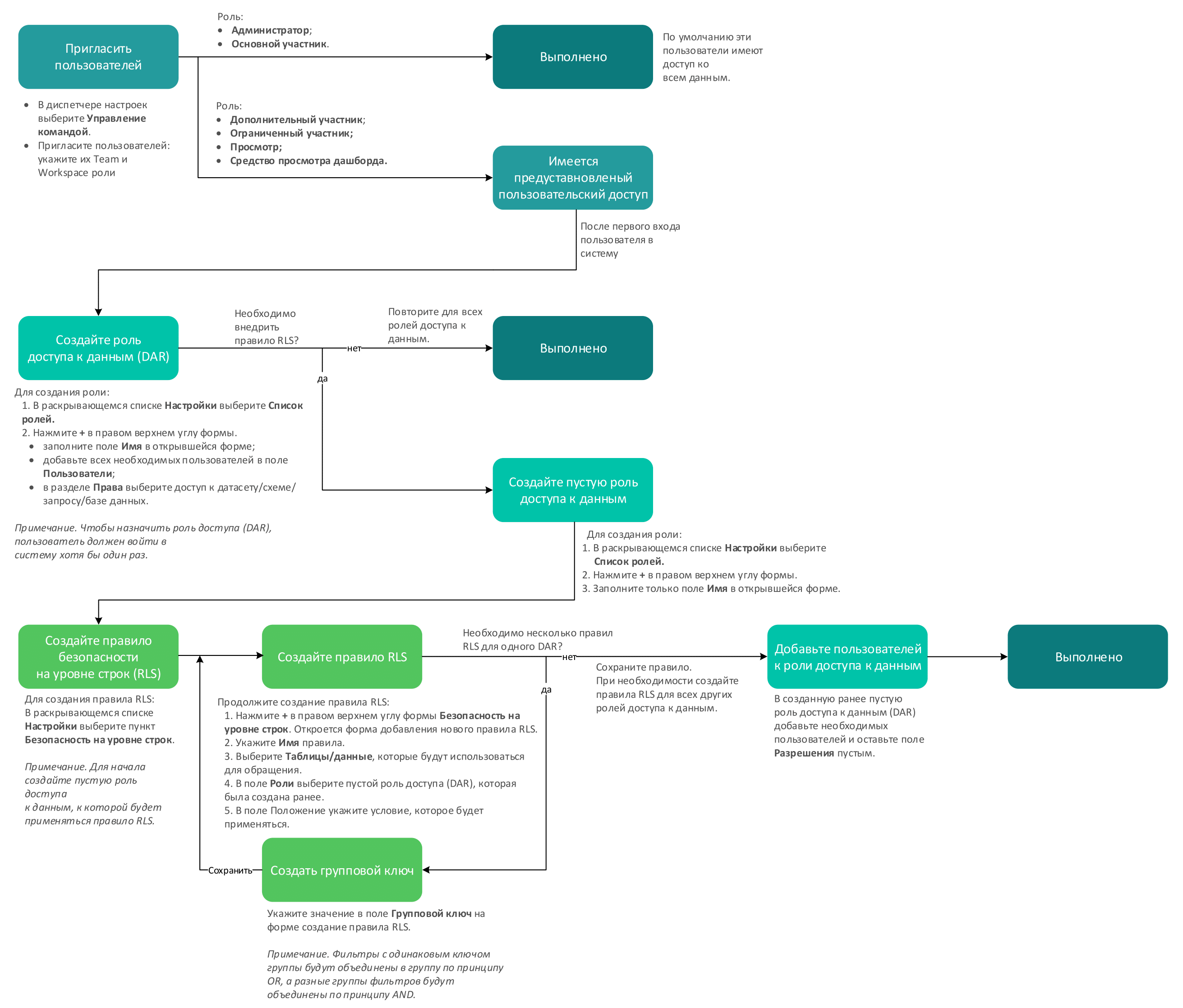
¶ 12.7.2 Типы фильтров в правиле RLS
Фильтры в правилах безопасности на уровне строк разделяются на обычные (Regular) и базовые (Base):
- Обычный тип фильтра применяется ко всем запросам пользователя, добавленных в выбранную роль. Правило добавляет оператора WHERE в запросы, если пользователь принадлежит роли, указанной в правиле.
Пример: есть группа продавцов, которые видят данные только для своего региона. Создайте правило с обычным типом фильтра с условием Region = “Северо-Запад” и назначьте это правило для роли доступа к данным, которая включает в себя продавцов, ответственных за северо-западную территорию. - Базовый тип фильтр применяется ко всем запросам пользователей, не добавленных в выбранную роль. Правило добавляет оператора WHERE ко всем запросам, кроме ролей, указанных в правиле. Правило с этим типом фильтра может использоваться для определения того, что пользователи видят, если к ним не применяются никакие фильтры в группе правил RLS.
Пример: чтобы для всех пользователей, просматривающих наши дашборды, ориентированные на клиентов, за исключением нашей группы данных, установить ограничение на просмотр данных только за последние 3 месяца, необходимо создать правило с базовым типом фильтра, назначить на него свою группу обработки данных и добавить условие, ограничивающее временной диапазон последними тремя месяцами.
¶ 12.7.3 Варианты использования
¶ 12.7.3.1 Первый вариант
Безопасность на уровне строк можно использовать для создания настройки разрешений, при которой все пользователи используют один дашборд, но каждый из них видит только те данные, которые связаны с его регионом (AMER, APAC или EMEA).
Дашборд, который будет использоваться в этом примере, — это дашборд Продажа транспортных средств, который по умолчанию включен в рабочее пространство.
¶ 12.7.3.1.1 Необходимые условия
- Пользователи приглашены в рабочую область.
- Эти пользователи совершили первый вход в RT DataVision.
- Созданы датасеты, которые будут использованы в правиле RLS.
Для начала необходимо создать роль доступа к данным для всех этих пользователей и предоставить им доступ к датасету public.Продажа транспортных средств.
¶ 12.7.3.1.2 Создание роли доступа к данным
Для создания роли:
- В раскрывающемся списке Настройки выберите Список ролей.
- Нажмите + в правом верхнем углу формы.
- Заполните поле Имя в открывшейся форме. В этом примере создадим одну роль доступа к данным Команда продаж — все.
- Нажмите Сохранить. Откроется форма Список ролей.
- Нажмите на иконку редактирования созданной роли. Откроется форма Редактировать роль.
- Добавьте всех необходимых пользователей в поле Пользователи.
- В разделе Права выберите Доступ к датасету. Продажа транспортных средств.
- Нажмите Сохранить.
¶ 12.7.3.1.3 Создание пустой роли доступа к данным
Cоздайте пустую роль доступа к данным для каждого из регионов. В этом примере создадим три роли доступа к данным с именами: Отдел продаж — Азия, Отдел продаж — Африка и Отдел продаж — Европа. Это роли доступа к данным, к которым будут применяться правила безопасности на уровне строк.
Для создания пустых ролей:
- В раскрывающемся списке Настройки выберите Список ролей.
- Нажмите + в правом верхнем углу формы.
- Заполните только поле Имя. В этом примере создадим три отдельные роли доступа к данным: Отдел продаж — Азия, Отдел продаж — Африка и Отдел продаж — Европа.
- Нажмите Сохранить.
Добавлять пользователей к этим ролям не нужно, пока не создадим правила безопасности на уровне строк. Поле Разрешения тоже оставляем пустым. Создадим три правила безопасности на уровне строк для каждого регионов: Отдел продаж RLS — Азия, Отдел продаж RLS — Африка и Отдел продаж RLS — Европа. Выберем к какому датасету/схеме/БД будут применяться эти правила, и укажем условие, которое ограничит пользователям просмотр только определенных данных.
¶ 12.7.3.1.4 Создание правила безопасности на уровне строк
Для создания правила RLS:
- В раскрывающемся списке Настройки выберите Безопасность на уровне строк.
- Нажмите + в правом верхнем углу формы. Откроется форма добавления правила.
- Укажите данные в следующих полях:
- Имя: Отдел продаж RLS — Европа
- Тип фильтра: Обычный
- Таблицы: public.Продажа транспортных средств
- Роли: Отдел продаж – Европа
- Групповой ключ: оставить значение пустым
- Положение: territory IN ('Европа')
- Описание: Это правило RLS ограничит доступ отдела продаж в регионе Европа только к просмотру данных из региона Европа при доступе к датасету Продажа транспортных средств.
- Нажмите Сохранить.
Подобным образом создайте правила Отдел продаж RLS — Азия и Отдел продаж RLS — Африка.
¶ 12.7.3.1.5 Добавление пользователей к роли доступа
Для добавления пользователей к созданным ролям:
- В раскрывающемся списке Настройки выберите Список ролей.
- Выберите одну из ролей доступа к данным: Отдел продаж – Азия, Отдел продаж – Африка или Отдел продаж – Европа.
- Добавьте продавцов в соответствующие регионы.
- Нажмите Сохранить.
Результат:
Теперь все продавцы на территории Европа добавлены к ролям доступа к данным: Команда продаж — Все и Отдел продаж — Европа будет иметь пункт:
WHERE territory IN ('Европа')Условие применяется ко всем запросам на формирование графиков с использованием датасета public.Продажа транспортных средств. Они смогут просматривать только те данные, у которых в столбце territory указано значение Европа.
¶ 12.7.3.2 Второй вариант. Определение инклюзивного регулярного правила RLS
Цели:
- Создать базовый фильтр, исключающий доступ по запросам ко всем игровым платформам в датасете — это правило будет применяться ко всем пользователям.
- Создать обычный фильтр, который будет предоставлять доступ только к видеоиграм на платформе Wii — это правило будет применяться к роли доступа к данным.
Конечным результатом является то, что пользователи, которым назначена роль Платформа Wii, смогут просматривать диаграмму, включающую только видеоигры на платформе Wii.
¶ 12.7.3.2.1 Создание роли доступа к данным
Для создания роли:
- В раскрывающемся списке Настройки выберите Список ролей.
- Нажмите + в правом верхнем углу формы.
- Заполните поле Имя в открывшейся форме. В этом примере создадим одну роль доступа к данным Платформа Wii.
- Нажмите Сохранить.
¶ 12.7.3.2.2 Создание правила безопасности на уровне строк
Для создания правила RLS:
- В раскрывающемся списке Настройки выберите Безопасность на уровне строк.
- Нажмите + в правом верхнем углу формы. Откроется форма добавления правила.
- Укажите данные в следующих полях:
- Имя: Платформа Wii (RLS)
- Тип фильтра: Обычный (этот тип фильтра добавляет оператора WHERE к запросам пользователя, если его роль указана в правиле)
- Таблицы: public.Video_game_sales
- Роли: Платформа Wii
- Групповой ключ: platform
- Положение: platform = 'Wii'
- Описание: Фильтр, который будет предоставлять доступ только к видеоиграм на платформе Wii.
- Нажмите Сохранить.
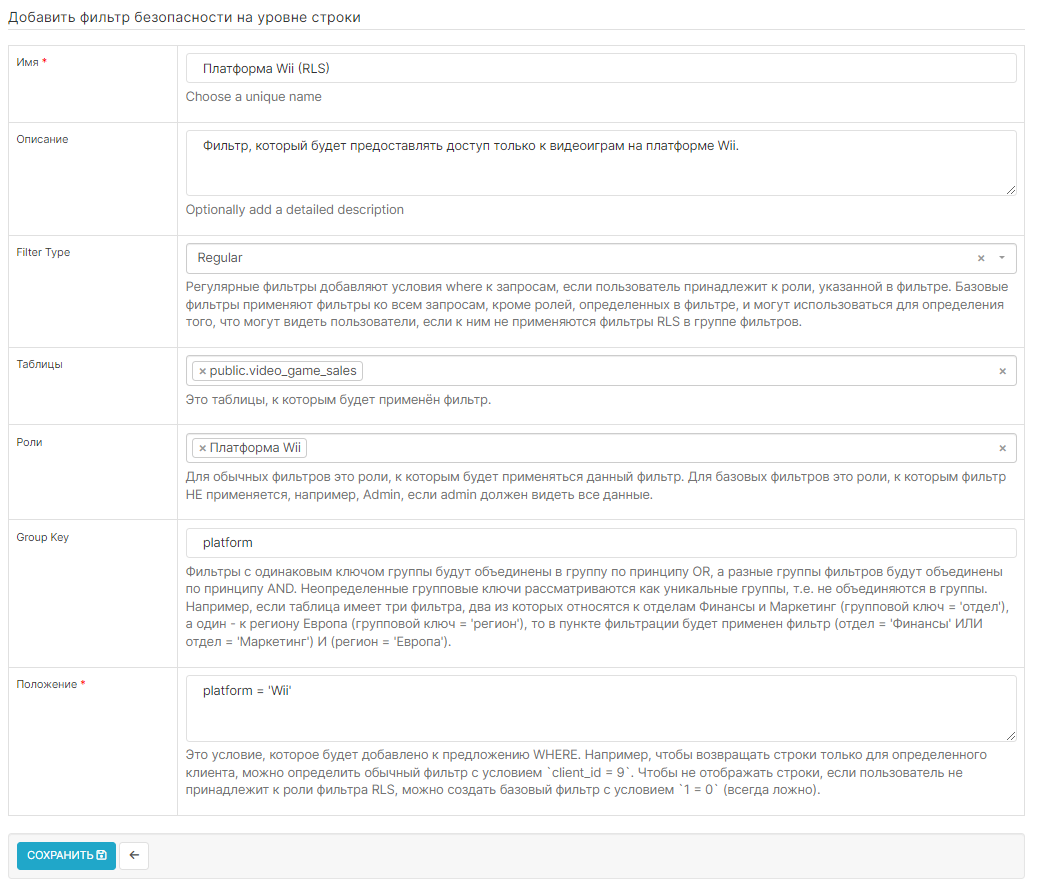
¶ 12.7.3.3 Третий вариант. Определение исключающего базового RLS-фильтра
¶ 12.7.3.3.1 Создание правила безопасности на уровне строк
Для создания правила RLS:
- В раскрывающемся списке Настройки выберите Безопасность на уровне строк.
- Нажмите + в правом верхнем углу формы. Откроется форма добавления правила.
- Укажите данные в следующих полях:
- Имя: Video_game_sales(RLS)
- Тип фильтра: Базовый (этот тип фильтра применяется ко всем запросам)
- Таблицы: public.Video_game_sales
- Роли: оставьте значение пустым (т. е. применимо ко всем). Поскольку это базовый тип, правило не будет применяться ни к каким ролям, определенным в этом поле.
- Групповой ключ: platform
- Положение: 1 = 0 (это условие, которое определяет фильтр, применяемый к запросу. В этом случае ложный запрос “1 = 0” не будет возвращать ни одной строки)
- Нажмите Сохранить.
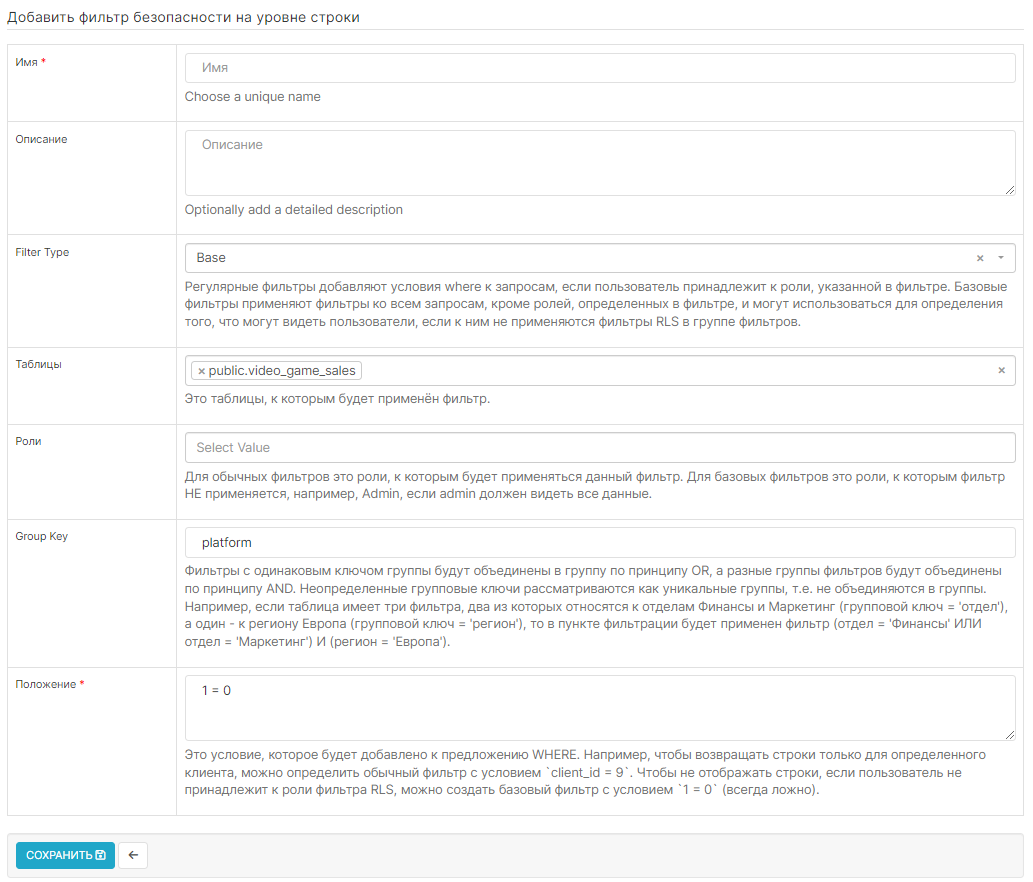
Примечание. Безопасность на уровне строк (RLS) не применимы к редактору SQL. Несмотря на то, что пользователь не может просматривать графики, защищенные правилом RLS, роль рабочей области ограниченного участника и выше все равно сможет запрашивать данные через редактор SQL.
Рассмотрим на таблицу Video_game_sales, чтобы протестировать созданный базовый фильтр Video_game_sales(RLS).
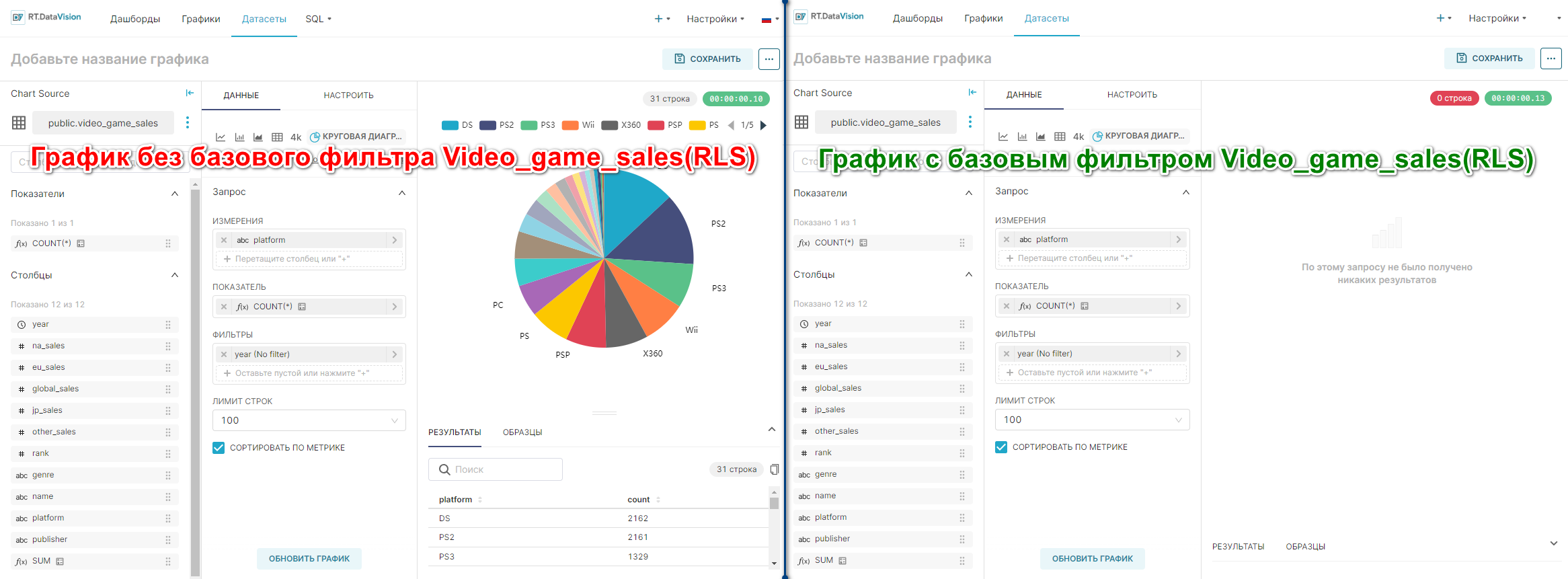
Как и ожидалось, базовый фильтр Video_game_sales(RLS) препятствует получению доступа к данным в датасете. При попытке построить график он будет формироваться пустым.
¶ 12.7.3.3.2 Связь роли с пользователем
Для связи роли Платформа Wii с пользователем:
- В раскрывающемся списке Настройки выберите Список ролей.
- Нажмите на иконку редактирования роли Платформа Wii. Откроется форма Редактировать роль.
- В поле Пользователи выберите одного или нескольких пользователей, к которым будет применена роль.
- При использовании RLS в сочетании с ролями доступа к данным оставьте поле Права пустым.
- Нажмите Сохранить.
¶ 12.7.3.4 Проверка созданных правил RLS
Перед проверкой созданных правил необходимо убедиться, что доступы для используемой роли выглядят следующим образом:
А в разделе Безопасность на уровне строк настроены следующие правила:

Для проверки обычного фильтра перейдите к графику таблицы Video_game_sales и выполните запрос.
На данном примере видно что, теперь пользователь может получить доступ только к записям из датасета, где платформа — Wii (обратите внимание на столбец Платформа в таблице).
¶ 12.7.4 Расширенная безопасность на уровне строк с использованием имени пользователя
Администраторы, у которых информация о доступе пользователей хранится в их базе данных, могут использовать правило RLS для автоматического и масштабируемого управления доступом к данным. Для настройки используется комбинация макросов Jinja , API и обычного фильтра RLS.
Прежде чем создавать новое правило RLS, необходимо использовать Preset API.
¶ 12.7.4.1 Сопоставление предустановленных имен пользователей с электронными письмами
Используя API Get Team Members, можно регулярно получать список адресов электронной почты и предустановленные имена пользователей для своих пользователей. Это может быть получено механизмом приема и сохранено на уровне интеграции вашей базы данных. Затем можно объединить эти предустановленные имена пользователей с любыми существующими таблицами данных, которые содержат доступ пользователей по электронной почте.
¶ 12.7.4.2 Настройка правила безопасности на уровне строки
После того как предустановленное имя пользователя будет сохранено на ваших вкладках, можно настроить фильтр Regular RLS с помощью предустановленного макроса Jinja. Сначала выберите Обычный тип фильтра и выберите таблицы в базе данных, которые одновременно содержат информацию о доступе пользователей и требуют фильтрации на основе доступа пользователей.
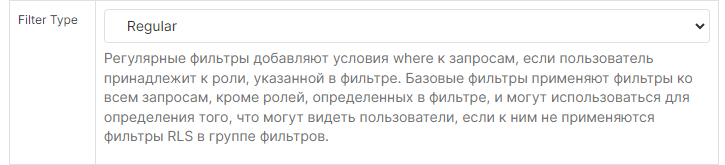
Добавьте оператор Clause для WHERE, которое фильтрует доступ к данным на основе имени пользователя для входа в систему.
[myusercolumn]='{{ current_username()}}'Замените [myusercolumn] столбцом в вашей таблице, который содержит предварительно заданное имя пользователя, указывающее, кто должен иметь доступ к этим данным.

Готово. Теперь ваши пользователи будут видеть только отфильтрованные для них данные при запросе к выбранным вами таблицам.
¶ 13 Дополнительная информация
¶ 13.1 Инструменты Country Map
¶ 13.1.1 Визуализация Country Map
Визуализация Country Map позволяет вам строить облегчённые картограммы ваших стран по регионам, провинциям, штатам или другим типам разделений. Функция не зависит от каких-либо сторонних картографических сервисов, но потребует от вас предоставить коды ISO-3166-2 разделений верхнего уровня вашей страны. По сравнению с полными названиями провинций или штатов код ISO менее неоднозначен и уникален для всех регионов мира.
¶ 13.1.2 Карты по умолчанию
Визуализация Country Map уже поставляется с картами следующих стран:
- Бельгия;
- Бразилия;
- Болгария;
- Канада;
- Китай;
- Египет;
- Франция;
- Германия;
- Индия;
- Иран;
- Италия;
- Япония;
- Корея;
- Лихтенштейн;
- Марокко;
- Мьянма;
- Нидерланды;
- Португалия;
- Россия;
- Сингапур;
- Испания;
- Швейцария;
- Сирия;
- Таиланд;
- Восточный Тимор;
- Великобритания;
- Украина;
- Уругвай;
- США;
- Замбия.
¶ 13.2 Экспорт и импорт источников данных
Интерфейс командной строки (CLI) RT.DataVision позволяет импортировать и экспортировать источники данных из YAML и в него. Источники данных включают как базы данных, так и кластеры druid. Предполагается, что данные будут организованы в следующей иерархии:
├──базы_данных
| ├──база_данных_1
| | ├──таблица_1
| | | ├──столбцы
| | | | ├──столбец_1
| | | | ├──столбец_2
| | | | └──... (больше столбцов)
| | | └──метрики
| | | ├──метрика_1
| | | ├──метрика_2
| | | └──... (больше метрик)
| | └── ... (больше таблиц)
| └── ... (больше баз данных)
└──druid_кластеры
├──кластер_1
| ├──источник_данных_1
| | ├──столбцы
| | | ├──столбец_1
| | | ├──столбец_2
| | | └──... (больше столбцов)
| | └──метрики
| | ├──метрика_1
| | ├──метрика_2
| | └──... (больше метрик)
| └── ... (больше источников данных)
└── ... (больше кластеров)¶ 13.2.1 Экспорт источников данных в YAML
Вы можете вывести свои текущие источники данных на stdout, запустив:
superset export_datasourcesЧтобы сохранить источники данных в файл, выполните:
superset export_datasources -f <название_файла>По умолчанию значения по умолчанию (null) будут опущены. Используйте флаг -d, чтобы включить их. Если вы хотите, чтобы обратные ссылки были включены (например, столбец для включения идентификатора таблицы, к которой он принадлежит), используйте флаг -b.
Кроме того, вы можете экспортировать источники данных с помощью пользовательского интерфейса:
- Sources > Databases для экспорта всех таблиц, связанных с одной или несколькими базами данных (Tables для одной или нескольких таблиц, Druid Clusters для кластеров, Druid Datasources для источников данных).
- Выберите элементы, которые вы хотите экспортировать.
- Нажмите Actions > Export to YAML.
- Если вы хотите импортировать элемент, который вы экспортировали через пользовательский интерфейс, вам нужно будет вложить его в его родительский элемент, например, база данных должна быть вложена в базы данных, таблица должна быть вложена в элемент базы данных.
Чтобы получить исчерпывающий список всех полей, которые вы можете импортировать, используя импорт YAML, запустите:
superset export_datasource_schema¶ 13.2.2 Импорт источников данных из YAML
Чтобы импортировать источники данных из файлов YAML, запустите:
superset import_datasources -p <путь_или_название_файла>Если вы укажете путь, все файлы, заканчивающиеся на yaml или yml, будут проанализированы. Вы можете применить дополнительные флаги (например, для рекурсивного поиска по указанному пути):
superset import_datasources -p <путь> -rФлаг синхронизации -s принимает параметры для синхронизации предоставленных элементов с вашим файлом. Будьте осторожны, это может удалить содержимое вашей метабазы данных. Пример:
set import_datasources -p <путь / название_файла> -s columns,metricsПосле запуска синхронизируются все метрики и столбцы для всех источников данных, найденных в <путь / название_файла> в метабазе данных RT.DataVision. Это означает, что столбцы и метрики, не указанные в YAML, будут удалены. Если вы добавите таблицы в столбцы, метрики также будут синхронизированы.
Если вы не укажете флаг синхронизации (-s), импорт будет только добавлять и обновлять (переопределять) поля. Например, вы можете добавить verbose_name в столбец ds в таблице random_time_series из примеров наборов данных, сохранив следующий YAML в файл, а затем выполнив команду import_datasources.
databases:
- database_name: main
tables:
- table_name: random_time_series
columns:
- column_name: ds
verbose_name: datetime¶ 13.3 Коды проблем
В данном разделе перечислены коды проблем, которые могут отображаться в RT.DataVision, и предоставлен дополнительный контекст.
¶ Код 1000
The datasource is too large to query.Вероятно, ваш источник данных стал слишком большим для выполнения текущего запроса, и истекло время ожидания. Вы можете решить эту проблему, уменьшив размер источника данных или изменив запрос, чтобы он обрабатывал только подмножество ваших данных.
¶ Код 1001
The database is under an unusual load.Возможно, время ожидания вашего запроса истекло из-за необычно высокой нагрузки на движок базы данных. Вы можете упростить запрос или дождаться, когда нагрузка на базу данных уменьшится, и повторить попытку.
¶ Код 1002
The database returned an unexpected error.Ваш запрос не выполнен из-за ошибки в базе данных. Это может быть связано с синтаксической ошибкой, ошибкой в вашем запросе или каким-либо другим внутренним сбоем в базе данных. Обычно такая ситуация не является проблемой в RT.DataVision, а проблема с основной базой данных, которая обслуживает ваш запрос.
¶ Код 1003
There is a syntax error in the SQL query. Perhaps there was a misspelling or a typo.Ваш запрос не выполнен из-за синтаксической ошибки в основном запросе. Убедитесь, что все столбцы или таблицы, на которые есть ссылки в запросе, существуют и написаны корректно.
¶ Код 1004
The column was deleted or renamed in the database.Ваш запрос не выполнен, поскольку он ссылается на столбец, которого больше нет в основном источнике данных. Вам следует изменить запрос, чтобы он ссылался на замещающий столбец, или удалить этот столбец из запроса.
¶ Код 1005
The table was deleted or renamed in the database.Ваш запрос не выполнен, поскольку он ссылается на таблицу, которой больше нет в основной базе данных. Вы должны изменить свой запрос, чтобы он ссылался на корректную таблицу.
¶ Код 1006
One or more parameters specified in the query are missing.Ваш запрос не был отправлен в базу данных, так как в нём отсутствует один или несколько параметров. Вы должны определить все параметры, на которые есть ссылки в запросе, в действительном документе JSON. Проверьте корректность написания параметров и валидность синтаксиса документа.
¶ Код 1007
The hostname provided can't be resolved.Имя хоста, указанное при добавлении новой базы данных, является невалидным и не может быть разрешено. Пожалуйста, проверьте, чтобы в имени хоста не было опечаток.
¶ Код 1008
The port is closed.Порт, указанный при добавлении новой базы данных, не открыт. Убедитесь, что номер порта указан корректно, а база данных работает и прослушивает этот порт.
¶ Код 1009
The host might be down, and cannot be reached on the provided port.Хост, указанный при добавлении новой базы данных, похоже, не работает. Кроме того, он не может быть достигнут на указанном порту. Убедитесь, что нет правил файрвола, запрещающих доступ к хосту.
¶ Код 1010
Superset encountered an error while running a command.Произошло что-то непредвиденное, и RT.DataVision обнаружил ошибку при выполнении команды. Пожалуйста, обратитесь к администратору.
¶ Код 1011
Superset encountered an unexpected error.Что-то неожиданное произошло в бэкенде RT.DataVision. Пожалуйста, обратитесь к администратору.
¶ Код 1012
The username provided when connecting to a database is not valid.Пользователь указал имя пользователя, которого нет в базе данных. Убедитесь, что имя пользователя введено корректно и существует в базе данных.
¶ Код 1013
The password provided when connecting to a database is not valid.Пользователь ввёл некорректный пароль. Пожалуйста, проверьте корректность ввода пароля.
¶ Код 1014
Either the username or the password used are incorrect.Либо указанное имя пользователя не существует, либо пароль был введён некорректно. Пожалуйста, проверьте корректность ввода имени пользователя и пароля.
¶ Код 1015
Either the database is spelled incorrectly or does not exist.Либо база данных была написана некорректно, либо она не существует. Проверьте корректность написания.
¶ Код 1016
The schema was deleted or renamed in the database.Схема была либо удалена, либо переименована. Убедитесь, что схема введена корректно и существует.
¶ Код 1017
The user doesn't have the proper permissions to connect to the database.Нам не удалось подключиться к вашей базе данных. Подтвердите, что у вашего аккаунта сервиса есть роли Viewer и Job User в проекте.
¶ Код 1018
One or more parameters needed to configure a database are missing.Присутствовали не все параметры, необходимые для тестирования, создания или редактирования базы данных. Пожалуйста, проверьте, какие параметры необходимы и присутствуют ли они.
¶ Код 1019
The submitted payload has the incorrect format.Убедитесь, что полезная нагрузка запроса имеет корректный формат (например, JSON).
¶ Код 1020
The submitted payload has the incorrect schema.Убедитесь, что полезная нагрузка запроса имеет ожидаемую схему.
¶ Код 1021
Results backend needed for asynchronous queries is not configured.В вашем инстансе RT.DataVision не настроен бэкенд результатов, необходимый для асинхронных запросов. Пожалуйста, свяжитесь с администратором для получения дополнительной помощи.
¶ Код 1022
Database does not allow data manipulation.Для этой базы данных разрешены только операторы SELECT. Обратитесь к администратору, если вам нужно запустить DML (язык обработки данных) в этой базе данных.
¶ Код 1023
CTAS (create table as select) doesn't have a SELECT statement at the end.Последним оператором в запросе, выполняемом как CTAS, должен быть оператор SELECT. Пожалуйста, убедитесь, что последним оператором в запросе является SELECT.
¶ Код 1024
CVAS (create view as select) query has more than one statement.При запуске CVAS запрос должен содержать один оператор. Пожалуйста, убедитесь, что запрос содержит один оператор и не содержит лишних точек с запятой, кроме последней.
¶ Код 1025
CVAS (create view as select) query is not a SELECT statement.При запуске CVAS запрос должен быть оператором SELECT. Пожалуйста, убедитесь, что запрос содержит один оператор, и это оператор SELECT.
¶ Код 1026
Query is too complex and takes too long to run.Отправленный запрос может быть слишком сложным для выполнения в течение времени, установленного вашим администратором RT.DataVision. Проверьте свой запрос и убедитесь, что его можно оптимизировать. Либо обратитесь к администратору, чтобы увеличить время ожидания.
¶ Код 1027
The database is currently running too many queries.База данных может быть перегружена, выполняется слишком много запросов. Повторите попытку позже или обратитесь за помощью к администратору.
¶ Код 1028
One or more parameters specified in the query are malformatted.Запрос содержит один или несколько параметров шаблона некорректного формата. Проверьте свой запрос и убедитесь, что все параметры шаблона заключены в двойные фигурные скобки, например, "{{ ds }}". Затем попробуйте снова выполнить запрос.
¶ Код 1029
The object does not exist in this database.Схема, столбец или таблица не существуют в базе данных.
¶ Код 1030
The query potentially has a syntax error.В запросе может быть синтаксическая ошибка. Проверьте и запустите снова.
¶ Код 1031
The results backend no longer has the data from the query.Результаты запроса могли быть удалены из бэкенда результатов спустя некоторое время. Повторите запрос.
¶ Код 1032
The query associated with the results was deleted.Запрос, связанный с сохранёнными результатами, больше не существует. Повторите запрос.
¶ Код 1033
The results stored in the backend were stored in a different format, and no longer can be deserialized.Результаты запроса были сохранены в формате, который больше не поддерживается. Повторите запрос.
¶ Код 1034
The database port provided is invalid.Убедитесь, что указанный порт базы данных является целым числом от 0 до 65535 (включительно).
¶ Код 1035
Failed to start remote query on a worker.Запрос не был запущен асинхронным воркером. Обратитесь к администратору за дополнительной помощью.
¶ Код 1036
The database was deleted.Операция завершилась неудачно, так как база данных, на которую указывает ссылка, больше не существует. Обратитесь к администратору за дополнительной помощью.
¶ 14 FAQ
¶ 14.1 Можно ли джойнить/запрашивать несколько таблиц одновременно?
В пользовательском интерфейсе Explore или Visualization нельзя. Источник данных RT.DataVision SQLAlchemy может быть только одной таблицей или представлением.
При работе с таблицами решением могла бы быть материализация таблицы, содержащей все поля, необходимые для вашего анализа, скорее всего, посредством некоторого запланированного пакетного процесса.
Представление — это простой логический уровень, который абстрагирует произвольные SQL-запросы в виде виртуальной таблицы. Это может позволить вам JOIN и UNION несколько таблиц, а также применять некоторые трансформации с использованием произвольных выражений SQL. Ограничением является производительность вашей базы данных, поскольку RT.DataVision эффективно запускает запрос поверх вашего запроса (представления). Хорошей практикой может быть ограничение JOIN вашей основной большой таблицы только к одной или нескольким небольшим таблицам и избегание использования GROUP BY, где это возможно, поскольку RT.DataVision будет выполнять свою собственную GROUP BY, а выполнение работы дважды может снизить производительность.
Используете ли вы таблицу или представление, важным фактором является то, достаточно ли быстра ваша база данных, чтобы обслуживать её в интерактивном режиме, чтобы обеспечить хорошее взаимодействие с пользователем в RT.DataVision.
Однако, если вы используете SQL Lab, такого ограничения нет, вы можете написать sql-запрос для JOIN нескольких таблиц, если ваша учётная запись базы данных имеет доступ к таблицам.
¶ 14.2 Насколько большим может быть источник данных?
Он может быть гигантским! RT.DataVision действует как тонкий слой над вашими базами данных или движками данных.
Как упоминалось выше, основным критерием является то, может ли ваша база данных выполнять запросы и возвращать результаты в сроки, приемлемые для ваших пользователей. Многие распределённые базы данных могут выполнять запросы, которые сканируют терабайты в интерактивном режиме.
¶ 14.3 Почему таймаут запросов истёк?
Есть много причин, которые могут привести к длительному таймауту запроса.
Для выполнения длинного запроса из Лаборатории SQL (SQL Lab) по умолчанию RT.DataVision позволяет ему выполняться до 6 часов, прежде чем он будет завершён с помощью celery. Если вы хотите увеличить время выполнения запроса, вы можете указать таймаут в конфигурации. Например:
SQLLAB_ASYNC_TIME_LIMIT_SEC = 60 * 60 * 6RT.DataVision работает на веб-сервере gunicorn, что может привести к превышению времени ожидания веб-запросов. Если вы хотите увеличить значение по умолчанию (50), вы можете указать таймаут при запуске веб-сервера с флагом -t, который выражается в секундах.
superset runserver -t 300Если вы видите таймауты (504 Gateway Time-out) при загрузке дашбордов или исследовании графиков, вы, вероятно, находитесь за шлюзом или прокси-сервером (например, Nginx). Если он не получил своевременный ответ от сервера RT.DataVision (который обрабатывает длинные запросы), эти веб-серверы будут напрямую отправлять клиентам код состояния 504. RT.DataVision имеет лимит таймаута на стороне клиента для решения этой проблемы. Если запрос не вернулся в течение таймаута на стороне клиента (по умолчанию 60 секунд), RT.DataVision отобразит предупреждающее сообщение, чтобы избежать сообщения о таймауте шлюза. Если у вас лимит таймаута шлюза больше, вы можете изменить настройки таймаута в superset_config.py:
SUPERSET_WEBSERVER_TIMEOUT = 60¶ 14.4 Почему карта не отображается в геопространственной визуализации?
Вам необходимо зарегистрировать бесплатную учётную запись на Mapbox.com, получить ключ API и добавить его в superset_config.py по ключу MAPBOX_API_KEY:
MAPBOX_API_KEY = "длиннаястрокабуквиц1фр"¶ 14.5 Как добавить динамические фильтры на дашборд?
Используйте виджет Filter Box, создайте график и добавьте его на дашборд.
Виджет Filter Box позволяет определить запрос для заполнения раскрывающихся списков, которые можно использовать для фильтрации. Чтобы создать список различных значений, мы запускаем запрос и сортируем результат по предоставленной вами метрике, сортируя по убыванию.
В виджете также есть флажок Date Filter, который включает возможности фильтрации по времени на дашборде. После установки флажка и обновления вы увидите раскрывающийся список from и to.
По умолчанию фильтрация будет применяться ко всем срезам, построенным поверх источника данных, который имеет то же имя столбца, на котором основан фильтр. Также необходимо, чтобы этот столбец был отмечен как Is Filterable на вкладке Columns редактора Edit Dataset.
Чтобы определённые виджеты не отфильтровывались на дашборде, необходимо отредактировать дашборд и отредактировать на форме поле JSON Metadata, а точнее ключ filter_immune_slices, который получает массив идентификаторов sliceId, на которые никогда не должна влиять фильтрация на уровне дашборда.
{
"filter_immune_slices": [324, 65, 92],
"expanded_slices": {},
"filter_immune_slice_fields": {
"177": ["country_name", "__time_range"],
"32": ["__time_range"]
},
"timed_refresh_immune_slices": [324]
}В приведённом выше blob json срезы 324, 65 и 92 не будут затронуты какой-либо фильтрацией на уровне дашборда.
Теперь обратите внимание на ключ filter_immune_slice_fields. Он позволяет внести более конкретные связи и определить для конкретного slice_id, какие поля фильтра следует игнорировать.
Обратите внимание на использование ключевого слова __time_range, которое зарезервировано для работы с упомянутой выше фильтрацией временных границ.
Но что происходит с фильтрацией при работе со срезами из разных таблиц или баз данных? Если имя столбца является общим, фильтр будет применён.
¶ 14.6 Как ограничить время обновления на дашборде?
По умолчанию функция обновления по времени дашборда позволяет автоматически повторно запрашивать каждый срез дашборда в соответствии с установленным расписанием. Однако иногда вам не нужно обновлять все срезы, особенно если некоторые данные перемещаются медленно или выполняются тяжёлые запросы. Чтобы исключить определённые срезы из процесса синхронизированного обновления, добавьте ключ timed_refresh_immune_slices в поле JSON Metadata дашборда:
{
"filter_immune_slices": [],
"expanded_slices": {},
"filter_immune_slice_fields": {},
"timed_refresh_immune_slices": [324]
}В приведённом выше примере, если для дашборда задано обновление по времени, каждый срез, кроме 324, будет автоматически повторно запрашиваться по расписанию.
Обновление среза также будет происходить в течение указанного периода. Вы можете отключить это смещение, установив для stagger_refresh значение false, и изменить период смещения, установив для stagger_time значение в миллисекундах в поле JSON Metadata:
{
"stagger_refresh": false,
"stagger_time": 2500
}В примере весь дашборд будет обновляться сразу, если периодическое обновление включено. Время смещения 2,5 секунды игнорируется.
¶ 14.7 Почему ‘flask fab’ или RT.DataVision зависает/не отвечает при запуске (домашний каталог смонтирован по NFS)?
По умолчанию RT.DataVision создаёт и использует базу данных SQLite в ~/.superset/superset.db. Известно, что SQLite плохо работает при использовании в NFS из-за неработающей имплементации блокировки файлов в NFS.
Вы можете переопределить этот путь, используя переменную среды SUPERSET_HOME.
Другой обходной путь — изменить место, где RT.DataVision хранит базу данных sqlite, добавив в superset_config.py следующее:
SQLALCHEMY_DATABASE_URI = 'sqlite:////new/location/superset.db'Подробнее о конфигурировании RT.DataVision с помощью конфигурационного файла можно прочитать в разделе Конфигурирование RT.DataVision.
¶ 14.8 Что делать, если схема таблицы изменилась?
Схемы таблиц развиваются, и RT.DataVision должен учитывать это. Довольно часто в жизненном цикле дашборда требуется добавить новое измерение или метрику. Чтобы RT.DataVision мог обнаружить ваши новые столбцы, всё, что вам нужно сделать, это перейти в Data > Datasets, щёлкнуть значок редактирования рядом с набором данных, схема которого изменилась, и нажать Sync columns from source на вкладке Columns. Новые столбцы будут объединены. После этого вы можете повторно отредактировать таблицу, чтобы настроить вкладку Columns, установить соответствующие флажки и снова сохранить.
¶ 14.9 Какой движок базы данных можно использовать в качестве бэкенда для RT.DataVision?
Бэкенд базы данных — это база данных OLTP, используемая RT.DataVision для хранения своей внутренней информации, такой как ваш список пользователей, срезов и определений дашбордов.
RT.DataVision тестируется с использованием Mysql, Postgresql и Sqlite для его бекэндом. Рекомендуется установить RT.DataVision на один из этих серверов баз данных для производственной среды.
Использование колочных хранилищ, баз данных без OLTP, таких как Vertica, Redshift или Presto, в качестве бэкенда базы данных просто не будет работать, поскольку эти базы данных не предназначены для такого типа рабочей нагрузки. Установка с Oracle, Microsoft SQL Server или других базах данных OLTP может работать, но не тестировалась.
Обратите внимание, что практически любые базы данных с интеграцией SqlAlchemy должны отлично работать в качестве источника данных для RT.DataVision, но не в качестве бэкенда OLTP.
¶ 14.10 Как настроить аутентификацию и авторизацию OAuth?
Вы можете взглянуть на этот пример конфигурации Flask-AppBuilder.
¶ 14.11 Как установить фильтр по умолчанию на дашборде?
Просто примените фильтр и сохраните дашборд, пока фильтр активен.
¶ 14.12 Есть ли способ использовать определённые цвета на дашборде?
Это возможно для каждого дашборда путём предоставления маппинга меток с цветами в атрибуте JSON Metadata с использованием ключа label_colors.
{
"label_colors": {
"Girls": "#FF69B4",
"Boys": "#ADD8E6"
}
}¶ 14.13 Работает ли RT.DataVision с [вставьте сюда движок базы данных]?
В п. 11 Настройки подключения БД представлен лучший обзор поддерживаемых баз данных. Движки баз данных, не указанные в той статье, также могут работать.
Чтобы движок базы данных поддерживался в RT.DataVision через коннектор SQLAlchemy, необходимо наличие совместимого с Python диалекта SQLAlchemy, а также определённого драйвера DBAPI. База данных с ограниченной поддержкой SQL также может работать. Например, можно подключиться к Druid через коннектор SQLAlchemy, хотя Druid не поддерживает join и подзапросы. Ещё один ключевой элемент поддержки базы данных — интерфейс RT.DataVision Database Engine Specification. Этот интерфейс позволяет определять конфигурации и логику для конкретной базы данных, выходящие за рамки SQLAlchemy и DBAPI. Он включает в себя такие функции, как:
- Функция SQL, связанная с датой, которая позволяет RT.DataVision извлекать разную степень детализации времени при выполнении запросов временных рядов.
- Поддерживает ли движок подзапросы. Если нет, RT.DataVision может выполнять двухэтапные запросы, чтобы компенсировать ограничение.
- Методы обработки логов и определения процента выполнения запроса.
- Технические сведения о том, как обрабатывать курсоры и соединения, если драйвер не является стандартным DBAPI.
Помимо коннектора SQLAlchemy, также возможно, хотя и гораздо сложнее, расширить RT.DataVision и написать свой собственный коннектор. Единственным примером этого на данный момент является коннектор Druid, который заменяется растущей поддержкой SQL в Druid и недавней доступностью драйвера DBAPI и SQLAlchemy. Если база данных, которую вы планируете интегрировать, имеет какую-либо поддержку SQL, вероятно, предпочтительнее пойти по пути SQLAlchemy. Обратите внимание, что для того, чтобы собственный коннектор был возможен, база данных должна иметь поддержку выполнения запросов типа OLAP и должна иметь возможность выполнять действия, типичные для базового SQL:
- Агрегация данных.
- Применение фильтров.
- Применение фильтров типа HAVING.
- Знание о схеме, выставление столбцов и типов.
¶ 14.14 Что делает смещение часов в представлении Edit Dataset?
В представлении Edit Dataset можно указать смещение по времени. Это поле позволяет настроить количество часов, которое будет добавлено или вычтено из столбца времени. Это можно использовать, например, для преобразования времени UTC в местное время.