Внимание. Для интерфейса RT.DataVision можно настроить два языка — английский и русский. Поэтому в данной инструкции наименования элементов интерфейса описываются для обоих языков: сначала на русском, а далее в скобках наименование элемента на английском языке (при наличии). Например, Данные (Data).
¶ 1. Знакомство с RT.DataVision
Внимание. В зависимости от выданных прав элементы и функции интерфейса могут различаться.
После входа в интерфейс RT.DataVision появится Главная (Home) страница.
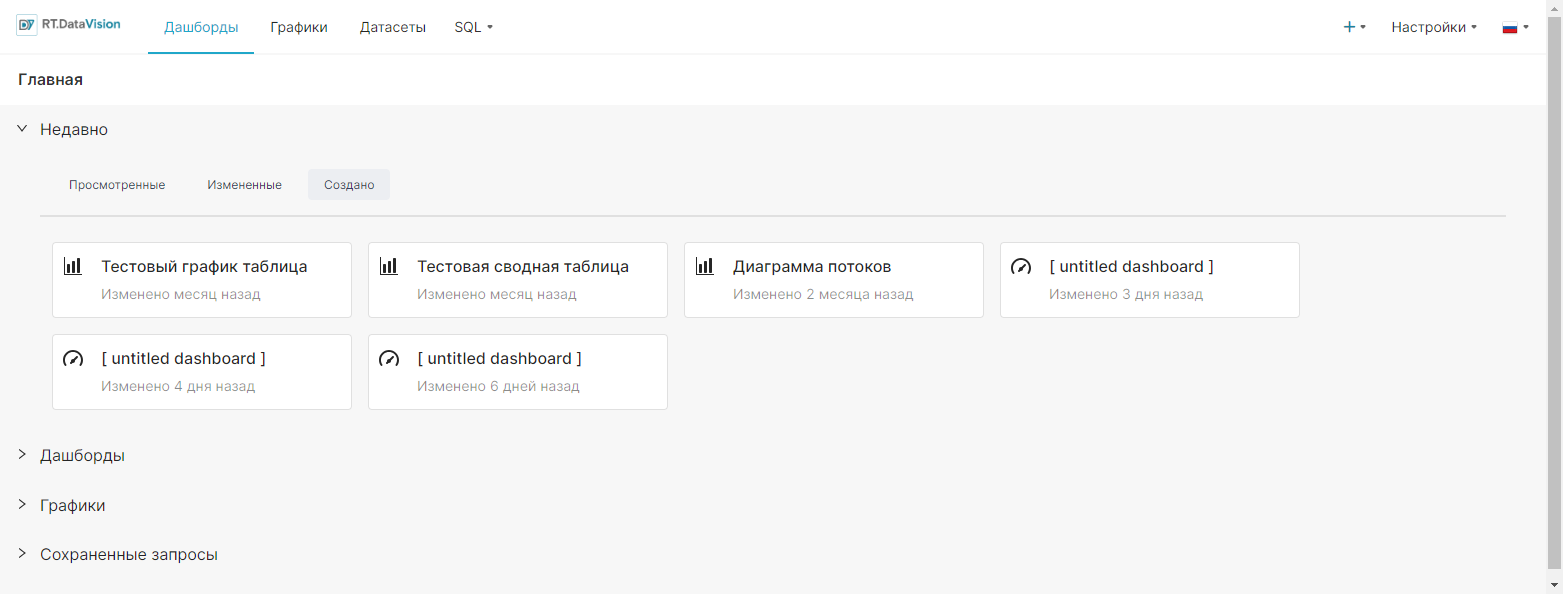
На верхней панели страницы Главная (Home) расположены разделы, отвечающие за функциональность RT.DataVision:
- Дашборды (Dashboards) — предоставляет следующие возможности управления дашбордами:
- просматривать все дашборды, имеющиеся в RT.DataVision (при наличии необходимых прав);
- создавать новые;
- изменять существующие;
- удалять.
- Графики (Charts) — предоставляет следующие возможности управления графиками, созданные пользователями RT. DataVision (при наличии необходимых прав):
- создать новые;
- редактировать существующие;
- удалять.
- Датасеты (Datasets) – предоставляет следующие возможности управления датасетами:
- просмотр перечня имеющихся физических и виртуальных датасетов;
- создать новые;
- редактировать существующие;
- удалять.
- SQL — предоставляет возможности управления SQL-запросами, размещенные на следующих вкладках:
- Лаборатория SQL (SQL Lab) – редактор для создания SQL-запросов и построения графика;
- Сохраненные запросы (Saved Queries) – выводит все сохранённые SQL-запросы;
- История запросов (Query History) – история формирования SQL-запросов.
- Данные (Data) — содержит вкладки:
- Подключить базу данных (Connect database) – создание нового подключения к базе данных;
- Загрузка CSV в базу данных (Upload CSV to database) – настройка CSV для базы данных;
- Загрузка колоночного файла в базу данных (Uploading column file to database) – конфигурация колонок к базе данных;
- Загрузка файла Exel в базу данных (Uploading Excel file to database) – настройка Excel для работы с базой данных.
- SQL-запрос (SQL query) – редактор для создания SQL-запросов и построения графика (Лаборатория SQL).
- График (Chart) – создание нового графика.
- Дашборд (Dashboard) – создание нового дашборда.
- Настройки (Settings) — предоставляет следующие возможности администрирования RT.DataVision:
- Безопасность (Security) – раздел, позволяющий управлять безопасностью RT.DataVision:
- Список пользователей (List Users) — предоставляет следующие возможности управление пользователями:
- заведение нового пользователя;
- назначение ролей;
- редактирование;
- удаление.
- Список ролей (List Roles) — предоставляет следующие возможности управление ролями RT.DataVision:
- создание новых ролей;
- настройка и назначение прав для роли;
- редактирование;
- удаление.
- Регистрация пользователей (User Registrations) — управление регистрацией пользователей;
- Безопасность на уровне строк (Row Level Security) — управление безопасностью на уровне строк, позволяющая более тонко настроить доступ пользователей к данным;
- Журнал действий (Action Log) — управление логированием RT.DataVision;
- Список пользователей (List Users) — предоставляет следующие возможности управление пользователями:
- Данные (Data) – раздел, позволяющий управлять базами данных:
- Базы данных (Databases) – содержит перечень всех подключённых баз данных к RT.DataVision, позволяющий:
- подключить новую базу данных;
- отредактировать имеющееся подключение;
- удалить подключение.
- Базы данных (Databases) – содержит перечень всех подключённых баз данных к RT.DataVision, позволяющий:
- Управление (Manage) – раздел, позволяющий осуществлять управление RT.DataVision:
- CSS шаблоны (CSS Templates) — управление шаблонами CSS для стилизации дашбордов;
- Отчеты и оповещения (Alerts & Reports) — управление оповещениями и рассылкой;
- Слои аннотаций (Annotation Layers) — управлением слоями аннотаций для добавления контекста на графики.
- Пользователь (User) – раздел , позволяющий управлять текущим пользователем:
- Профиль (Profile) – профиль текущего пользователя в RT.DataVision, в котором отображаются:
- общие сведения об учетной записи;
- созданные пользователем Дашборды и Графики;
- последние действия;
- назначенные роли.
- Инфо (Info) – данные текущего пользователя. Доступны действия по изменению пароля и редактировании имени и фамилии.
- Выход из системы (Logout) – выход из RT.DataVision.
- Профиль (Profile) – профиль текущего пользователя в RT.DataVision, в котором отображаются:
- О нас (About) – используемая версия RT.DataVision.
Ниже на Главной (Home) странице размещаются следующие области:
- Недавно (Recents) — содержит перечень дашбордов и графиков, с которыми взаимодействовал текущий пользователь в последнее время. На вкладках Просмотренные (Viewed), Измененные (Edited) и Создано (Created) размещаются плитки объектов, которые были недавно просмотрены, изменены или созданы. При нажатии на плитку откроется выбранный объект.
- Дашборды (Dashboards) — содержит перечень дашбордов и кнопку +Дашборд (+Dashboards) для создания нового дашборда. Дашборды в данной области разделены на следующие категории:
- Избранное (Favorite);
- Мои (Mine);
- Все (All).
- Графики (Charts) — содержит перечень графиков и кнопку +График (+Charts) для создания нового графика. Графики в данной области разделены на следующие категории:
- Избранное (Favorite);
- Мои (Mine);
- Все (All).
- Сохранённые запросы (Saved Queries) — содержит перечень созданных и сохраненных пользователем SQL-запросов и кнопку +SQL-запрос (+SQL query) для создания нового запроса.
Для получения первых навыков по работе с инструментом воспользуйтесь разделом Создание первого дашборда.
¶ 2. Создание первого дашборда
Раздел предназначен для конечных пользователей, которые будут использовать RT.DataVision для анализа и исследования данных, создания графиков и дашбордов.
В разделе описаны следующие сценарии взаимодействия пользователя с RT.DataVision:
- подключение RT.DataVision к новой базе данных;
- формирование таблицы в этой БД;
- добавление графика к дашборду.
¶ 2.1. Подключение к новой базе данных
Примечание. Подключение к новой базе данных доступно только для роли Admin. Проверьте, создано ли подключение к необходимой БД, так как возможно оно уже существует и можно сразу перейти ко второму пункту пошаговой инструкции. В противном случае, необходимо обратиться к администратору с просьбой создать необходимое подключение к БД.
RT.DataVision не имеет уровня хранения данных, вместо этого RT.DataVision подключается к существующей базе данных или хранилищу данных, поддерживающим SQL.
Для того, чтобы иметь возможность запрашивать и визуализировать данные из БД, необходимо добавить учётные данные для подключения к БД.
Примечание. При использовании RT.DataVision локально через Docker compose (раздел Локальное развёртывание RT.DataVision с помощью Docker Compose), пропустите этот шаг, потому что база данных Postgres с именем examples включена и предварительно настроена в RT.DataVision.
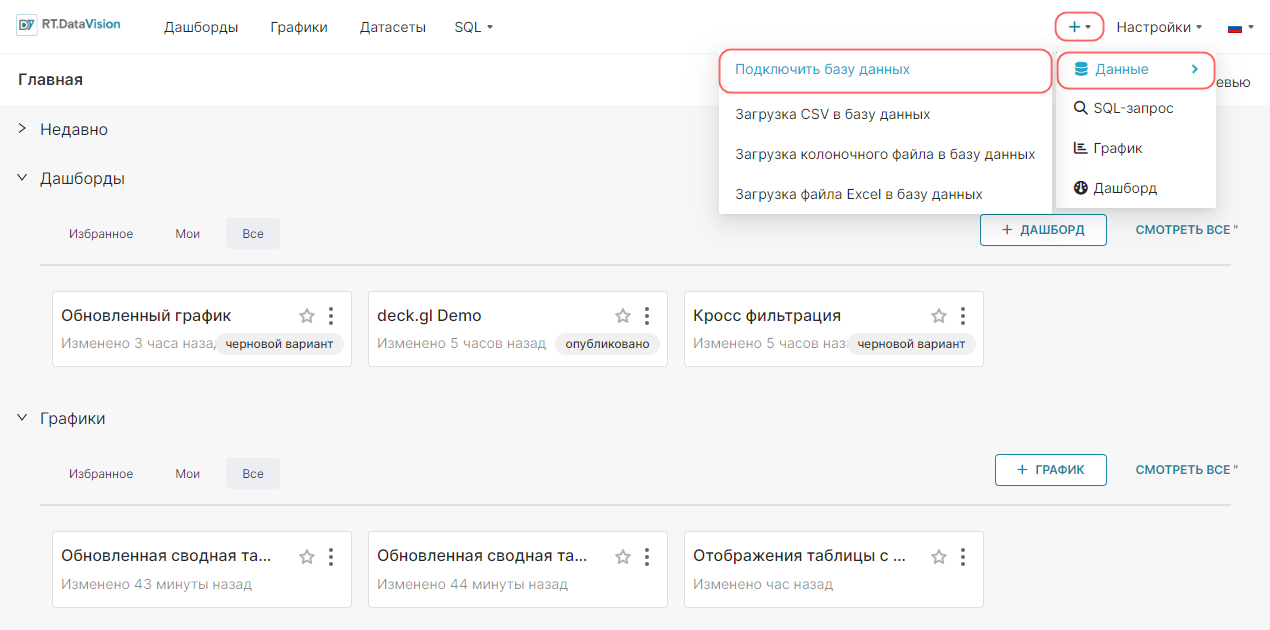
Для создания подключения к новой базе данных:
1. В дополнительном меню + выберите Данные (Data) → Подключить базу данных (Connect database).
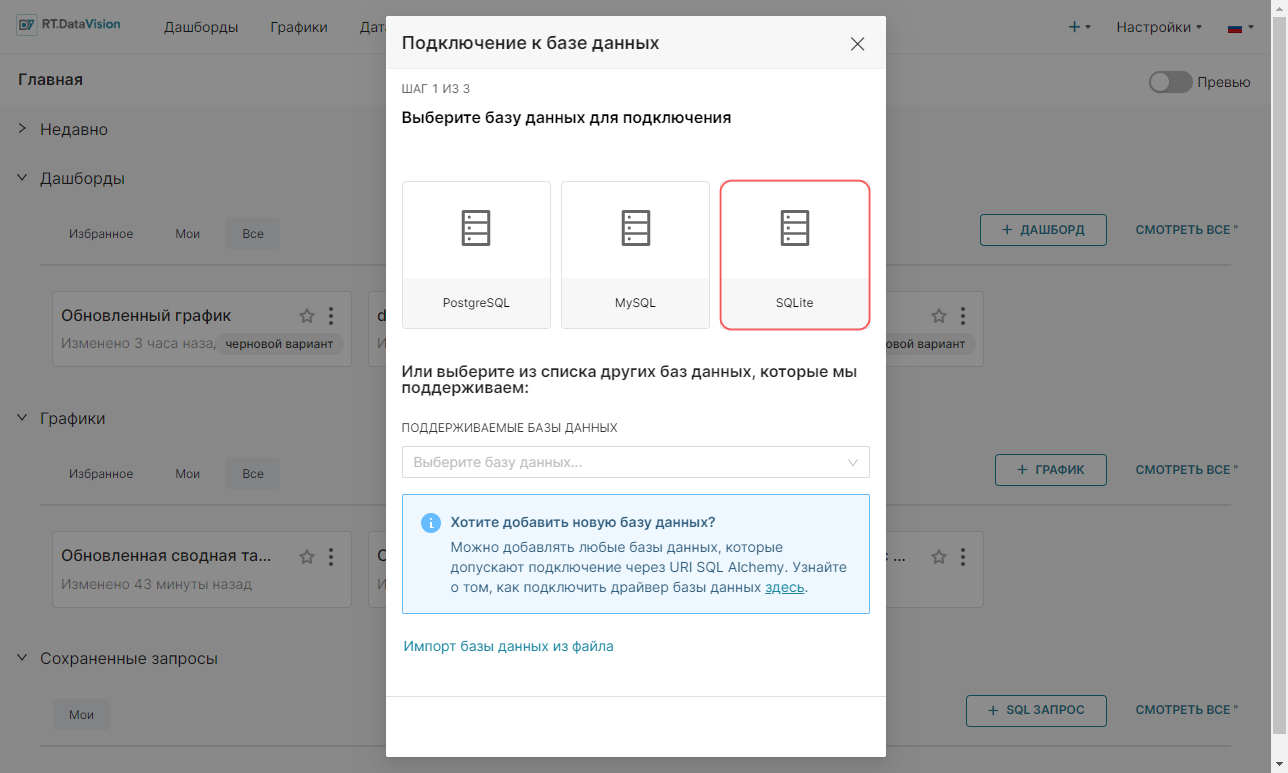
2. Нажмите на плитку SQLite в открывшемся окне Подключение к базе данных (Connect a database).
3. Укажите Отображаемое имя (Display name) и SQLAlchemy URI на вкладке Базовые (Basic) в окне подключения. Конфигурирование дополнительных параметров доступно на вкладке Расширенные (Advanced), но для данной пошаговой инструкции достаточно указать только основные параметры на вкладке Базовые (Basic).
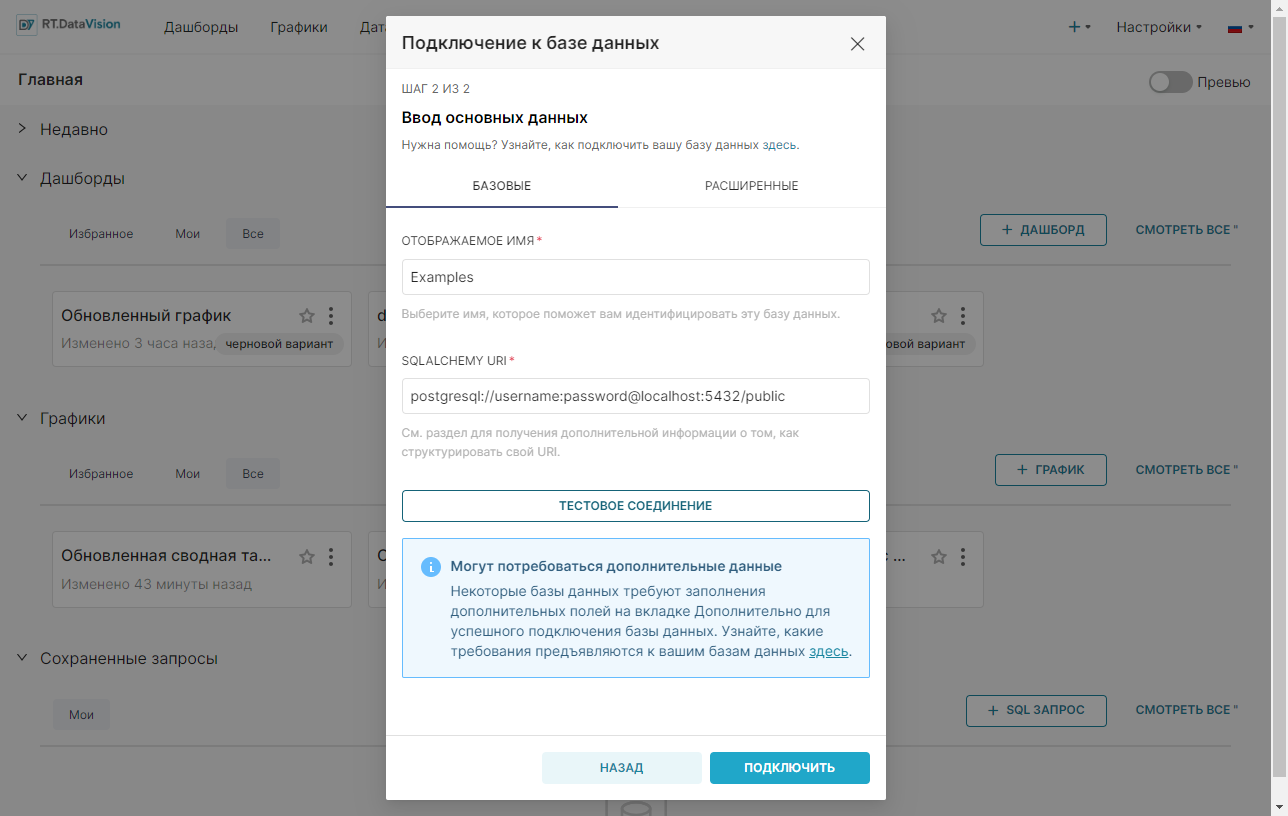
Как указано информационном блоке под полем SQLAlchemy URI, при необходимости обратитесь к документации SQLAlchemy по созданию новых URI подключения для целевой базы данных.
5. Нажмите кнопку Тестовое соединение (Test Connection), для проверки соединения с БД.
6. Сохраните конфигурацию с помощью кнопки Подключить (Connect).
После выполнения всех действий новый источник данных будет добавлен в RT.DataVision.
¶ 2.2. Регистрация новой таблицы
После конфигурирования источника данных необходимо выбрать определённые таблицы, называемые датасетами в RT.DataVision, которые будут использоваться для выполнения запросов.
Для добавления нового датасета:
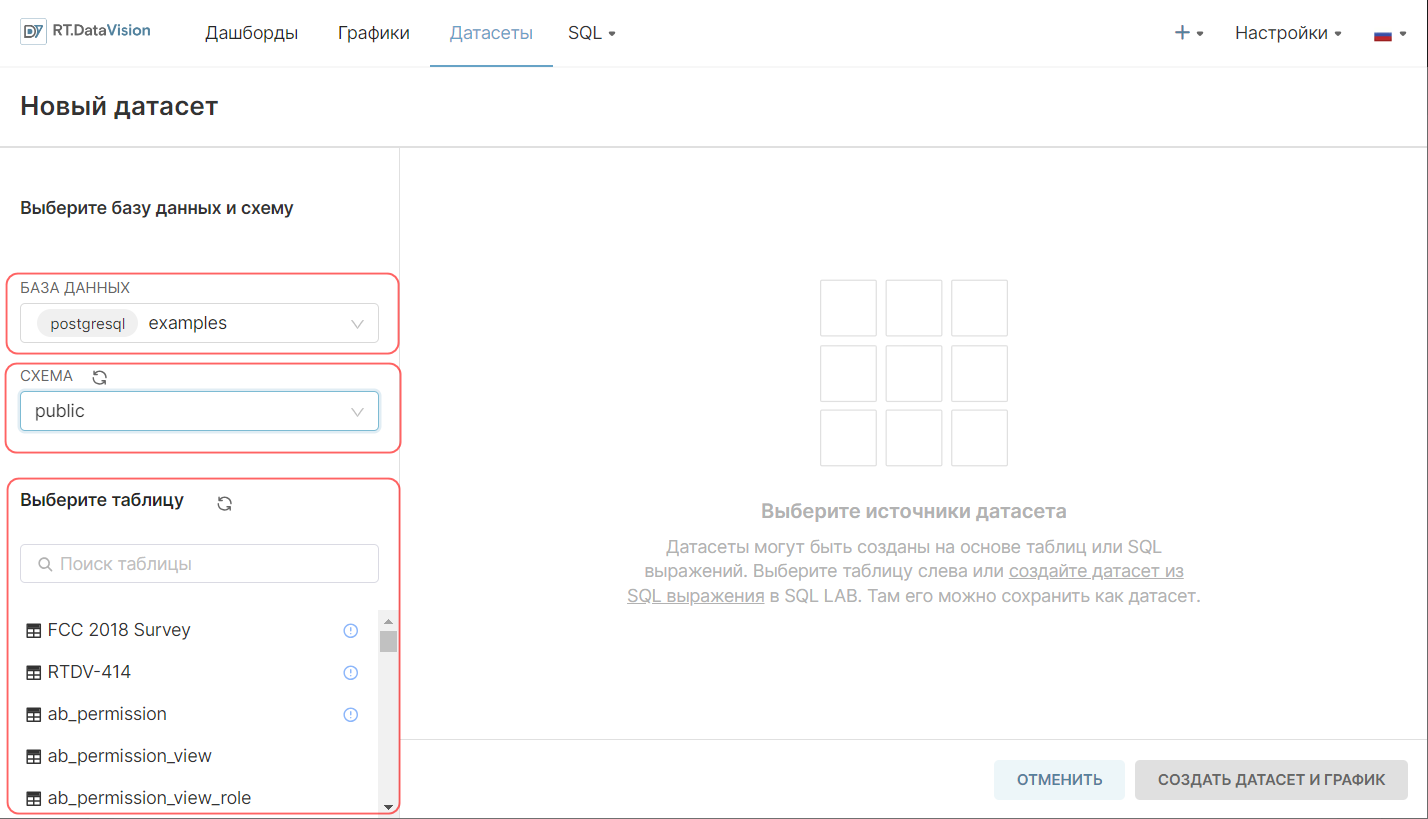
1. Перейдите в раздел Датасеты (Datasets) и нажмите кнопку + Датасет (+ Dataset). Откроется форма создания нового датасета.
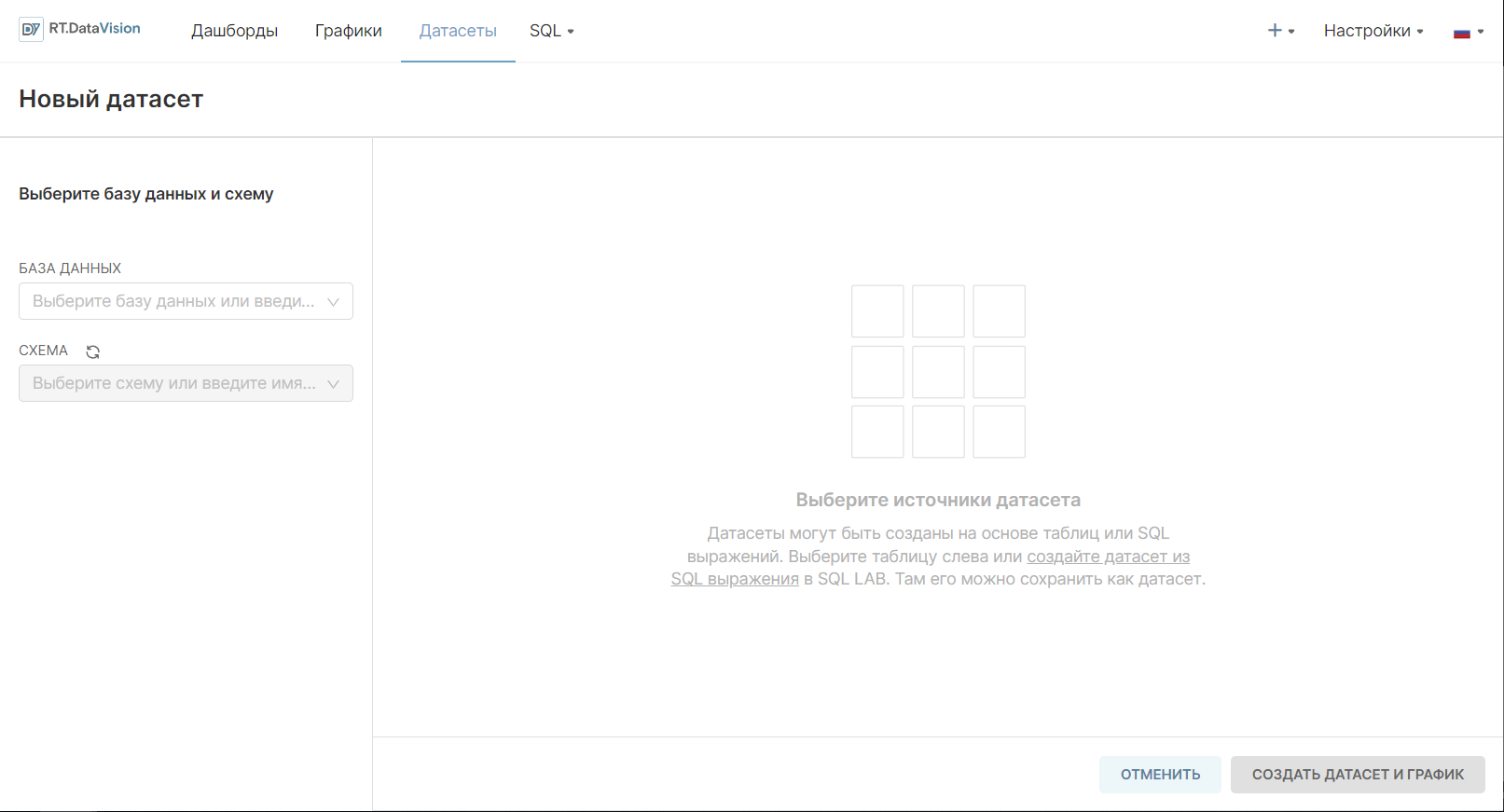
2. Выберите необходимую БД в поле База данных (Database).
3. Укажите схему БД в поле Схема (Schema).
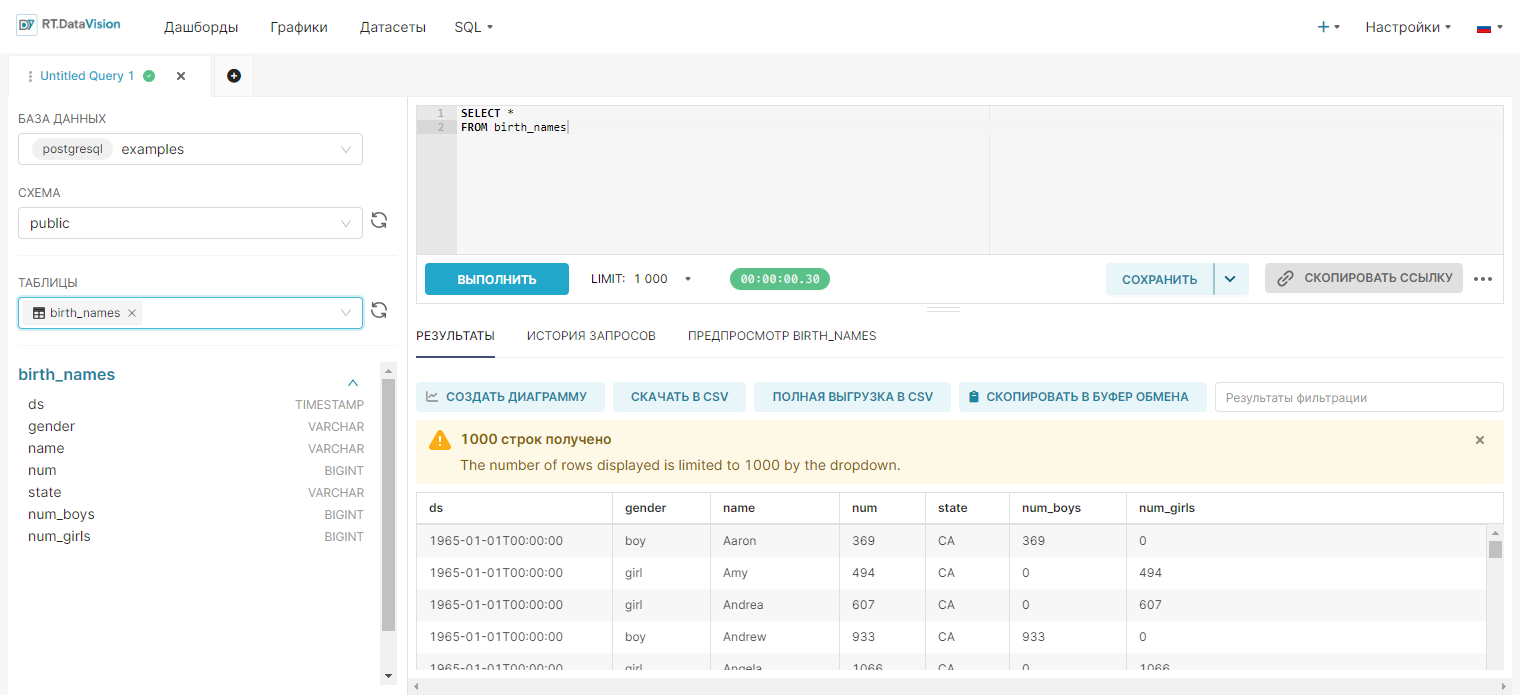
4. Выберите из выпадающего списка необходимую таблицу в поле Выберите таблицу (See table schema). В примере ниже регистрируется таблица birth_names из БД examples.
5. Нажмите кнопку Создать датасет и график Add (Create dataset and chart).
После выполнения действий созданные датасет появится в списке датасетов.
¶ 2.3. Настройка свойств столбца
После регистрации датасета необходимо сконфигурировать свойства столбца для дальнейшей его обработки в воркфлоу в Исследовать (Explore). Для этого :
1. Перейдите в раздел Датасеты (Datasets).
2. Выберите необходимый датасет и нажмите на значок Редактировать (Edit). Для быстрого поиска датасета воспользуйтесь фильтрами.
3. Перейдите на вкладку Столбцы (Columns) в открывшемся окне редактирования датасета.
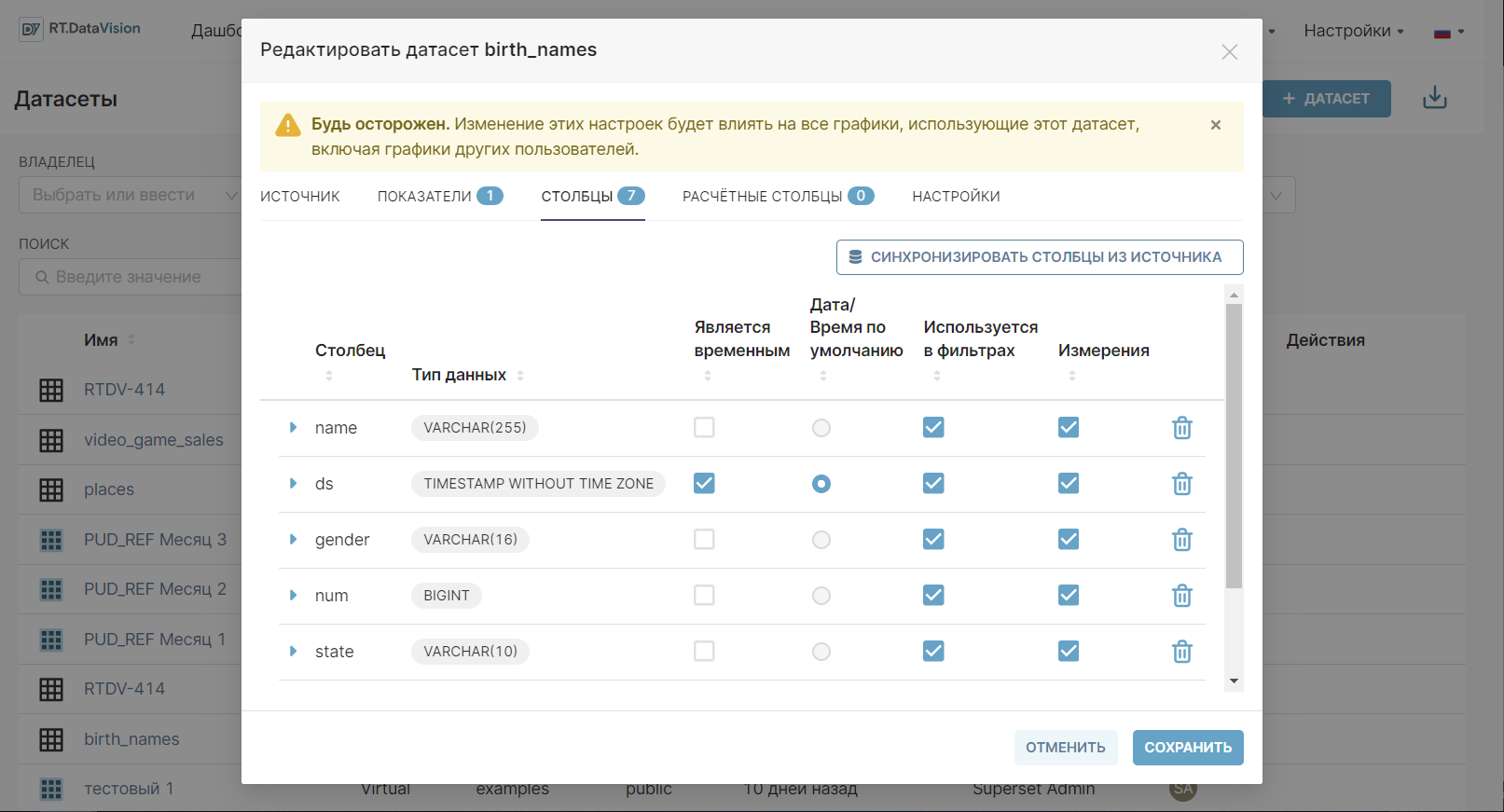
4. Настройте свойства таблицы с помощью следующих столбцов:
- Является временны́м (Is temporal) — отметьте значения, которые являются отметками времени и которые следует использовать на графиках в качестве временных рядов;
- Дата/Время по умолчанию (Default datatime) — выберите значение, которое будет использоваться в качестве временного ряда по умолчанию;
- Используется в фильтрах (Is filterable) — отметьте значения, которые могут быть использованы на графике в качестве фильтров;
- Измерения (Is dimension) — отметьте значения, которые будут использоваться как измерения на графике.
3. Нажмите Сохранить (Save) для сохранения внесенных изменений.
¶ 2.4. Настройка семантического слоя
RT.DataVision имеет тонкий семантический слой, который облегчает работу аналитиков.
Семантический слой RT.DataVision может хранить 2 типа вычисляемых данных:
- Виртуальные метрики — SQL-запросы, которые объединяют значения из нескольких столбцов и делают их доступными в виде столбцов для визуализации в Исследовать (Explore). Использование агрегированных функций разрешено и рекомендуется для метрик;
- Виртуальные расчётные столбцы — SQL-запросы, которые кастомизируют внешний вид и поведение определённого столбца. Использование агрегированных функций не разрешено в расчётных столбцах.
Для настройки семантического слоя:
1. Перейдите в раздел Датасеты (Datasets).
2. Выберите необходимый датасет и нажмите на значок Редактировать (Edit). Для быстрого поиска датасета воспользуйтесь фильтрами.
3. Перейдите на вкладку Показатели (Metrics) в открывшемся окне редактирования датасета.
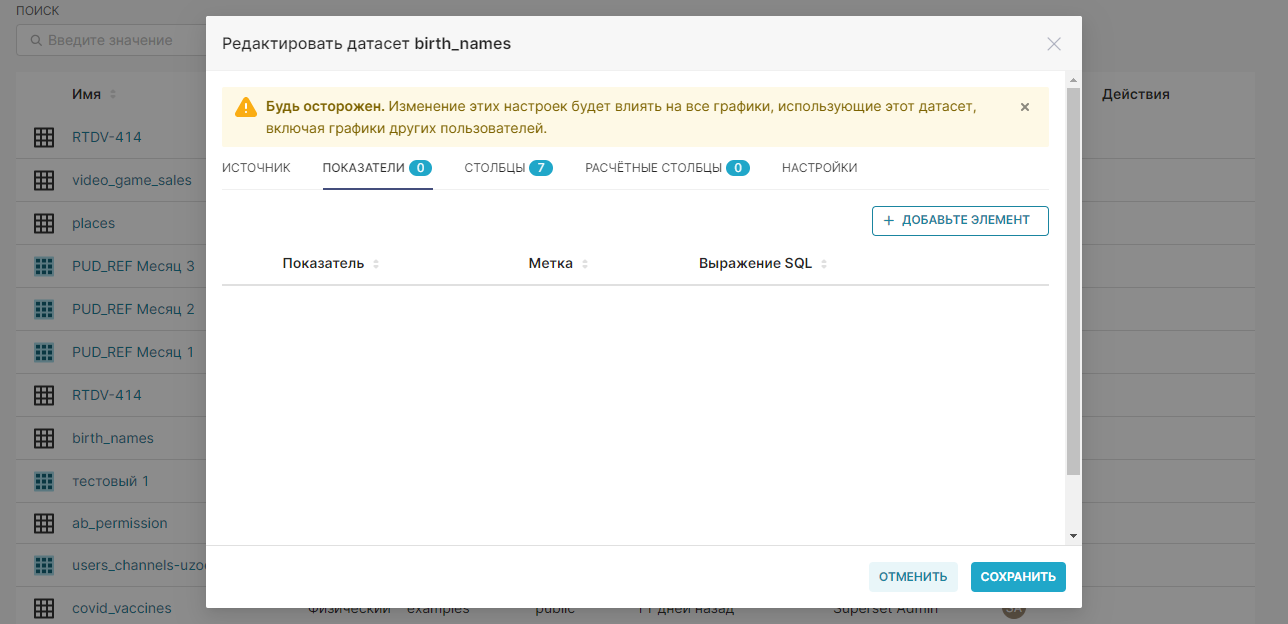
4. Добавьте виртуальные метрики для датасета с помощью кнопки + Добавьте элемент (+ Add item). Укажите для метрик SQL-запросы SUM(num) и COUNT(*) и дайте названия этим метрикам sum_num и count соответственно.
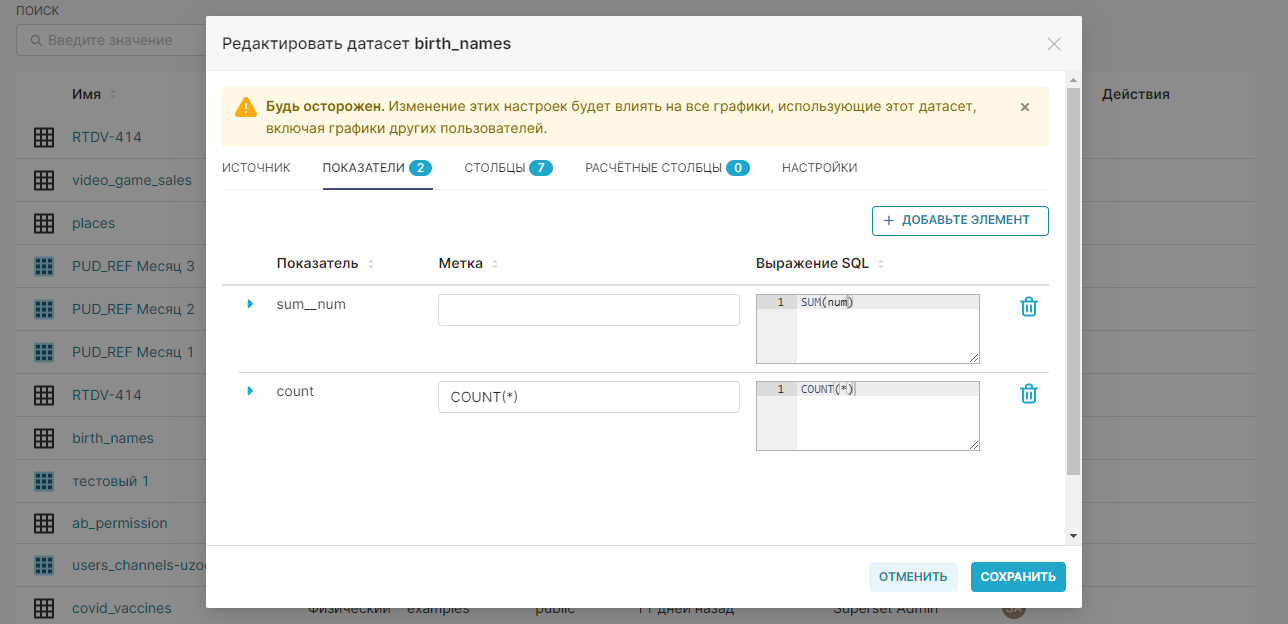
5. Добавьте виртуальные расчётные столбцы для датасета на вкладке Расчётные столбцы (Calculated columns). Нажмите + Добавьте элемент (+ Add item), укажите название расчётного столбца как num_california, заполните для него SQL-запрос (для данного примера — CASE WHEN state = 'CA' THEN num ELSE 0 END) и при необходимости скорректируйте свойства добавленного расчётного столбца.
4. Нажмите Сохранить (Save), чтобы добавить к датасету новые метрики и расчётные столбцы.
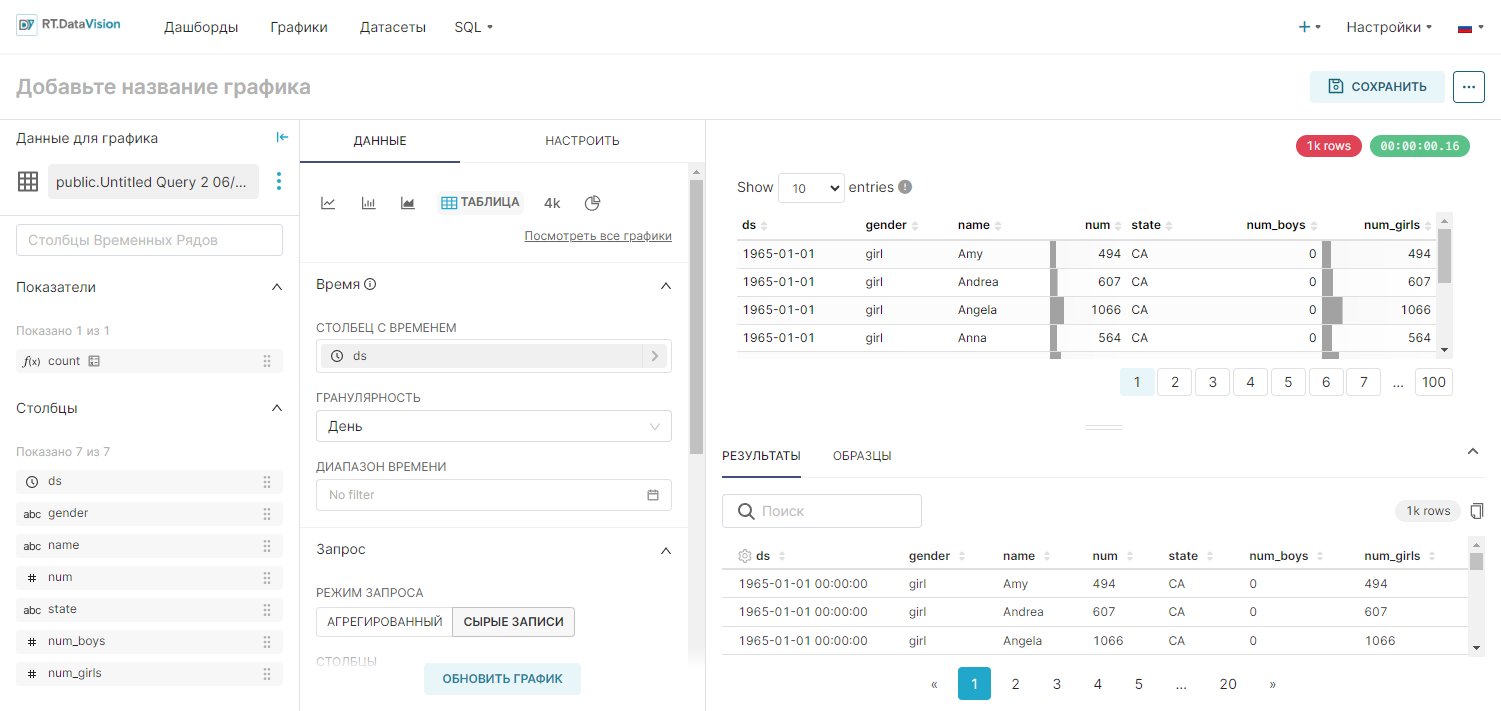
¶ 2.5. Создание графиков в Исследовать (Explore)
RT.DataVision имеет 2 основных интерфейса для изучения данных:
- Исследовать (Explore) — конструктор визуализаций без использования кода: выбор датасета → выбор графика → кастомизация внешнего вида → публикация.
- Лаборатория SQL (SQL Lab) — SQL IDE для очистки, объединения и подготовки данных для воркфлоу Исследовать (Explore).
Для создания графика в Исследовать (Explore) перейдите в раздел Датасеты (Datasets). В открывшемся окне щёлкните по имени датасета, который необходимо использовать при создании графика.
Откроется воркфлоу Исследовать (Explore), предназначенный для изучения данных в датасете и построения графика, который содержит:
| Представление Датасет (Dataset), расположенное с левой стороны, содержит список метрик и столбцов, ограниченных текущим выбранным датасетом; |
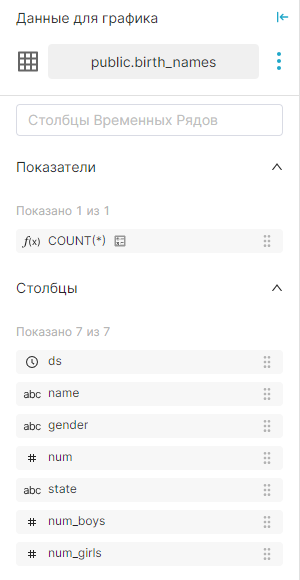 |
|
|
Используя вкладки Данные (Data) и Настроить (Customize), можно изменить:
|
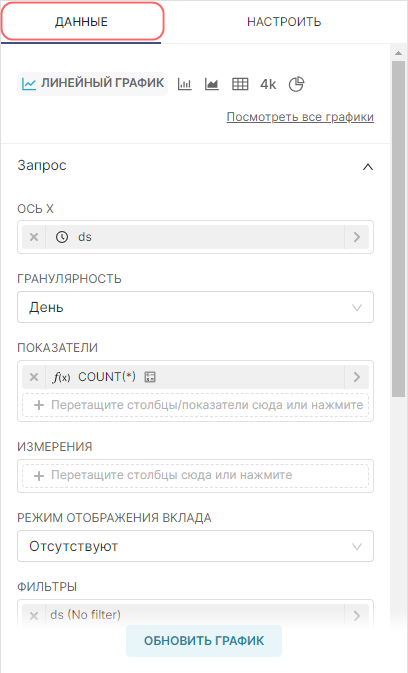 |
 |
|
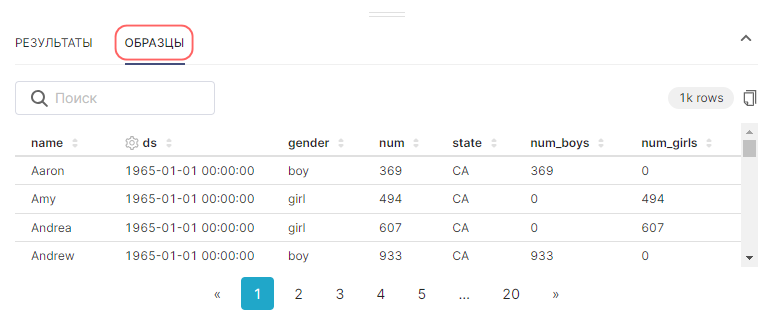
Предварительный просмотр Результаты (Results) и Образцы (Samples) под областью графика предоставляет полезную информацию:
|
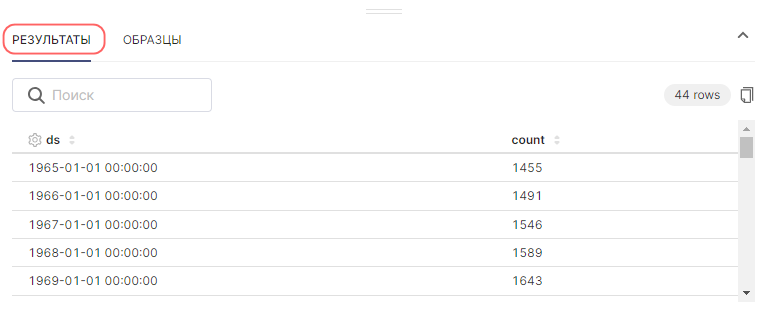 |
|
 |
||
При настройки графика с использованием полей из представлений, не забудьте нажимать кнопку Обновить график (Update chart), чтобы получить визуальную обратную связь.
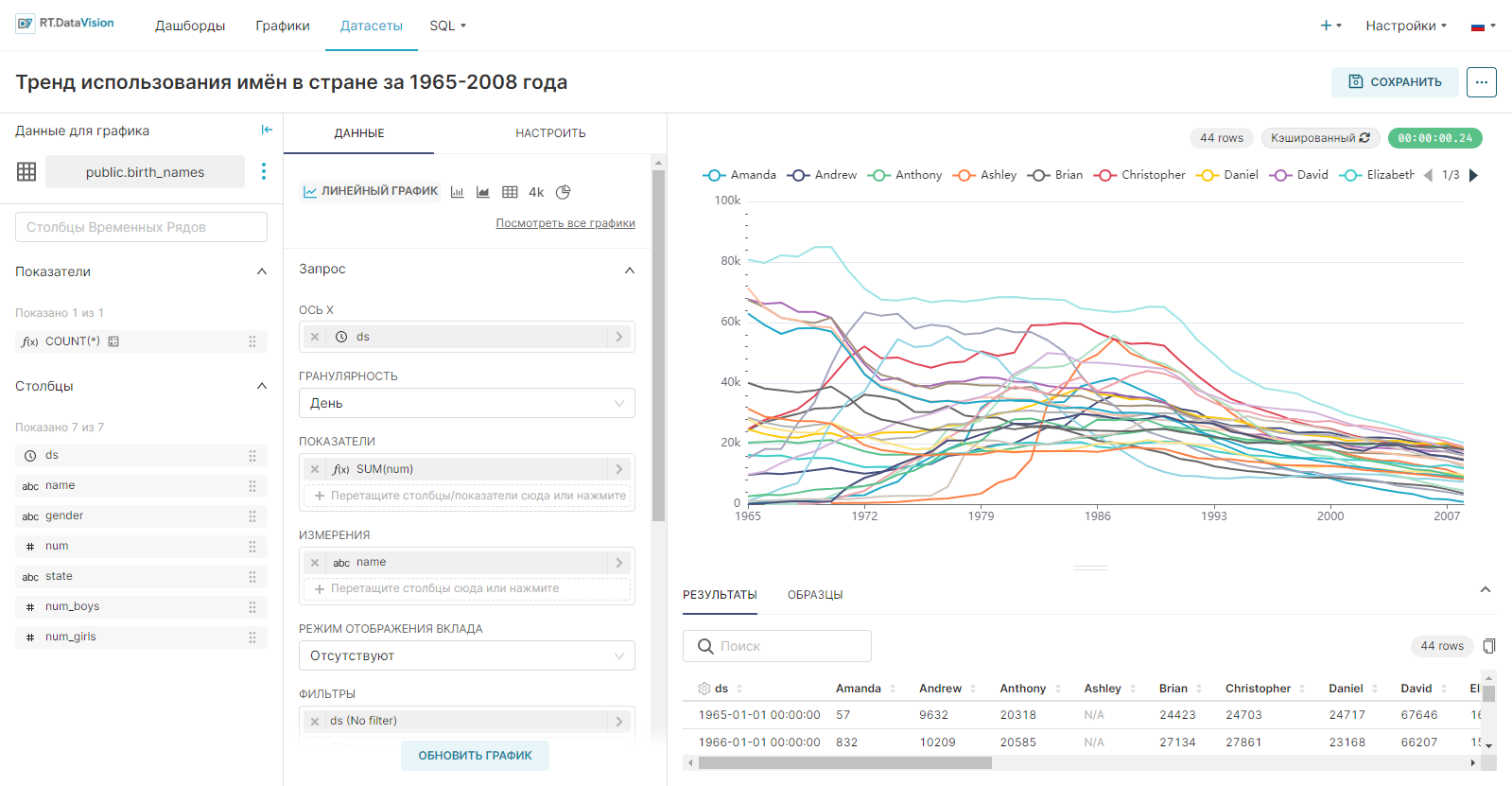
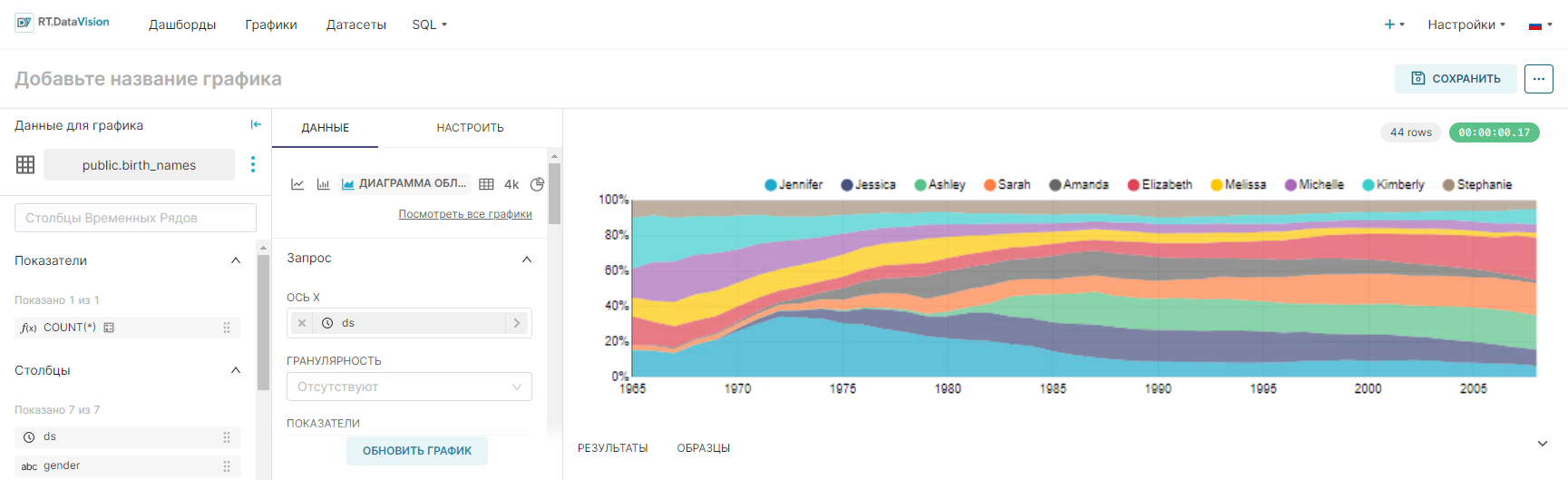
Пример создания линейного графика на основе настроенного датасета, который покажет тренды имён в стране с 1965 по 2008 год:
- В качестве типа визуализации выберите Линейный график (Line Chart) в поле Тип визуализации (Visualization type);
- Для временного ряда Ось X (X-axis) используйте столбец ds датасета;
- Добавьте метрику, данные которой будут использоваться для построения графика и выберите агрегат для неё. Перетащите столбец num из представления датасета в поле Показатели (Metrics) на вкладке Данные (Data). В отобразившемся окне в поле Агрегированный (Aggregate) выберите значение SUM и сохраните настройки;
- Добавьте измерение, которое объединит данные из метрики в необходимые группы. Из датасета перетащите столбец name в поле Измерения (Dimensions) на вкладке Данные (Data);
- Установите ограничение на отображение настроенных групп на графике: в поле Лимит кол-ва рядов (Series limit) на вкладке Данные (Data) установите значение 25;
- Остальные настройки оставьте по умолчанию.
- Нажмите кнопку Создать диаграмму (Create chart).
Результат построения линейного графика для визуализации данных о трендах использования имён в стране за 1965-2008 года:
¶ 2.6. Создание дашборда
Для создания дашборда:
1. Сохраните график с помощью кнопки Сохранить (Save). В открывшемся окне Сохранить график (Save chart) существует возможность:
- Сохранить график и добавить его на уже существующий дашборд — т.е. выбрать существующий дашборд из выпадающего списка Добавить в дашборд (Add to dashboard);
- Сохранить график и добавить его на новый дашборд — т.е. вручную указать название нового дашборда в поле Добавить в дашборд (Add to dashboard) для его создания.
На рисунке ниже показано сохранение графика на новом дашборде Тренды.
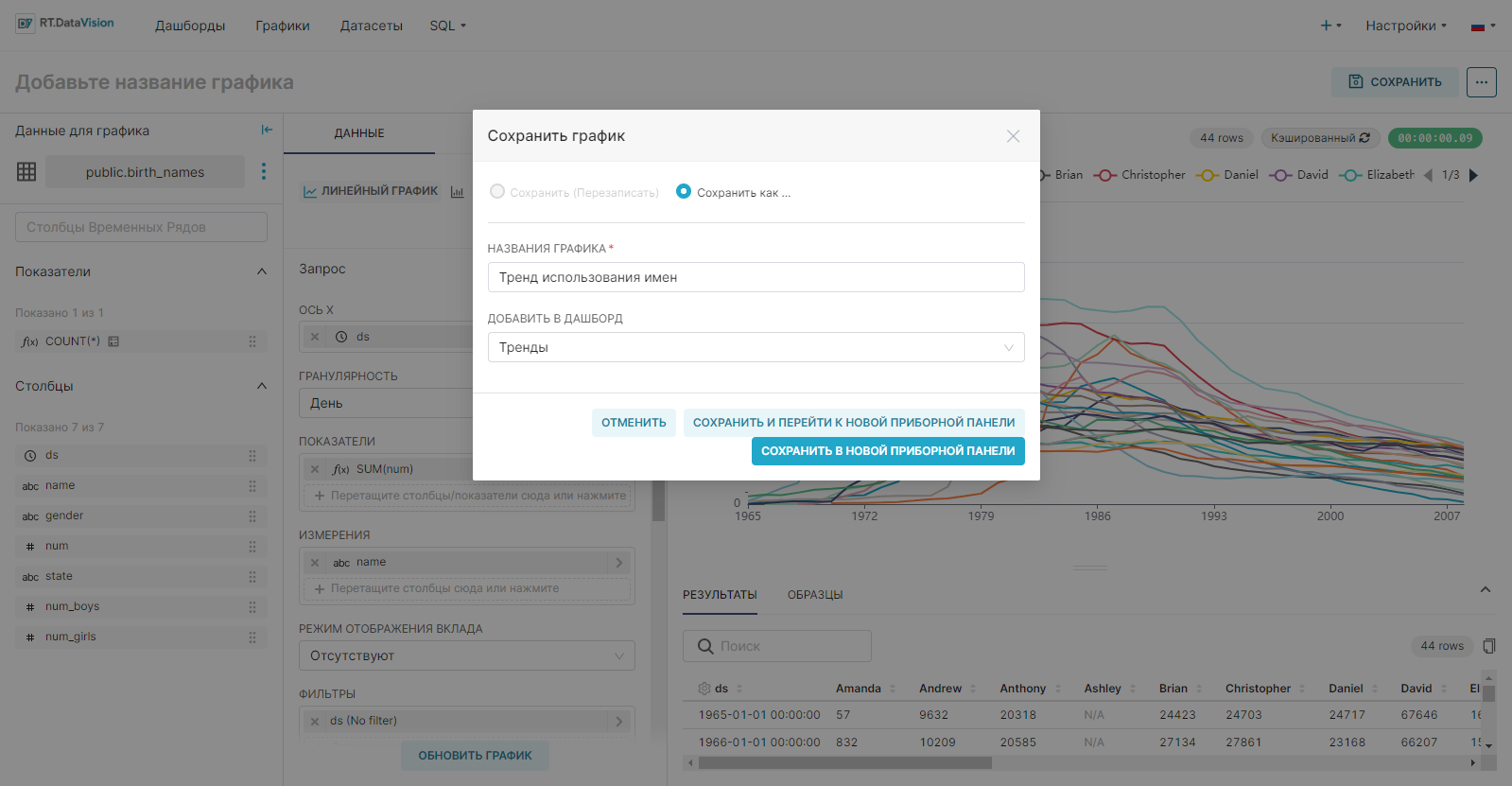
RT.DataVision создаст срез и сохранит всю информацию, необходимую для создания диаграммы, в своём тонком слое данных (запрос, тип диаграммы, выбранные параметры, имя и т.д.).
2. Откроется созданный дашборд Тренды с добавленным на него графиком Тренд использования имен.
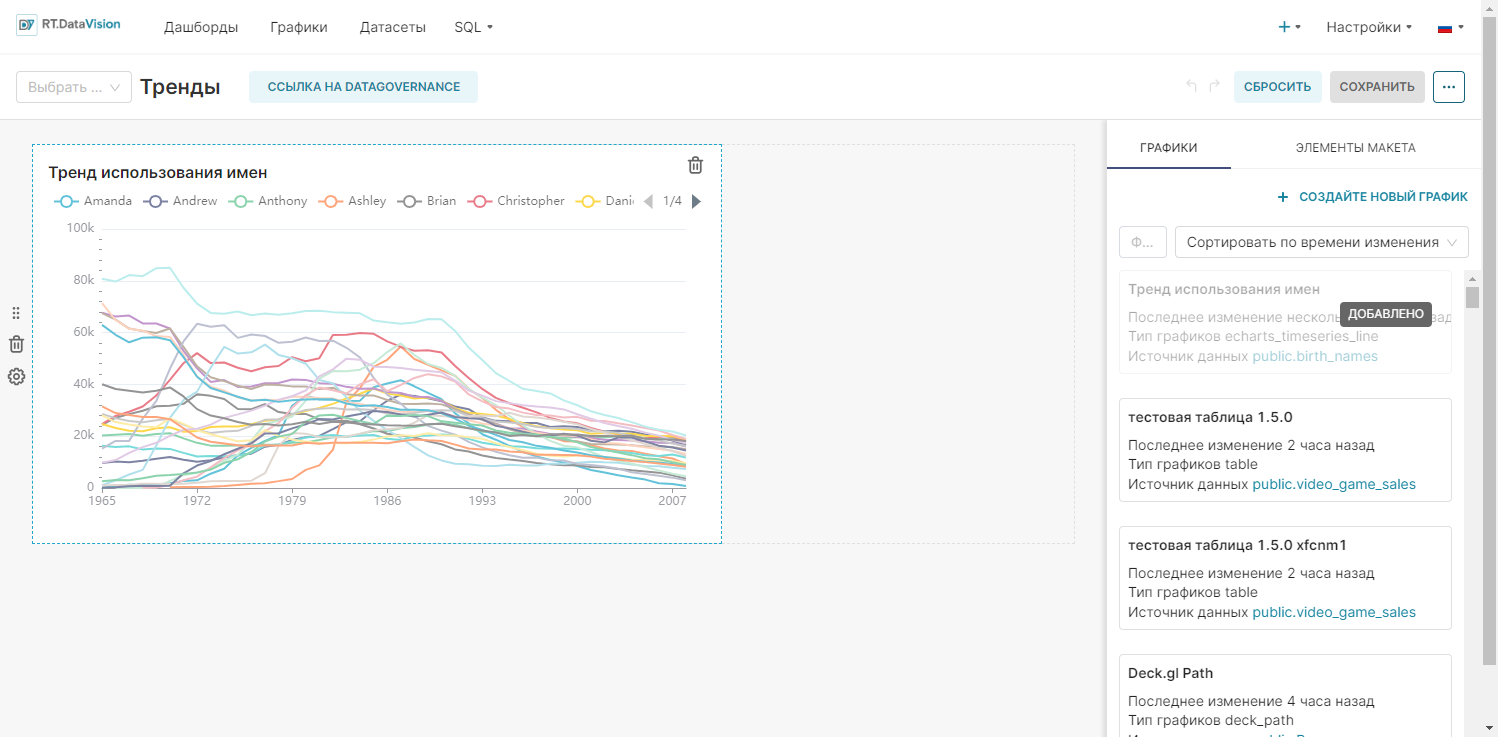
3. Нажмите Сохранить (Save) для сохранения изменения на дашборде.
После всех выполненных действий данные будет успешно связаны, проанализированы и визуализированы в RT.DataVision. Также, существует множество других конфигураций таблиц и вариантов визуализации.
¶ 3. Создание датасетов
¶ 3.1. Общая информация
После подключения базы данных администратором появится возможность создать физический или виртуальный датасет на данных этой БД.
Датасеты — это тщательно подобранное представление данных в БД, позволяющее графикам, которые необходимо создать, иметь унифицированные определения метрик. Они являются важным компонентом, поскольку каждый график создаётся из датасета. Датасеты обеспечивают высокий уровень гибкости при моделировании собранных данных, позволяя определить, как информация будет представлена на графике или дашборде для конкретной задачи.
Ключевые моменты RT.DataVision при работе с данными:
- RT.DataVision не извлекает данные из базы данных;
- Хранение и вычисления осуществляются на существующем бэкенде;
- Датасет в RT.DataVision — это тщательно подобранное представление данных, которые уже есть в базе данных;
- Каждый график основан на датасете.
¶ 3.2. Физические датасеты
Физический датасет указывает на таблицу в подключённой БД.
Добавление физического датасета — это быстрый способ приступить к созданию графиков в RT.DataVision. Просто создайте датасет, выбрав базу данных, схему и необходимую таблицу.
¶ 3.2.1. Доступ к физическим датасетам
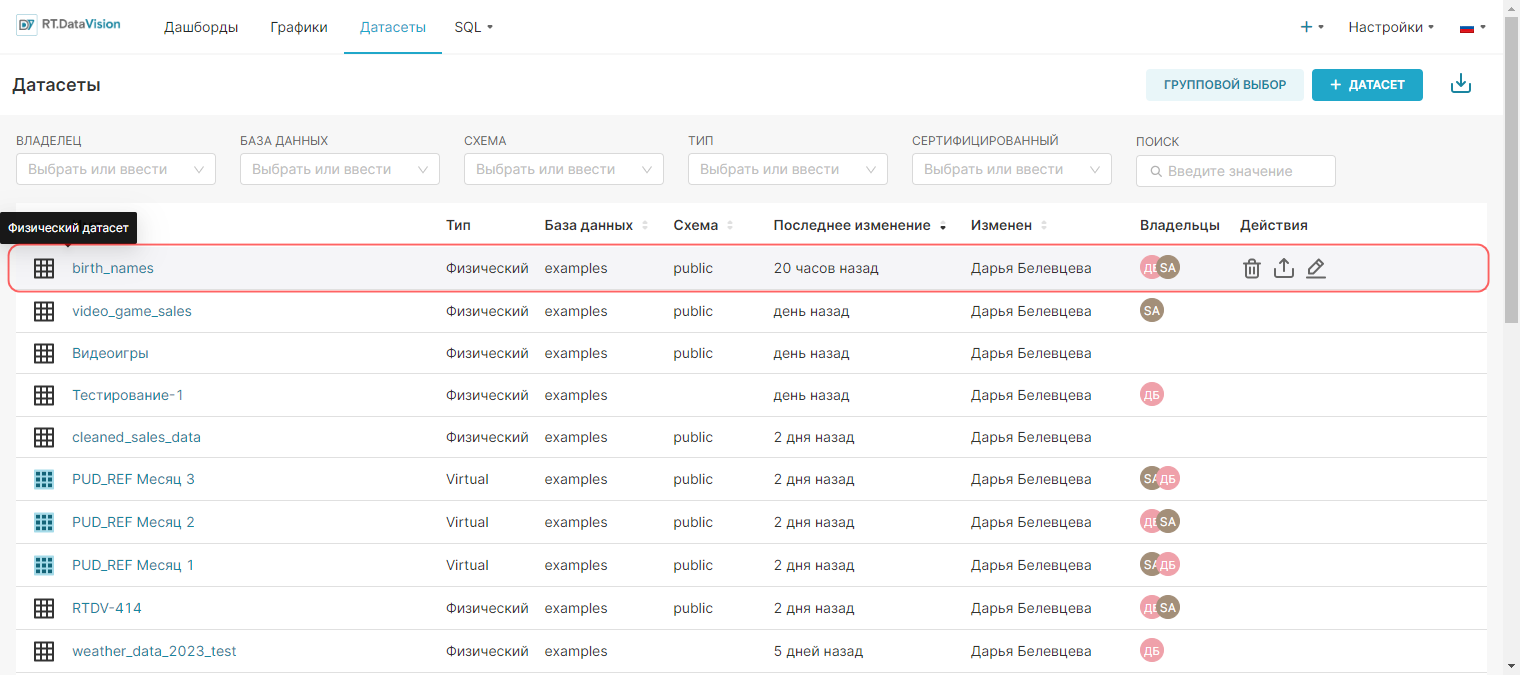
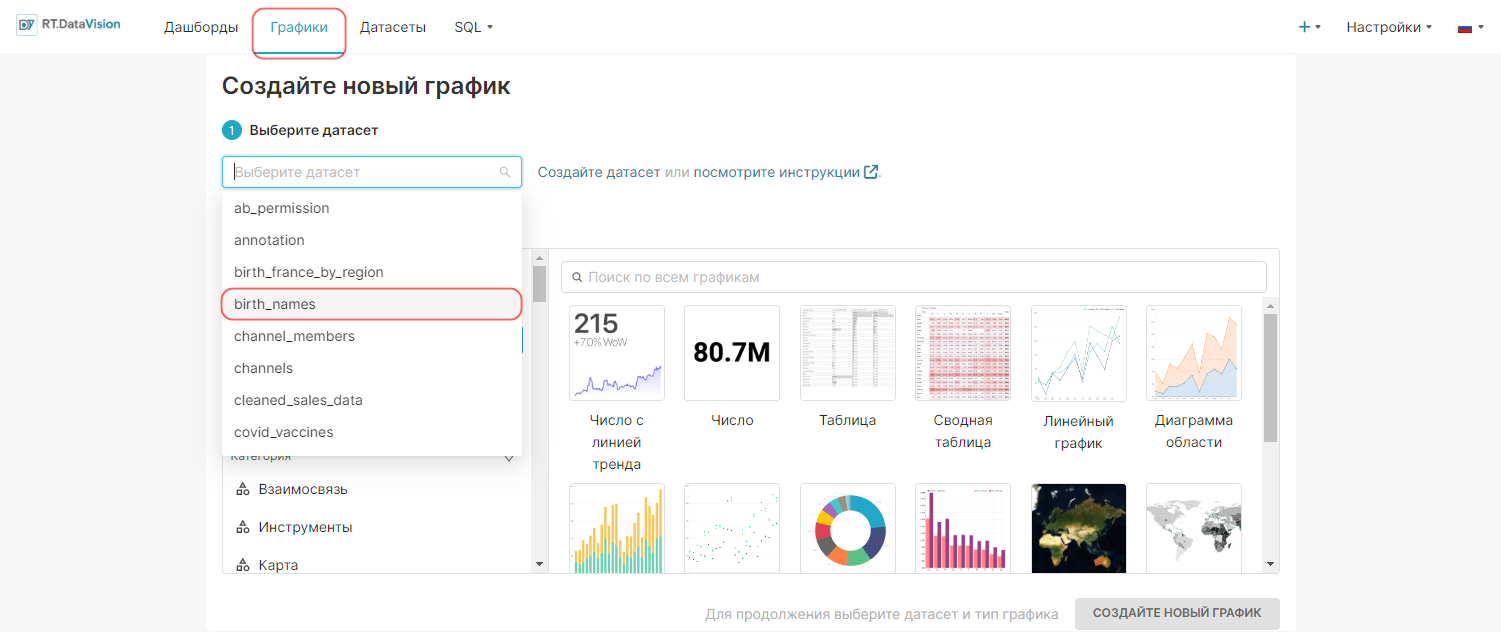
Физические датасеты обозначаются чёрными значками сетки и значением Физический (Physical) в столбце Тип (Type) в разделе Датасеты (Datasets). Этот раздел позволяет управлять, исследовать, удалять и просматривать физические датасеты так же, как виртуальные.
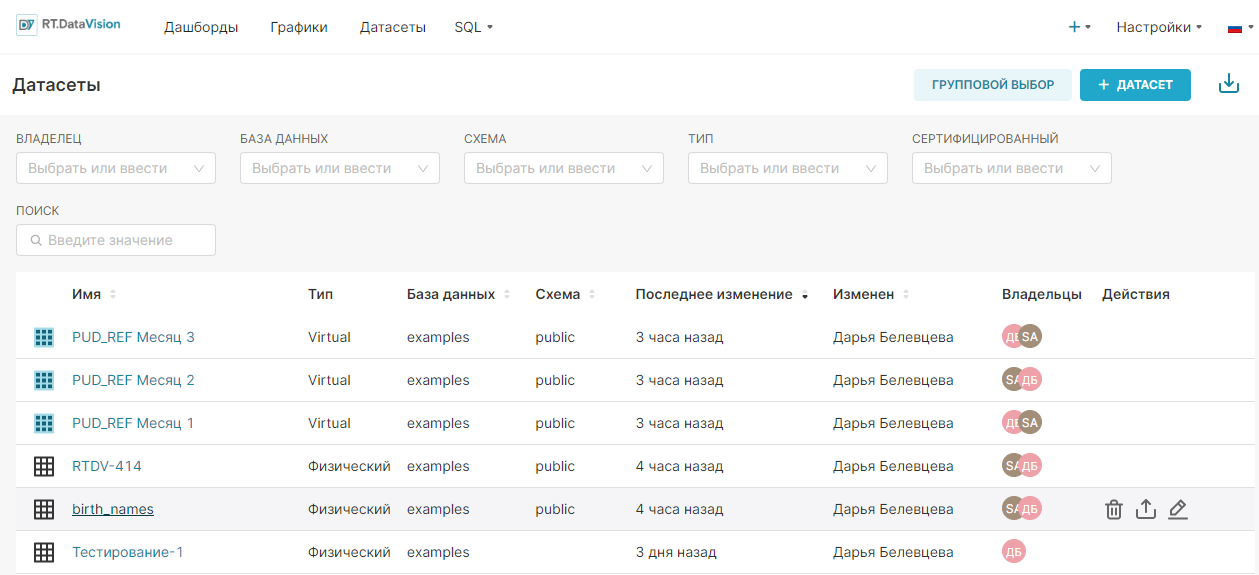
На рисунке ниже выделенная запись birth_names — это физический набор данных.
¶ 3.2.2. Добавление физического датасета
Для добавления нового физического датасета:
1. Перейдите в раздел Датасеты (Datasets).
2. Нажмите кнопку + Датасет (+ Dataset).
Появится окно Добавить базу данных (Add dataset).
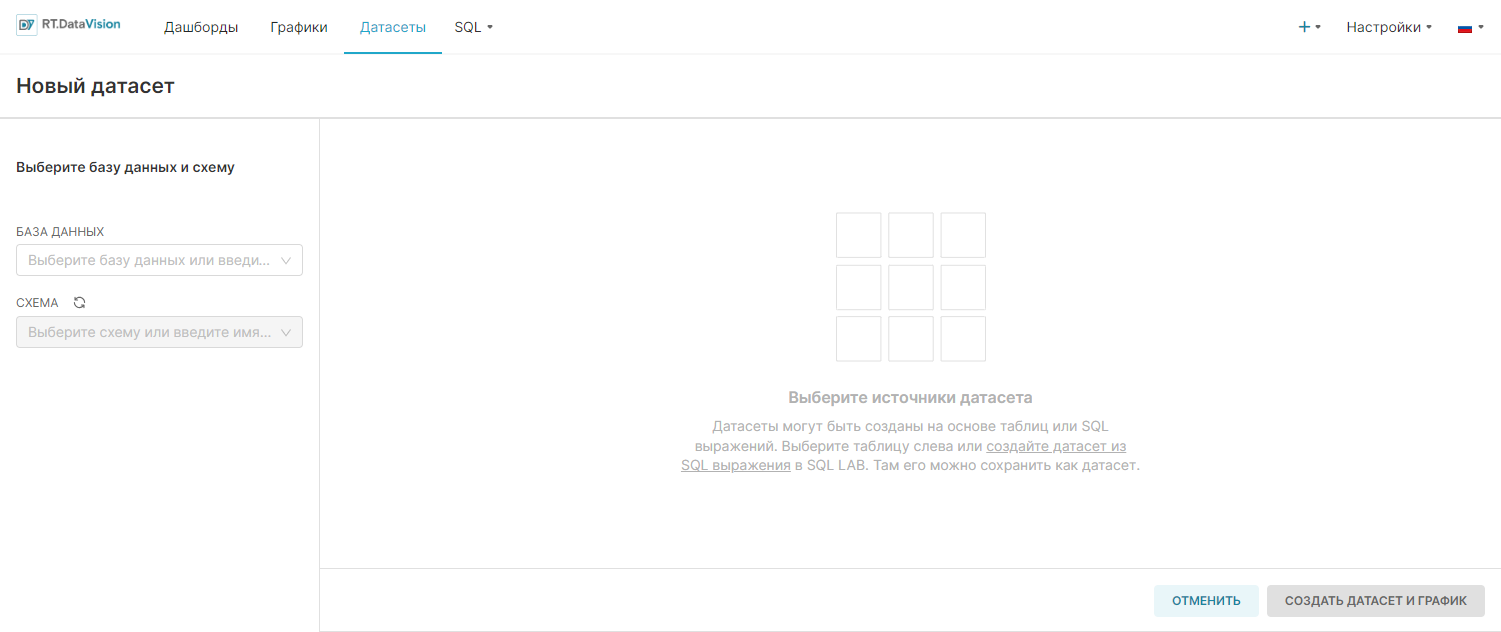
3. Выберите базу данных в поле База данных (Database) в открывшейся форме.
4. Выберите необходимое значение в поле Схема (Schema).
5. Выберите необходимый датасет в поле Выберите таблицу (See table schema). В примере ниже выбраны следующие значения:
- База данных (Database) – PostgreSQL;
- Схема (Schema) – public;
- Таблица (Table) – birth_names.
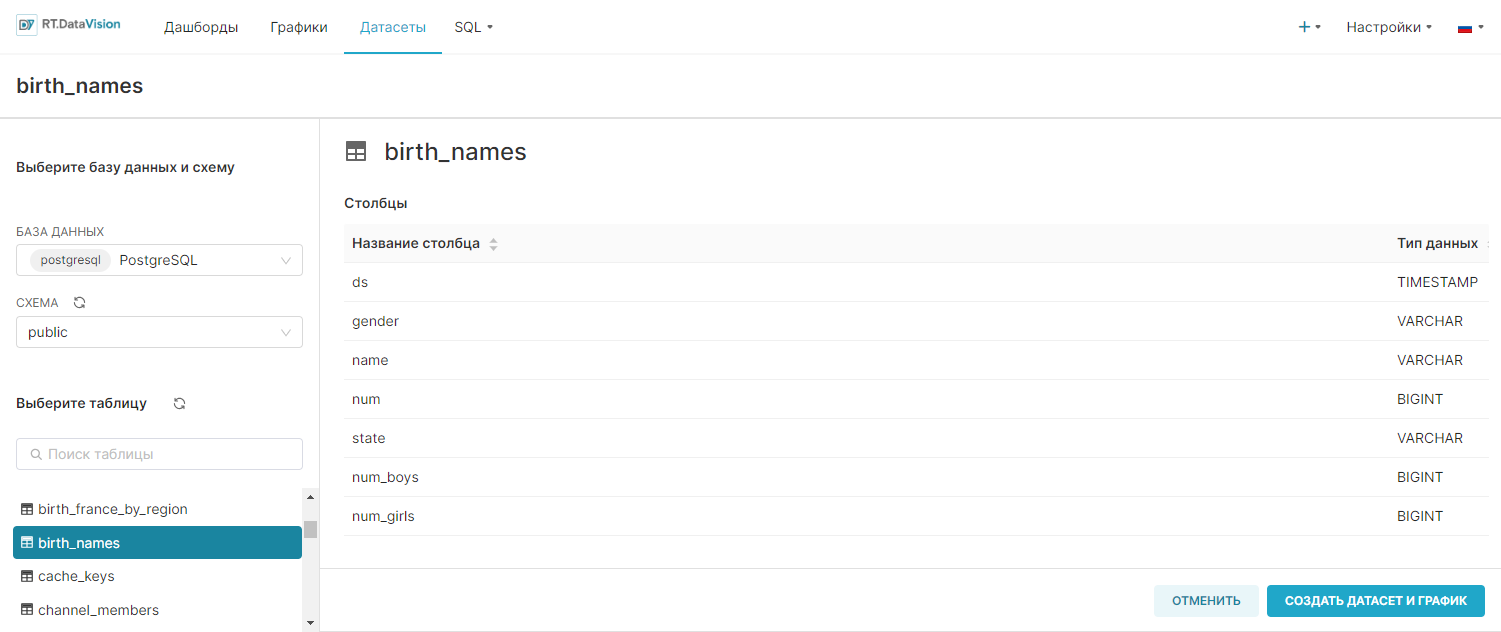
6. Нажмите кнопку Создать датасет и график Add (Create dataset and chart).
После сохранения датасета таблица будет доступна для выбора при создании графика. Добавленный датасет birth_names отображается в качестве параметра в раскрывающемся списке Выберите датасет (Choose a dataset).
¶ 3.3. Виртуальные датасеты
Виртуальный датасет — это представление данных, созданное в RT.DataVision с помощью Лаборатории SQL (SQL Lab). При создании виртуального датасета используется JOIN и любая другая операция SQL.
Создайте собственный уникальный SQL-запрос, который извлекает и упорядочивает данные в соответствии с необходимыми требованиями, и запустите запрос. После выполнения запроса отправьте результаты на страницу Исследовать (Explore), чтобы визуализировать запрос. При этом будет предложено сохранить представление данных в отдельный виртуальный датасет.
¶ 3.3.1. Доступ к виртуальным датасетам
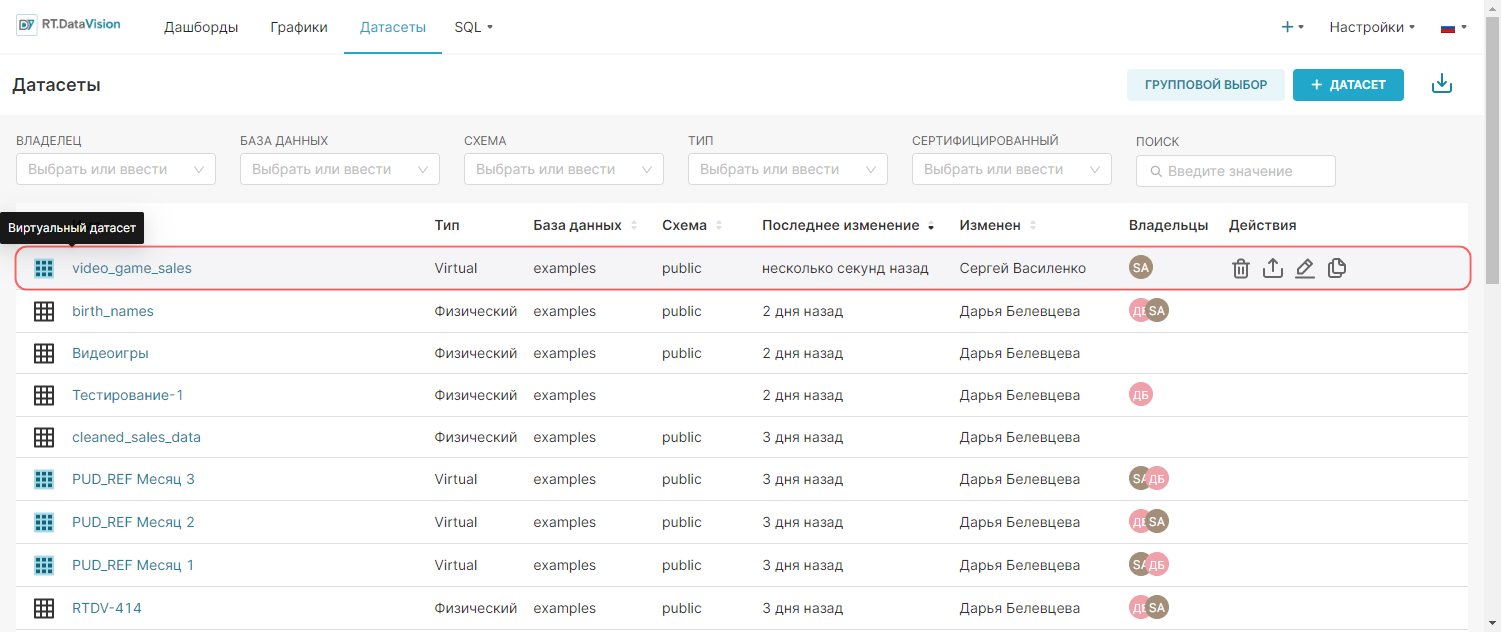
Виртуальные датасеты обозначаются синими значками сетки и значением Виртуальный (Virtual) в столбце Тип (Type) в разделе Датасеты (Datasets). Этот раздел позволяет управлять, исследовать, удалять и просматривать виртуальные датасеты так же, как физические.
На рисунке ниже выделенная запись video_game_sales — это виртуальный набор данных.
¶ 3.3.2. Создание нового виртуального датасета
Для создания виртуального датасета:
- Перейдите в раздел SQL (SQL) → Лаборатория SQL (SQL Lab).
2. Составьте необходимый запрос и нажмите кнопку Выполнить (Run).
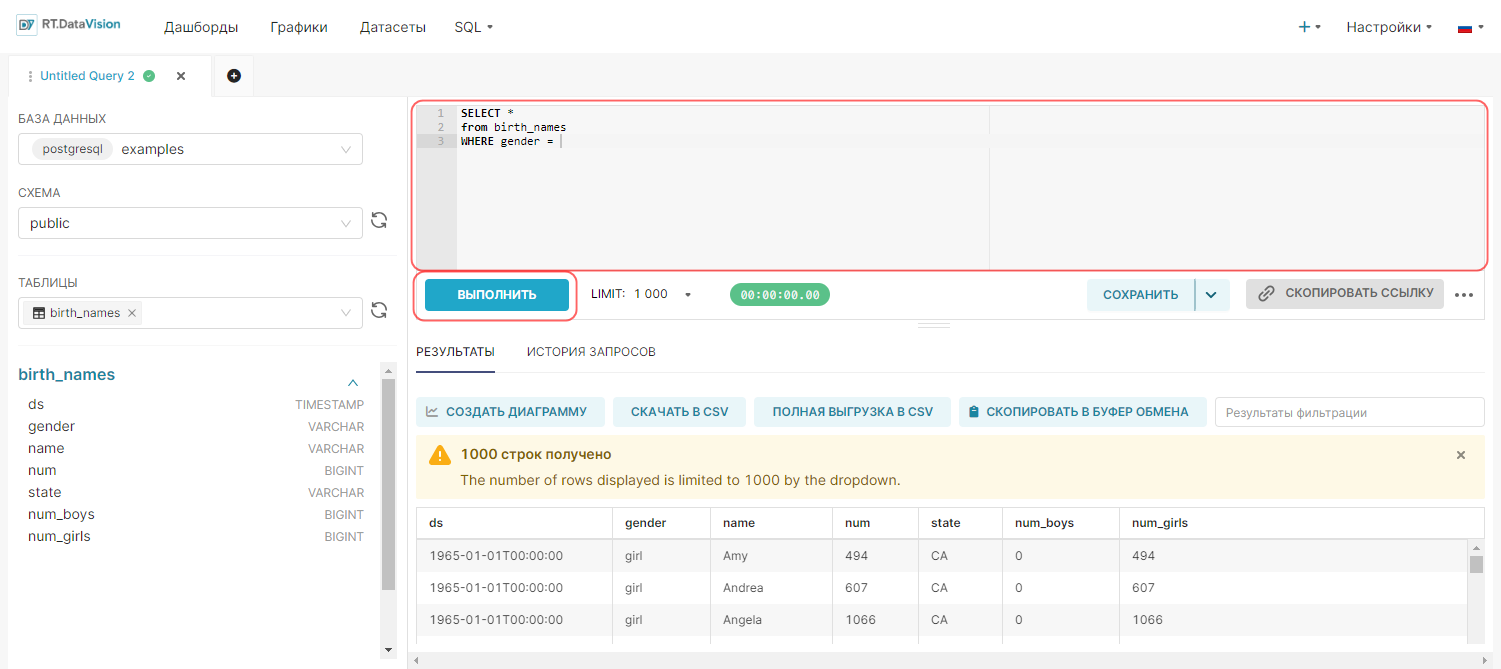
Примечание. Для просмотра созданного запроса на странице Исследовать (Explore) нажмите кнопку Создать диаграмму (Create chart) на вкладке Результаты (Results).
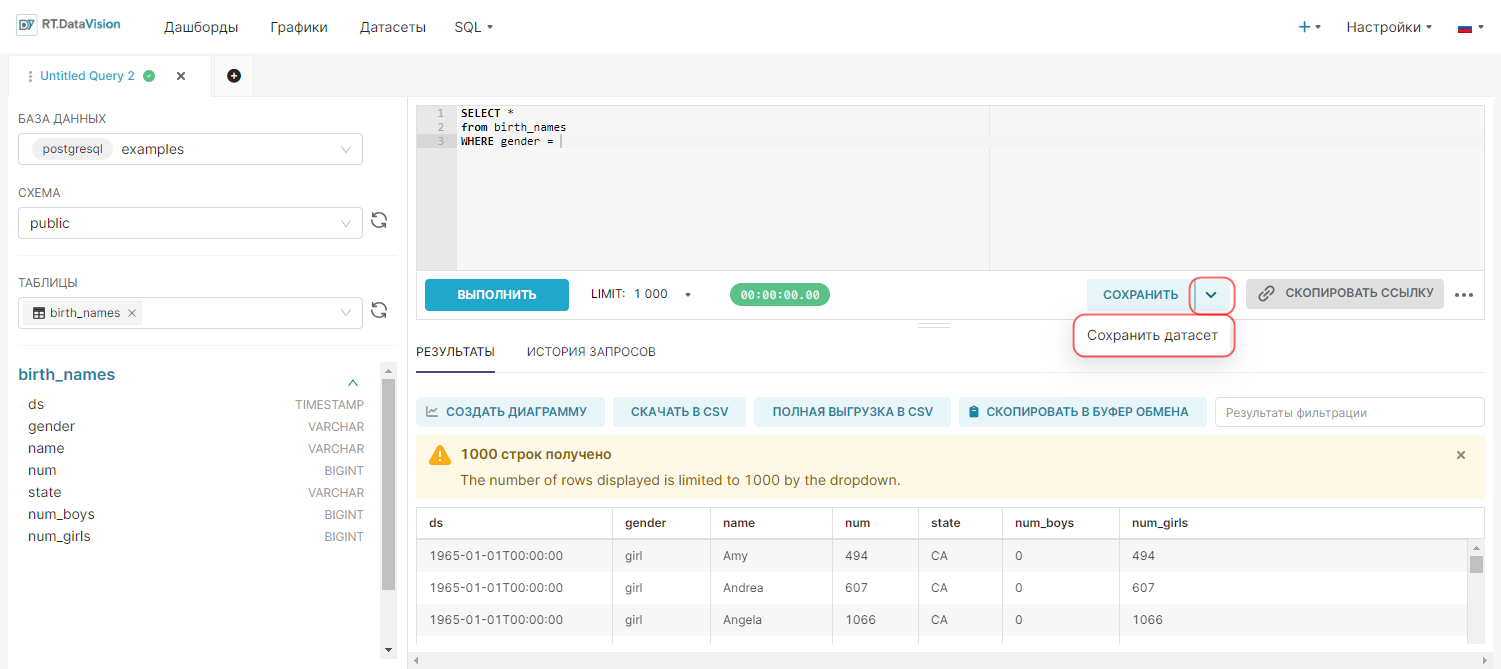
3. Нажмите кнопку Сохранить датасет (Save dataset).
4. Выберите необходимый вариант сохранения датасета в открывшемся окне Сохранения или перезаписи датасета (Save or Overwrite Dataset):
- Для сохранения нового вируального датасета выберите Сохранить как новый (Save as new) и укажите имя датасета.
- Для перезаписи уже существующего датасета выберите Перезаписать существующий (Overwrite existing) и укажите имя существующего датасета.
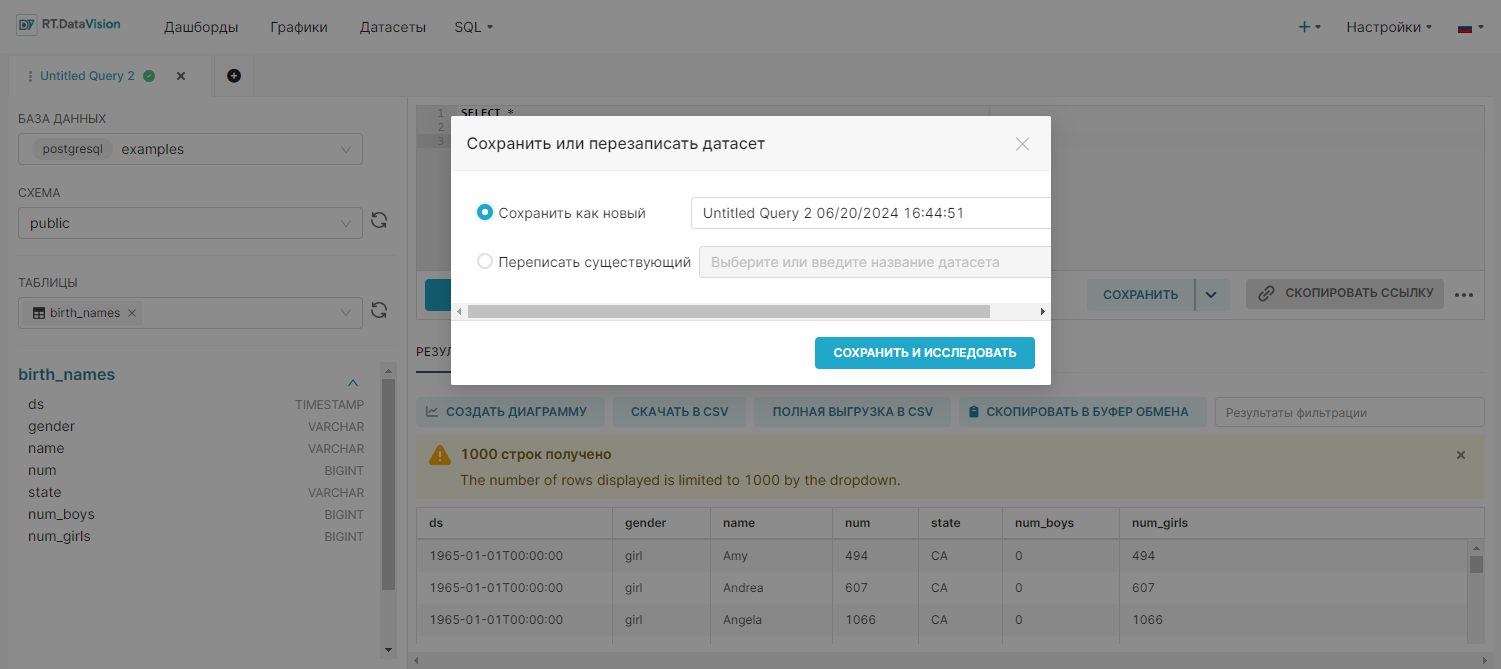
5. Нажмите кнопку Сохранить и исследовать (Save & Explore). Откроется страница Исследовать (Explore) с созданным виртуальным датасетом.
Новый датасет также доступен в разделе Датасеты (Datasets).
¶ 3.3.3. Создание виртуального датасета из физического
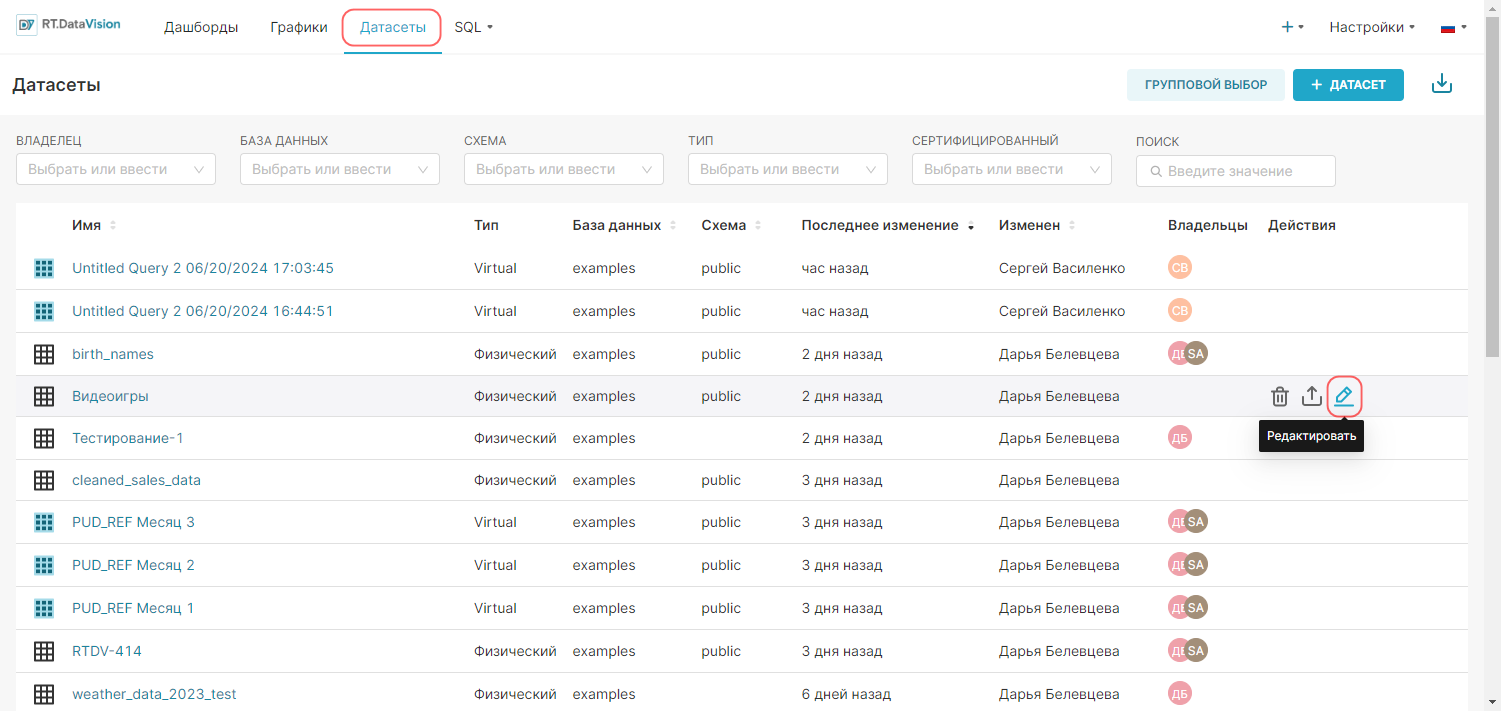
Для создания виртуального датасета из уже существующего физического датасета:
1. Перейдите в раздел Датасеты (Datasets).
2. Найдите необходимый физический датасет и нажмите кнопку Редактировать (Edit).
3. Нажмите на иконку замка в окне редактирования датасета.
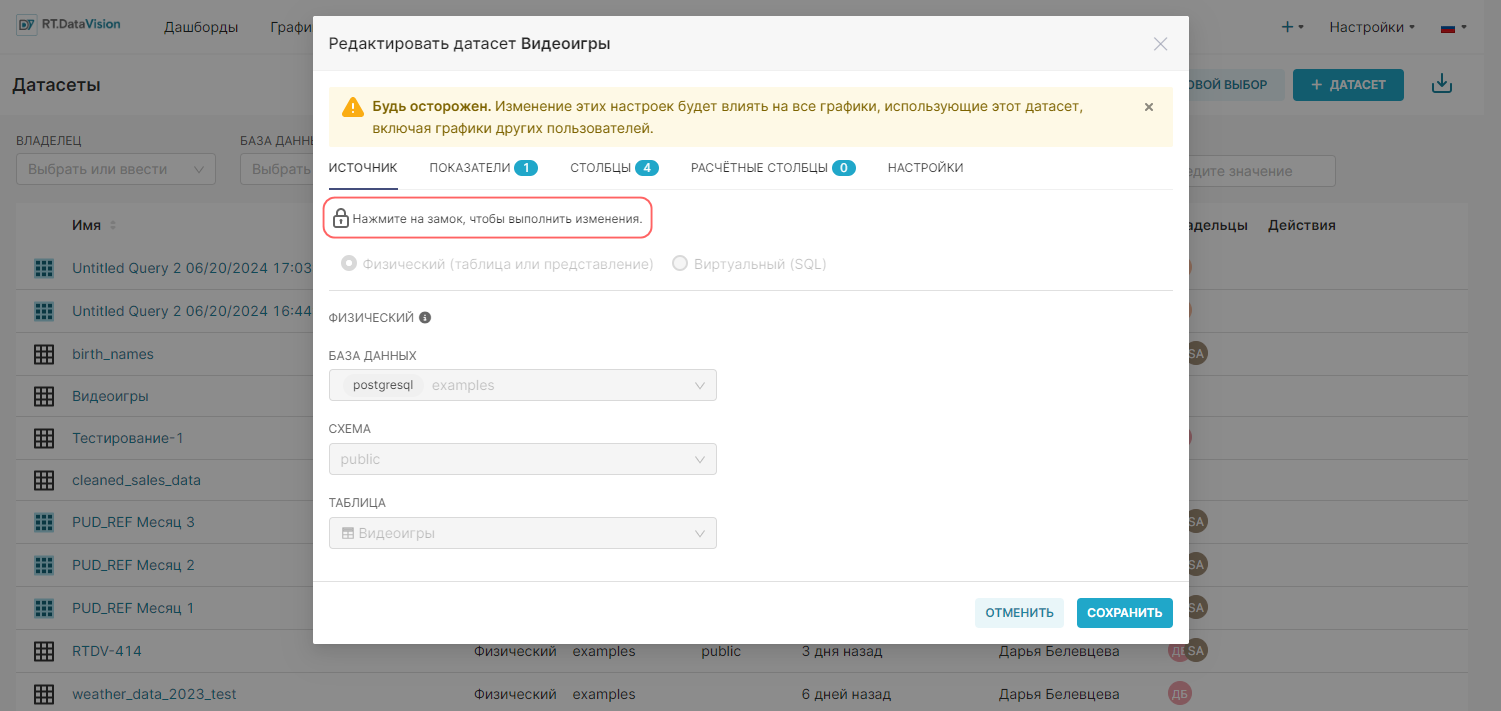
4. Установите переключатель на значение Виртуальный (SQL) (Virtual).
5. Укажите необходимый SQL-запрос в поле SQL.
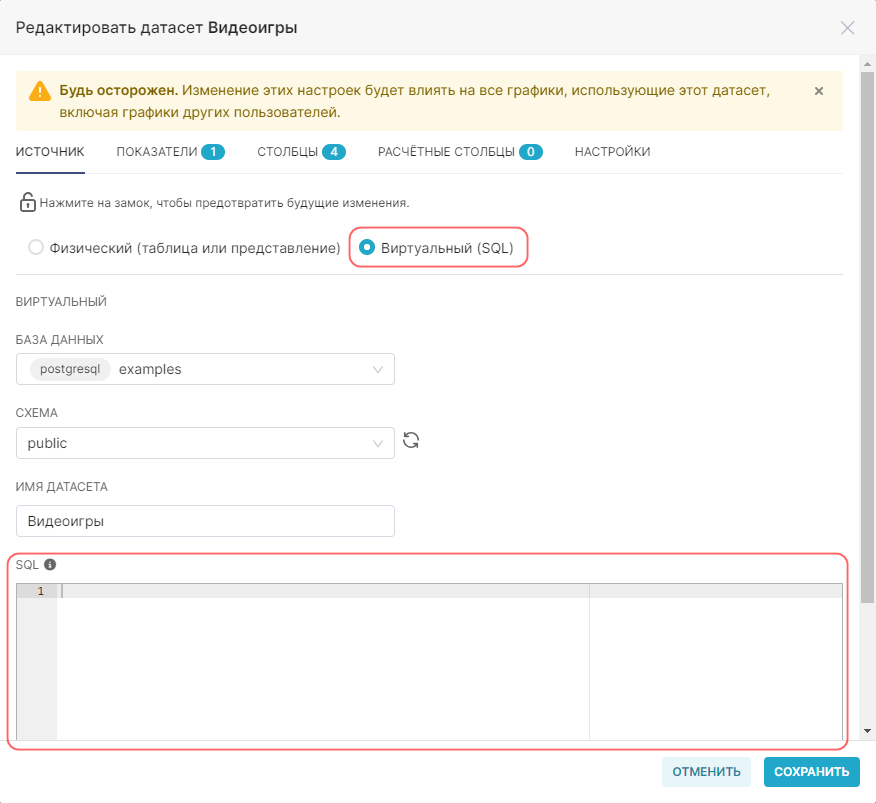
6. Нажмите кнопку Сохранить (Save) и подтвердите внесенные изменения.
Виртуальный датасет отобразится в списке раздела Датасеты (Datasets).
¶ 3.4. Настройка семантического слоя
¶ 3.4.1. Общая информация
Датасеты, добавленные в RT.DataVision из своей базы данных, можно настроить для более точного соответствия с необходимой аудиторией. Например, определить доступность данных в полях, указать форматы даты и изменить метки. В каждом датасете можно изменять его метрики, столбцы, а также создавать расчётные столбцы.
В этом разделе описывается настройка и изменение датасета для большего соответствия потребностям нужной аудитории.
¶ 3.4.2. Доступ к деталям о датасете
Изменение настроек датасета осуществляется с помощью панели Редактировать датасет (Edit Dataset), которая доступна из двух мест в RT.DataVision: на странице Датасеты (Datasets) и на странице Исследовать (Explore).
Внимание! Изменение настроек метрики повлияет на все графики, использующие этот датасет, включая графики, принадлежащие другим пользователям.
¶ 3.4.2.1. Доступ через страницу Datasets
Перейдите в раздел Датасеты (Datasets). В этом разделе находится перечень всех датасетов в RT.DataVision, к которым предоставлен доступ.
Для изменения датасета выберите необходимый датасет и нажмите на кнопку Редактировать (Edit).
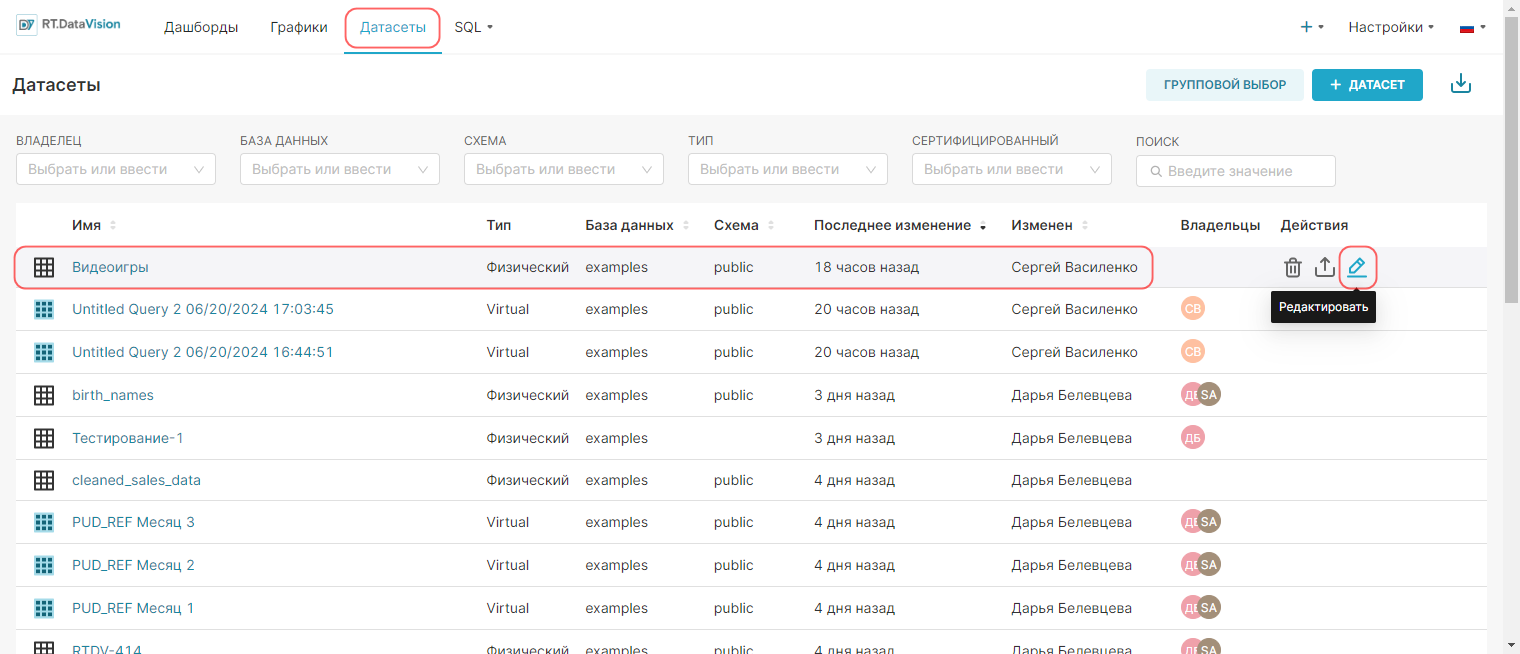
Откроется окно Редактировать датасет (Edit Dataset).
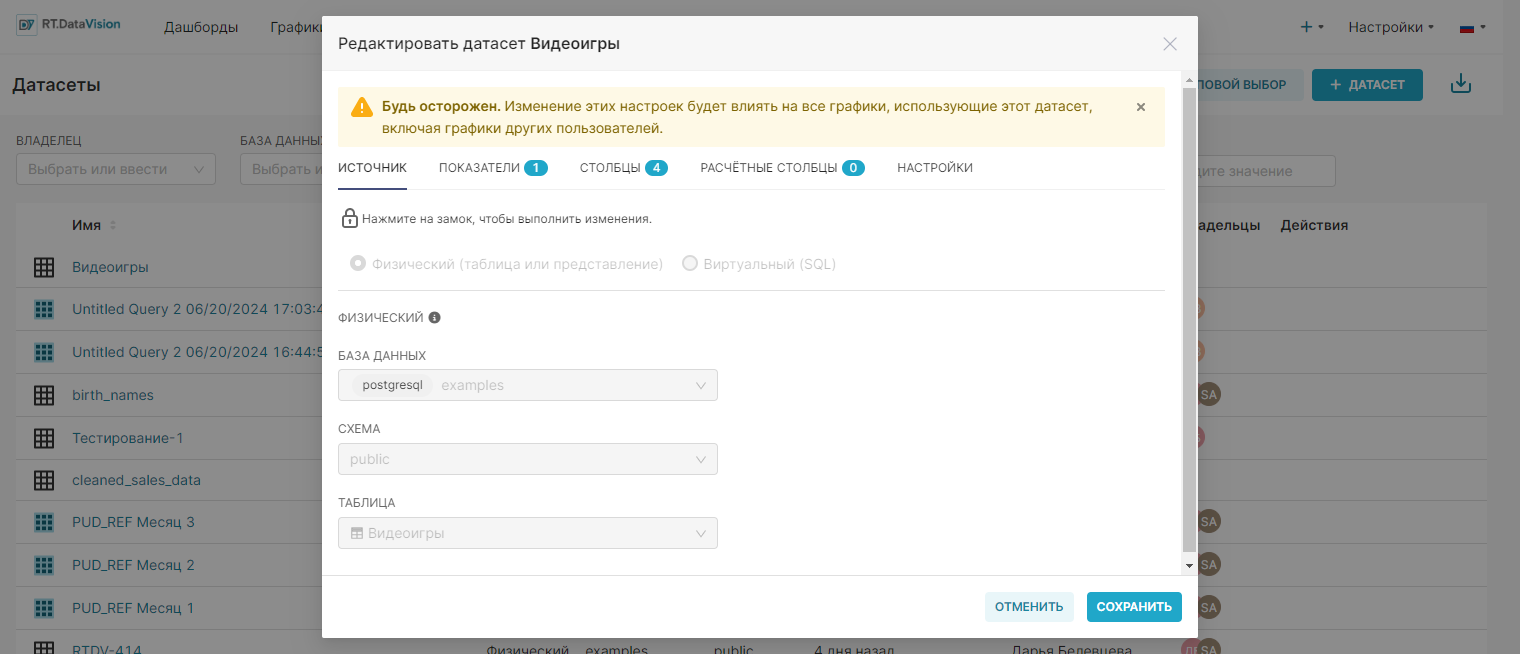
¶ 3.4.2.2. Доступ через страницу Исследовать (Explore)
Окно Редактировать датасет (Edit Dataset) также можно открыть через страницу Исследовать (Explore) при изучении графика. На панели представления датасета нажмите на значок с многоточием и выберите Edit dataset (Редактировать датасет).
¶ 3.4.3. Показатели (Metrics)
Показатели (Metrics) используются для выполнения операций с датасетом (т.е. применяются более чем к 1 строке). Преимущественно они используются для:
- Расчётов на основе агрегации;
- Расчётов для ротации строк в столбцы.
Показатели (Metrics) заменяются выражением SQL в операторе SQL, но определённые метрики недоступны в Лаборатории SQL (SQL Lab).
Для просмотра, изменения, добавления, удаления показателей в датасете откройте окно редактирования датасета и перейдите на вкладку Показатели (Metrics). Список всех показателей в датасете отображается в виде таблицы, где:
- Показатель (Metric) — имя показателя;
- Метка (Label) — текстовое поле, которое отображается как метка показателя. Метка — это то, что пользователь видит как имя показателя;
- Выражение SQL (SQL Expression) — SQL-выражение, связанное с показателем. Появляется в виде всплывающей подсказки при наведении курсора на значок вопросительного знака.
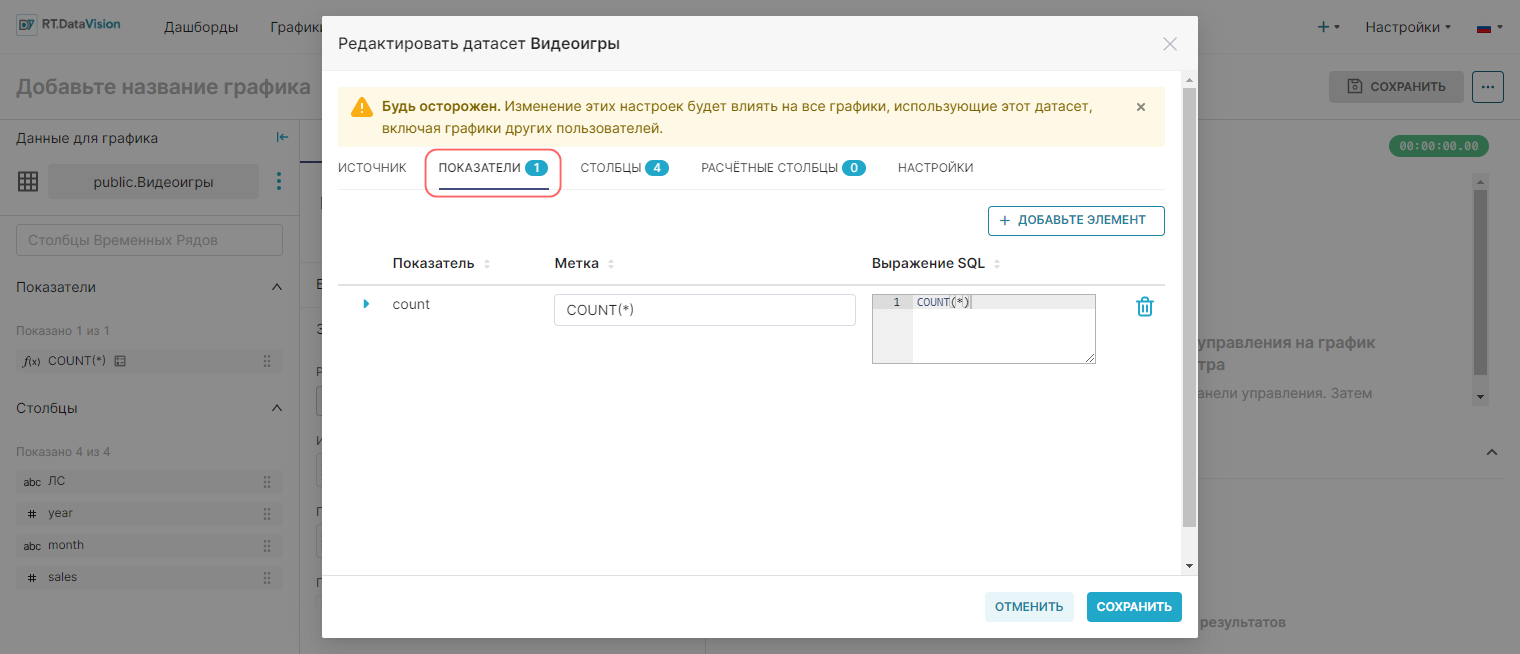
Для изменения других полей, связанных с показателем, нажмите на значок стрелки в левой части строки с показателем.
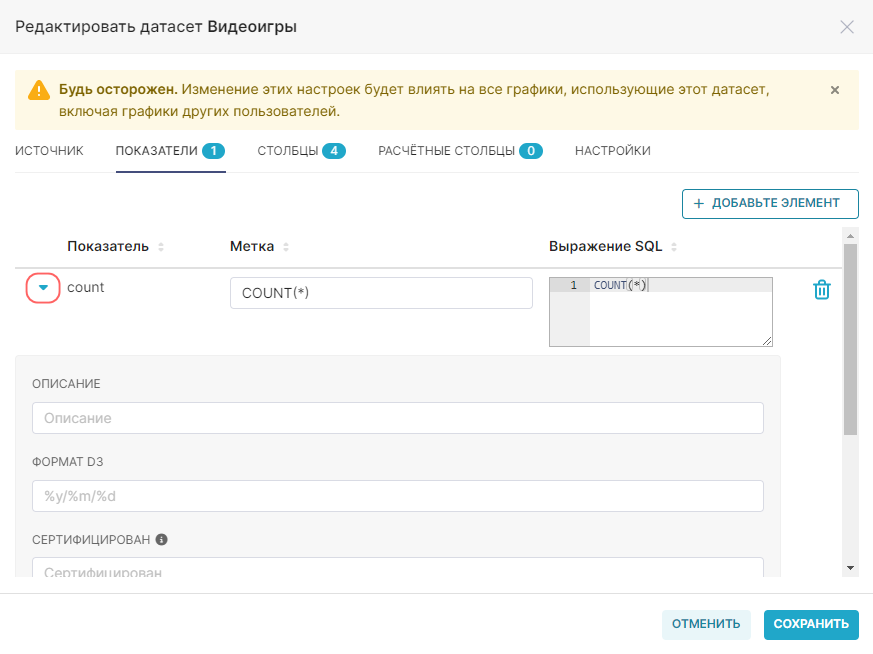
Для редактирования доступны следующие поля:
- Описание (Description) — краткое описание показателя. Описание появляется в виде всплывающей подсказки при наведении курсора на значок буквы i;
- Формат D3 (D3 Format)— форматирование значений на основе формата D3. Например, для значения 1234,567: .2% = 123456.7%, .2k = 1K, ,.2r = 1,200;
- Изменено (Certified By) — название сертифицирующей организации/лица;
- Детали сертификации (Certfication Details) — сведения о сертификации;
- Предупреждение (Warning) — предупреждающее сообщение, появляющееся в поле выбора показателя.
¶ 3.4.3.1. Добавление показателя
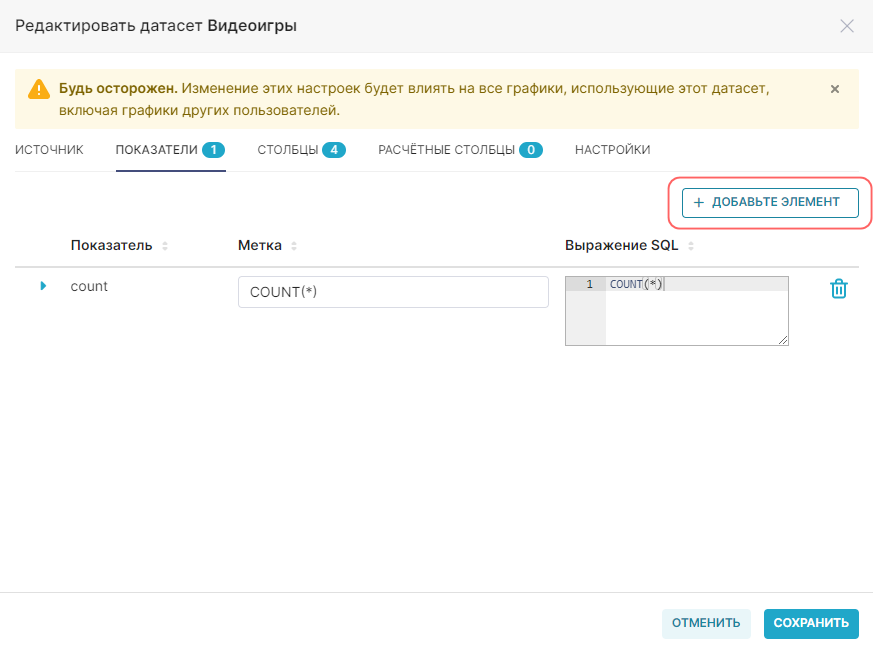
Для добавления нового показателя:
1. Нажмите кнопку + Добавить элемент (+ Add item) в окне редактирования датасета на вкладке Показатели (Metrics).
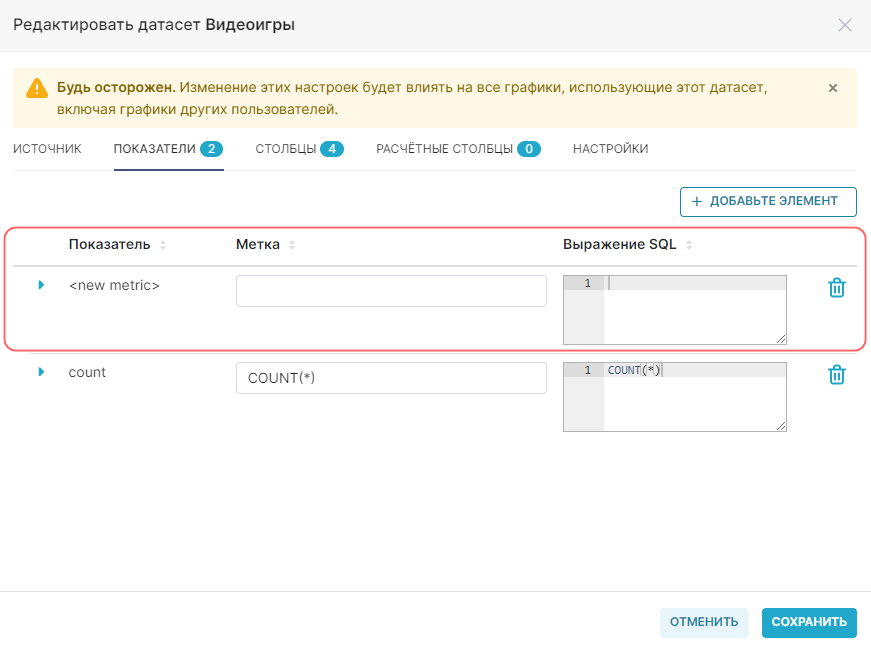
2. Укажите метку нового показателя в поле Метка (Label) на строке с именем <new metric>.
3. Введите необходимое SQL-выражение в поле Выражение SQL (SQL Expression).
4. Разверните строку с новым показателем и заполните дополнительные поля при необходимости.
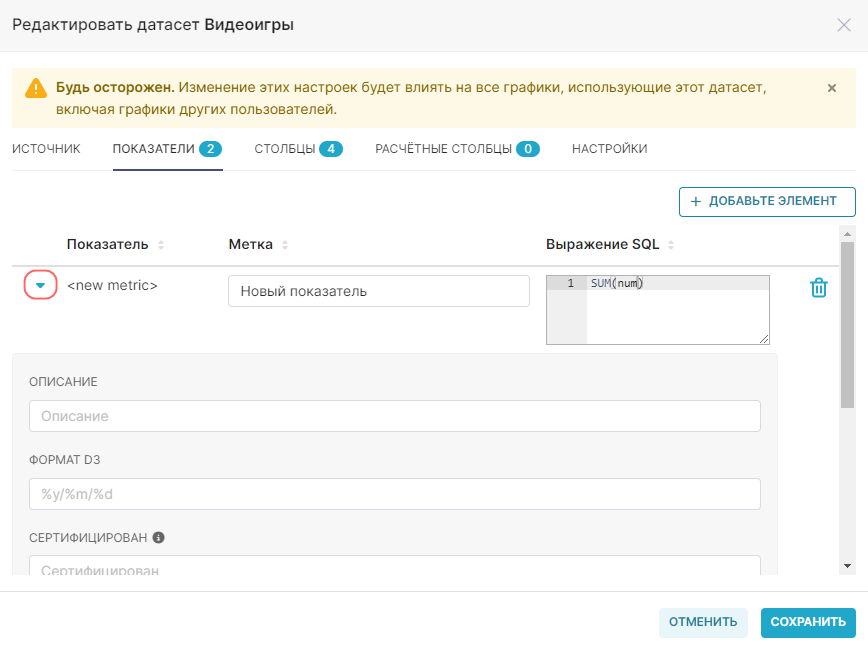
5. Нажмите кнопку Сохранить (Save).
Новый показатель отобразится на вкладке Показатели (Metrics) датасета.
¶ 3.4.4. Столбцы
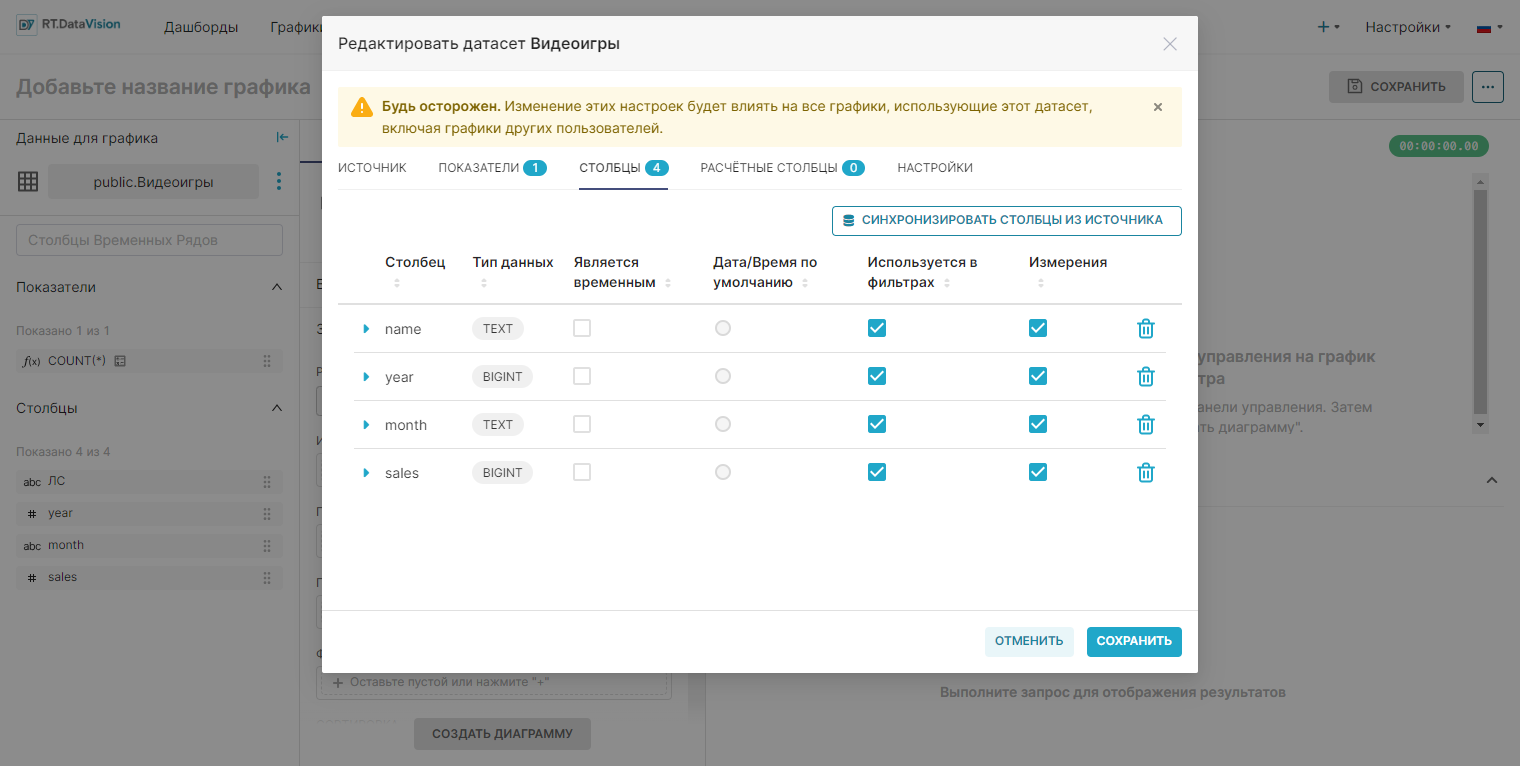
В окне редактирования датасета на вкладке Столбцы (Columns) отображаются все данные столбцов в датасете в виде таблицы со следующими столбцами:
- Столбец (Column) — имя столбца (редактируемое поле);
- Тип данных (Data type) — тип данных в столбце, например: integer, float, variable character, timestamp и т.д. (редактируемое поле);
- Является временны́м (Is temporal) — выбранный столбец представляет собой отметку времени и должен быть доступен в качестве параметра на панели Время (Time) в Исследовать (Explore) (редактируемое поле);
- Дата/Время по умолчанию (Default datatime) — столбец с отметкой времени как использующийся по умолчанию;
- Используется в фильтрах (Is filterable) — выбранный столбец включён в качестве параметра в поле Фильтры (Filter) в Исследовать (Explore) (редактируемое поле);
- Измерения (Is dimension) — выбранный столбец включён в качестве параметра в поле Сортировка (Group by) в Исследовать (Explore) (редактируемое поле);
- Удалить (Delete) — удаление столбца.
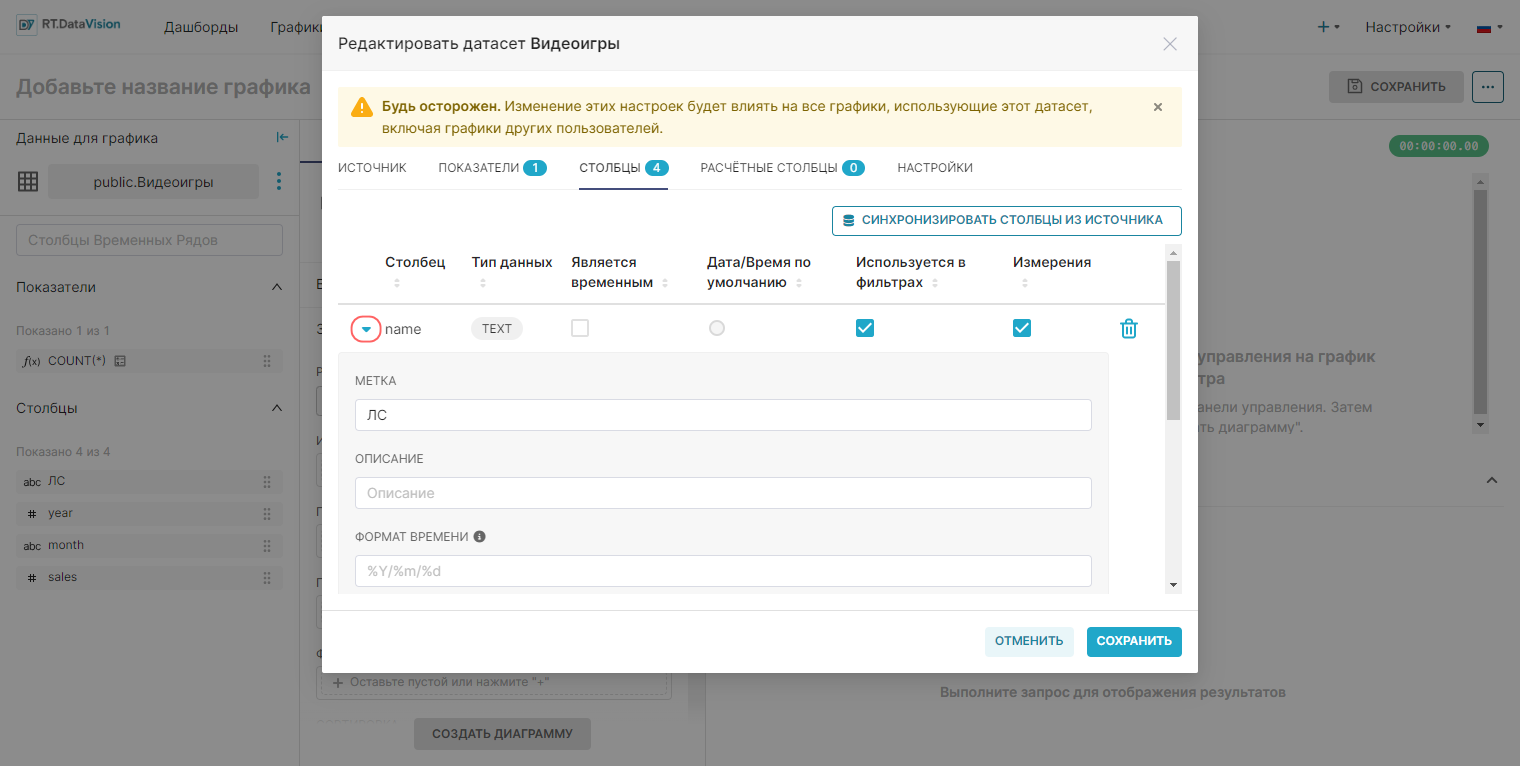
Для определения дополнительных данных для столбца выберите соответствующую ему стрелку в левой части строки. Дополнительные поля включают:
- Метка (Label) — метка столбца. Метка — это то, что пользователь увидит как имя столбца (редактируемое поле);
- Описание (Description)— краткое описание столбца. Описание появляется в виде всплывающей подсказки, когда пользователь наводит курсор на значок буквы i (редактируемое поле);
- Формат времени (Datetime Format) — формат отметки даты и времени в формате Python (редактируемое поле). Примеры: %m-%d-%Y= 02-27-2020, %a %d, %y = Tue 2, 2020, %x %X = 02/27/2020 17:41:00, %B-%Y = February-2020, Epoch_m = если дата является целым числом века;
- Сертифицирован (Certified By) — название сертифицирующей организации/лица (редактируемое поле);
- Детали сертификации (Certfication Details) — сведения о сертификации (редактируемое поле).
Кнопка Синхронизировать столбцы из источника (Sync Columns from Source) используется для повторного подключения к источнику данных и обновления состава столбцов в таблице.
¶ 3.4.5. Расчётные столбцы
Расчётные столбцы используются для “фальсификации” данных. Это простой процесс преобразования сырых данных в формат, более значимый для конечных пользователей, с целью предоставления значимых данных на основе аудитории конечных пользователей.
Примеры методов “фальсификации” данных включают:
- Преобразование данных — преобразование данных в разные форматы;
- Обогащение данных — добавление значимой информации к данным;
- Валидация данных — исправление и валидация данных.
В RT.DataVision расчётные столбцы заменяются выражением SQL в операторе SQL, но они недоступны в Лаборатории SQL (SQL Lab).
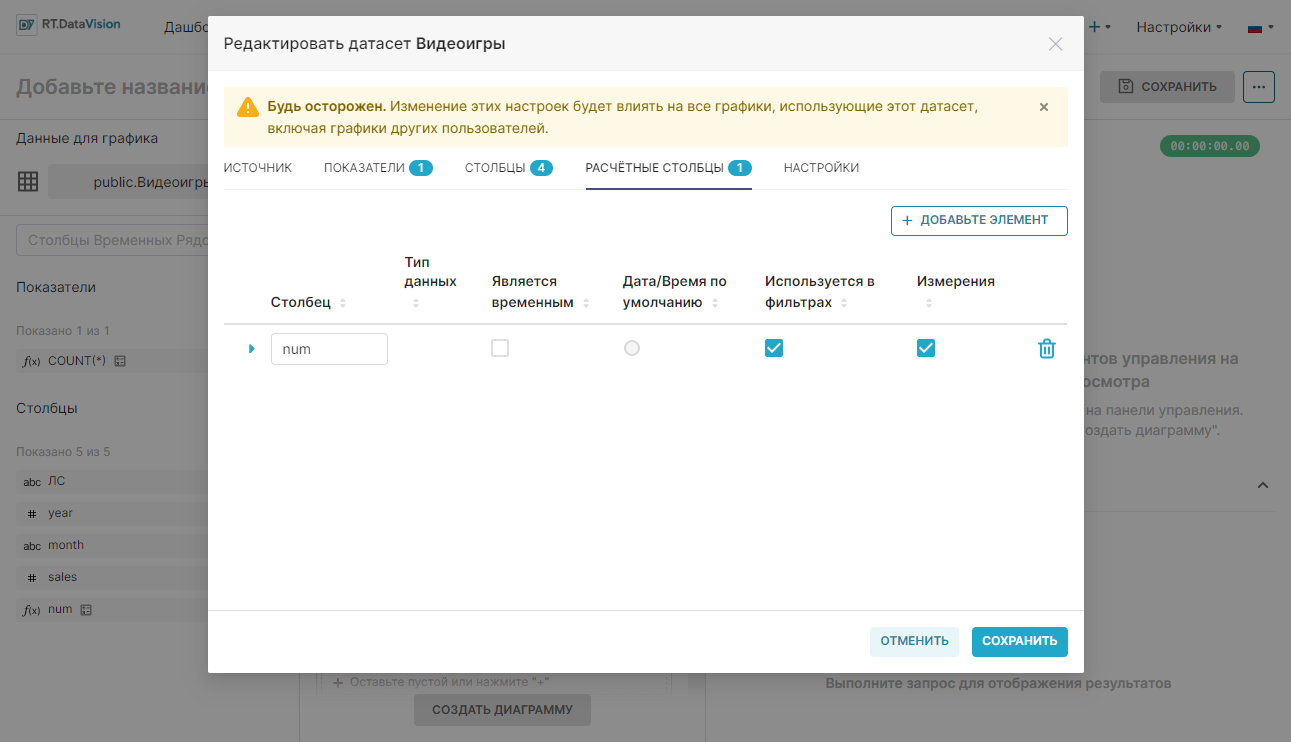
В окне редактирования датасета на вкладке Расчётные столбцы (Calculated columns) отображаются все данные расчётного столбца в виде таблицы со следующими столбцами:
- Столбец (Column) — имя столбца (редактируемое поле);
- Тип данных (Data type) — тип данных в столбце, например: integer, float, variable character, timestamp и т.д. (редактируемое поле);
- Является временны́м (Is temporal) — выбранный столбец представляет собой отметку времени и должен быть доступен в качестве параметра на панели Время (Time) в Исследовать (Explore) (редактируемое поле);
- Дата/Время по умолчанию (Default datatime) — столбец с отметкой времени как использующийся по умолчанию;
- Используется в фильтрах (Is filterable) — выбранный столбец включён в качестве параметра в поле Фильтры (Filter) в Исследовать (Explore) (редактируемое поле);
- Измерения (Is dimension) — выбранный столбец включён в качестве параметра в поле Сортировка (Group by) в Исследовать (Explore) (редактируемое поле);
- Удалить (Delete) — удаление столбца.
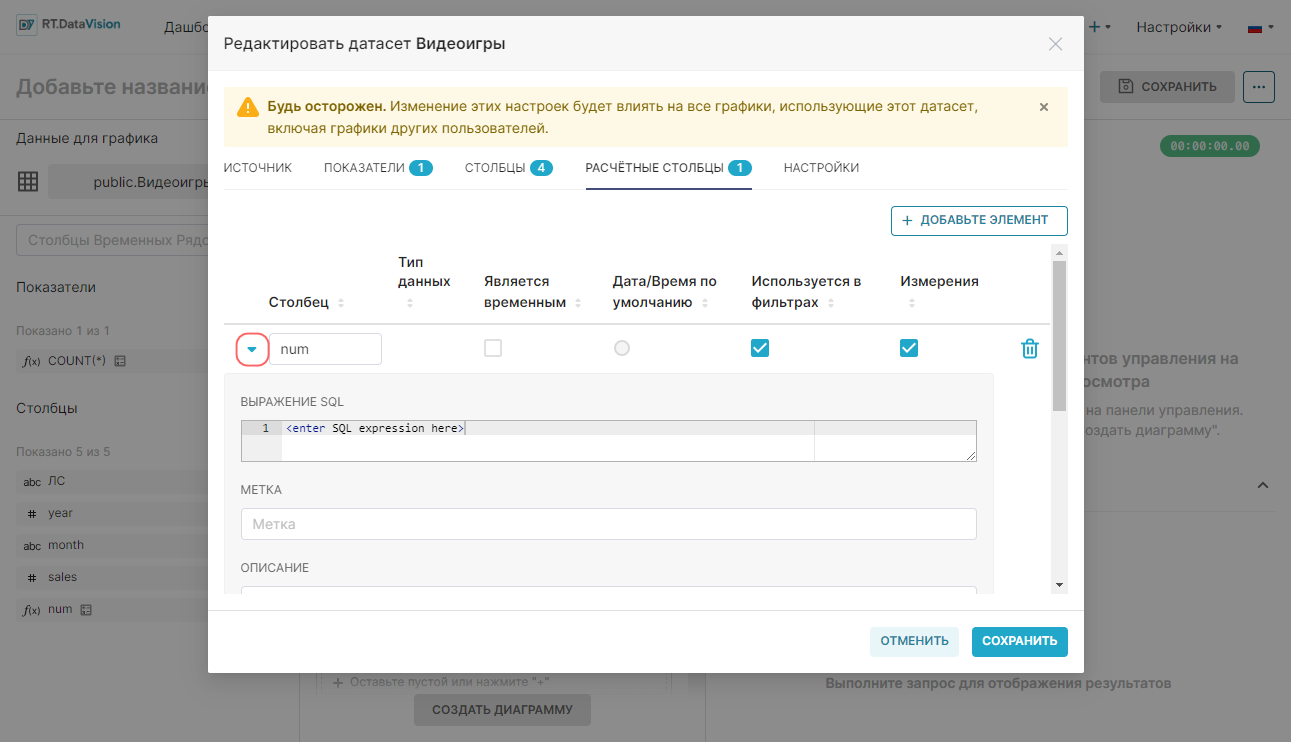
Для определения дополнительных данных для расчётного столбца выберите соответствующую ему стрелку в левой части строки. Дополнительные поля включают:
- Выражение SQL (SQL Expression) — SQL-выражение, связанное с расчётным столбцом. Появляется в виде всплывающей подсказки при наведении курсора на значок вопросительного знака (редактируемое поле);
- Метка (Label) — метка столбца. Метка — это то, что пользователь увидит как имя столбца (редактируемое поле);
- Описание (Description)— краткое описание столбца. Описание появляется в виде всплывающей подсказки, когда пользователь наводит курсор на значок буквы i (редактируемое поле);
- Тип данных (Data type) — тип данных в столбце, например: integer, float, variable character, timestamp и т.д. (редактируемое поле);
- Формат времени (Datetime Format) — формат отметки даты и времени в формате Python (редактируемое поле). Примеры: %m-%d-%Y= 02-27-2020, %a %d, %y = Tue 2, 2020, %x %X = 02/27/2020 17:41:00, %B-%Y = February-2020, Epoch_m = если дата является целым числом века;
- Сертифицирован (Certified By) — название сертифицирующей организации/лица (редактируемое поле);
- Детали сертификации (Certfication Details) — сведения о сертификации (редактируемое поле).
¶ 3.4.5.1. Добавление расчётного столбца
Для добавления расчетного столбца:
1. Перейдите на вкладку Расчётные столбцы (Calculated columns) в окне редактирования датасета.
2. Нажмите кнопку + Добавить элемент (+ Add item).
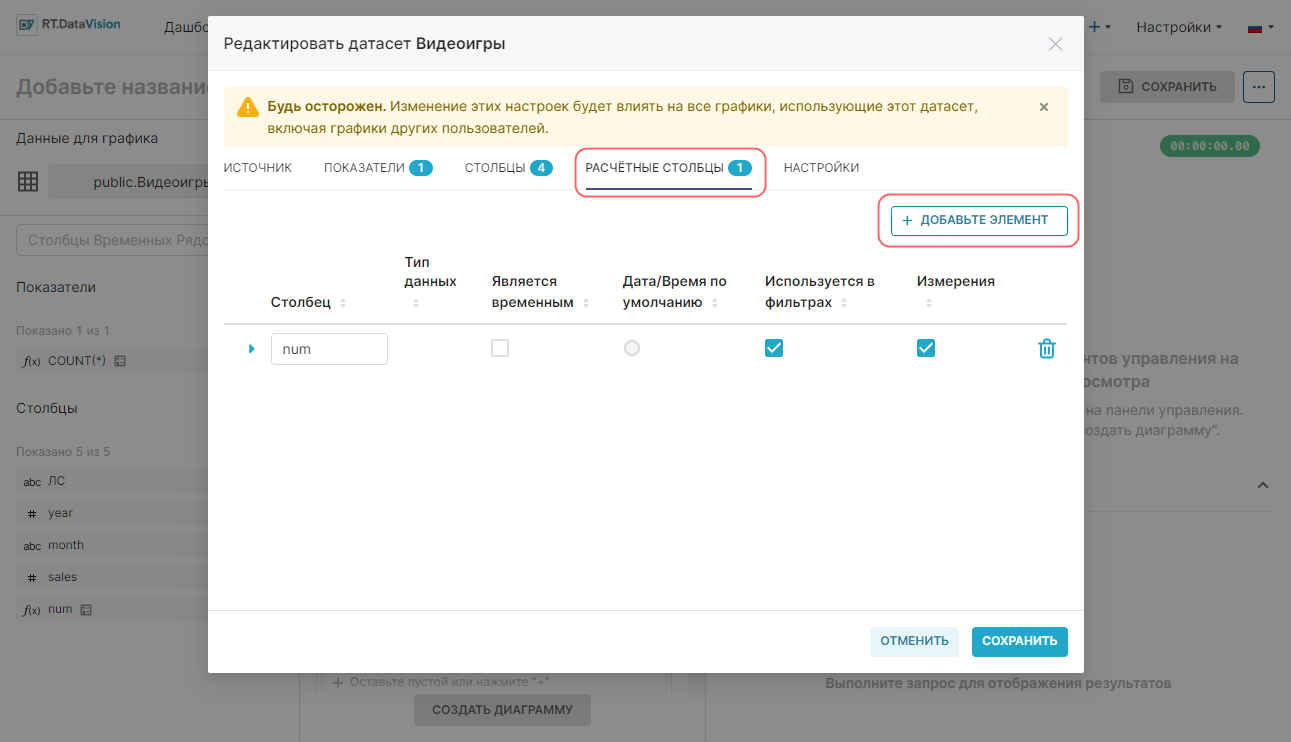
Появится новая предварительно развёрнутая строка. По умолчанию установлены отметки в полях Используется в фильтрах (Is filterable) и Измерения (Is dimension).
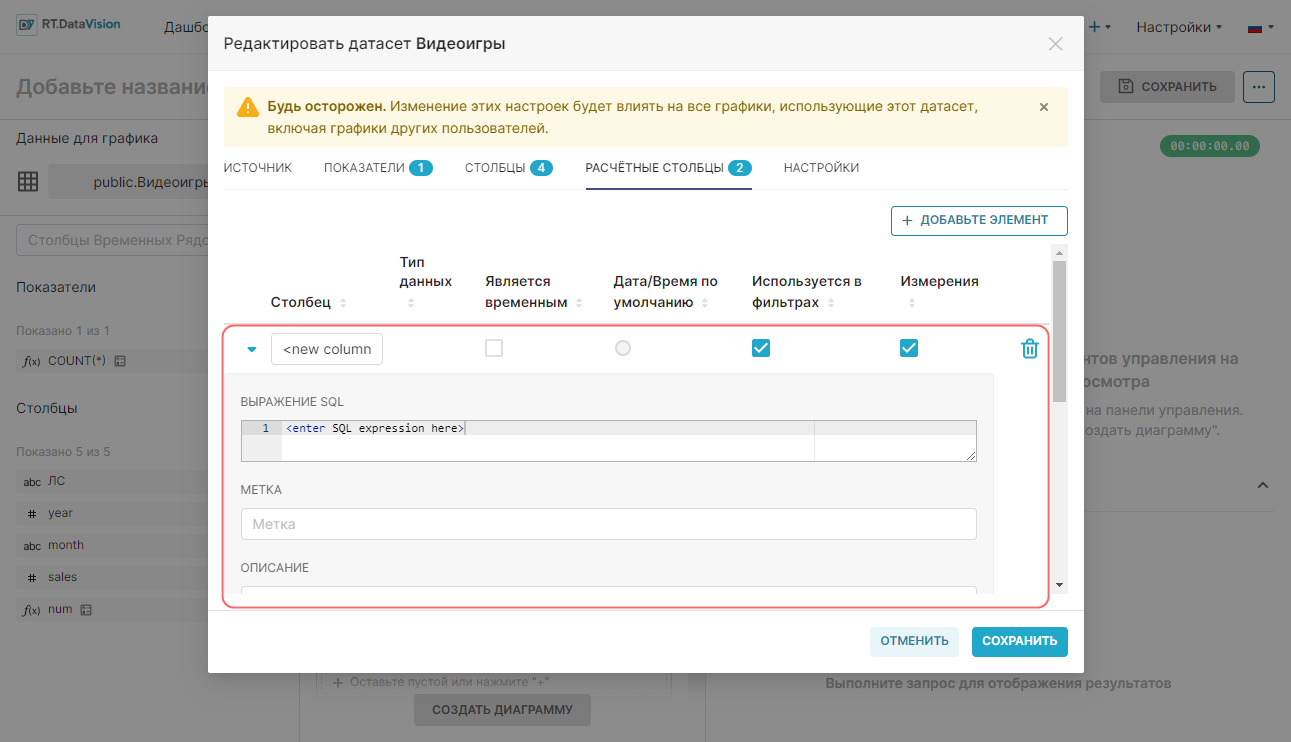
3. Укажите имя для нового расчётного столбца. По умолчанию имя столбца <new column>.
4. Введите выражение SQL для нового расчётного поля в поле Выражение SQL (SQL Expression). Указанное здесь выражение также появляется в виде всплывающей подсказки при наведении курсора на значок вопросительного знака.
5. Укажите имя метки в поле Метка (Label). Метка — это то, что увидят конечные пользователи.
6. Укажите краткое описание расчётного столбца в поле Описание (Description). Указанное здесь описание также появляется в виде всплывающей подсказки при наведении курсора на значок всплывающей подсказки расчётного столбца i.
7. Выберите соответствующий тип данных для расчётного столбца в поле Тип данных (Data Type) .
8. Введите формат даты и времени в поле Формат времени (Datetime Format), используя формат Python.
9. Укажите сведения о сертификации в полях Сертифицирован (Certified By) и Детали сертификации (Certfication Details) при необходимости.
10. Нажмите кнопку Сохранить (Save).
Новый расчетный столбец будет добавлен в выбранном датасете.
¶ 4. Создание графиков
¶ 4.1. Общая информация
Способы создания графиков в RT.DataVision:
- Через предварительно сохранённый датасет (см. раздел Создание датасетов).
- Через запрос, созданный в SQL Lab (Лаборатория SQL).
¶ 4.2. Создание графика
¶ 4.2.1. Создание графика через датасет
Начиная с создания физического или виртуального датасета, можно масштабировать построение графика и повторно использовать предварительно определённые метрики. Процесс создания датасетов подробно описан в разделах Физические датасеты и Виртуальные датасеты.
В верхней части панели инструментов нажмите на значок + и пункт меню выберите График (Chart).
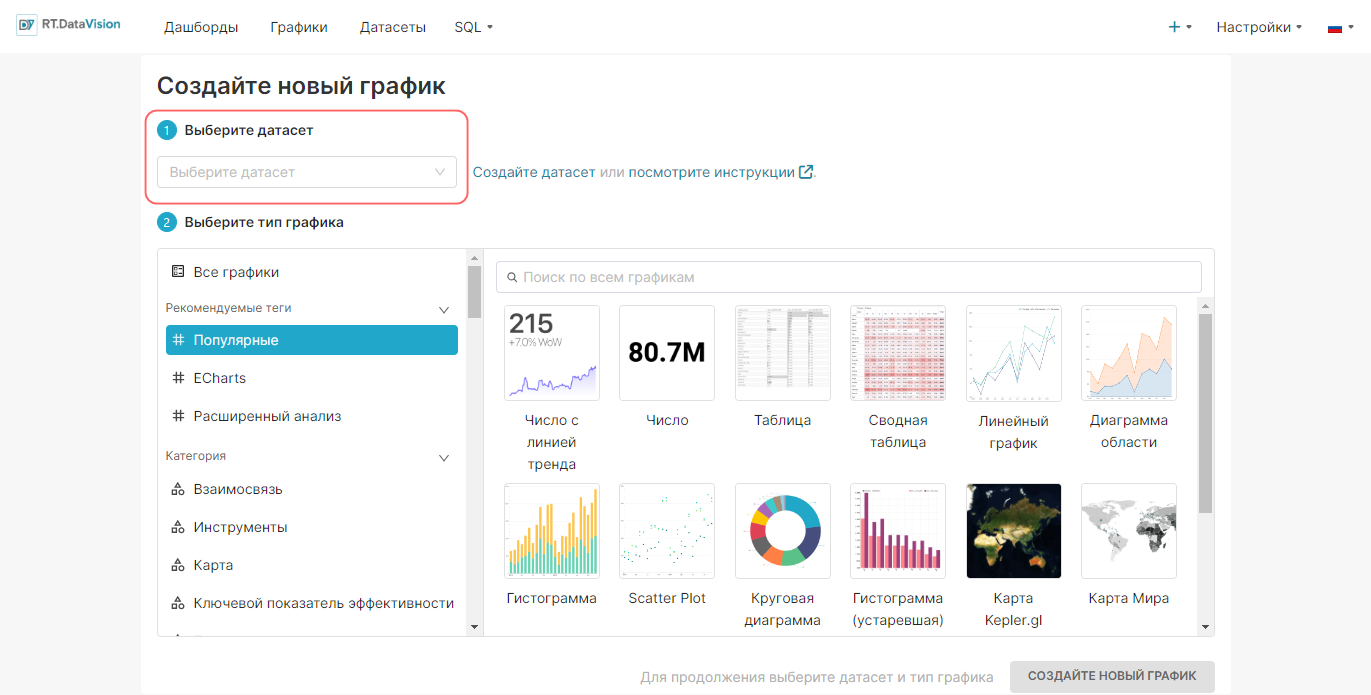
Откроется форма Создайте новый график (Create a new chart). В поле Выберите датасет (Choose a dataset) выберите необходимый датасет из раскрывающегося списка. Для удобства можно воспользоваться поиском.
¶ 4.2.2. Создание графика через SQL-запрос
В качестве альтернативы, начав создание графика с SQL-запроса, можно более гибко изучить используемые данные и решить, какие метрики будут использоваться.
В верхней части навигации выберите SQL (SQL) → Лаборатория SQL (SQL Lab).
Выберите источник данных на панели, расположенной в левой части формы, и введите SQL-запрос в текстовое поле.
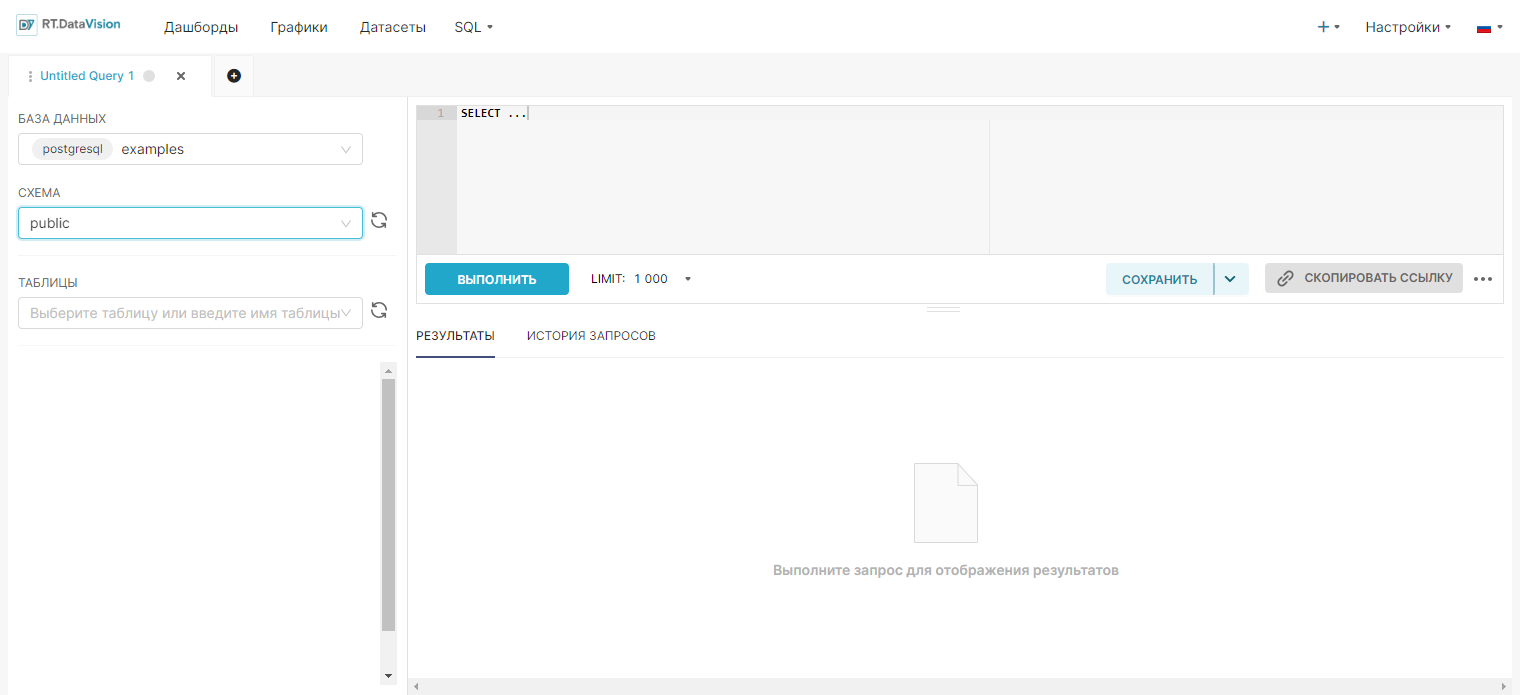
Запустите запрос кнопкой Выполнить (Run). Если запрос корректен, то создайте график с помощью кнопки Создать диаграмму (Create chart).
¶ 4.2.2. Выбор типа графика
Выберите тип графика в окне Создать новый график (Create a new chart) и укажите необходимый датасет в поле Выберите датасет (Choose a dataset). Можете выбрать тип графика из рекомендованных (например, с тегом #Популярные (#Popular)) или из необходимой категории (например, из категории Взаимосвязь (Correlation)).
¶ 4.2.3. Настройка графика
На странице Исследовать (Explore) перетащите записи с левой панели из панелей Показатели (Metrics) и Столбцы (Columns) на соседнюю панель на вкладку Данные (Data).
¶ 4.3. Использование Explore
¶ 4.3.1. Общая информация
В этом разделе будет описано, как работает страница Исследовать (Explore), и продемонстрирован процесс настройки графика и выполнения запроса.
¶ 4.3.2. Обзор панели Dataset
Перед созданием любого графика проверьте информацию в панели Данные для графика (Chart Source). В левом верхнем углу Исследовать (Explore) отображается используемый датасет.
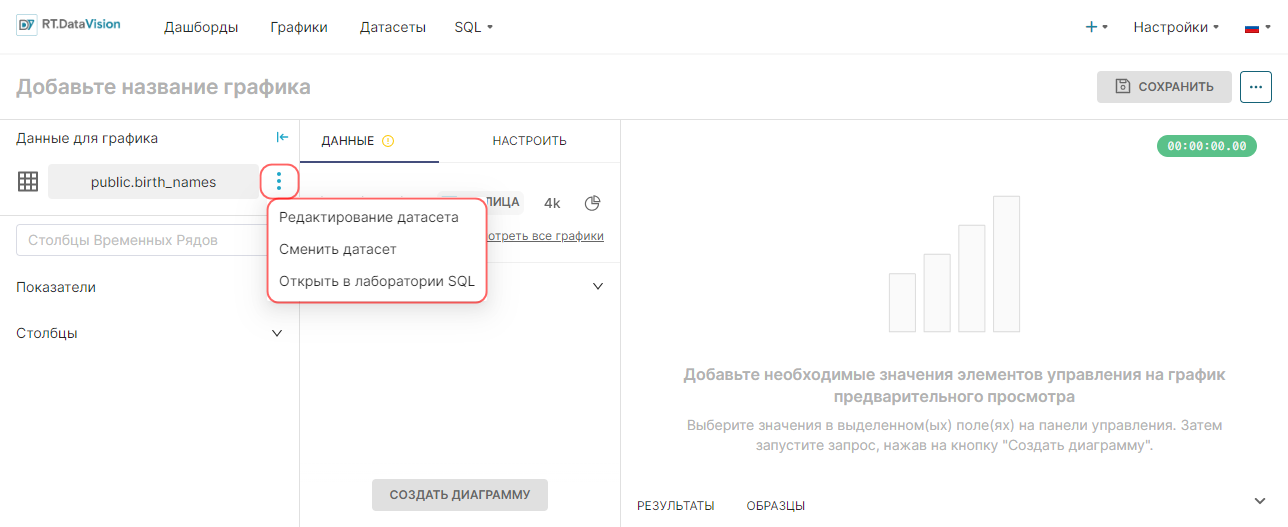
Чтобы посмотреть опции, доступные для датасета, нажмите значок с тремя точками. Отобразятся следующие опции:
- Редактировать датасет (Edit dataset) — позволяет настроить выбранный датасет. При нажатии откроется окно Редактировать датасет (Edit dataset). Редактирование датасета может повлиять на все графики, использующие этот датасет;
- Сменить датасет (Change dataset) — позволяет заменить текущий датасет на другой. При нажатии откроется окно Сменить датасет (Change dataset);
- Открыть в лаборатории SQL (View in SQL Lab) — позволяет открыть датасет как запрос SQL. При нажатии откроется Лаборатория SQL (SQL Lab).
¶ 4.3.3. Обзор панелей Показатели и Столбцы
Под панелью Данные для графика (Chart Source) находится панели Показатели (Metrics) и Столбцы (Columns). Поле Поиск показателей и столбцов (Search Metrics & Columns) позволяет быстро найти нужные данные.
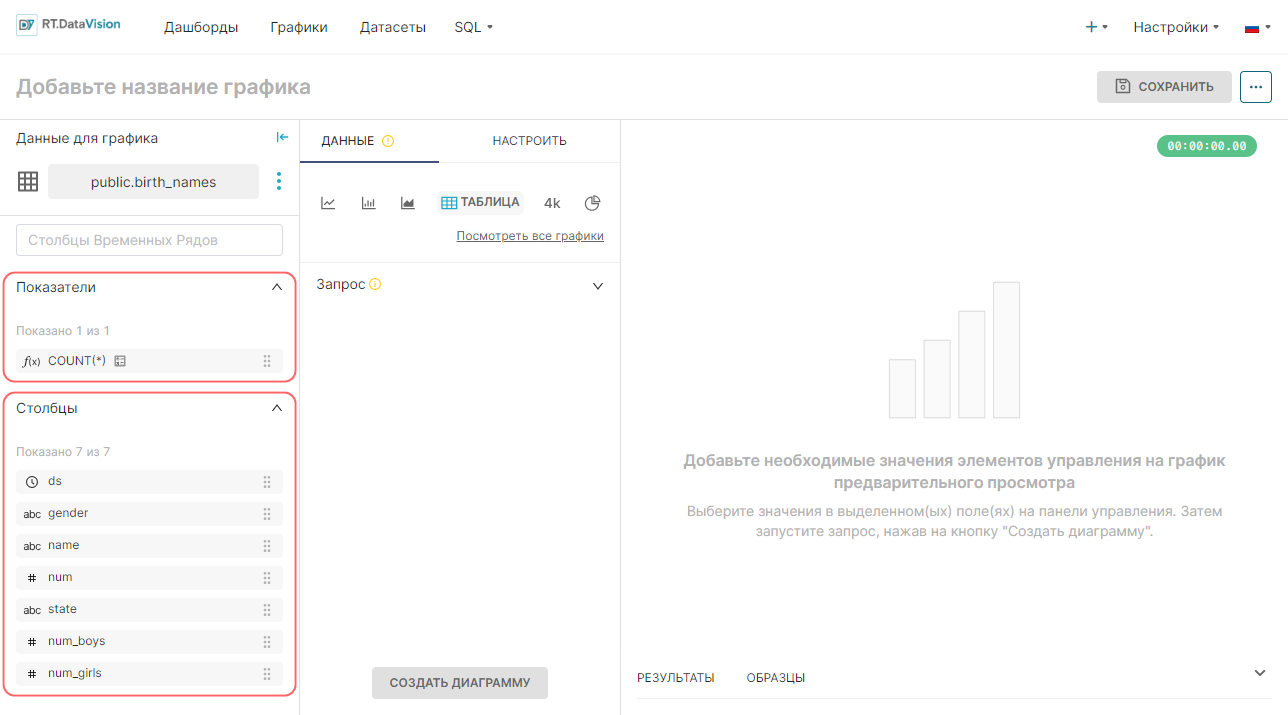
Каждому типу данных соответствует значок, обозначающий его тип:
- ƒ — функция, используемая для метрик;
- Часы — столбец времени источника данных;
- ABC — текстовые данные;
- # — числовое значение данных.
Метрики и столбцы можно перетаскивать на соседнюю панель для настройки визуализации.
¶ 4.3.4. Обзор панели визуализации
Панель визуализации используется для изменения типа графика.
С помощью кнопки Посмотреть все графики (View all charts) можно изменить тип графика, выбрав необходимый график из рекомендованных (например, с тегом #Популярные (#Popular)) или из необходимой категории (например, из категории Взаимосвязь (Correlation)). При изменении типа графика настройки, выполненные ранее на панели визуализации, будут сохранены.
¶ 4.3.5. Настройка полей
¶ 4.3.5.1. Просмотр примеров данных
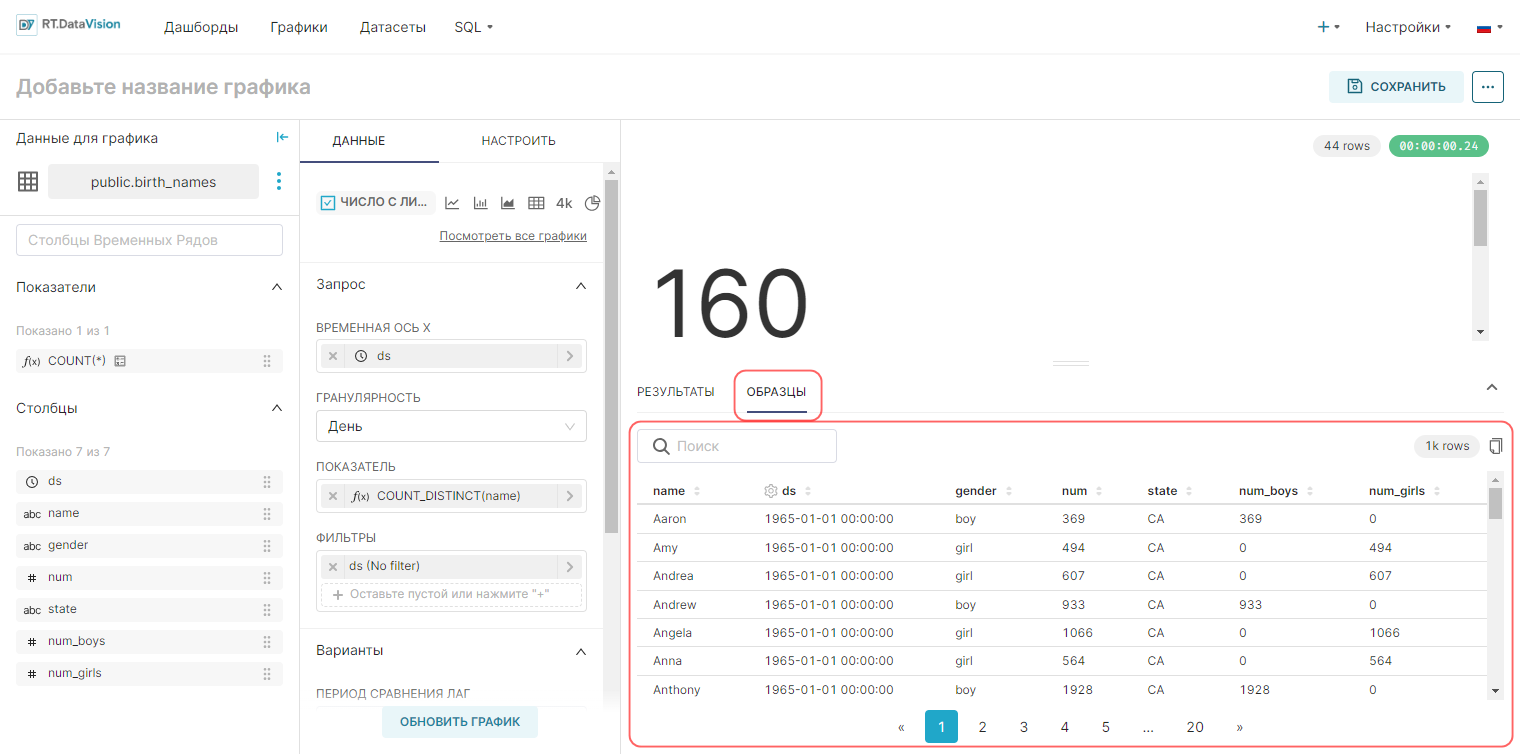
Перед настройкой полей для графика, рекомендуется исследовать данные в используемом датасете (для понимания того, что именно в них содержится). Для получения сырых данных в виде таблицы перейдите на вкладку Образцы (Samples).
¶ 4.3.5.2. Выбор параметров времени
Панель Время (Time) используется для выбора элемента данных датасета, связанного со временем (поле Столбец с временем (Time Column)), указания степени гранулярности отображаемых значений с помощью поля Гранулярность (Time Grain) и определения диапазона времени (поле Диапазон времени (Time Range)), который используется для указания диапазонов дат, от каких данных будут извлечены из источника данных.
Если поле Столбец с временем (Time Column) не заполнилось автоматически столбцом даты и времени, то перетащите необходимый столбец для выполнения запроса.
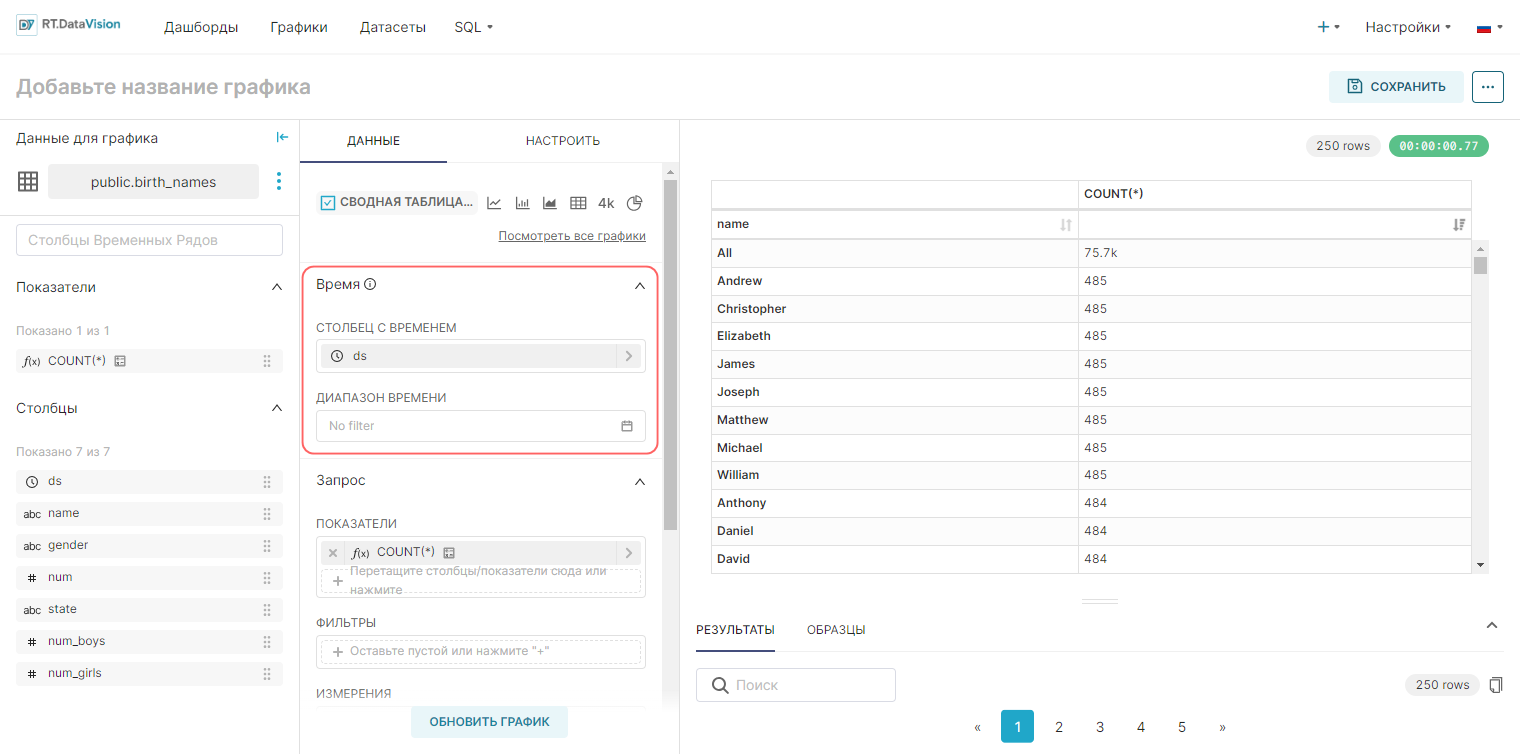
¶ 4.3.5.3. Добавление метрик или столбцов
Для формирования графика перетащите метрику или столбец в необходимое поле назначения на вкладке Данные (Data). После перемещения метрики или столбца в необходимое поле отобразиться всплывающее окно для выбора дополнительных подробностей.
Примечание. Поля, обязательные для заполнения, отмечены значком восклицательным знаком.
¶ 4.4. Конфигурирование времени
¶ 4.4.1. Общая информация
В RT.DataVision существует ряд различных временных диапазонов, для дополнительной настройки графика. Временные диапазоны настраиваются в Исследовать (Explore) Данные (Data) → Время (Time).
¶ 4.4.1.1. Выбор гранулярности (Time Grain)
Для указания степени гранулярности отображаемых значений выберите необходимый вариант в поле Гранулярность (Time Grain). Существует возможность выбора следующих значений:
- Секунда;
- Минута;
- Час;
- День;
- Неделя;
- Месяц;
- Квартал;
- Год.
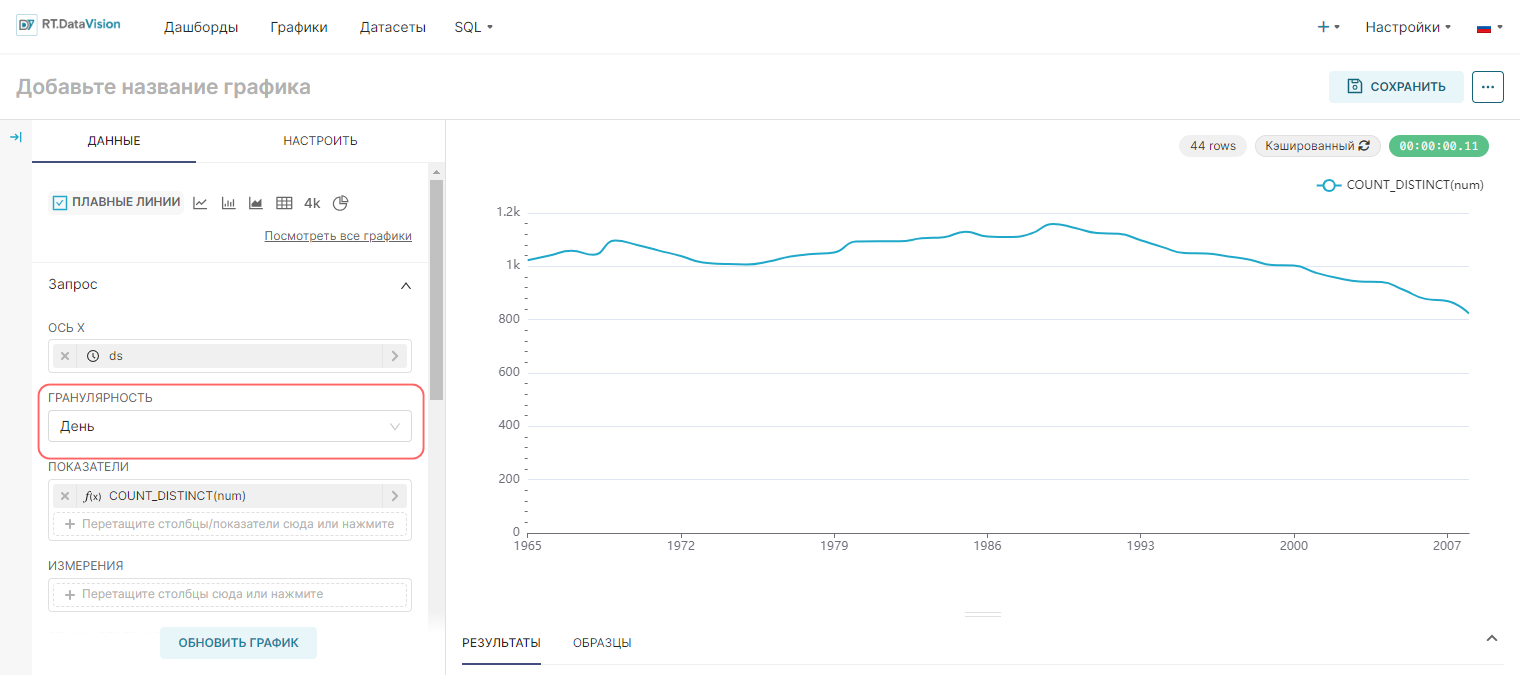
¶ 4.4.2. Выбор диапазона времени
Для указания диапазона даты и времени, из которого будут извлекаться данные для запроса, выберите необходимое значение в поле Диапазон времени (Time Range):
- Последний (Last);
- Предыдущий (Previous);
- Пользовательский (Custom);
- Расширенные (Advanced);
- Без фильтра (No Filter).
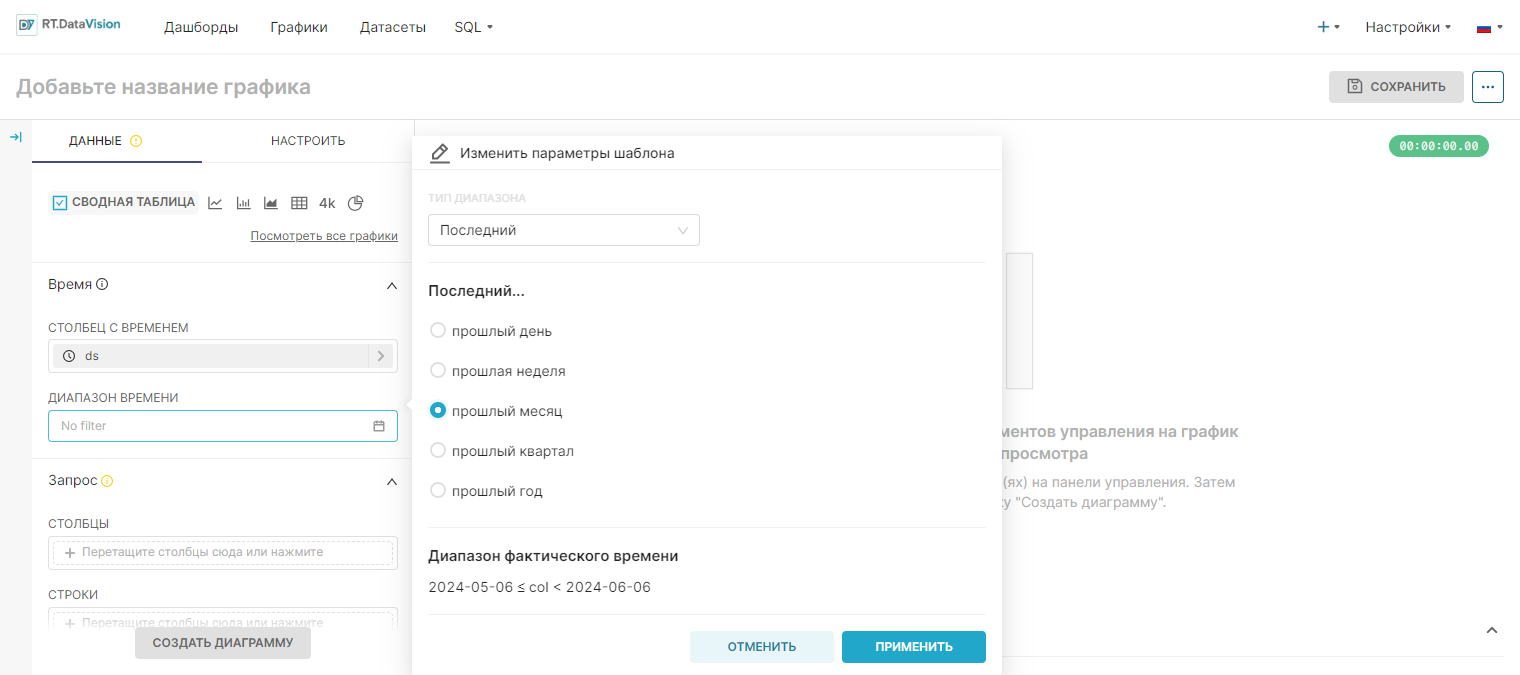
¶ 4.4.2.1. Тип диапазона Последний (Last)
При выборе значения Последний (Last) в поле Тип диапазона (Range Type) RT.DataVision будет отображать диапазон дат, который начинается с начала выбранного параметра и заканчивается в 23:59:59 вчера.
Примечание. Вариант Последний (Last) не включает данные за сегодняшний день, чтобы избежать предоставления частичных данных.
Примеры:
- Прошлый месяц (Last Month) — если сегодня 6 июня 2024 г., то параметр Прошлый месяц (Last Month) будет извлекать данные с 6 мая 2024 г. включительно до 6 июня 2024 г. В поле Диапазон фактического времени (Actual time range) отображается установленное значение диапазона 2024-05-06 ≤ col < 2024-06-06, т.е. диапазон дат начинается 6 мая 2024 года в 00:00:00 и заканчивается 5 июня 2024 года в 23:59:59;
- Прошлый год (Last year) — если сегодня 6 июня 2024 г., то параметр Прошлый год (Last year) будет извлекать данные с 6 июня 2023 г. включительно до 6 июня 2024 г. В поле Диапазон фактического времени (Actual time range) отображается установленное значение диапазона 2023-06-06 ≤ col < 2024-06-06, т.е. диапазон дат начинается 6 июня 2023 года в 00:00:00 и заканчивается 5 июня 2024 года в 23:59:59.
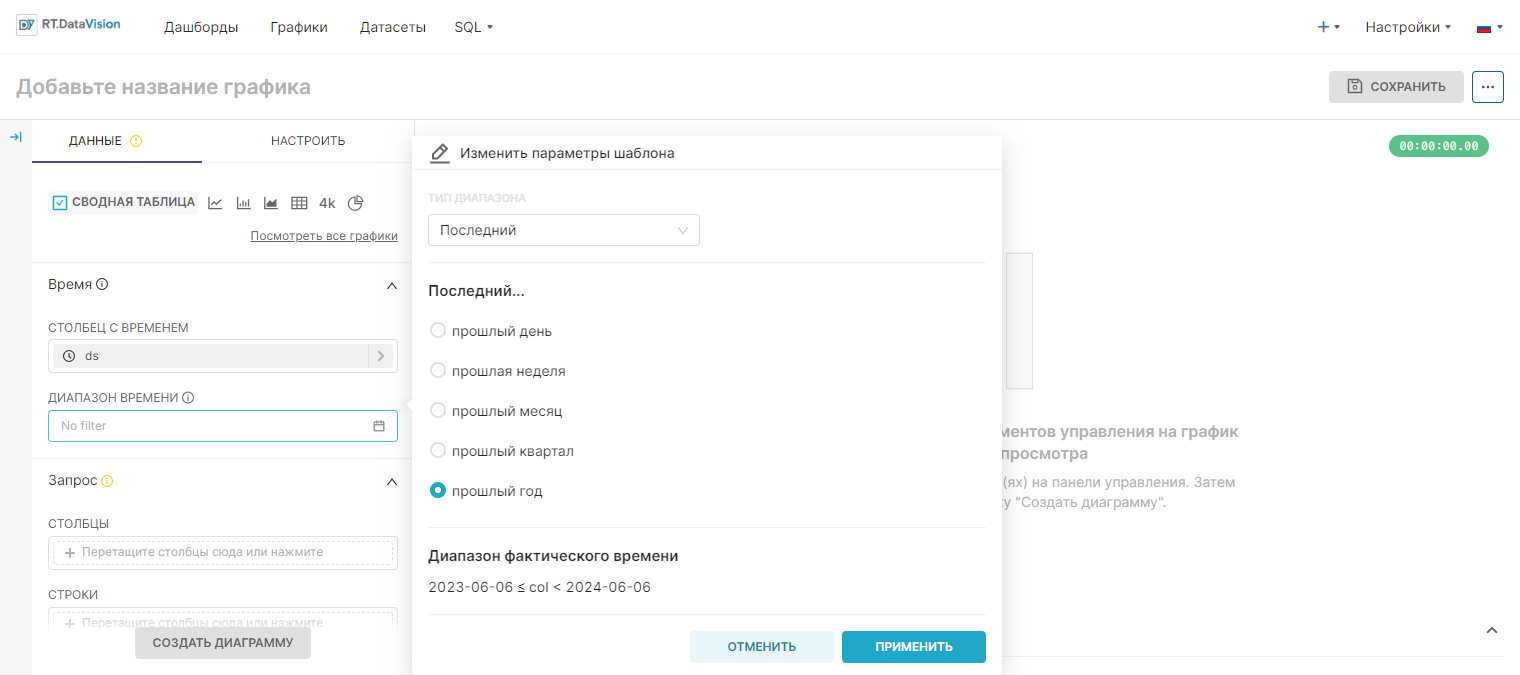
¶ 4.4.2.2. Тип диапазона Предыдущий (Previous)
При выборе значения Предыдущий (Previous) в поле Тип диапазона (Range Type) RT.DataVision будет отображать диапазон дат, основанный на предыдущей секции календаря, т.е. предыдущая календарная неделя, календарный месяц или календарный год.
Пример:
- Предыдущий календарный месяц (Previous Calendar Month) — если сегодня 6 июня 2024 г., то при выборе параметра Предыдущий календарный месяц (Previous Calendar Month) будут получены все дни календарного месяца мая 2024 г. В поле Диапазон фактического времени (Actual time range) отображается установленное значение диапазона 2024-05-01 ≤ col < 2024-06-01, т.е. диапазон дат начинается 1 мая 2024 года в 00:00:00 и заканчивается 31 мая 2024 года в 23:59:59.
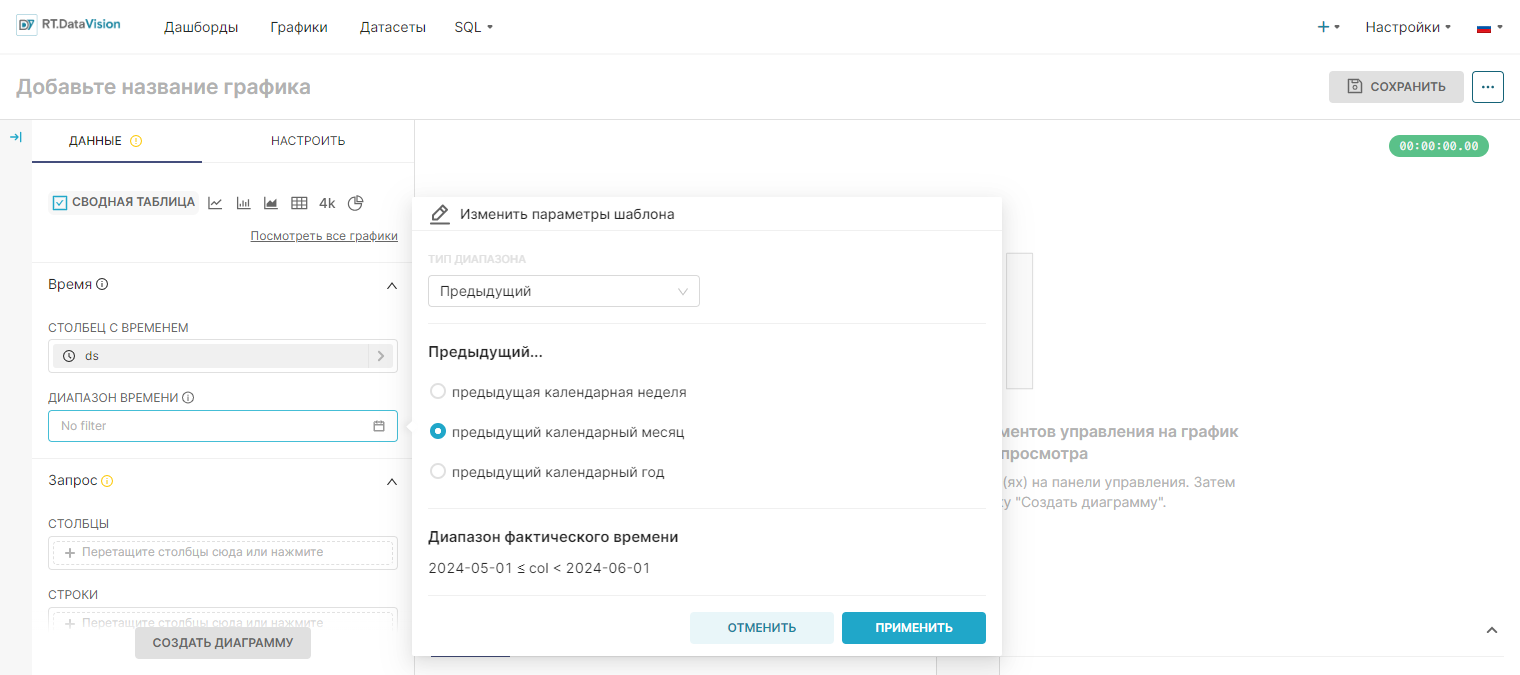
¶ 4.4.2.3. Тип диапазона Пользовательский (Custom)
При выборе значения Пользовательский (Custom) в поле Тип диапазона (Range Type) в RT.DataVision будет отображаться диапазон дат, основанный на заданных датах начала и окончания.
Параметры включают:
- Начало (включительно) (Start (inclusive)) – включает указанную дату начала:
- Корректная дата/время (Specific Date/Time) — введите дату и время в формате yyyy-mm-dd hh:mm:ss;
- Относительная дата/время (Relative Date/Time):
- Значение (Value) — введите число;
- <х> До (Before) — где <x> = Секунды (Seconds) | Минуты (Minutes) | Часы (Hours) | Дни (Days) | Недели (Weeks) | Месяцы (Months) | Кварталы (Quarters) | Годы (Years) (т.е. например, секунды до, дни до и т.д.);
- Сейчас (Now) — выбирает текущую дату и время;
- Полночь (Midnight) — выбирает сегодня в 00:00:00;
- Конец (не включительно) (End (exclusive)) – исключает указанную дату окончания:
- Корректная дата/время (Specific Date/Time) — введите дату и время в формате yyyy-mm-dd hh:mm:ss;
- Относительная дата/время (Relative Date/Time):
- Значение (Value) — введите число;
- <х> До (Before) — где <x> = Секунды (Seconds) | Минуты (Minutes) | Часы (Hours) | Дни (Days) | Недели (Weeks) | Месяцы (Months) | Кварталы (Quarters) | Годы (Years) (т.е. например, секунды до, дни до и т.д.);
- Сейчас (Now) — выбирает текущую дату и время;
- Полночь (Midnight) — выбирает сегодня в 00:00:00.
Пример:
- В этом примере выбрано значение Пользовательский (Custom) в поле Тип диапазона (Range Type), и сконфигурирован диапазон дат 10 недель до текущего дня. В поле Диапазон фактического времени (Actual time range) отображается значение 2024-03-28T17:28:38 ≤ col < 2024-06-06T17:28:38.
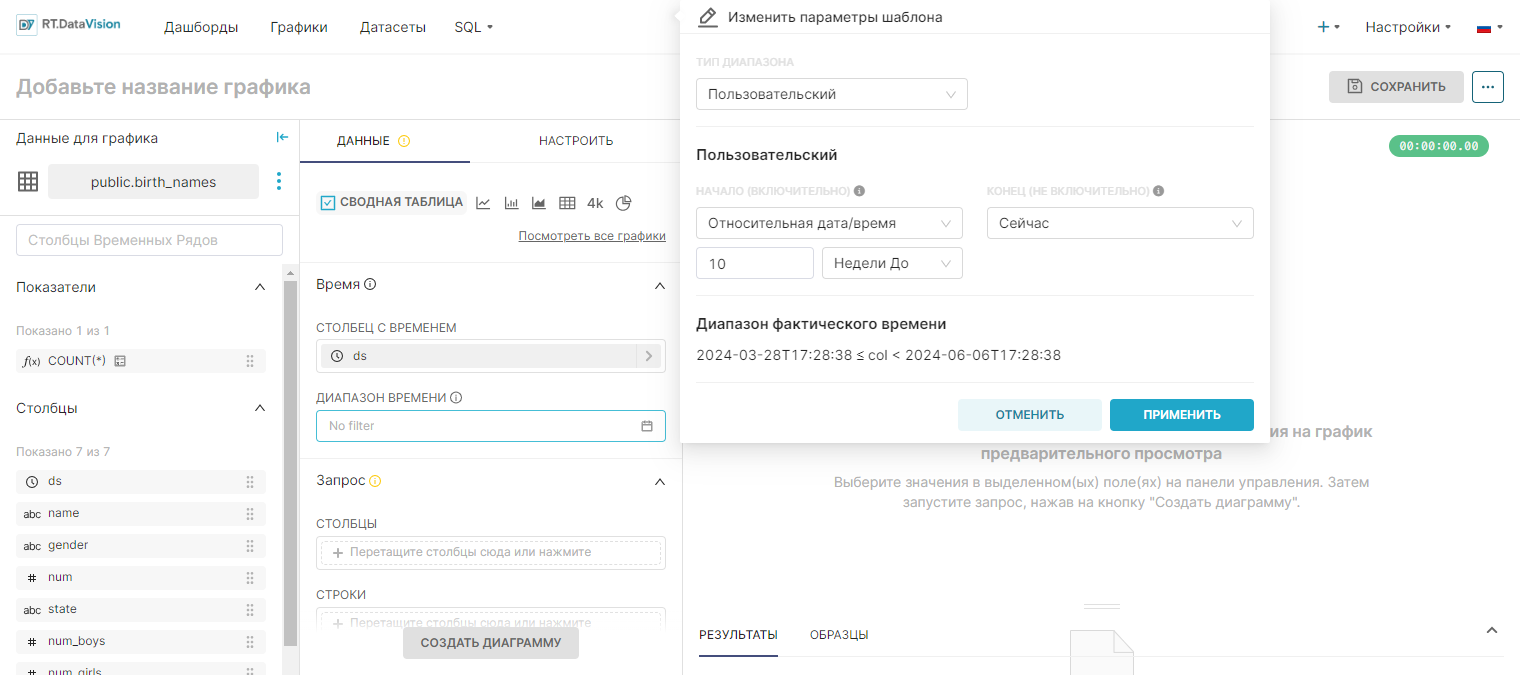
¶ 4.4.2.4. Тип диапазона Расширенные (Advanced)
При выборе значения Расширенные (Advanced) в поле Тип диапазона (Range Type) RT.DataVision использует свои логические возможности AI для определения конкретной даты на основе ввода.
Примеры текста для полей Начало (включительно) (Start (inclusive)) и Конец (не включительно) (End (exclusive)):
- 3 weeks ago – 3 недели назад;
- today – сегодня;
- now – сейчас;
- next 2 weeks – следующие 2 недели;
- next year – следующий год;
- yesterday – вчера;
- last monday – в прошлый понедельник.
Если значения в полях Начало (включительно) (Start (inclusive)) и/или Конец (не включительно) (End (exclusive)) не указаны, то RT.DataVision установит значение ∞ (бесконечность). Это означает, что все новые данные включаются до текущей даты и времени включительно.
Пример:
- В приведённом ниже примере указан диапазон дат от прошедших 2-х недель и не указана дата окончания. Если сегодня 6 июня 2024 г., то RT.DataVision будет включать все данные двухнедельной давности, а именно с 23 мая 2024 г. до бесконечности (будут включены все новые данные). В поле Диапазон фактического времени (Actual time range) будет отображаться значение 2024-05-23 ≤ col < ∞.
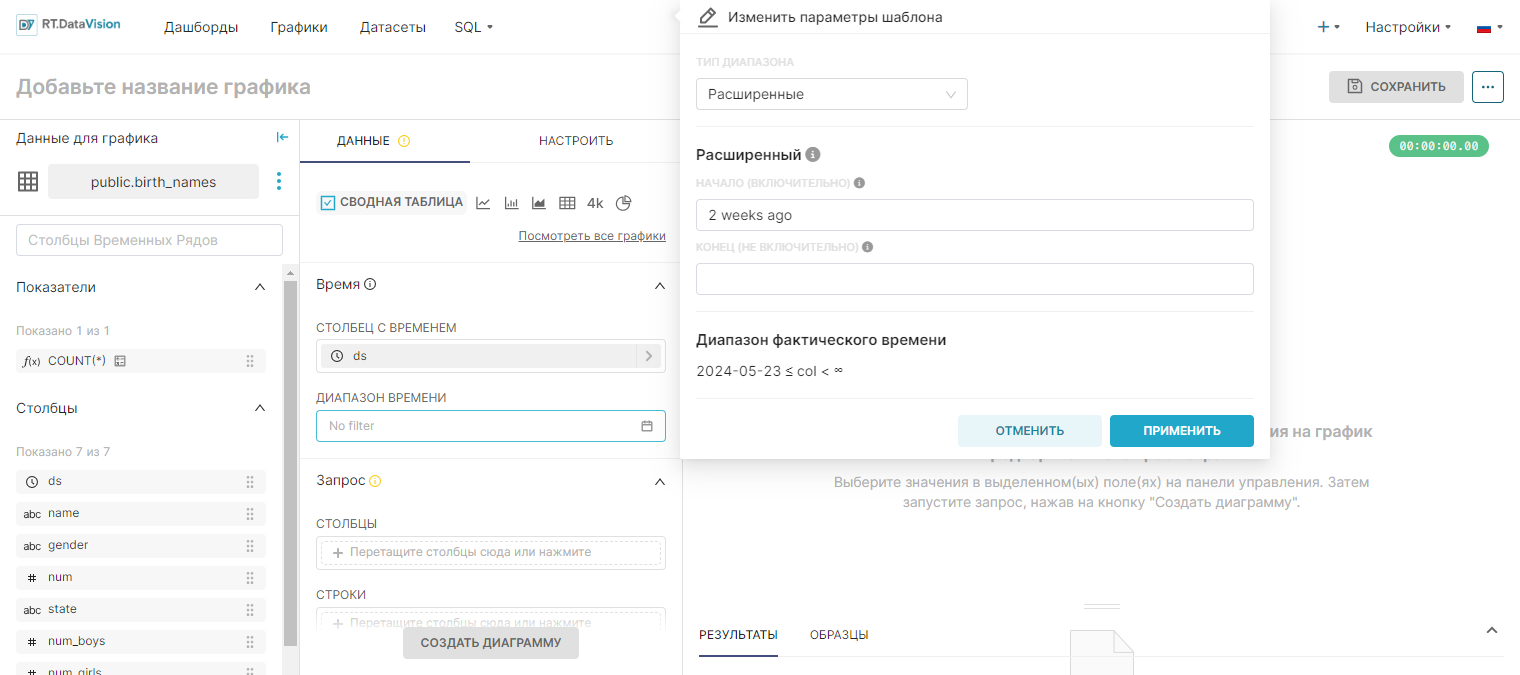
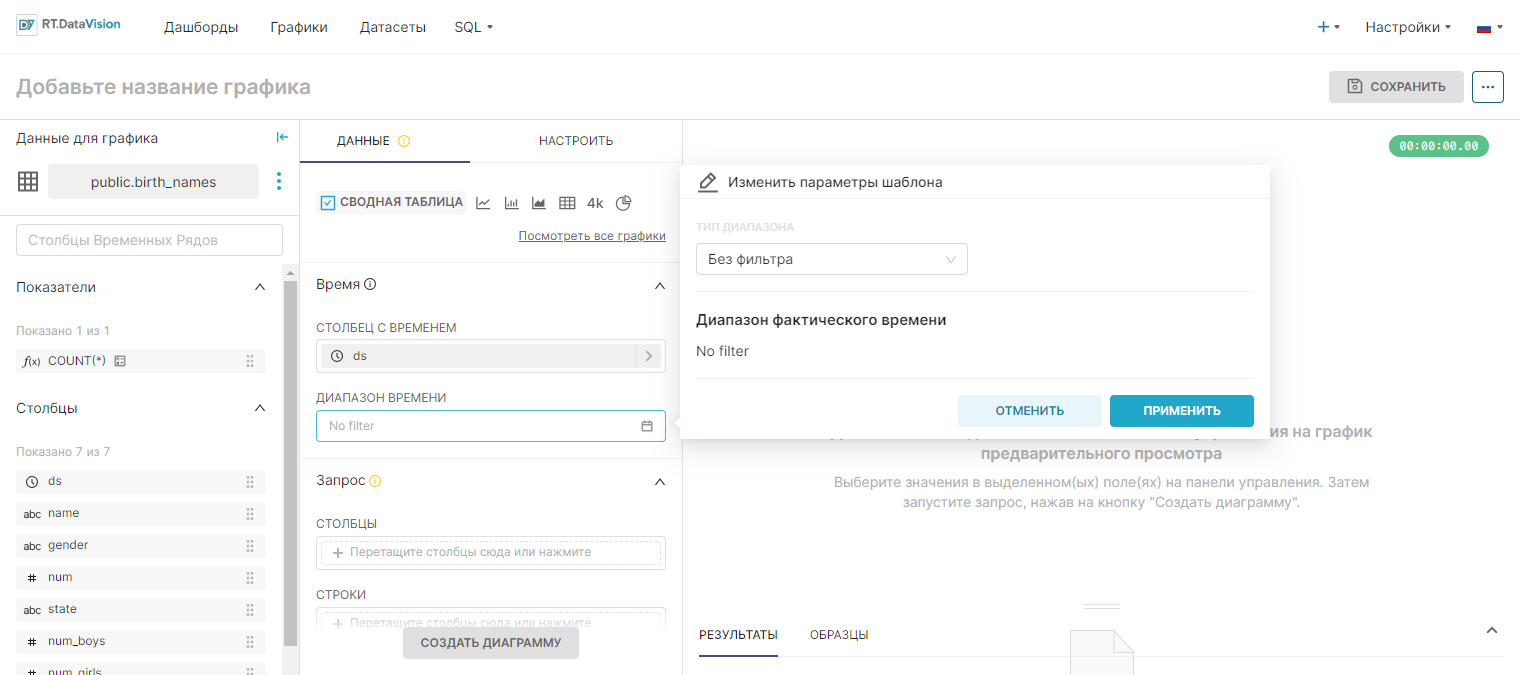
¶ 4.4.2.5. Тип диапазона Без фильтра (No Filter)
Чтобы получить доступ ко всем данным в датасете, без применения каких-либо фильтров временного диапазона, выберите Без фильтра (No Filter) в поле Тип диапазона (Range Type). Этот выбор рекомендуется, если используется датасет с ограниченным объёмом данных.
¶ 4.5. Форматирование осей
Кастомное форматирование, расположенное в Исследовать (Explore) → Настроить (Customize) предоставляет больший контроль над тем, как числовые данные отображаются на графике в RT.DataVision. С помощью кастомного форматирования можно применить параметры форматирования библиотеки Python D3 к числовым данным, отображаемым в визуализациях.
Примечание. Каждый тип визуализации имеет различные параметры настройки.
Вы можете изменить формат на отображаемые параметры:
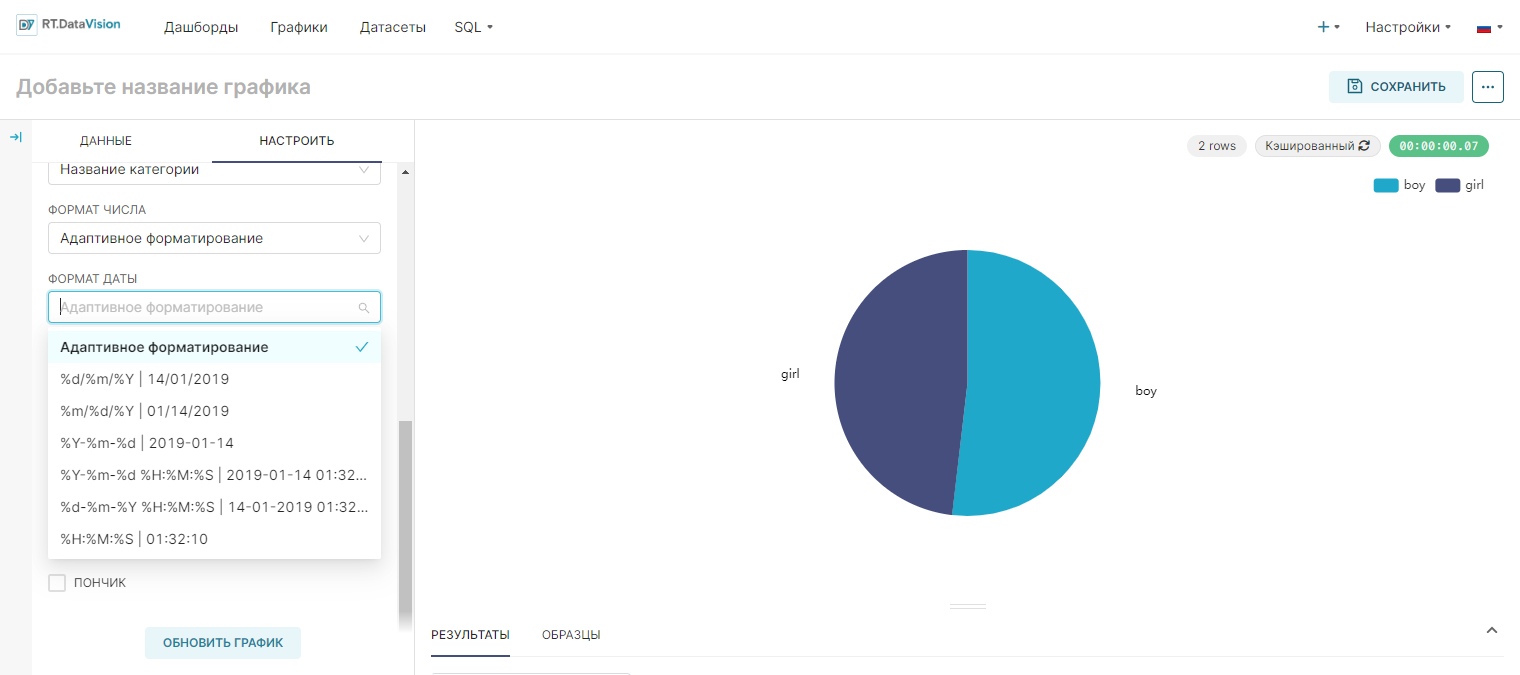
По умолчанию RT.DataVision задаёт формат Адаптивное форматирование (Adaptive Formatting). Для изменения формата выберите один из доступных параметров или введите соответствующий параметр форматирования D3.
¶ 4.5.1. Форматы даты
Форматы даты приведены в таблице:
| Формат | Описание | Пример |
|---|---|---|
| %a | День недели, короткая версия | Wed |
| %A | День недели, полная версия | Wednesday |
| %w | День недели в виде числа 0-6, где 0 — воскресенье | 3 |
| %d | День месяца в виде числа 01-31 | 31 |
| %b | Название месяца, короткая версия | Dec |
| %B | Название месяца, полная версия | December |
| %m | Месяц в виде числа 01-12 | 12 |
| %y | Год, короткая версия, без века | 18 |
| %Y | Год, полная версия | 2018 |
| %H | Час, число 00-23 | 17 |
| %I | Час, число 00-12 | 05 |
| %p | AM/PM | AM |
| %M | Минуты, число 00-59 | 41 |
| %S | Секунды, число 00-59 | 08 |
| %f | Микросекунды, число 000000-999999 | 548513 |
| %z | Смещение UTC | +0100 |
| %Z | Часовой пояс | CST |
| %j | День года, число 001-366 | 365 |
| %U | Неделя года, воскресенье как первый день недели, число 00-53 | 52 |
| %W | Неделя года, понедельник как первый день недели, число 00-53 | 52 |
| %c | Локальная версия даты и времени | Mon Dec 31 17:41:00 2018 |
| %x | Локальная версия даты | 12/31/18 |
| %X | Локальная версия времени | 17:41:00 |
| %% | Символ | % |
¶ 4.5.2. Другие форматы
Для других форматов, таких как числа или валюта, обратитесь к библиотеке D3.
¶ 5. Типы визуализации графиков
¶ 5.1. Общая информация
RT.DataVision предлагает множество различных графиков, предназначенных для визуализации ваших данных. Для просмотра всех возможностей, на панели инструментов выберите + Chart (+ График) и отфильтруйте по Все графики (All charts).
| Наименование графика | Описание | |
|---|---|---|
| Ядро | ||
| Гистограмма (Bar Chart) | Гистограммы обеспечивают простой для понимания способ визуального представления категорийных данных. | |
| Число (Big Number) | Полезно для выделения одной метрики или ключевого показателя эффективности в определённый момент времени. | |
| Большое количество с трендом (Big Number with Trendline) | Вариант диаграммы Big Number, которая также включает линию тренда для демонстрации последних изменений в метрике. | |
| Диаграмма воронка (Funnel Chart) | Использует толщину компонентов физической воронки для демонстрации различных этапов пайплайна в ваших операциях. | |
| Калибровочная диаграмма (Gauge Chart) | Повторно использует шкалы из научной и промышленной среды, чтобы продемонстрировать частичный прогресс в достижении определённого числа. | |
| Круговая диаграмма (Pie Chart) | Круговой статистический график, показывающий пропорцию различных данных, передаваемых в виде слайсов внутри круга (т.е. кругового графика). | |
| Сводная таблица (Pivot Table) | Базовая таблица сгруппированных значений, объединяющая отдельные элементы более обширной таблицы в одной или нескольких дискретных категориях. | |
| Таблица (Table Chart) | Построчная таблица, похожая на представление датасета. Используйте таблицы, чтобы продемонстрировать представление базовых данных или показать агрегированные метрики. | |
| Древовидная диаграмма (Treemap) | Использует масштабированные прямоугольники для визуализации одной и той же метрики в нескольких разных группах. | |
| Временные ряды | ||
| График смешанных временных рядов (Mixed Chart) | Объединяет несколько визуализаций временных рядов в одном контейнере графика, используя общую временную ось X. | |
| Диаграмма области (Area Chart) | Использует меняющуюся область под линиями, чтобы визуализировать, как отношения, пропорции или проценты метрик изменяются с течением времени. | |
| Гистограмма временных рядов (Time-series Bar Chart) | Использует столбцы, чтобы визуализировать изменение метрики с течением времени. | |
| Линейный график временных рядов (Time-series Line Chart) | Использует линии для визуализации того, как метрики изменяются с течением времени. | |
| Точечный график временных рядов (Time-series Scatter Plot) | Использует точки для визуализации того, как метрики изменяются с течением времени. | |
| Плавные линии (Smooth Line) | Вариация линейного графика временных рядов, которая соединяет в сглаженную линию, соединяющую две точки данных. | |
| Ступенчатый график (Stepped Line) | Вариация линейного графика временных рядов, которая соединяет две точки данных с помощью линий с шагом 90 градусов. | |
| Прочее | ||
| Графическая диаграмма (Graph Chart) | Визуализирует связанные объекты или события с помощью узлов, окружностей и рёбер или соединённых линий между узлами. | |
| Радиальная диаграмма (Radar Chart) | Позволяет визуализировать параллельный набор метрик по нескольким группам или категориям. | |
| Диаграмма Санкей (Sankey Diagram) | Блок-схема, которая передаёт относительный размер метрических данных на основе размера линий потока от источника к цели. | |
| Древовидный график (Tree Chart) | Превосходно визуализирует иерархию. | |
¶ 5.2. Гистограмма (Bar Chart)
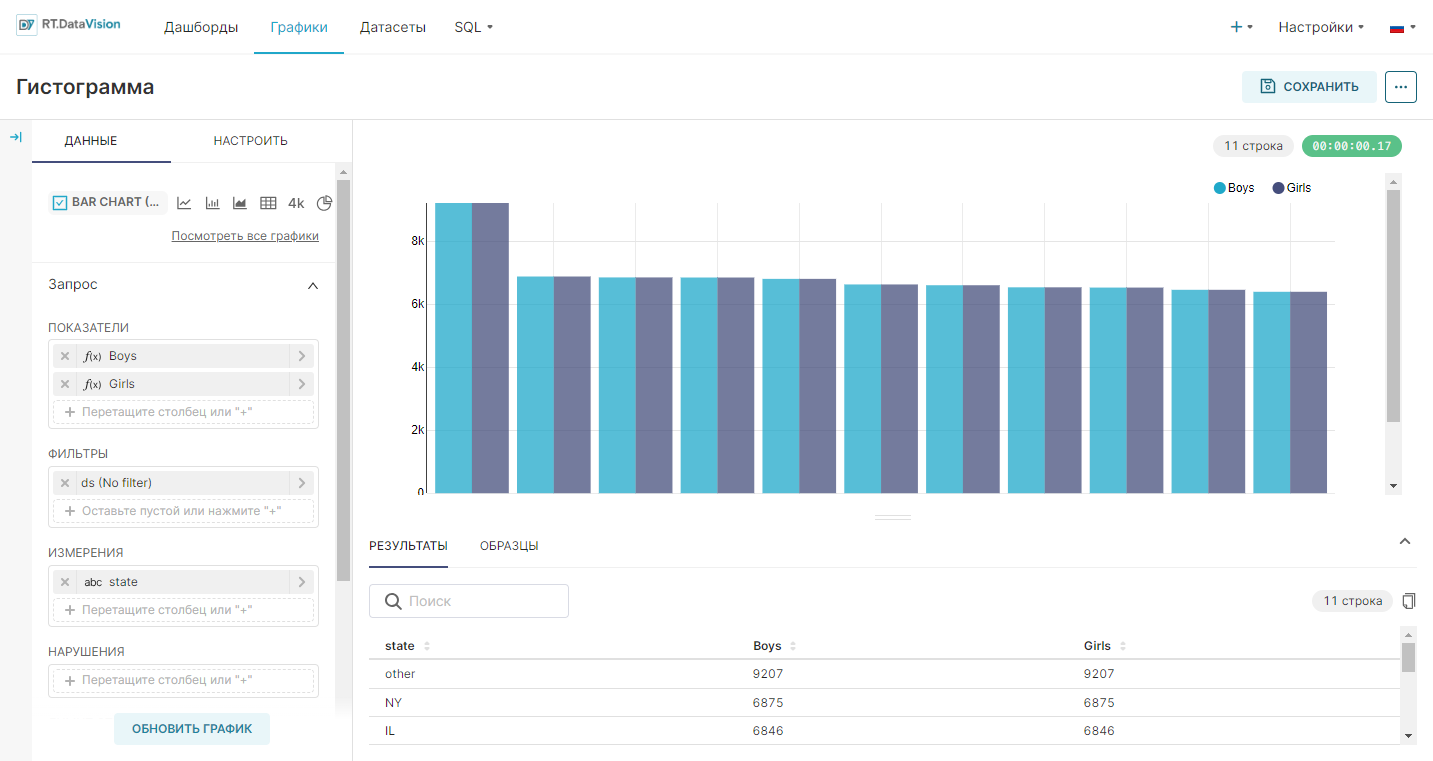
Гистограмма (Bar Chart) использует столбцы, для сравнивания метрики по группам или сегментам.
¶ 5.2.1. Создание гистограммы
В настоящее время RT.DataVision имеет несколько видов гистограмм в средстве выбора визуализации:
- Гистограмма (Bar Chart);
- Гистограмма временных рядов (Time-series Bar Chart);
- Гистограмма временных рядов v2 (Time-series Bar Chart v2).
При визуализации дискретных значений (где время не является осью X) по группам необходимо использовать тип визуализации Гистограмма (Bar Chart). Чтобы создать гистограмму, необходимо определить следующие значения:
- Ось Y — метрики, которые необходимо визуализировать на оси Y;
- Ось X — столбцы, по которым необходима группировка/классификация метрик.
Значения для осей X и Y определены на вкладке Данные (Data) в разделе Исследовать (Explore). Пример графика:
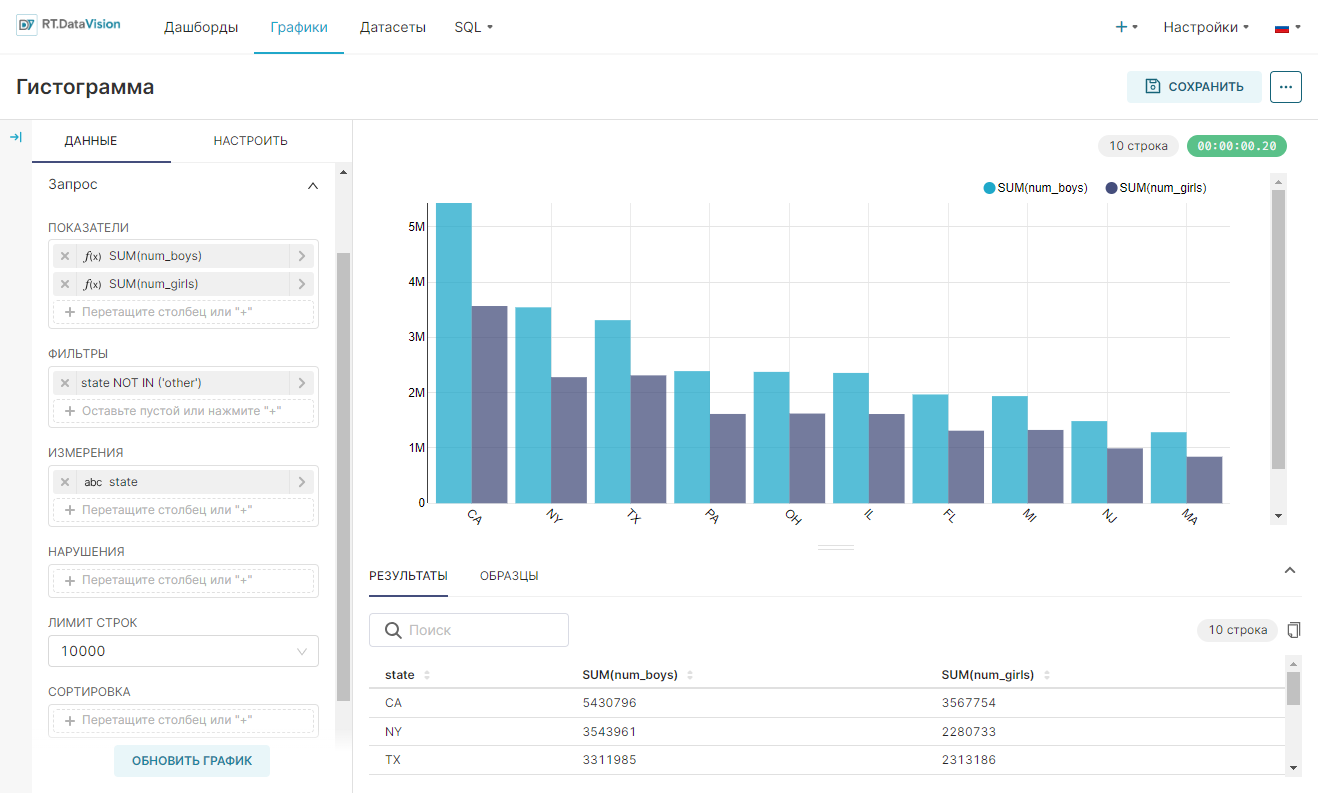
Значения, используемые для создания такого графика:
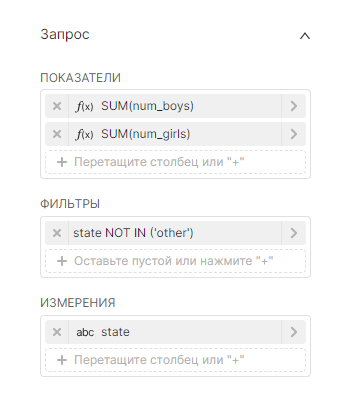 |
Параметры в Исследовать (Explore):
|
|
Сгенерированный SQL-запрос:
|
¶ 5.2.2. Гистограмма с более сложной группировкой
¶ 5.2.2.1. Несколько измерений
Для более сложных попарных групповых метрик, можно использовать несколько столбцов Измерения (Dimensions) в Исследовать (Explore). Этот метод будет генерировать m на n столбцов гистограммы, где m соответствует количеству групп в первом выбранном столбце, а n соответствует количеству групп во втором выбранном столбце. Пример графика:
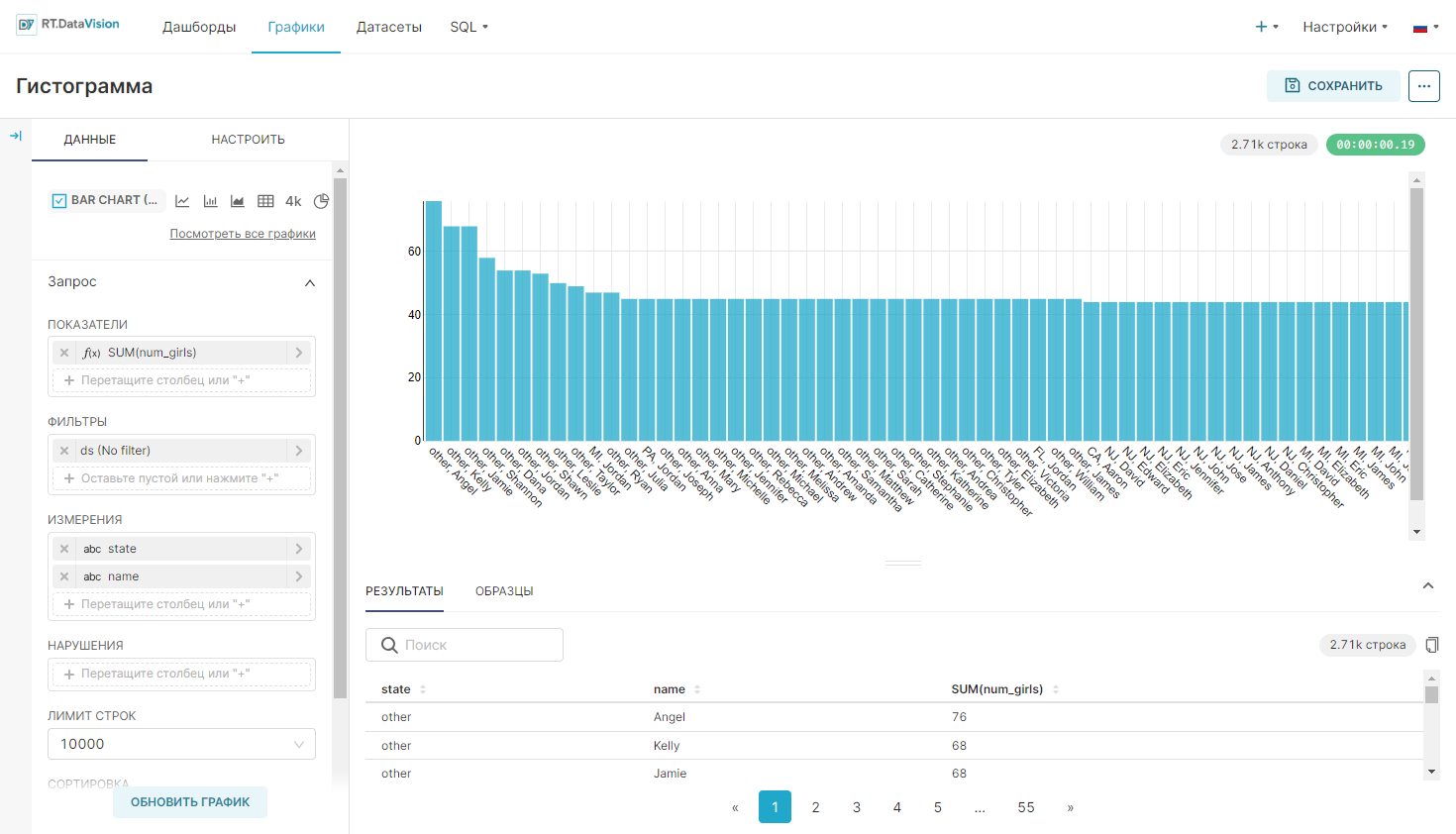
Значения, используемые для создания такого графика:
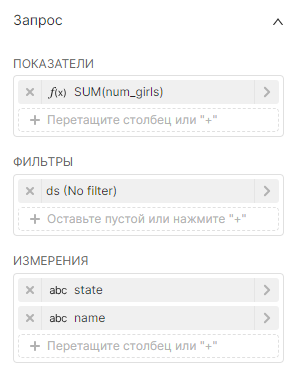 |
Параметры в Исследовать (Explore):
|
|
Сгенерированный SQL-запрос:
|
¶ 5.2.2.2. Измерения и разбивка
Использование двух измерений, приведённых выше, дает огромное количество отдельных столбцов гистограммы, которые трудно как показать, так и интерпретировать. Вместо этого можно раскрасить сегменты каждого такого столбца, используя функцию Нарушения (Breakdowns). Она повторно использует столбец измерения для разбивки существующих столбцов вместо создания новых. Пример графика:
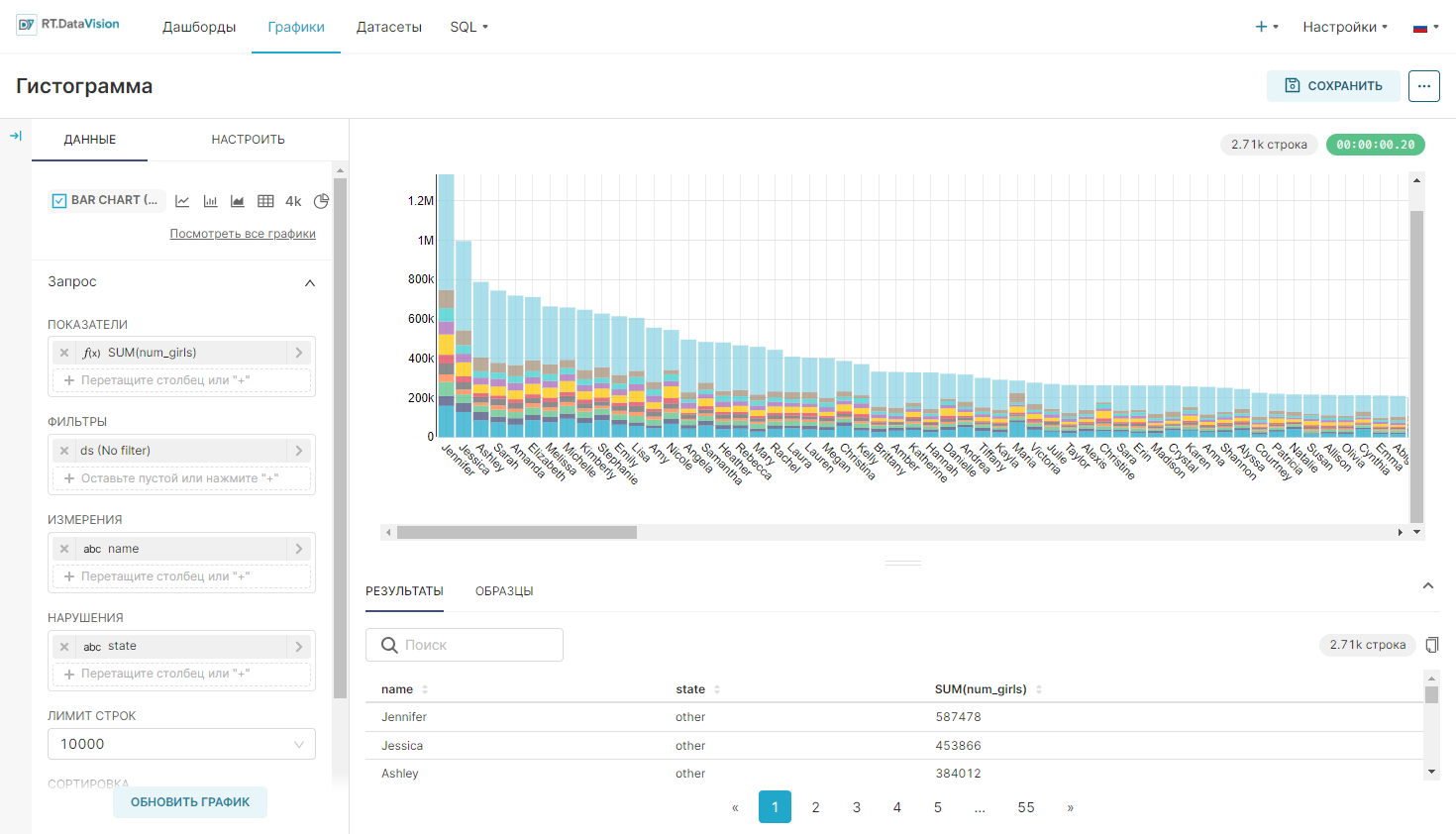
Для формирования такого графика необходимо переместить столбец state из раздела Измерения (Dimensions) в раздел Нарушения (Breakdowns) и установить флажок в поле Уложенные батончики (Stacked Bars) на вкладке Настроить (Customize). Окончательный сгенерированный SQL-запрос такой же, но этот график теперь располагается более компактно.
¶ 5.2.3. Настройка гистограммы
Можно дополнительно визуально адаптировать график, используя следующие параметры на вкладке Настроить (Customize):
- Цветовая схема (Color scheme) — регулирует цветовую схему, которая будет использоваться для гистограммы;
- Легенда (Legend) — регулирует отображение легенды на графике для каждого измерения и цвета;
- Значения баров (Bar values) — регулирует отображение общего значения для каждого столбца гистограммы;
- Подробная всплывающая подсказка (Rich tooltip) — регулирует отображение всплывающей подсказки, которая возникает при наведении указателя мыши и содержит подробную информацию о данных. При снижении производительности рекомендуется её отключить;
- Уложенные батончики (Stacked Bars) — регулирует расположение уникальных групповых значений друг над другом в столбце Нарушения (Breakdowns);
- Сортировочные линейки (Sort bars) — регулирует сортировку столбцов гистограммы
- Формат оси Y (Y axis label) — описательное имя для метки оси Y;
- Формат оси X (X axis label) — описательное имя для метки оси X.
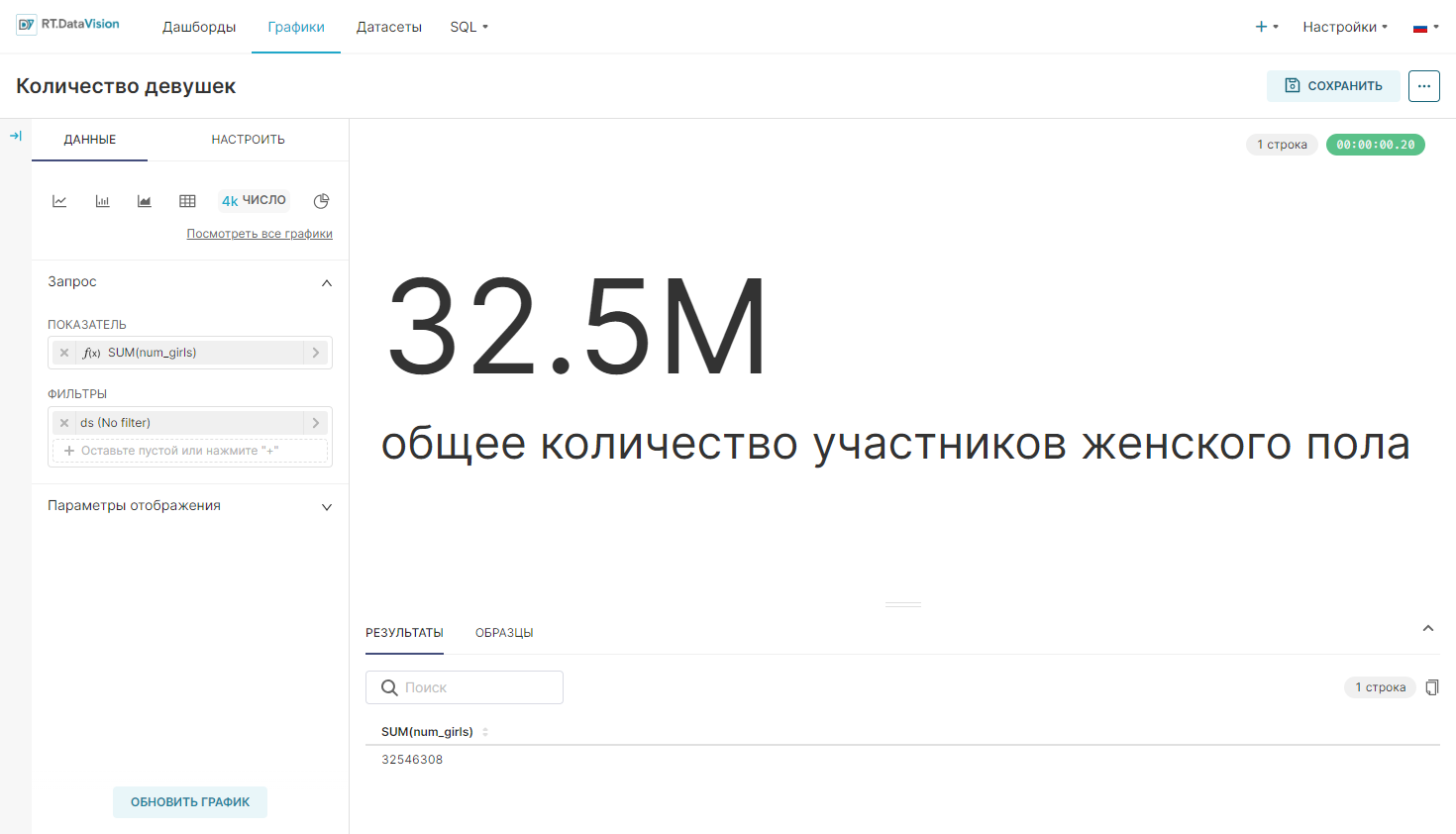
¶ 5.3. Число (Big Number)
Число (Big Number) позволяет выделить важную совокупную метрику или KPI (ключевой показатель эффективности). Число с линией тренда (Big Number with Trendline) поможет подчеркнуть недавнее состояние совокупной метрики и продемонстрировать линию тренда. Примеры графиков:
¶ 5.3.1. Создание графика Число (Big Number)
Для создания базового графика Число (Big Number), укажите следующие значения:
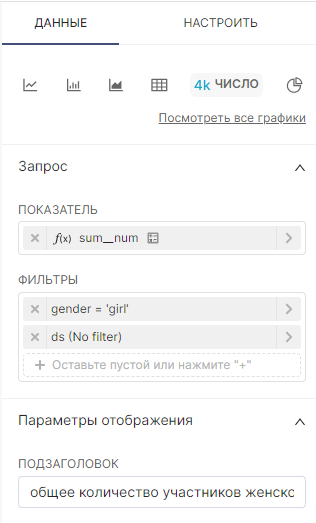 |
Показатель (Metric) (обязательно):
Фильтры (Filters) (опционально):
Подзаголовок (Subheader) (опционально):
|
|
Сгенерированный SQL-запрос |
Нажмите Создать График (Create Chart) или Обновить График (Update Chart), чтобы сгенерировать запросы, выполнить запросы и визуализировать результаты.
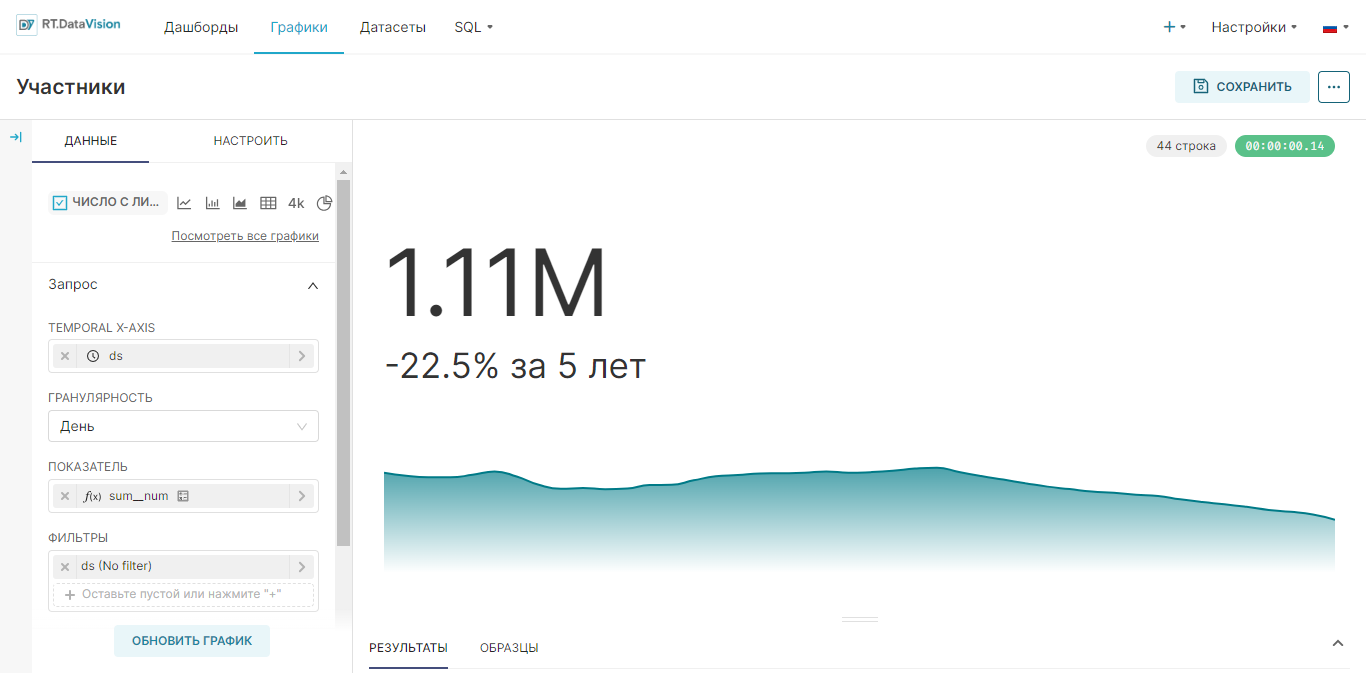
¶ 5.3.2. Создание графика Число с линией тренда (Big Number with Trendline)
Если необходимо акцентировать внимание на недавнем состояние агрегированной метрики и продемонстрировать линию тренда, то можно использовать график Число с линией тренда (Big Number with Trendline).
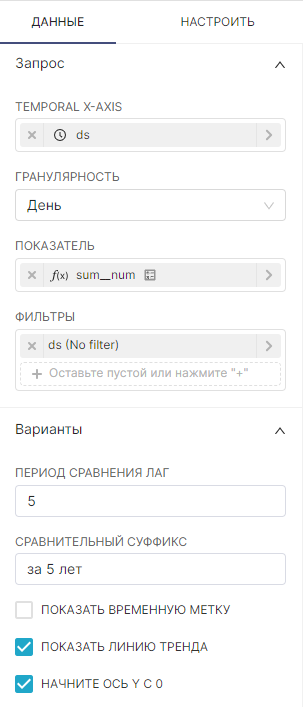 |
Гранулярность (Time range) (опционально):
Показатель (Metric) (обязательно):
Фильтры (Filters) (опционально):
Варианты (Options):
|
|
Сгенерированный SQL-запрос |
Нажмите Создать График (Create Chart) или Обновить График (Update Chart), чтобы сгенерировать запросы, выполнить запросы и визуализировать результаты.
¶ 5.4. Диаграмма воронка (Funnel Chart)
Диаграмма воронка (Funnel Chart) визуализирует этапы пайплайна. Воронкообразные графики чрезвычайно распространены в отделах продаж, маркетинга, продуктов и операций. Пример воронки продаж, визуализированный с помощью Диаграммы воронки (Funnel Chart):
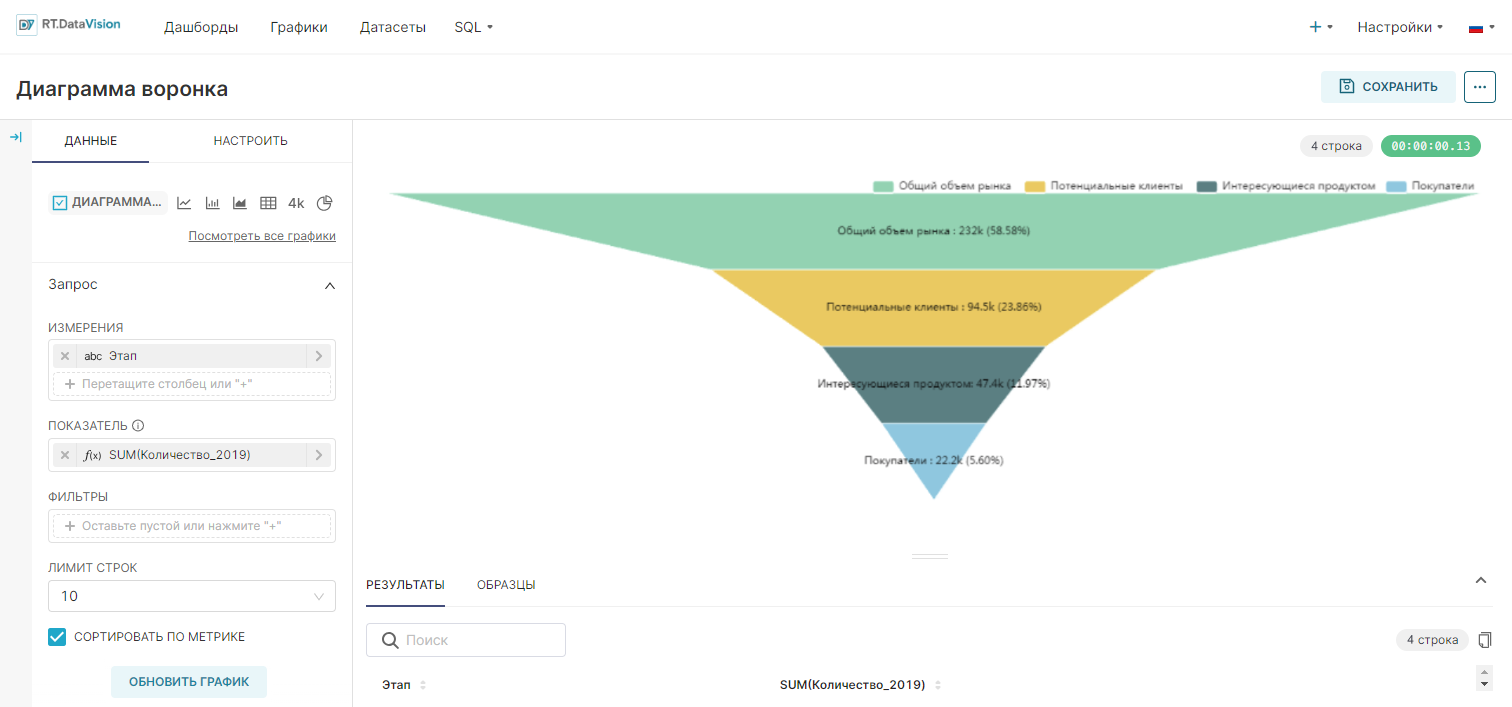
В этом разделе показано, как создать график Диаграмма воронка (Funnel Chart) из сырых неагрегированных данных и из агрегированных данных.
¶ 5.4.1. Создание диаграммы воронки
Для создания графика Диаграмма воронка (Funnel Chart), данные должны иметь следующую форму:
| Этап | Количество_2019 |
|---|---|
| Общий объём рынка | 232000 |
| Потенциальные клиенты | 94480 |
| Интересующиеся продуктом | 47390 |
| Покупатели | 22181 |
¶ 5.4.1.1. Диаграмма воронка из неагрегированных данных
Если данные не агрегированы, то укажите соответствующий столбец и то, как необходимо агрегировать значения в этом столбце.
Вид данных до агрегации:
| Этап | Идентификатор_пользователя |
|---|---|
| Общий объём рынка | Пользователь_2015 |
| Общий объём рынка | Пользователь_0913 |
| Потенциальные клиенты | Пользователь_2015 |
| Интересующиеся продуктом | Пользователь_1483 |
| Интересующиеся продуктом | Пользователь_2015 |
| Покупатели | Пользователь_2015 |
| Общий объём рынка | Пользователь_1483 |
| Потенциальные клиенты | Пользователь_0913 |
| Интересующиеся продуктом | Пользователь_1737 |
| … | … |
Вид данных после агрегации сырых данных:
| Этап | Количество_2019 |
|---|---|
| Общий объём рынка | 232000 |
| Потенциальные клиенты | 94480 |
| Интересующиеся продуктом | 47390 |
| Покупатели | 22181 |
Значения, используемые для создания такого графика:
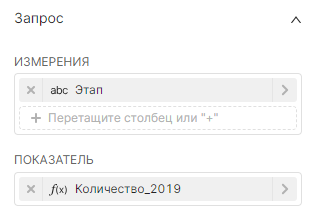 |
Измерения (Dimensions):
Показатель (Metric):
|
|
Сгенерированный SQL-запрос |
¶ 5.4.1.2. Воронкообразный график из агрегированных данных
Если данные уже агрегированы по этапам, то можно выбрать агрегатную функцию, которая даёт идентичное значение для агрегированных значений (например, MIN, MAX или SUM).
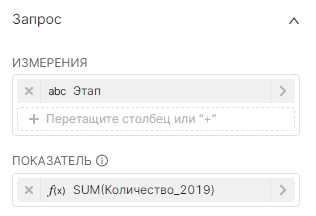 |
Измерения (Dimensions):
Показатели (Metric):
|
|
Сгенерированный SQL-запрос |
¶ 5.5. Калибровочная диаграмма (Gauge Chart)
Калибровочная диаграмма (Gauge Chart) использует интерфейс из научной и промышленной среды, чтобы продемонстрировать частичный прогресс в достижении определённого числа. Их также часто называют графиками спидометра (как приборные панели в автомобилях) или циферблатными графиками.
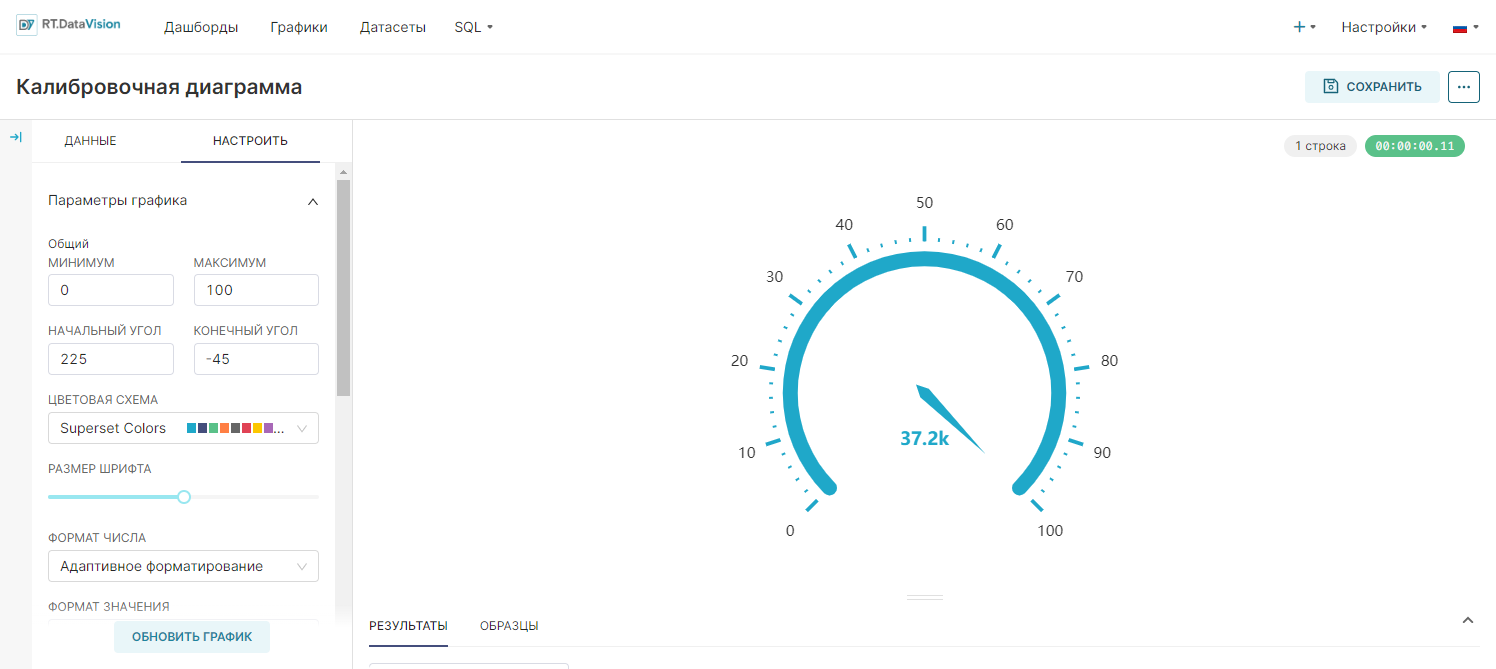
Калибровочная диаграмма (Gauge Chart) — это простые, лёгкие для понимания графики, которые визуализируют одно значение за раз. Они выделяются на панелях KPI (или стратегических) по сравнению со стандартным графиком Число (Big Number), где необходимо кратко сообщить о прогрессе в достижении цели или интересующего KPI (а не только саму метрику).
¶ 5.5.1. Создание графика шкалы
¶ 5.5.1.1. Простой график шкалы
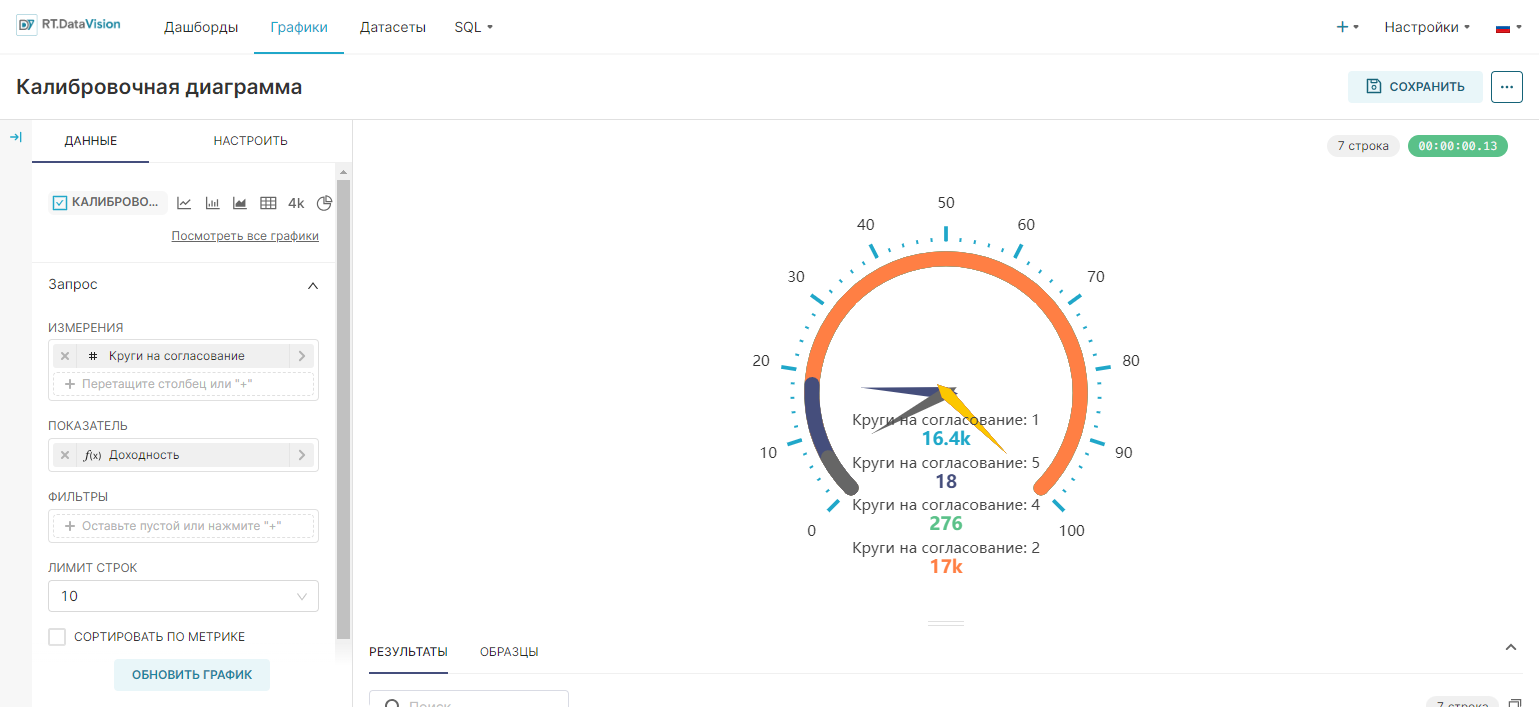
Для создания Калибровочной диаграммы (Gauge Chart) единственным обязательным полем для указания данных является поле Показатель (Metric), значением в котором и будет визуализировано. Чтобы сделать график более информативным, необходимо настроить цель, которая соответствует 100% шкалы.
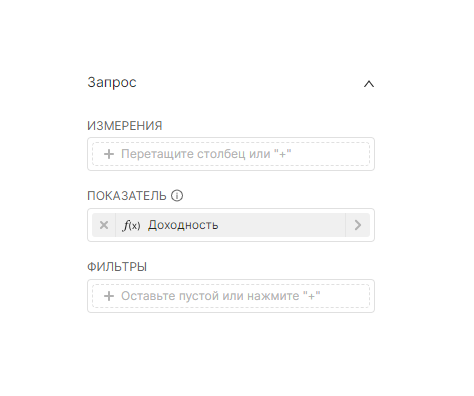 |
Вкладка Данные (Data) → Показатель (Metric):
|
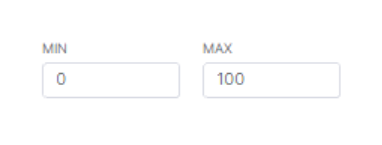 |
Вкладка Настроить (Customize) → Параметры графика (Chart Options) → Минимум (Min) и Максимум (Max):
|
В результате сформируется следующий график:
¶ 5.5.1.2. Калибровочная диаграмма с измерениями
В следующем примере разделяется тип сегмента.
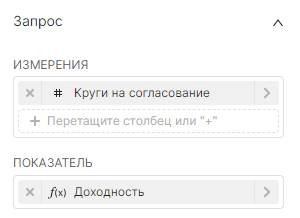 |
Измерения (Dimensions):
|
В результате сформируется следующий график:
¶ 5.5.1.3. Настройка графика шкалы
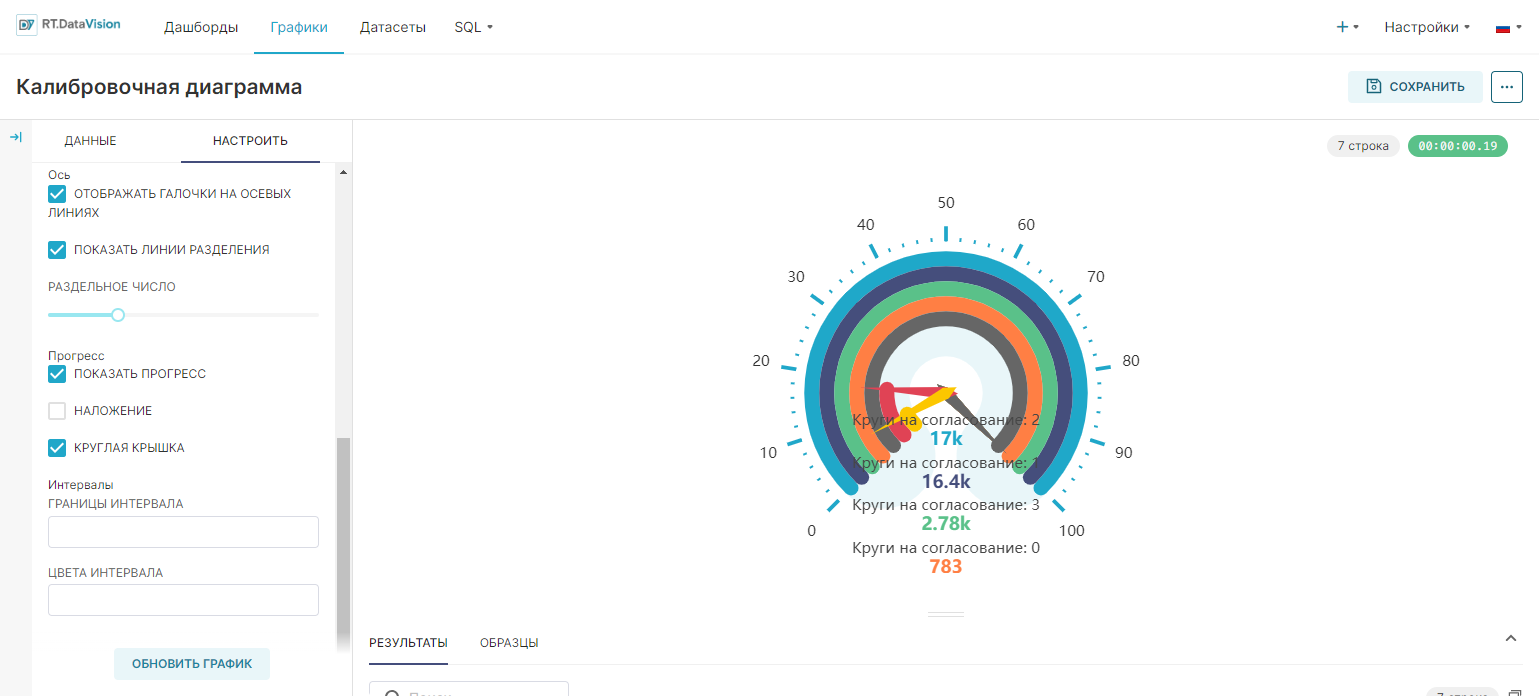
Панель Настроить (Customize) для графика предоставляет большое количество параметров для дальнейшего уточнения графика. Состоит из следующих основных полей:
- Общий (General):
- Минимум (Min) и Максимум (Max) — позволяет указать начальное и конечное значения графика;
- Начальный угол (Start Angle) и Конечный угол (End Angle) — регулирует наклон шкалы;
- Показать указатель (Show Pointer) — регулирует отображение циферблатов из центра (по умолчанию включено);
- Анимация (Animation) — регулирует отображение анимации при обновлении значений или отображении графика;
- Ось (Axis):
- Отображать галочки на осевых линиях (Show Axis Line Ticks) — регулирует отображение второстепенных разделительных линий вдоль шкалы;
- Показать линии разделения (Show Split Lines) — регулирует отображение основных линий разделения вдоль шкалы;
- Раздельное число (Split Number) — регулирует выбор количества разделений, используемых для линий разделения. Чем выше, тем чаще и меньше расстояние между разделителями;
- Прогресс (Progress):
- Показать прогресс (Show Progress) — регулирует отображение частичных индикаторов выполнения (по умолчанию включено). Рекомендуется оставить включённым;
- Круглая крышка (Round Cap) — регулирует закругление концов стержней (вместо прямоугольных);
- Наложение (Overlap) — регулирует складывание индикаторов выполнения уровня измерения вместе на одном индикаторе. Не рекомендуется использовать при наличии нескольких измерений.
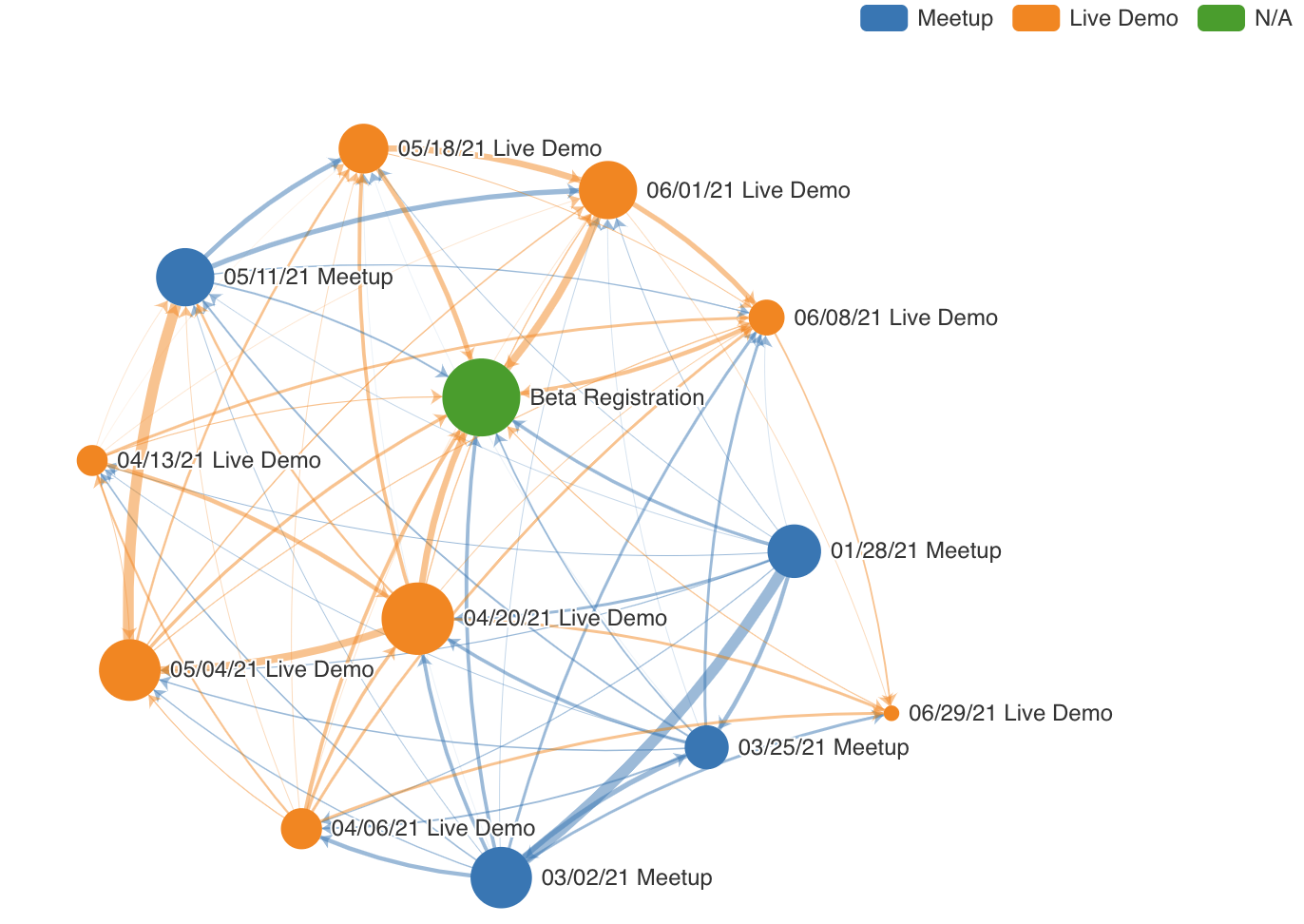
¶ 5.6. Графическая диаграмма (Graph Chart)
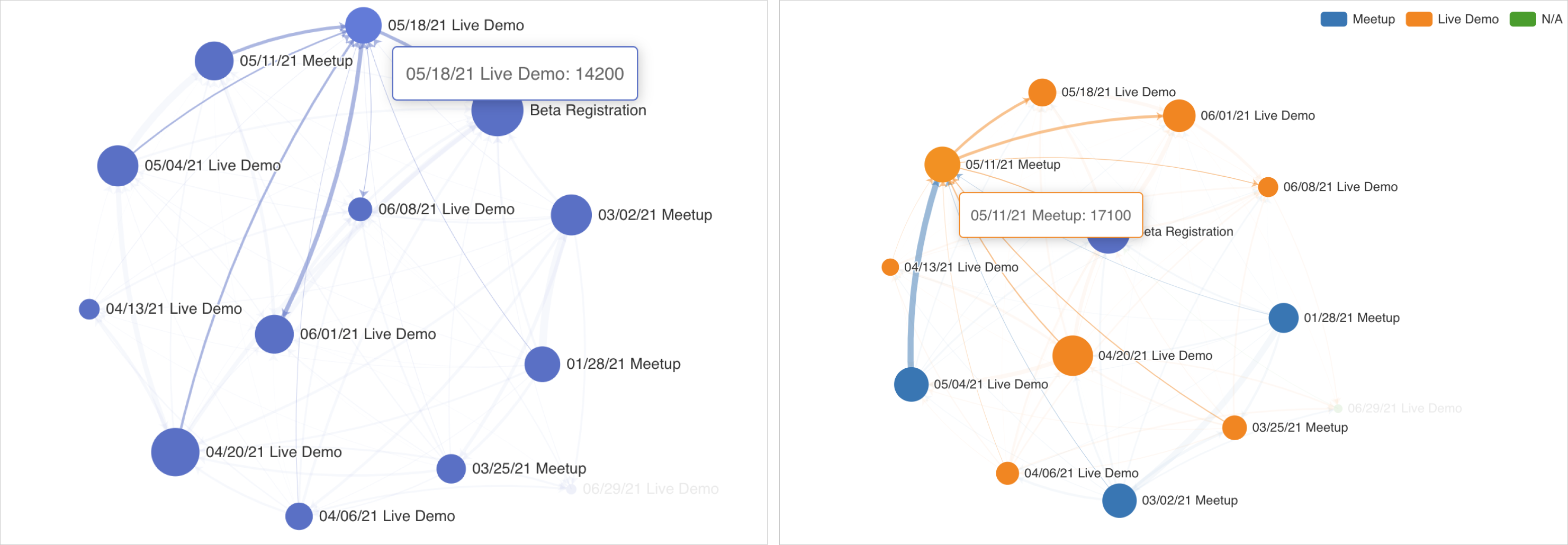
Графическая диаграмма (Graph Chart) позволяет визуализировать связи между категориями. Круги представляют отдельные категории или объекты, а линии, соединяющие круги, также называемые рёбрами, представляют связи между этими категориями. Примеры графиков:
¶ 5.6.1. Создание Графической диаграммы
¶ 5.6.1.1. Понимание формы данных
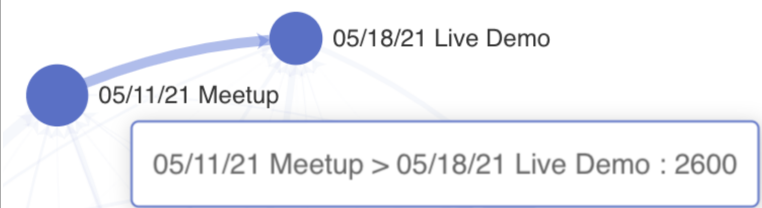
Для создания графической диаграммы важно понять как данные должны быть структурированы в используемой базе данных и то как эти данные будут преобразованы с помощью параметров, выбранных в Исследовать (Explore). Рассмотрим конкретный пример одной точки данных, которая определяет оба круга и линию, соединяющую их:
| Используемые данные | Результат | ||
 |
 |
||
Доступные значения для изменения формы данных в Исследовать (Explore):
 |
В Исследовать (Explore) необходимо выбрать следующие столбцы для применения:
Для каждого уникального значения группировки в столбцах Источник (Source) и Цель (Target), которые были выбрали:
|
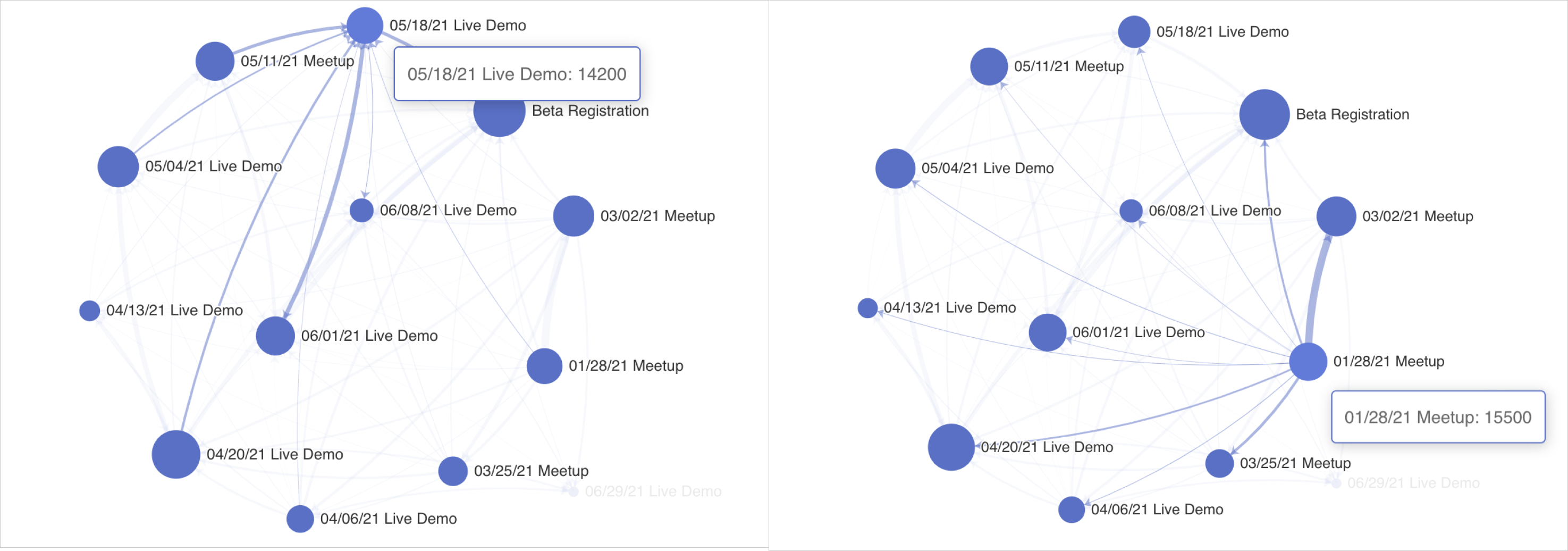
Размер каждого узла вычисляется путём суммирования всех значений метрик, связанных с рёбрами, указывающими на узел или исходящими из него. На графиках ниже показаны 2 узла и соответствующие им области:
¶ 5.6.1.2. Создание графической диаграммы из неагрегированных данных
Если используемые данные ещё не агрегированы по парным значениям в столбцах Источник (Source) и Цель (Target), то потребуется использовать параметр Показатель (Metric) в Исследовать (Explore) для агрегирования данных.
| Исходные данные |
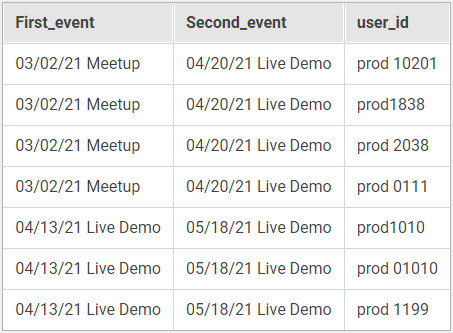 |
| Значения в Исследовать (Explore) |
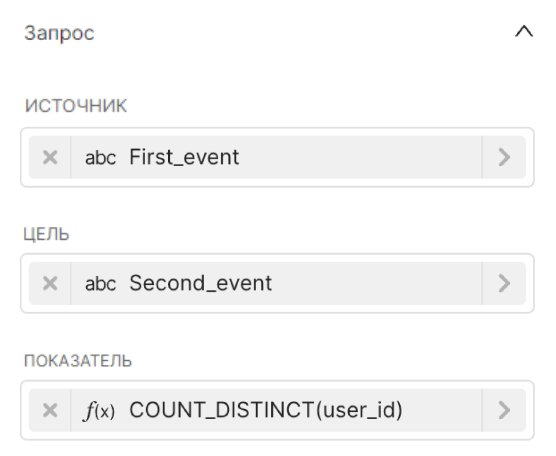 |
| Сгенерированный запрос |
|
| Финальные данные |
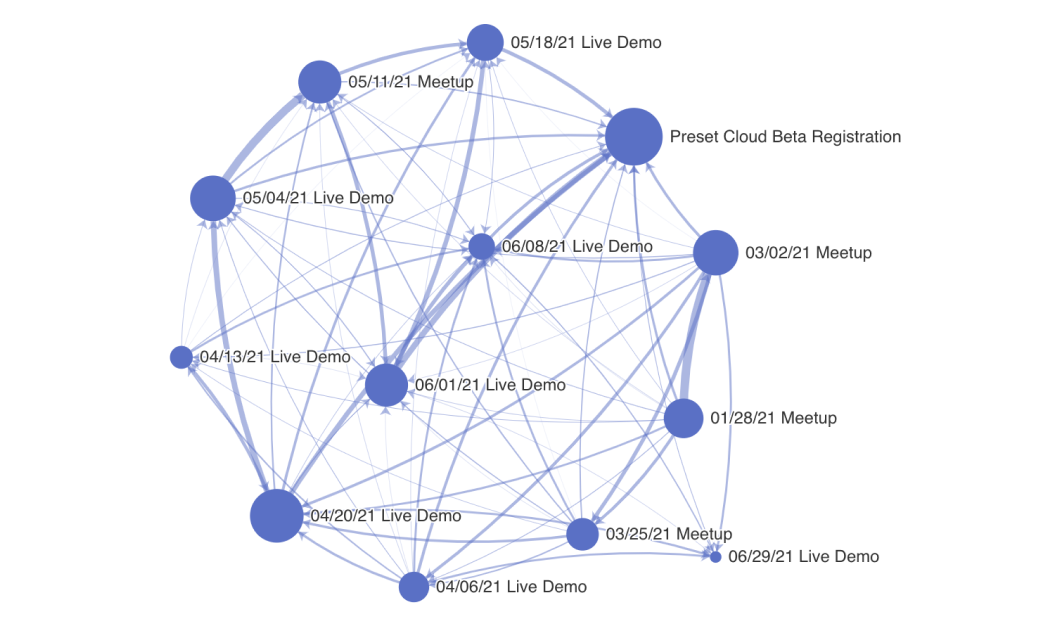 |
¶ 5.6.1.3. Создание графической диаграммы из предварительно агрегированных данных
Если данные уже агрегированы по парным значениям в столбцах Источник (Source) и Цель (Target), то необходимо выбрать агрегатную функцию, которая будет возвращать одно и то же значение (например, Минимум (Min) или Максимум (Max) — хороший выбор).
| Исходные данные |
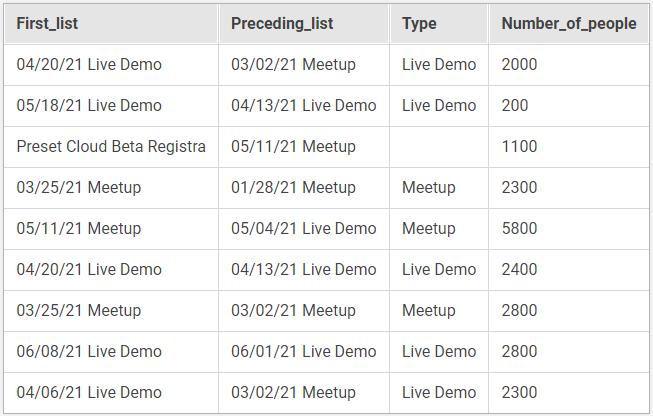 |
| Значения в Исследовать (Explore) |
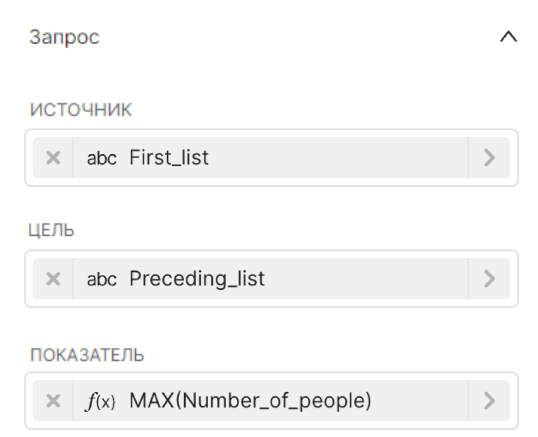 |
| Сгенерированный запрос |
|
| Финальные данные |
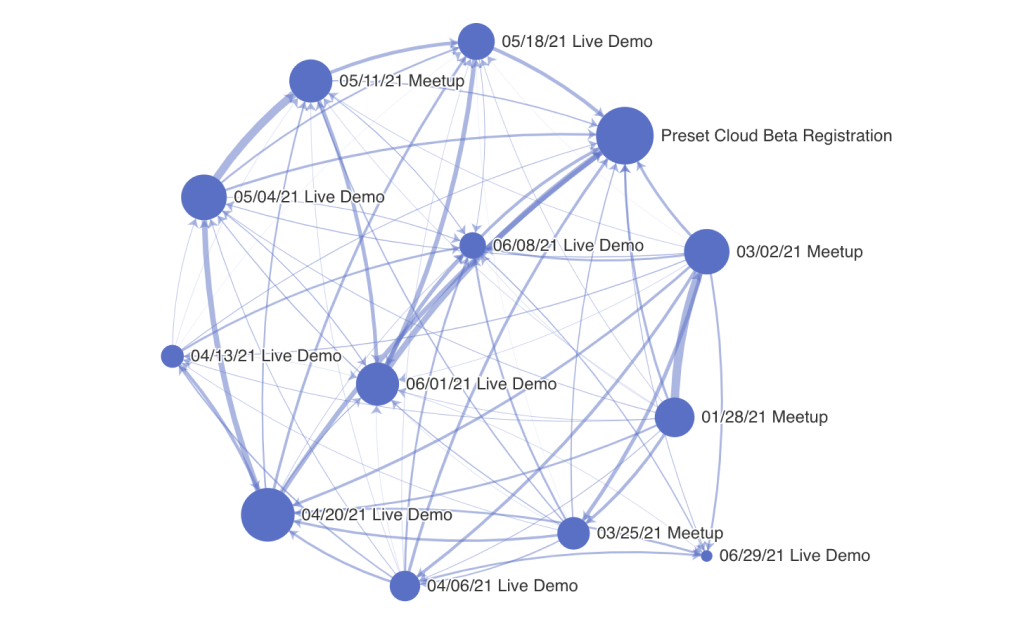 |
¶ 5.6.1.4. Создание графической диаграммы с измерениями
Чтобы добавить больше размерности графикам, необходимо дополнительно выбрать столбец, который будет использоваться для раскрашивания графа.
- Рекомендуется использовать параметры Категория источника (Source Category) или Целевая категория (Target Category) для наилучшего построения графа;
- Вне зависимости от выбора параметра, для генерации цветов будут использоваться уникальные значения в выбранном столбце;
- Для отсутствующих значений будет использоваться значение N/A.
¶ 5.6.2. Настройка графической диаграммы
Панель Настроить (Customize) для графической диаграммы предоставляет большое количество параметров для дальнейшего уточнения вашего графика.
1. Включение или отключение легенды.
- Показать легенду (Show Legend) — установите или снимите этот флажок, чтобы показать или скрыть легенду. Легенда используется только для отображения размеров, если они были выбраны, и цветов, которым они соответствуют;
- Тип (Type) — выберите тип отображения легенды;
- Ориентация (Orientation)— выберите расположение легенды;
- Маржа (Margin) — добавьте любые дополнительные отступы для легенды в пикселях.
2. Изменение цветовой схемы.
- Цветовая схема (Color Scheme) — измените цветовую палитру, используемую для окраски узлов и рёбер на графике.
3. Переключение на круговой граф.
- Расположение графиков (Graph layout) — переключение с графика Сила (Force) по умолчанию на график Циркуляр (Circular).
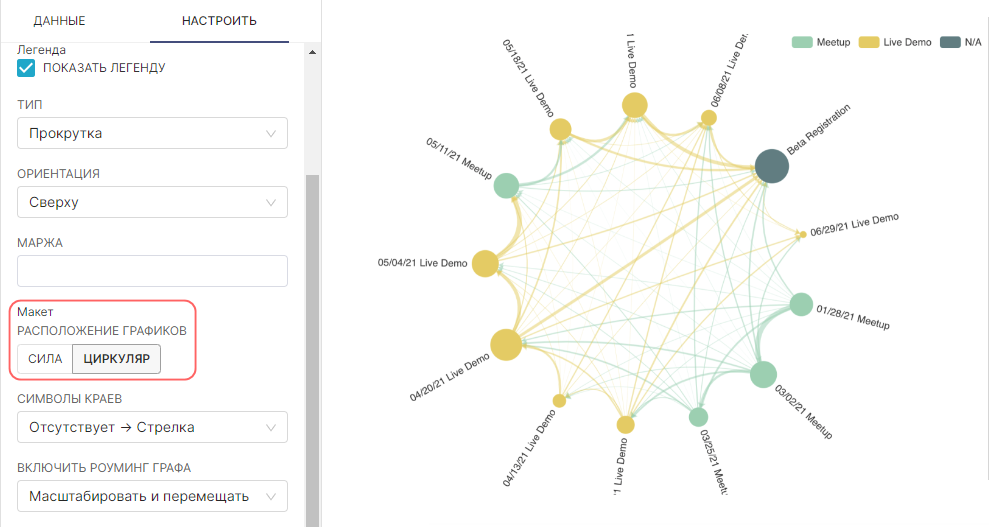
4. Изменение стиля рёбер.
- Символы краев (Edge Symbols) — измените способ представления концов рёбер или соединительных линий на графе с помощью раскрывающегося списка:
- Нет → Нет (None → None) — никаких стрелок, только простые линии;
- Отсутствует → Стрелка (None → Arrow) — стрелка только со стороны, касающейся столбца Цель (Target);
- Круг → Круг (Circle → circle) — круг на каждом конце;
- Круг → Стрелка (Circle → Arrow) — кружок на стороне Источник (Source), стрелка на стороне Цель (Target).
5. Настройка способа взаимодействия пользователей с графом.
- Включить роуминг графа (Enable Graph Roaming) — если при визуализации большого количество узлов и рёбер наблюдается замедление при масштабировании и перемещении, то рекомендуется отключить некоторые варианты поведения:
- Только перемещение (Move only) — пользователи графа могут щёлкать и перетаскивать представление графа, но не увеличивать или уменьшать масштаб;
- Только шкала (Scale only) — пользователи графа могут увеличивать или уменьшать масштаб, но не могут щёлкать и перетаскивать представление графа;
- Масштабировать и перемещать (Scale and Move) — пользователи графа могут как увеличивать или уменьшать масштаб, так и щёлкать и перетаскивать для перемещения по представлению графа;
- Отключен (Disabled) — фиксированный вид графа, без масштабирования или перемещения;
- Режим выбора узла (Node Select Mode) — изменение режима взаимодействия пользователей с узлами:
- Одиночный (Single) — включите щелчок и выбор отдельного узла;
- Множество (Multiple) — разрешите щёлкать и выбирать несколько узлов;
- Отключен (Disabled) — отключите все щелчки и выбор узлов;
- Порог метки (Label Threshold) — метки отображаются только в том случае, если вычисленное значение метрики превышает значение, указанное здесь;
- Размер узла (Node Size) — средний размер узла, самый большой узел будет в 4 раза больше, чем самый маленький;
- Ширина края (Edge Width) — средняя ширина ребра, самое толстое ребро будет в 4 раза толще самого тонкого;
- Длина кромки (Edge length) — установите длину рёбер между узлами, передвигая ползунок;
- Гравитация (Gravity) — установите силу стягивания графа к центру;
- Отталкивание (Repulsion) — установите силу отталкивания узлов друг от друга;
- Трение (Friction) — установите силу трения узлов.
¶ 5.7. График смешанных временных рядов (Mixed Chart)
График смешанных временных рядов (Mixed Chart) позволяет объединить два разных графика временных рядов в одной области графика, используя общую временную ось X (или временной столбец). Примеры графиков:
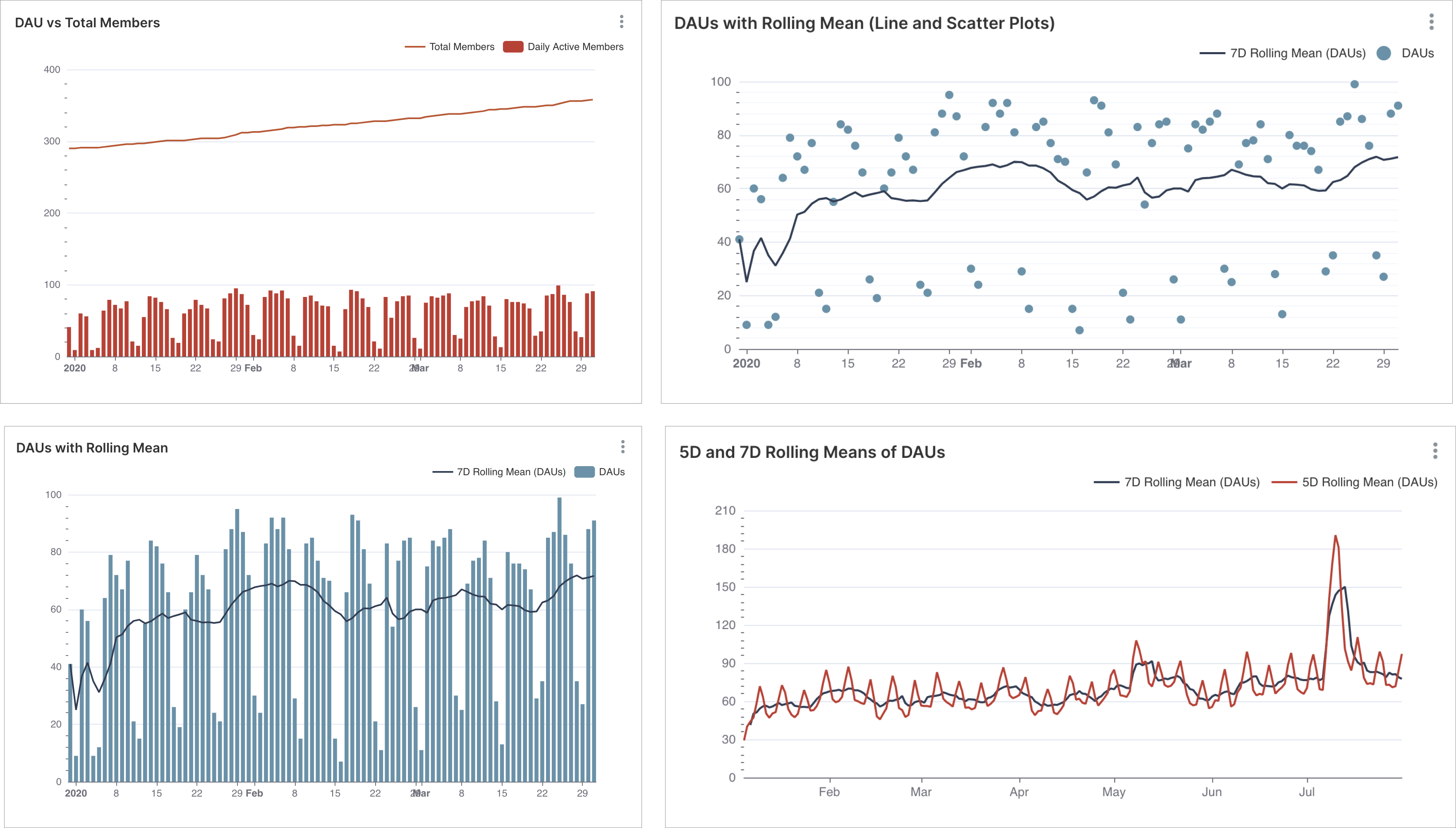
¶ 5.7.1. Варианты комбинирования графиков временных рядов
Визуализация смешанных временных рядов позволяет накладывать графики на одни и те же оси, что полезно для улучшения некоторых конкретных типов сравнения, которые были бы сложными для отдельных графиков. Ранее приходилось создавать несколько графиков временных рядов и размещать их рядом друг с другом, чтобы пользователь мог сравнить их.
Например, визуализируя растущее сообщество необходимо понять, какая доля сообщества регулярно вовлекается. Нужно понять ритмы ежедневных активных пользователей (daily active users, DAUs) и еженедельных активных пользователей (weekly active users, WAUs) по отношению к общему количеству пользователей.
Если размещать на дашборде отдельные графики временных рядов, то обнаружатся следующие недостатки:
- не рекомендуется сравнивать значения между DAUs и общим количеством пользователей, так как это будет выглядеть невероятно громоздко;
- диапазоны по оси Y по умолчанию соответствуют диапазонам, характерным для каждого столбца, поэтому нужно выполнить дополнительную настройку в Исследовать (Explore), чтобы диапазоны совпадали.
Используя график смешанных временных рядов в RT.DataVision, можно объединить оба графика и построить их в одной области графика:
- Линейный график текущего количества пользователей в сообществе;
- Гистограмма для ежедневных активных пользователей в сообществе.
Этот смешанных график имеет несколько ключевых преимуществ:
- сравнение ежедневных значений с общим количеством пользователей рекомендуется из-за общей оси и графика;
- коэффициенты масштабирования по оси Y в диапазонах обоих графиков и расширены для размещения обоих диапазонов данных;
- общая область графика использует меньше горизонтального пространства, что позволяет нам расширить диапазон дат с 1 месяца до 3 месяцев данных без потери точности сравнения.
¶ 5.7.1.1. Сравнение каунта со скользящим средним
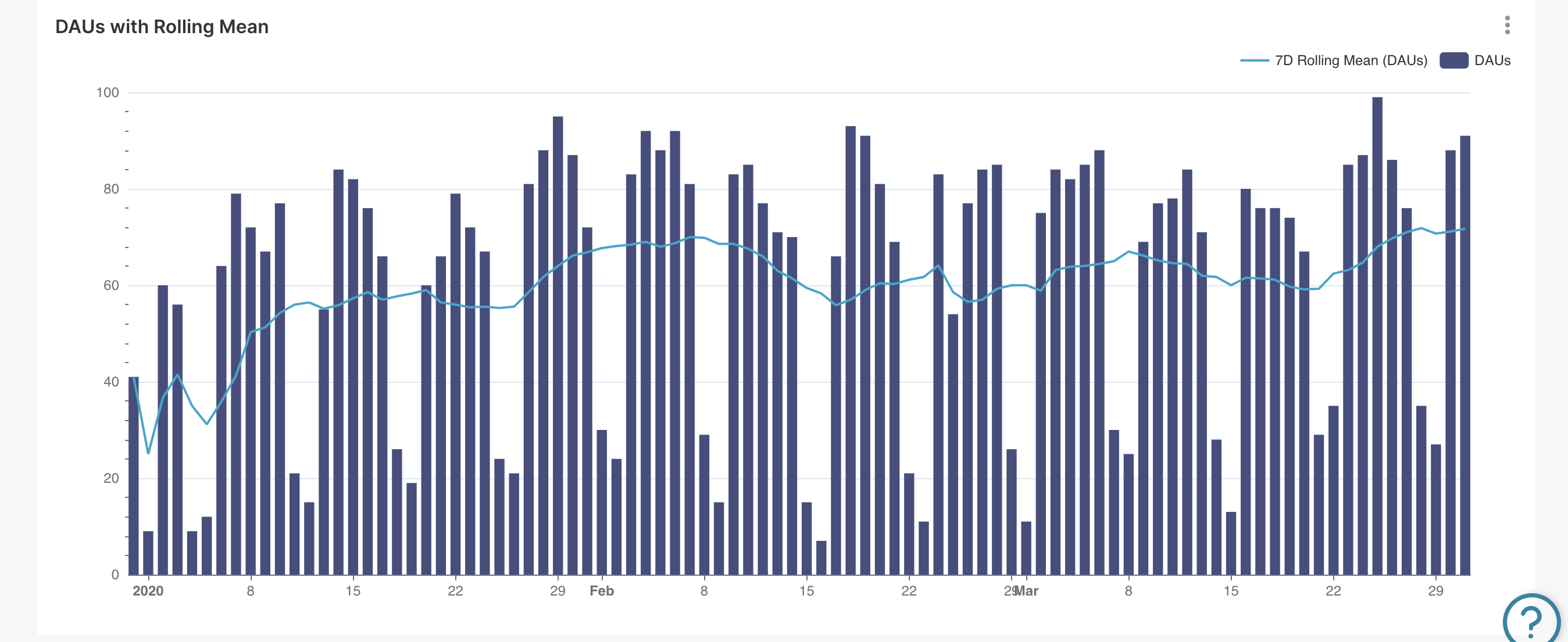
Сочетание гистограммы DAU с линейным графиком Общее количество участников помогает понять долю пользователей, которые ежедневно вовлечены. Для отображения тенденции DAU на самом деле можно применить скользящее среднее для стабилизации данных в плавный линейный график.
¶ 5.7.1.1.1. Сочетание линейного графика и гистограммы
Важно сохранять ежедневный контекст, чтобы была возможность заранее понять (раньше, чем период скользящего среднего), если вмешательство, которое потенциально имело влияние. Кроме того, всегда интересно понять недельные ритмы (спады в выходные, всплески в будние дни) и то, как они могут меняться со временем.
Можно объединить эти потребности, создав график смешанных временных рядов с:
- линейным графиком, отображающаим 7-дневное скользящее среднее число активных пользователей в день;
- гистограмму, отображающая ежедневных активных пользователей.
Пример графика в действии как комбинация, использующая один датасет и временной интервал:
¶ 5.7.1.1.2. Сочетание линейного графика и точечного графика
При необходимости сделать ещё один шаг вперёд и выделить 7-дневное скользящее среднее по ежедневным каунтам активных пользователей, один из вариантов — заменить гистограмму DAU на точечный график. Пример графика:
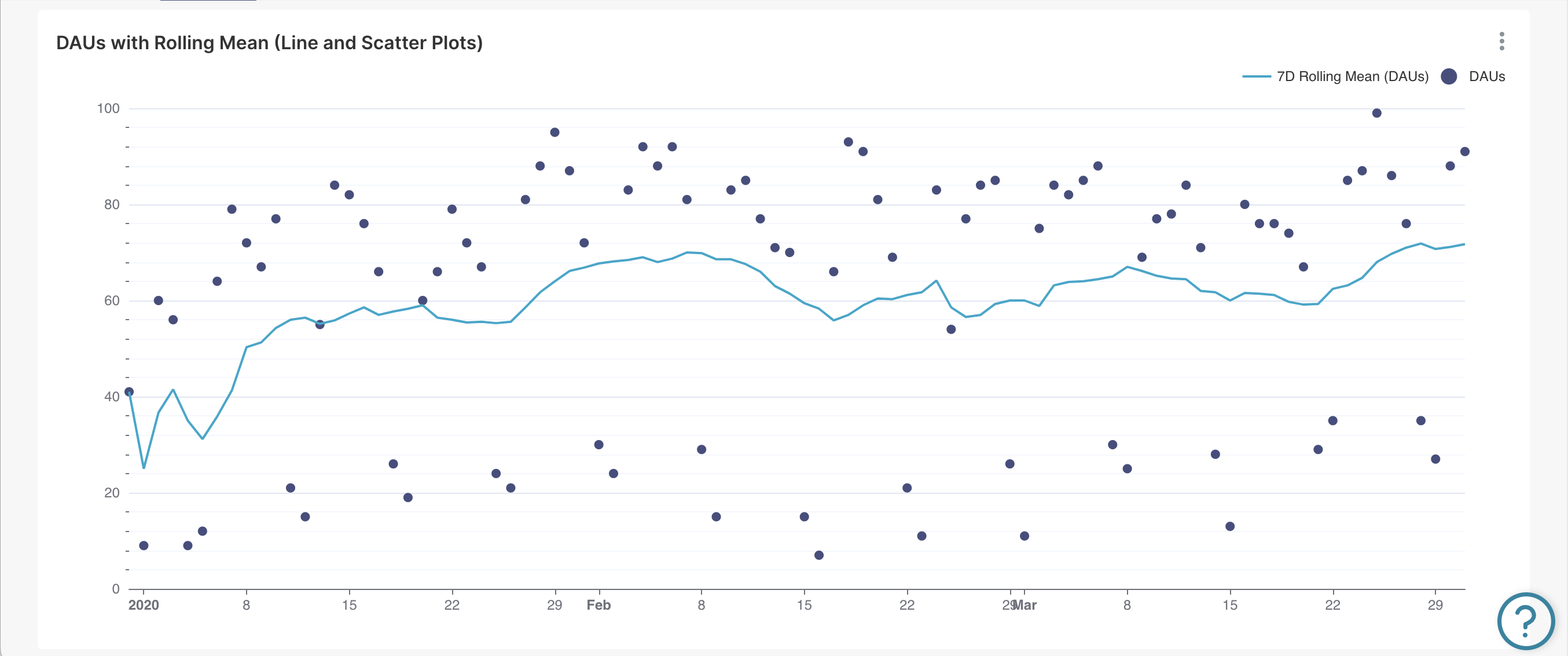
Это сохраняет способность искать конкретные значения DAU для определённых дней, но в то же время исключает способность легко сравнивать дни (или даже группы ближайших дней).
¶ 5.7.1.2. Сравнение скользящих окон
В настоящее время смешанные графики временных рядов в RT.DataVision позволяют объединять два графика, если они имеют одинаковый временной диапазон и временной интервал. Однако можно изменить скользящее окно, применяемое к каждому графику.
Это открывает возможность строить два графика скользящей суммы в одной области графика. На следующем графике нанесено 5-дневное и 7-дневное скользящее среднее в виде графика смешанного временного ряда.
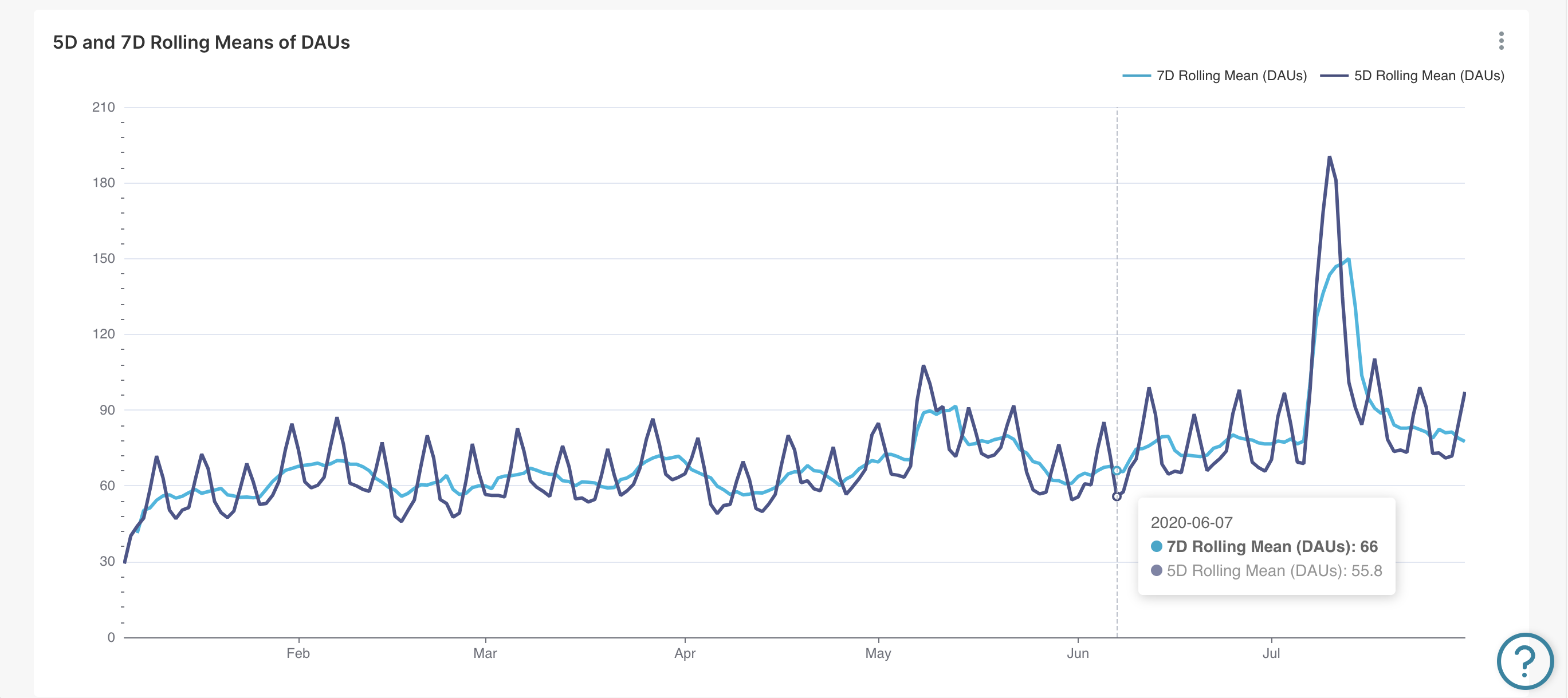
Сохраняются провалы выходных, которые демонстрировала дневная гистограмма.
¶ 5.7.1.2.1. Скрытие графика
Для некоторых пользователей этот график может быть непонятен, потому что сравнение 5-дневных и 7-дневных скользящих средних требует либо предварительного знакомства с этим типом графика, либо более глубокого самоанализа и исследования.
Если включить легенду на графике смешанного временного ряда (или на самом деле на большинстве графиков в RT.DataVision), то пользователь может скрыть график, просто щёлкнув его имя в легенде.
¶ 5.7.2. Как работают графики смешанных временных рядов в RT.DataVision
¶ 5.7.2.1. Запрос
График смешанных временных рядов в RT.DataVision работает путём создания и выполнения двух отдельных SQL-запросов и использования общего диапазона даты и времени и временного интервала для объединения данных для визуализации.
Пример запросов, сгенерированных для графика:
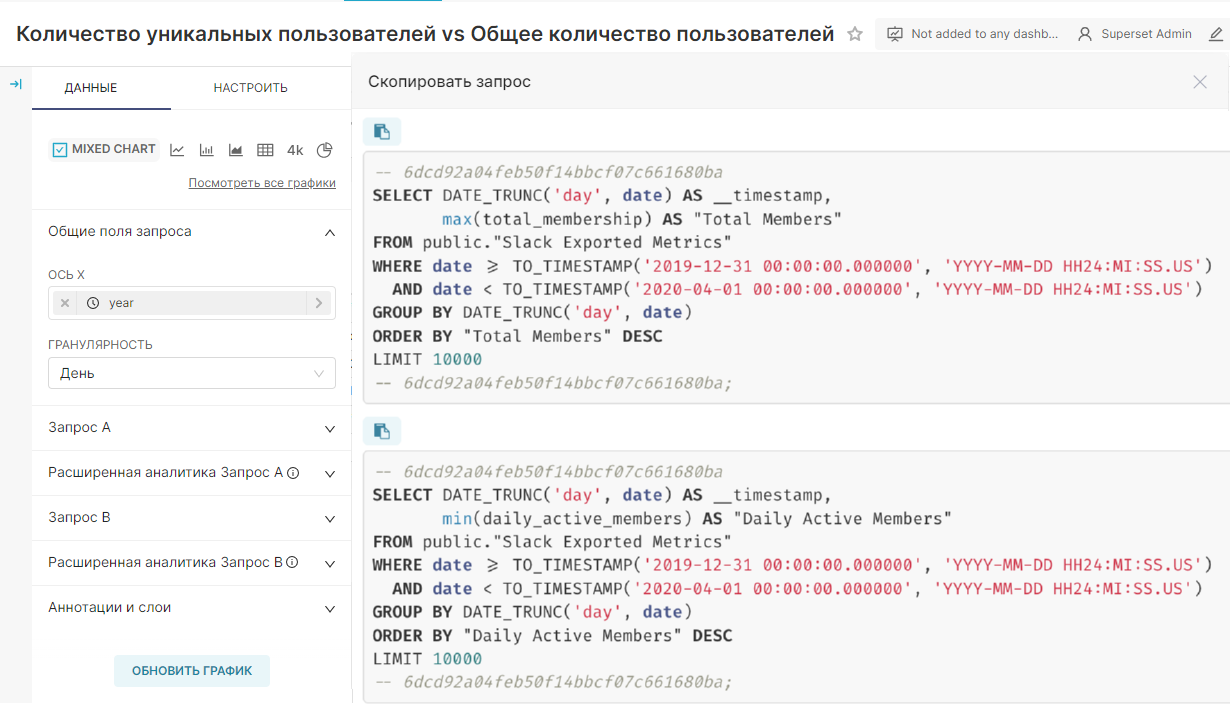
Чтобы выбрать метрики, фильтры и т.д. для каждого запроса, разверните Запрос А (Query A) и Запрос В (Query B) на панели слева.
¶ 5.7.2.2. Время
В настоящее время графики смешанных временных рядов в RT.DataVision должны иметь одинаковый временной диапазон и интервал. На скриншоте выше раздел Общие поля запроса (Shared query fields) находится вверху перед разделами Запрос А (Query A) и Запрос В (Query B), чтобы указать, что эти настройки являются общими для обоих запросов.
¶ 5.7.3. Создание графика смешанных временных рядов
Чтобы создать простой график смешанных временных рядов необходимо определить:
- Общую временную ось X для обеих визуализаций;
- Атрибуты для первой визуализации временных рядов (запрос A);
- Атрибуты для второй визуализации временных рядов (запрос B).
Все они определены на вкладке Данные (Data) в разделе Исследовать (Explore).
 |
Общие поля запроса (Shared query fields):
|
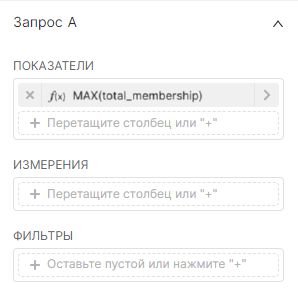 |
Первая визуализация временных рядов Запрос А (Query A):
|
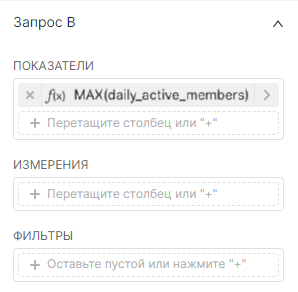 |
Вторая визуализация временных рядов Запрос В (Query B):
|
Нажмите Создать график (Create Chart) или Обновить график (Update Chart), чтобы сгенерировать запросы, выполнить запросы и визуализировать результаты.
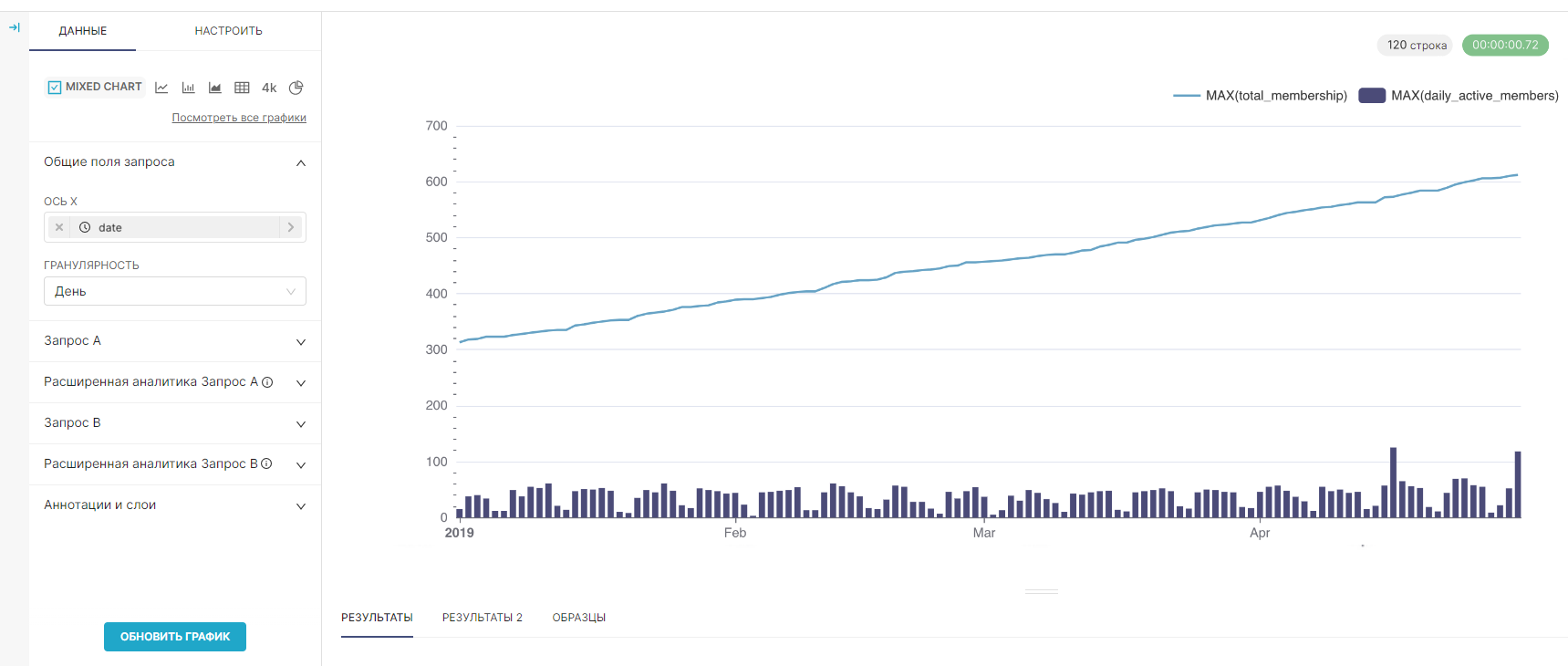
¶ 5.7.4. Понимание запросов и результатов
График смешанных временных рядов (Mixed Chart) уникален, потому что RT.DataVision генерирует два разных SQL-запроса и выравнивает результаты по общей оси X.
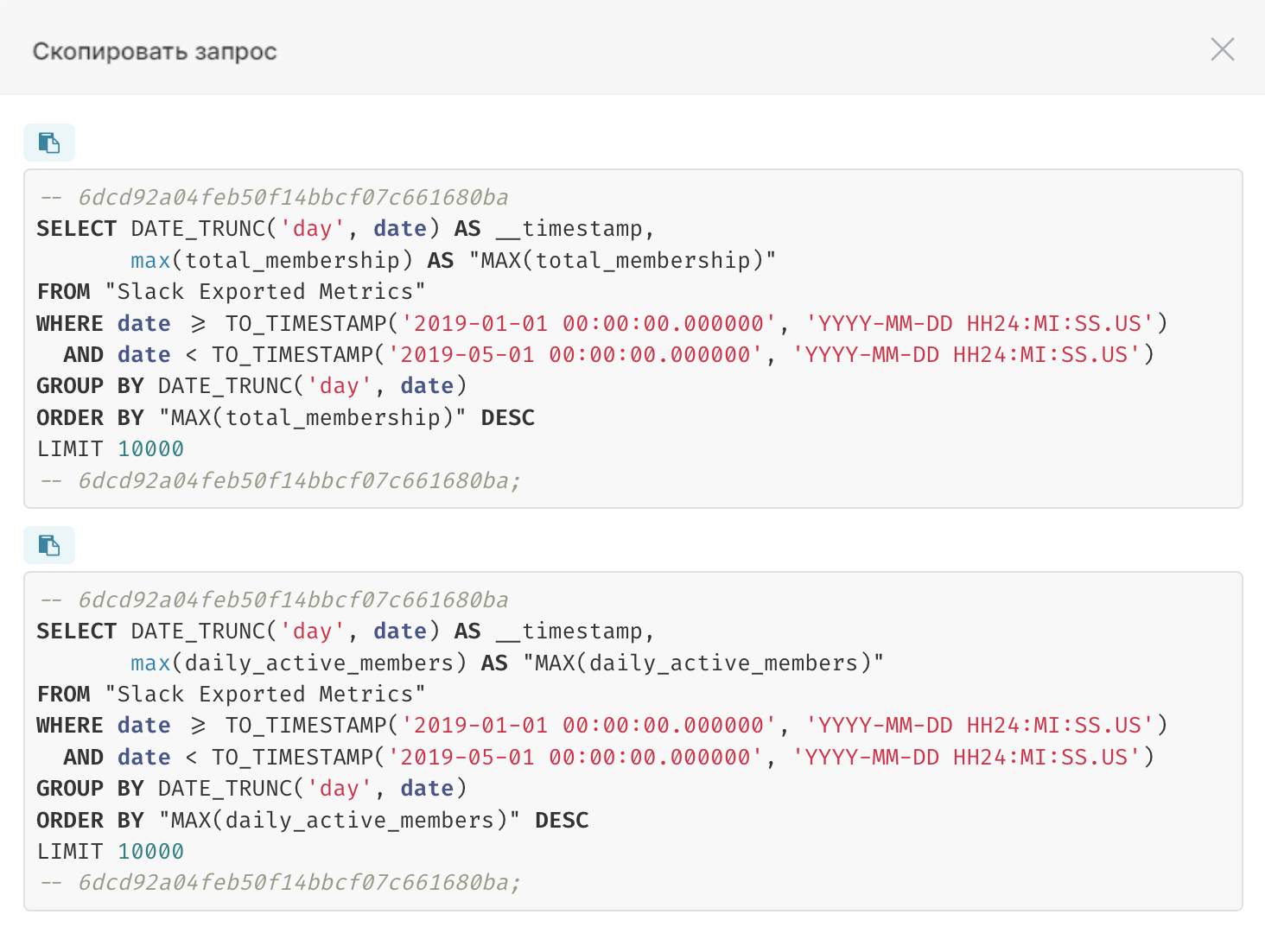 |
Просмотр обоих запросов: Нажмите кнопку [...] в правом верхнем углу интерфейса Исследовать (Explore), и нажмите Скопировать запрос (View Query) на любом графике, чтобы просмотреть сгенерированные запросы.
|
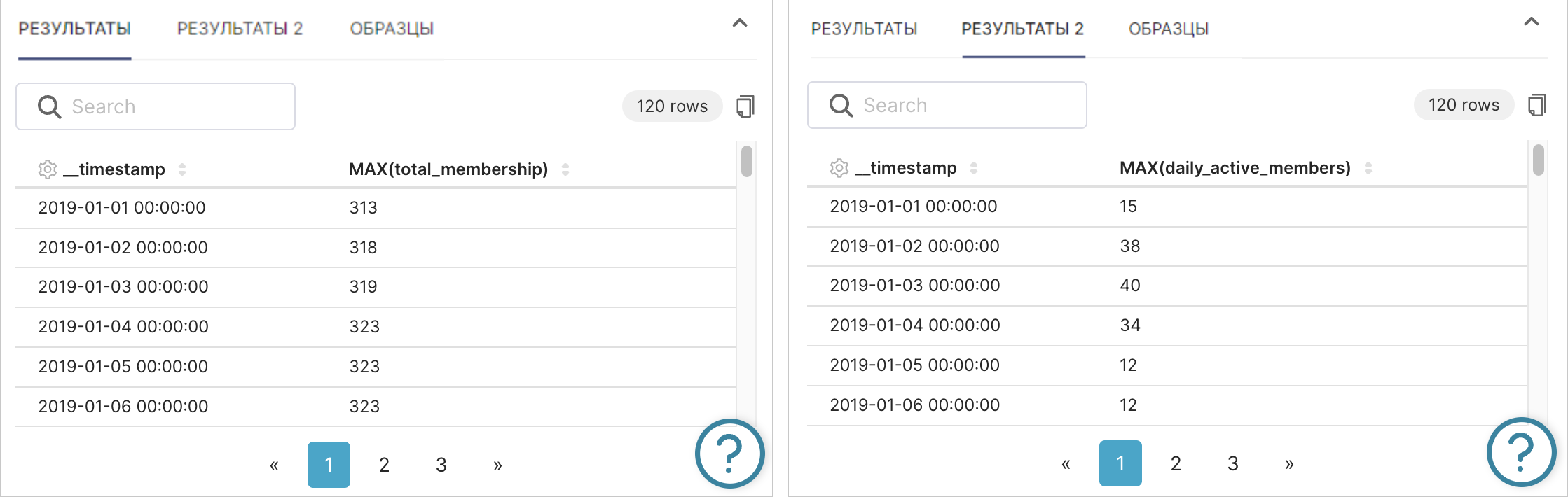 |
Просмотр обоих наборов результатов: Под отображаемым графиком есть две вкладки Результаты (Results), соответствующие результатам обоих запросов.
|
¶ 5.7.5. Расширенная аналитика
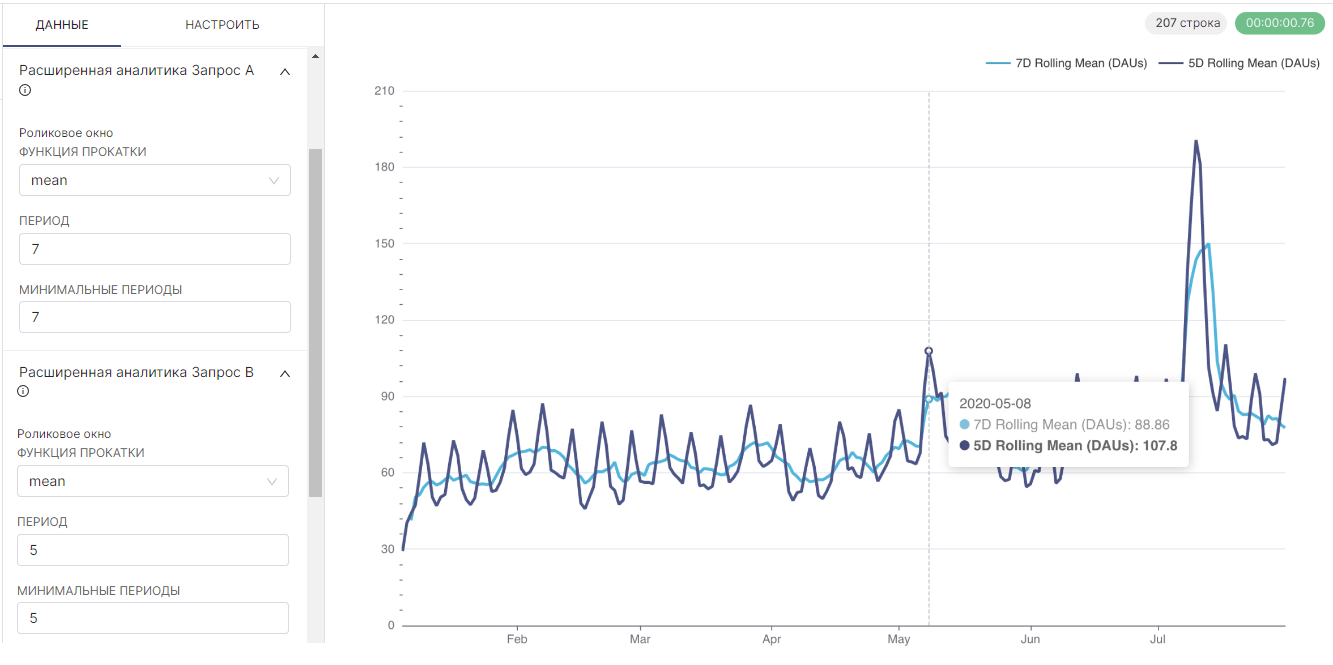
Как и в большинстве визуализаций временных рядов в RT.DataVision, диаграмма смешанных временных рядов поддерживает функцию Расширенная аналитика (Advanced Analytics).
Поскольку графики смешанных временных рядов объединяют два запроса, результата и графика, эти параметры можно применять на уровне отдельных графиков. В следующем примере применяется 7-дневное скользящее среднее к одному линейному графику и 5-дневное скользящее среднее к другому линейному графику.
¶ 5.7.6. Настройка графика
На вкладке Настроить (Customize) представлен ряд параметров для настройки внешнего вида этого графика.
- Раздел Ось Х (X Axis) — настройка имени и нижнего поля в пикселях для общей оси X.
- Раздел Ось Y (Y Axis) — настройка имени, поля и положения оси Y.
- Цветовая схема (Color Scheme) — выбор диапазона цветов, используемых для визуализации.
- Разделы Запрос А (Query A) и Запрос В (Query B) — все параметры настройки для каждого графика:
- Тип серии (Series Type) — выбор типа графика: Линия (Line), Разброс (Scatter), Плавне линии (Smooth Line), Полоса (Bar) или Шаг (Step);
- Флажок Сложить бары (Stack Series) — если на графике есть несколько временных рядов, установка этого флажка будет складывать ряды (полезно для складывания гистограмм);
- Флажок Диаграмма области (Area Chart) и ползунок Непрозрачность (Opacity) — затените область под линейным графиком, если флажок установлен, и используйте ползунок Непрозрачность (Opacity), чтобы указать степень непрозрачности;
- Флажок Показать значения (Show Values) — при установке этого флажка каждая точка данных будет отображаться в виде числа для этого графика;
- Маркер (Marker) и Размер маркера (Marker Size) — для линейных графиков можно включить маркеры (или круги) для точек данных и использовать ползунок для выбора размера;
- Ось Y (Y Axis) — имеет два значения диапазонов (вы можете включить два разных диапазона оси Y, установив разные значения для графиков):
- Первичный (Primary) — расчётная ось Y этого графика будет находиться слева;
- Вторичный (Secondary) — расчётная ось Y этого графика будет находиться справа;
- Легенда (Legend):
- Флажок Показать легенду (Show Legend) — если он установлен, каждая метрика будет отображаться в легенде;
- Тип (Type) — если установлено значение Прокрутка (Scroll), легенда будет отображать только несколько показателей за раз и скрывать остальные. Если установлено значение Простой (Plain), легенда попытается отобразить все метрики;
- Ориентация (Orientation) — расположение легенды по отношению к области графика (Сверху (Top), Снизу (Bottom), Слева (Left) или Справа (Right));
- Маржа (Margin) — дополнительный пробел между легендой и областью графика (в пикселях);
- Ось Х (X Axis):
- Формат времени (Time Format) — выберите формат для меток оси X или по умолчанию выберите Adaptive Formatting, чтобы позволить инструменту принять решение;
- Поворот метки оси Х (Rotate Axis Label) — при необходимости поверните метку оси X;
- Всплывающая подсказка (Tooltip):
- Флажок Насыщенная всплывающая подсказка (Rich Tooltip) — если установлен флажок, отображаются все значения метрики/серии при наведении указателя мыши по времени (ось X);
- Флажок Сортировка по метрике во всплывающей подсказке (Tooltip Sort by Metric) — если флажок установлен, всплывающая подсказка сортируется по выбранной метрике в порядке убывания.
¶ 5.7.7. Создание простого графика смешанных временных рядов (гистограмма и линейный график)
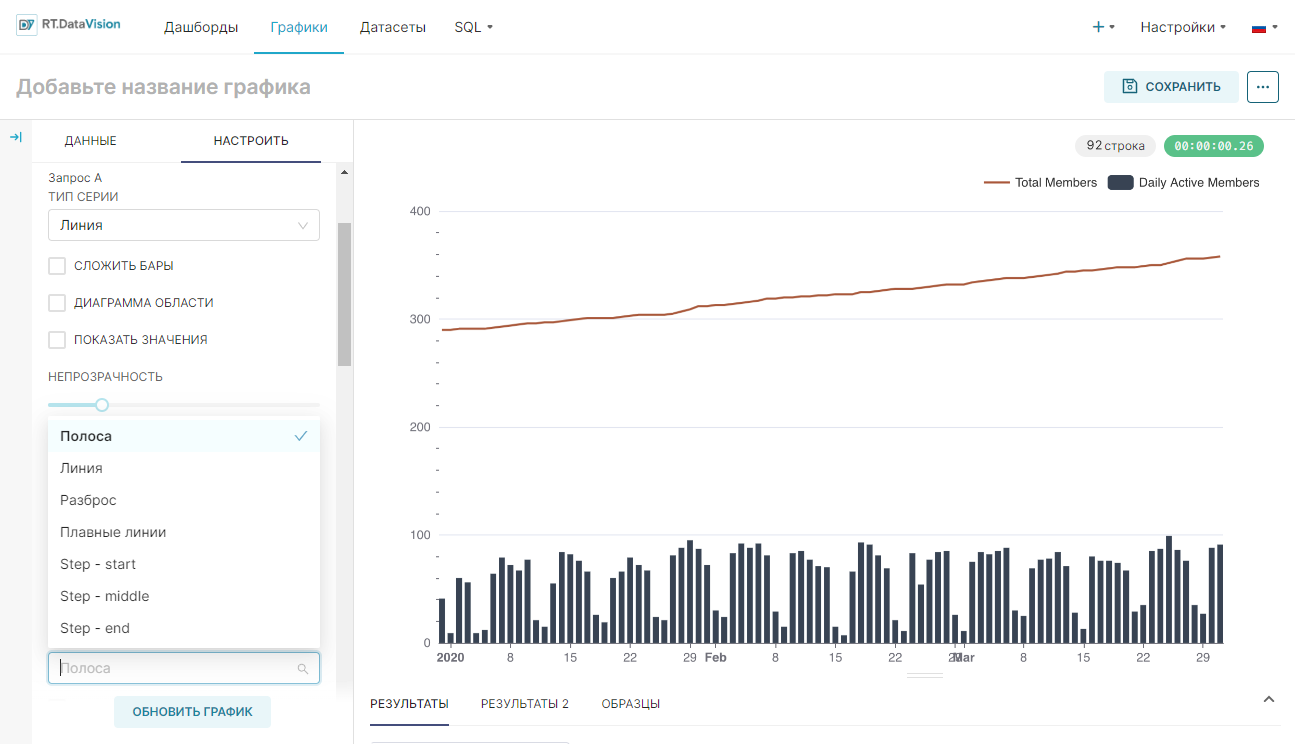
Процесс создания первого график, сочетающего гистограмму и линейный график:
1. Создайте новый график, щёлкнув вкладку Графики (Charts), затем кнопку + График (+ Chart), выберите датасет, найдите и выберите график смешанных временных рядов (Mixed Chart) в средстве выбора визуализации.
2. Выберите значение для Ось Х (X Axis) и установите для параметра временного интервала Гранулярность (Time range) значение Day.
3. Разверните раздел Запрос А (Query A) и вставьте столбец общего количества пользователей (Total Members) или эквивалентный столбец в выбранном датасете. Установите параметр Агрегированный (Aggregate) на MAX, если ваши данные предварительно агрегированы, или выберите соответствующую функцию для агрегирования.
4. Разверните раздел Запрос В (Query В) и вставьте столбец ежедневных активных пользователей (Daily Active Users, DAUs) или эквивалентный столбец в выбранном датасете. Установите параметр Агрегированный (Aggregate) на MAX, если данные предварительно агрегированы, или выберите соответствующую функцию для агрегирования.
5. Перейдите на вкладку Настроить (Customize). В разделе Запрос А (Query A) установите для параметра Тип серии (Series Type) значение Линия (Line), а в разделе Запрос В (Query В) установите для параметра Тип серии (Series Type) значение Полоса (Bar).
6. Нажмите Обновить график (Update Chart), чтобы посмотреть созданный график.
¶ 5.7.8. Создание графика смешанных временных рядов со скользящим средним
1. Создайте новый график, щёлкнув вкладку Графики (Charts), затем кнопку + График (+ Chart), выберите датасет, найдите и выберите график смешанных временных рядов (Mixed Chart) в средстве выбора визуализации.
2. Выберите значение для Ось Х (X Axis) и установите для параметра временного интервала Гранулярность (Time range) значение Day.
3. Разверните раздел Запрос А (Query A) и вставьте столбец ежедневных активных пользователей (Daily Active Users, DAUs) или эквивалентный столбец в выбранном датасете. Установите параметр Агрегированный (Aggregate) на MAX, если ваши данные предварительно агрегированы, или выберите соответствующую функцию для агрегирования.
4. Разверните раздел Расширенная аналитика запрос А (Advanced Analytics Query A) и установите:
- Функция прокатки (Rolling Function) в mean. В таком случае, RT.DataVision будет вычислять среднее значение за последние n периодов в указанный ранее интервал времени;
- Период (Periods) равный 7. Если установлен интервал времени на День (Day), скользящая функцию на среднее и периоды на 7, то RT.DataVision будет вычислять 7-дневное скользящее среднее;
- Минимальные периоды (Min Periods) на 0 или 7. Это минимальное количество периодов, необходимых для отображения вычисленных значений. Если 0, то даже скользящее среднее за 7 дней будет использовать только первый день для расчёта и визуализации среднего. Если 7, то 7-дневное скользящее среднее будет отображаться только после 7 дней наблюдений.
5. Разверните раздел Запрос В (Query В) и вставьте столбец ежедневных активных пользователей (Daily Active Users, DAUs) или эквивалентный столбец в выбранном датасете. Установите параметр Агрегированный (Aggregate) на MAX, если ваши данные предварительно агрегированы, или выберите соответствующую функцию для агрегирования. Не настраивайте Расширенная аналитика запрос В (Advanced Analytics Query В).
6. Перейдите на вкладку Настроить (Customize). В разделе Запрос А (Query A) установите для параметра Тип серии (Series Type) значение Линия (Line), а в разделе Запрос В (Query В) установите для параметра Тип серии (Series Type) значение Полоса (Bar).
7. Нажмите Обновить график (Update Chart), чтобы посмотреть созданный график.
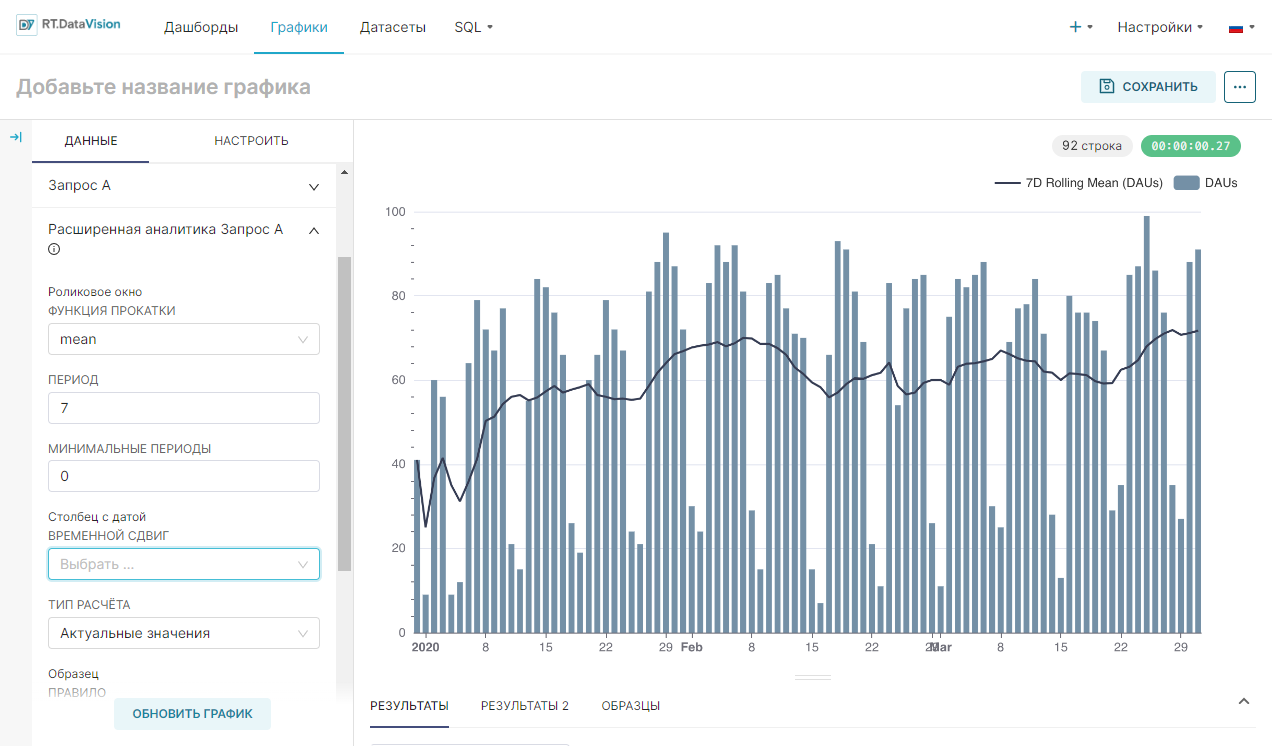
Чтобы заменить гистограмму точечный график, измените Тип серии (Series Type) для Запрос В (Query В) (сырые значения DAU) на Разброс (Scatter).
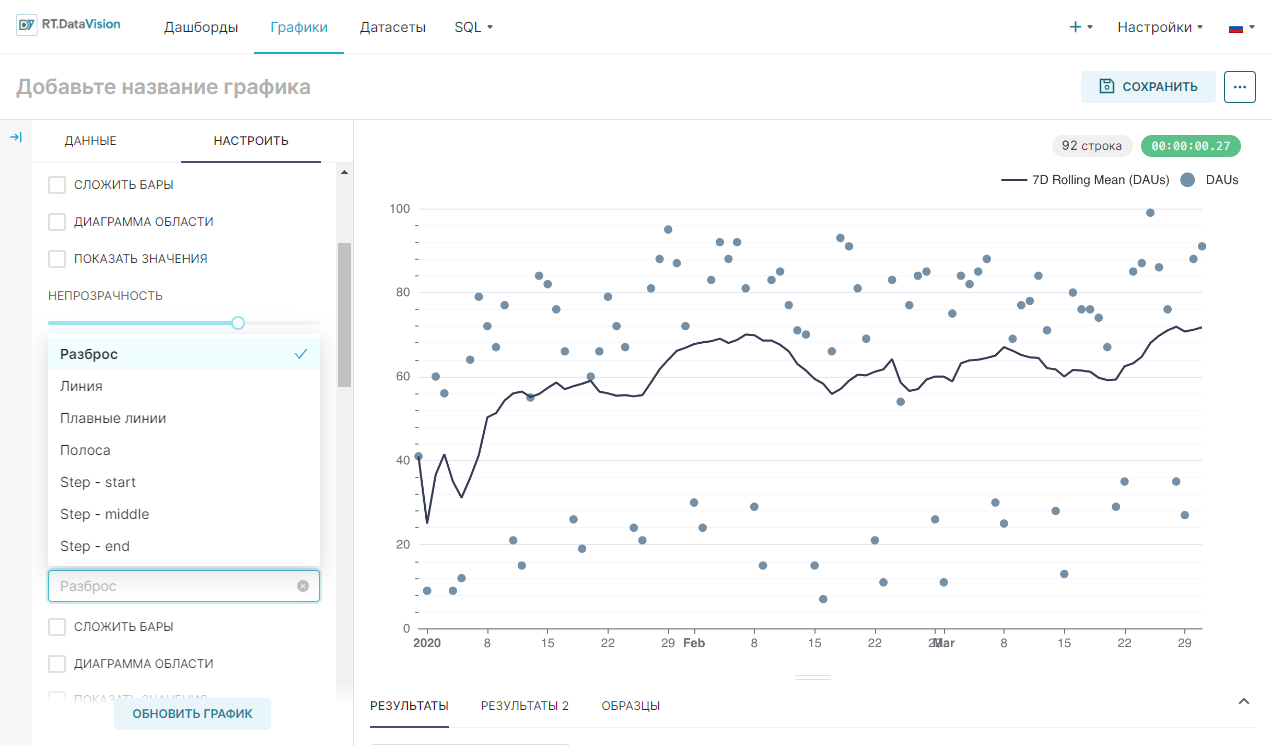
¶ 5.7.9. Создание смешанного графика с несколькими скользящими окнами
1. Создайте новый график, щёлкнув вкладку Графики (Charts), затем кнопку + График (+ Chart), выберите датасет, найдите и и выберите график смешанных временных рядов (Mixed Chart) в средстве выбора визуализации.
2. Выберите значение для Ось Х (X Axis) и установите для параметра временного интервала Гранулярность (Time range) значение Day.
3. Разверните раздел Запрос А (Query A) и вставьте столбец ежедневных активных пользователей (Daily Active Users, DAUs) или эквивалентный столбец в выбранном датасете. Установите параметр Агрегированный (Aggregate) на MAX, если данные предварительно агрегированы, или выберите соответствующую функцию для агрегирования в противном случае.
4. Разверните раздел Расширенная аналитика запрос А (Advanced Analytics Query A) и установите:
- Функция прокатки (Rolling Function) в mean. В таком случае, RT.DataVision будет вычислять среднее значение за последние n периодов в указанный ранее интервал времени;
- Период (Periods) равный 7. Если установлен интервал времени на День (Day), скользящая функцию на среднее и периоды на 7, то RT.DataVision будет вычислять 7-дневное скользящее среднее;
- Минимальные периоды (Min Periods) на 0 или 7. Это минимальное количество периодов, необходимых для отображения вычисленных значений. Если 0, то даже скользящее среднее за 7 дней будет использовать только первый день для расчёта и визуализации среднего. Если 7, то 7-дневное скользящее среднее будет отображаться только после 7 дней наблюдений.
5. Разверните раздел Запрос В (Query В) и вставьте столбец ежедневных активных пользователей (Daily Active Users, DAUs) или эквивалентный столбец в выбранном датасете. Установите параметр Агрегированный (Aggregate) на MAX, если данные предварительно агрегированы, или выберите соответствующую функцию для агрегирования.
6. Разверните раздел Расширенная аналитика запрос В (Advanced Analytics Query В) и установите:
- Функция прокатки (Rolling Function) в mean. Это означает, что RT.DataVision будет вычислять среднее значение за последние n периодов в указанный ранее интервал времени;
- Период (Periods) равный 5. Если мы установим интервал времени на Day, скользящую функцию на среднее и периоды на 5, то RT.DataVision будет вычислять 5-дневное скользящее среднее;
- Минимальные периоды (Min Periods) на 0 или 5.
7. Перейдите на вкладку Настроить (Customize). В разделе Запрос А (Query A) установите для параметра Тип серии (Series Type) значение Линия (Line), а в разделе Запрос В (Query В) установите для параметра Тип серии (Series Type) значение Линия (Line) (т.е. оба графика линейные).
8. Нажмите Обновить график (Update Chart), чтобы посмотреть созданный график.
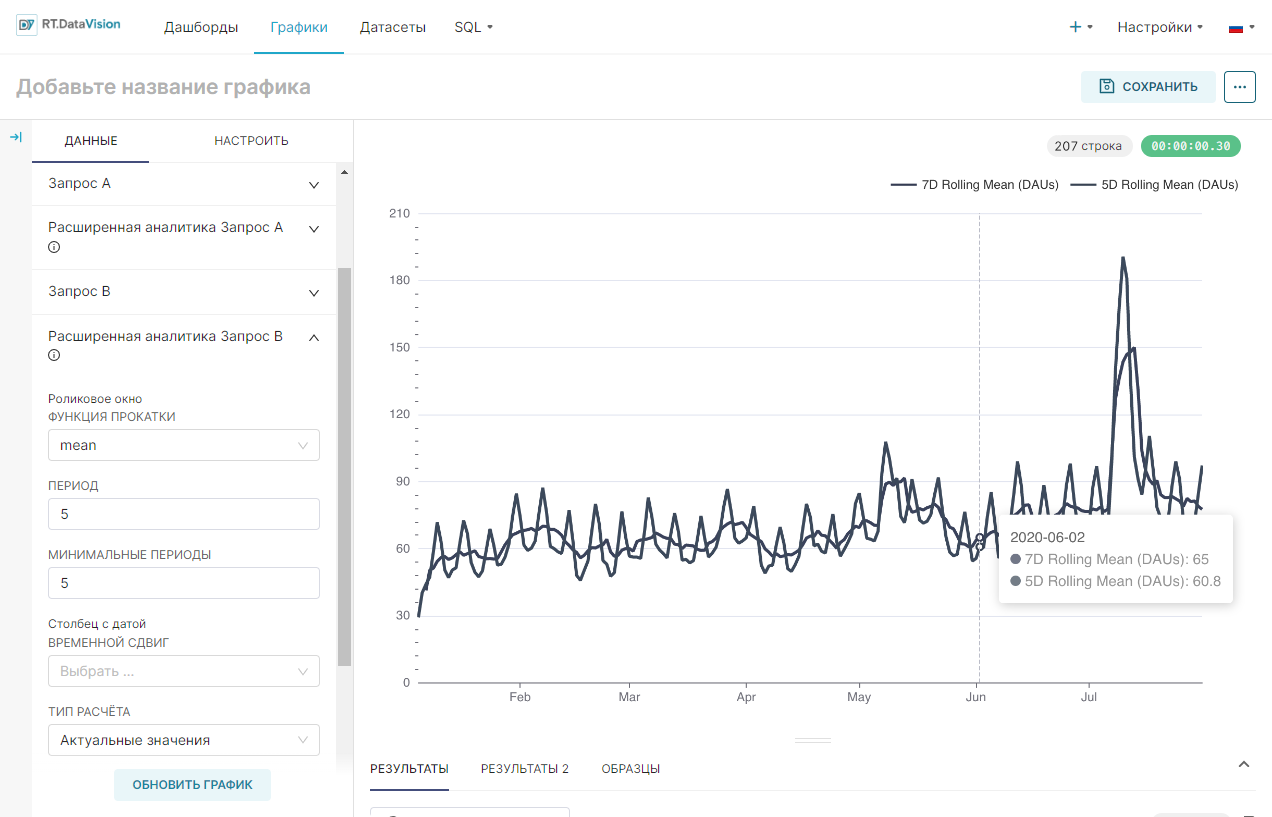
¶ 5.8. Круговая диаграмма (Pie Chart)
Круговая диаграмма (Pie Chart) — это классическая визуализация, которая представляет пропорции целого с помощью слайсов круга. Ниже два примера одного и того же кругового графика, один из которых представлен в виде классического кругового графика, а другой — кольцевой график (в виде “пончика”).
¶ 5.8.1. Создание кругового графика
¶ 5.8.1.1. Круговой график с одним измерением
Чтобы создать круговой график, необходимо определить:
- Показатели (Metrics) — метрика, которую хотите визуализировать;
- Измерения (Dimensions) — измерения, по которым хотите разделить метрику.
Пример графика:
Значения, используемые для создания такого графика:
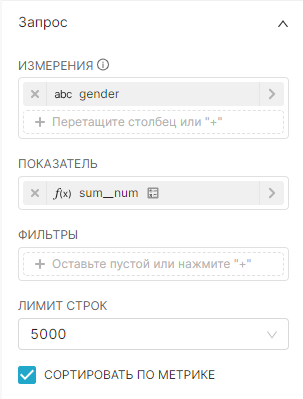 |
Параметры в Исследовать (Explore):
|
|
Сгенерированный SQL-запрос |
¶ 5.8.2. Круговой график с использованием нескольких измерений
Существует возможность включения нескольких измерений в круговой график. Результатом будет комбинация m на n секторов круга, используемых в группировке. Пример графика:
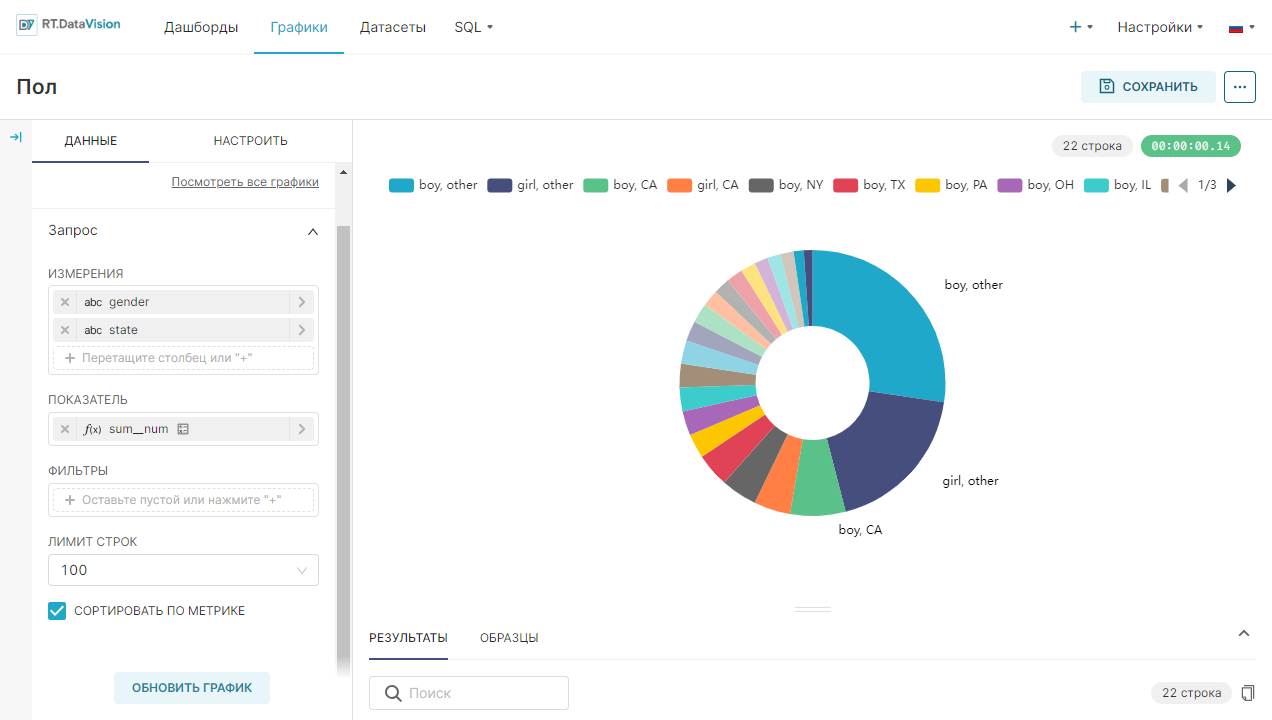
Значения, используемые для создания такого графика:
 |
Параметры в Исследовать (Explore):
|
|
Сгенерированный SQL-запрос |
¶ 5.8.3. Настройка кругового графика
Кастомизация кругового графика доступна с помощью параметров на вкладке Настроить (Customize):
1. Легенда (Legend):
- Показать легенду (Show Legend) — показывает легенду, если этот флажок установлен;
- Тип (Type) — прокручиваемая (Scroll) или статичная (Plain) легенда по умолчанию;
- Ориентация (Orientation) — местоположение легенды;
- Маржа (Margin) — дополнительный отступ для добавления вокруг легенды (в пикселях).
2. Метки (Labels):
- Тип метки (Label Type) — что будет отображаться на метках для каждого слайса графика, например, при выборе Название категории (Category Name) будут отображаться значения измерения или измерений;
- Формат числа (Number Format) — синтаксис формата D3. Может применяться только в тех случаях, когда для Тип метки (Label Type) выбрано значение, отображающее значения (Значение (Value) и прочие);
- Формат даты (Date Format) — синтаксис формата D3;
- Показать метки (Show Labels) — показывает метку для каждого слайса кругового графика, если этот флажок установлен;
- Поместите этикетки снаружи (Puts Labels Outside) — размещает метки снаружи секторов круговой диаграммы, если этот флажок установлен (в противном случае — внутри секторов);
- Линия метки (Label Line) — добавляет соединительные линии между метками секторов круга и самими сегментами, если этот флажок установлен;
- Показать метки (Show Total) — показывает общее количество значений метрик по всем группам.
3. Форма круга (Pie Shape):
- Внешний радиус (Outer Radius) — ползунок для указания радиуса кругового графика;
- Пончик (Donut) — переключает круговой график на кольцевой круговой график (в виде “пончика”) диаграмму, если этот флажок установлен;
- Внутренний радиус (Inner Radius) — ползунок для указания радиуса внутреннего круга на кольцевом графике (должен быть установлен флажок Пончик (Donut)).
¶ 5.9. Сводная таблица (Pivot Table)
Сводная таблица (Pivot Table) — это таблица сгруппированных значений, которая объединяет отдельные элементы более обширной таблицы в одной или нескольких дискретных категориях.
В качестве примера, в описанном ниже пошаговом руководстве будет создана сводная таблица, в которой будут представлены рейтинги имён в стране по регионам.
¶ 5.9.1. Шаг 1. Создание нового графика
Для создания графика:
1. На панели инструментов выберите + График (+ Chart). Появится экран Создайте новый график (Create a new chart).
2. В поле Выберите датасет (Choose a Dataset) выберите датасет, на основе которого будет создан запрос. В этом примере выбран датасет, который включает данные об именах в стране (birth_names).
3. В поле Выберите тип графика (Choose Chart Type) выберите Сводная таблица (Pivot Table) в галерее графиков, либо введите Сводная (Pivot) в поле поиска.
4. Выберите Создайте новый график (Create New Chart).
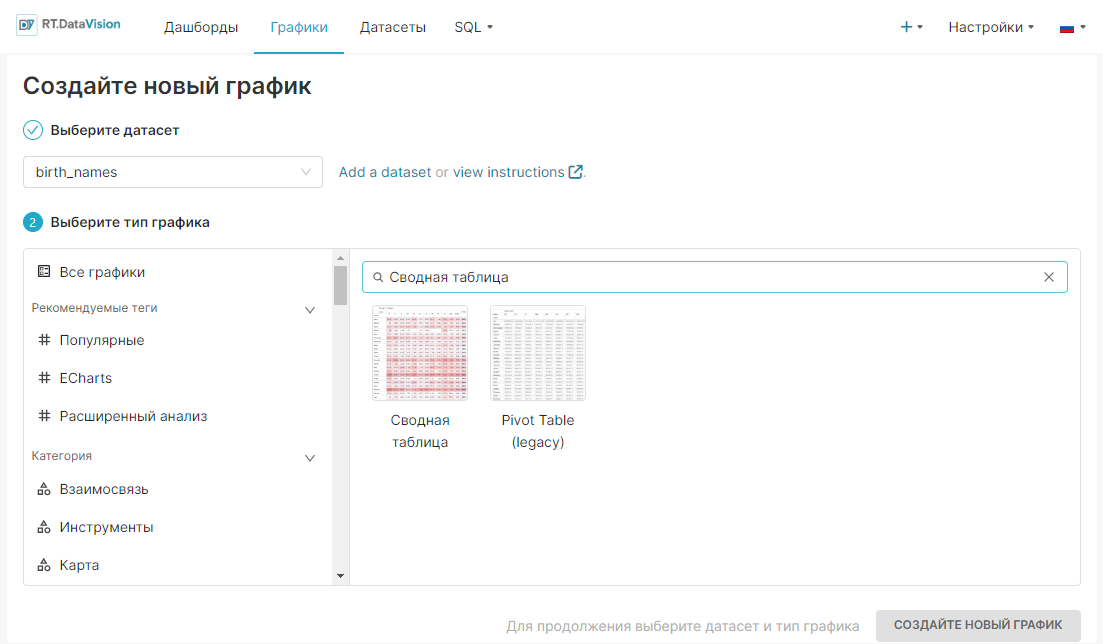
¶ 5.9.2. Шаг 2. Настройка графика
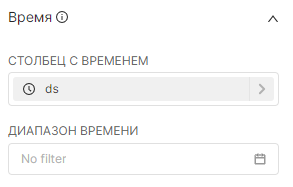
|
Панель Время (Time):
|
|
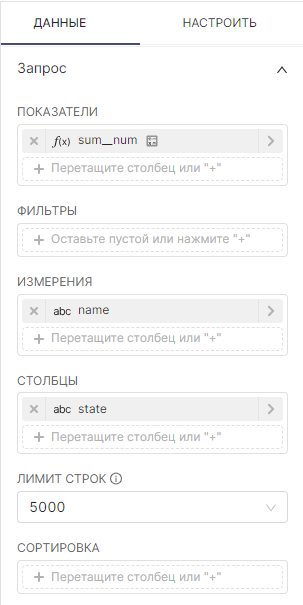 |
Панель Запрос (Query):
|
|
 |
Панель Параметры поворота (Pivot Options):
|
|
¶ 5.9.3. Шаг 3. Создание графика
Выберите Создать график (Create Chart) или Обновить график (Update Chart). Сводная таблица будет построена и отображена.
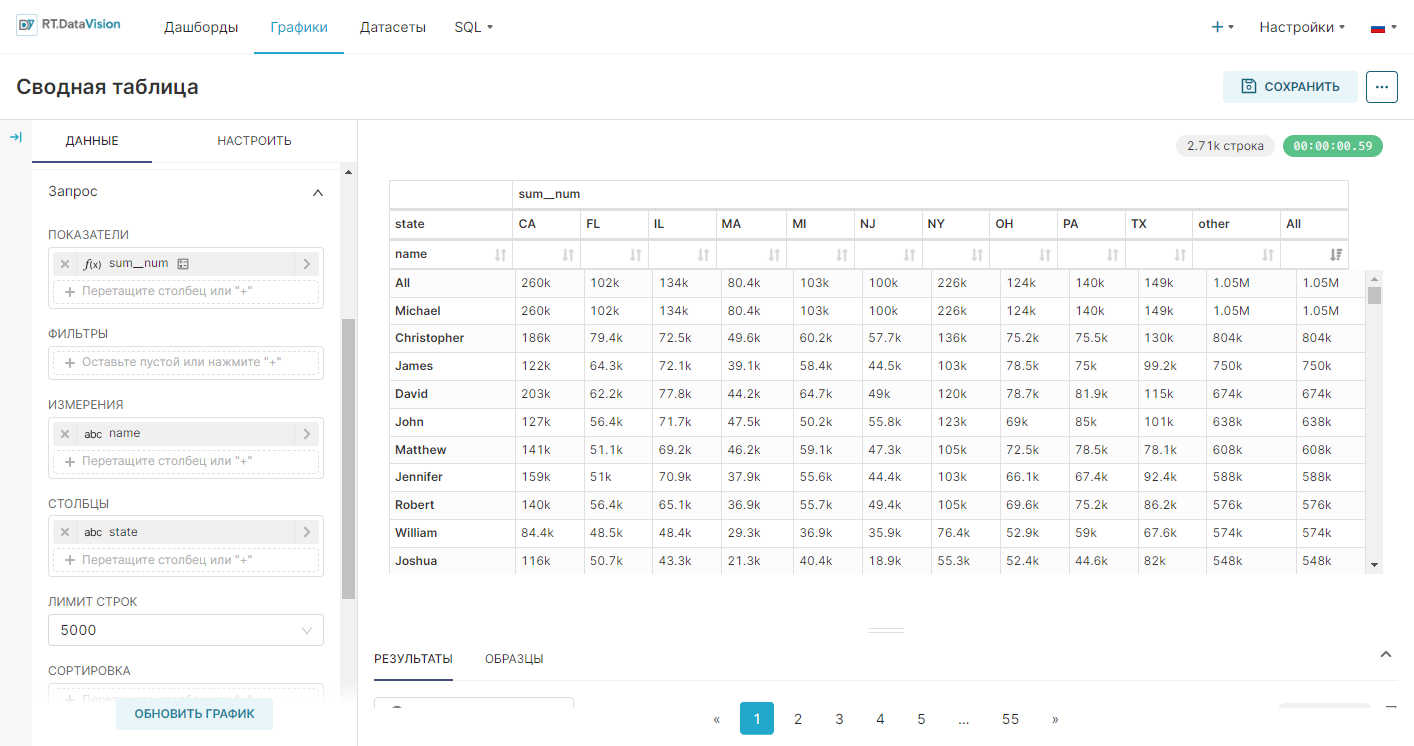
Для просмотра результатов данных и выборки из запроса разверните раздел Результаты (Results).
¶ 5.9.4. Шаг 4. Финализация графика
Если изменение визуализации не требуется, то укажите имя графика в поле Добавьте название графика (Add the name of the chart).
Если необходимо изменить визуализацию, то перейдите на вкладку Настроить (Customize) и кастомизируйте график.
Сохраните график с помощью кнопки Сохранить (Save). Существует возможность сохранения графика на существующем дашборде или создание нового дашборда из меню Сохранить (Save).
¶ 5.10. Диаграмма Санкей (Sankey Diagram)
Диаграмма Санкей (Sankey Diagram) — это популярный график, наглядно иллюстрирующий бизнес-процесс или движение потока. График показывает взаимосвязи частных потоков, их силу и вклад в общий поток. Ширина каждой линий потока на графике напрямую связана с долей этого потока: чем больше параметр потока, тем толще линия. Пример:
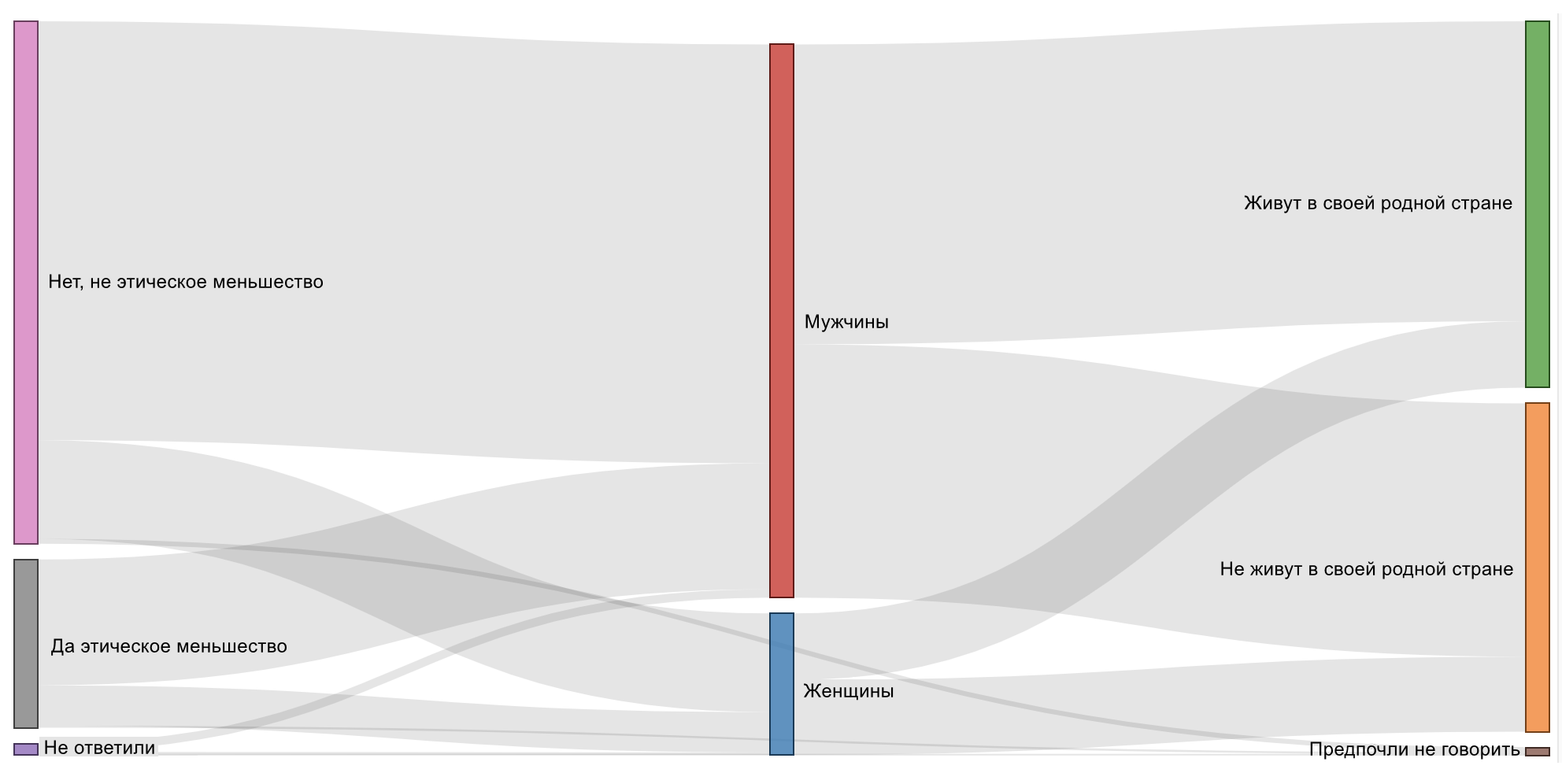
¶ 5.10.1. Создание графика Санки
График Санки использует узлы (визуально представленные в виде прямоугольников), рёбра (визуально представленные в виде потоков) и иерархию (слева направо). Акцент делается на потоке между узлами, а не на самой иерархии. Иерархия представляет этапы в системном потоке.
¶ 5.10.1.1. Форма данных
Структурирование данных в правильной форме имеет решающее значение для построения эффективного графика Санки. На примере ниже показано, как строка в датасете сопоставляется с парой узел-ребро-узел на графике.
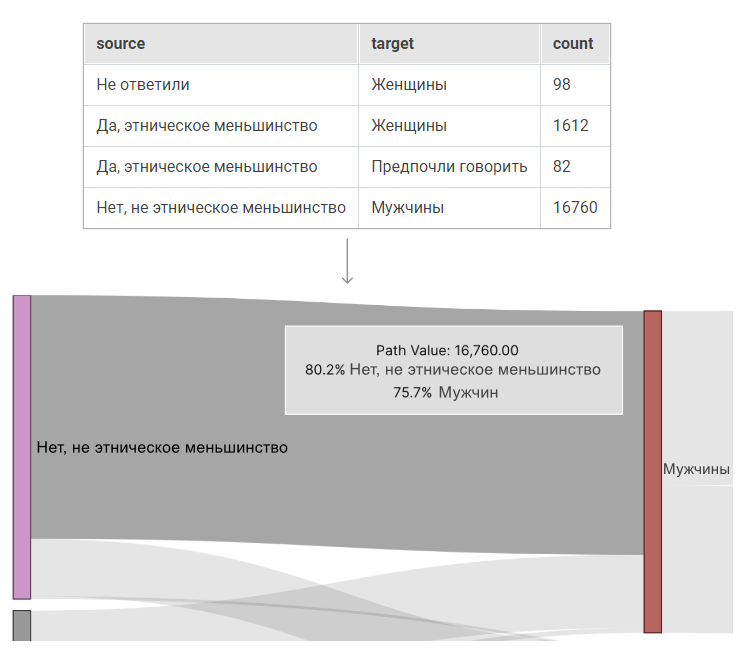 |
|
Чтобы масштабировать этот подход и построить полный график Санки, RT.DataVision использует ваши данные для расчёта всех пар source-target, а затем упорядочивает их слева направо при создании визуализации. Какие узлы тогда входят в крайний левый столбец (или первый слой узлов)? Уникальные значения столбца source, которых нет в столбце target (или потоке получения), попадают на первый уровень.
Пример графика:
Базовые данные и значения в Исследовать (Explore), используемые для создания такого графика:
 |
Базовые данные:
|
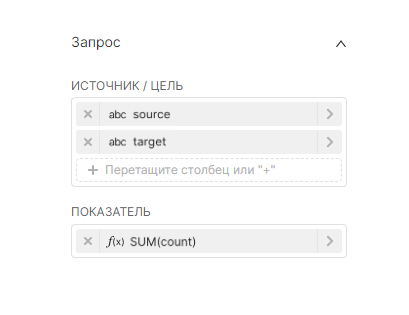 |
Параметры в Исследовать (Explore):
|
|
Сгенерированный SQL-запрос |
¶ 5.11. Радиальная диаграмма (Radar Chart)
Радиальная диаграмма (Radar Chart) позволяет визуализировать параллельный набор показателей по нескольким группам или категориям. Примеры графиков:
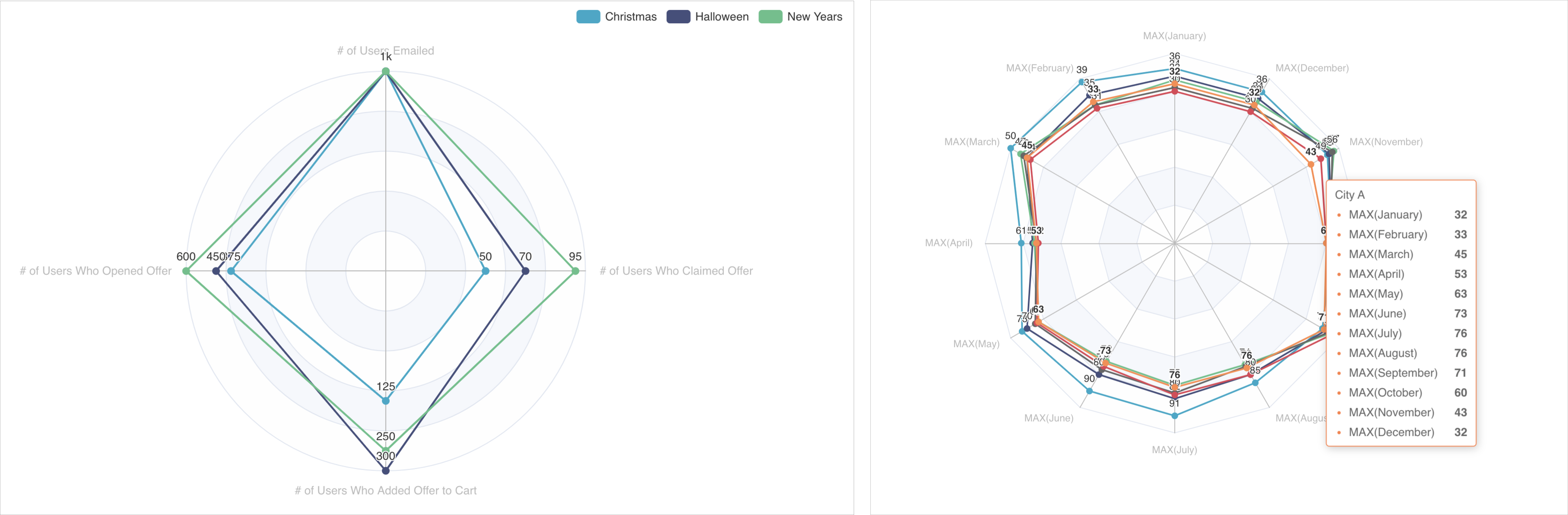
¶ 5.11.1. Создание базового радарного графика
Радиальная диаграмма — это уникальный и гибкий тип визуализации. Базовые данные и значения в Исследовать (Explore), используемые для создания такого графика:
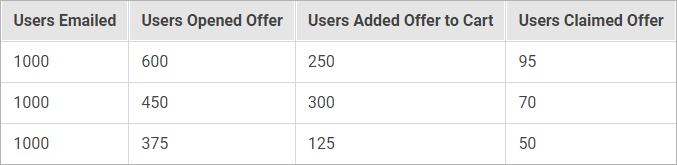 |
Форма данных:
|
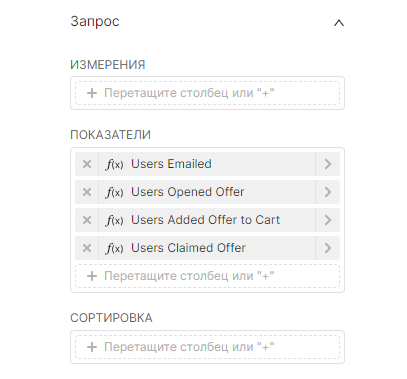 |
Параметры в Исследовать (Explore):
|
|
Сгенерированный SQL-запрос |
 |
Результирующий датасет:
|
Получившийся график:
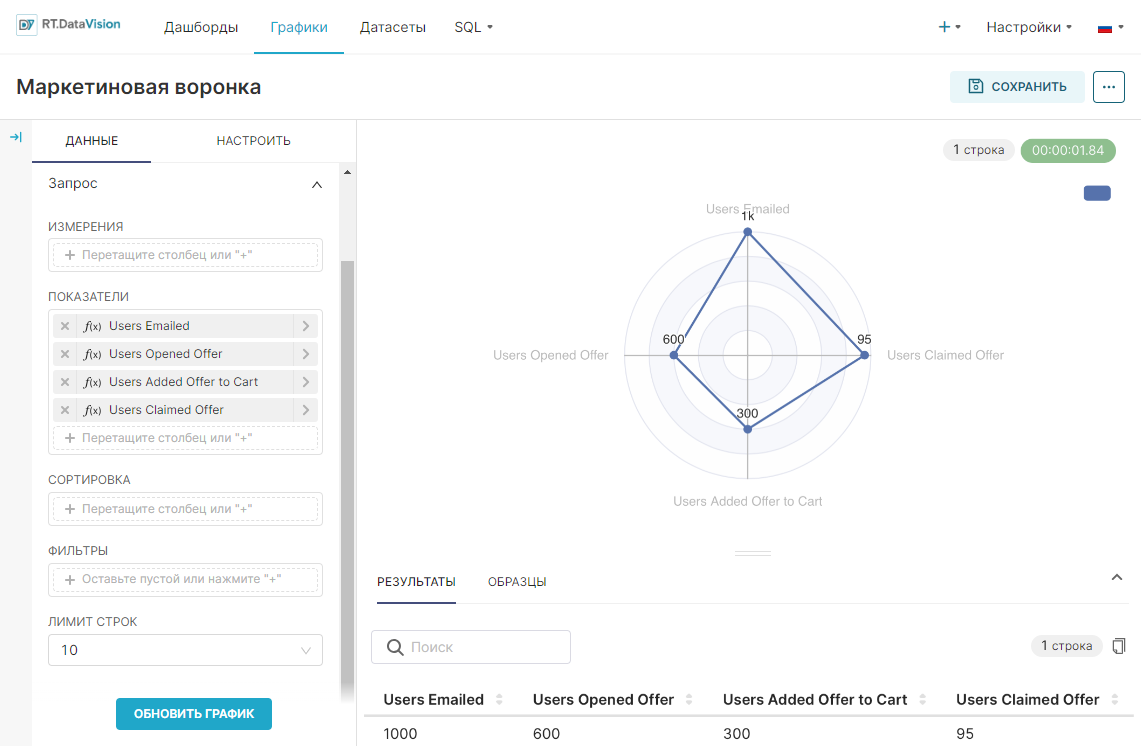
¶ 5.11.2. Создание радарного графика с измерениями
Существует возможность включить измерение в только что созданный график, используя параметр Измерения (Dimensions) в Исследовать (Explore). Уникальные значения будут использоваться для группировки данных и результирующих узлов и рёбер.
 |
Форма ваших данных:
|
 |
Параметры Explore:
|
|
Сгенерированный SQL-запрос:
|
 |
Результирующий датасет:
|
Получившийся график:
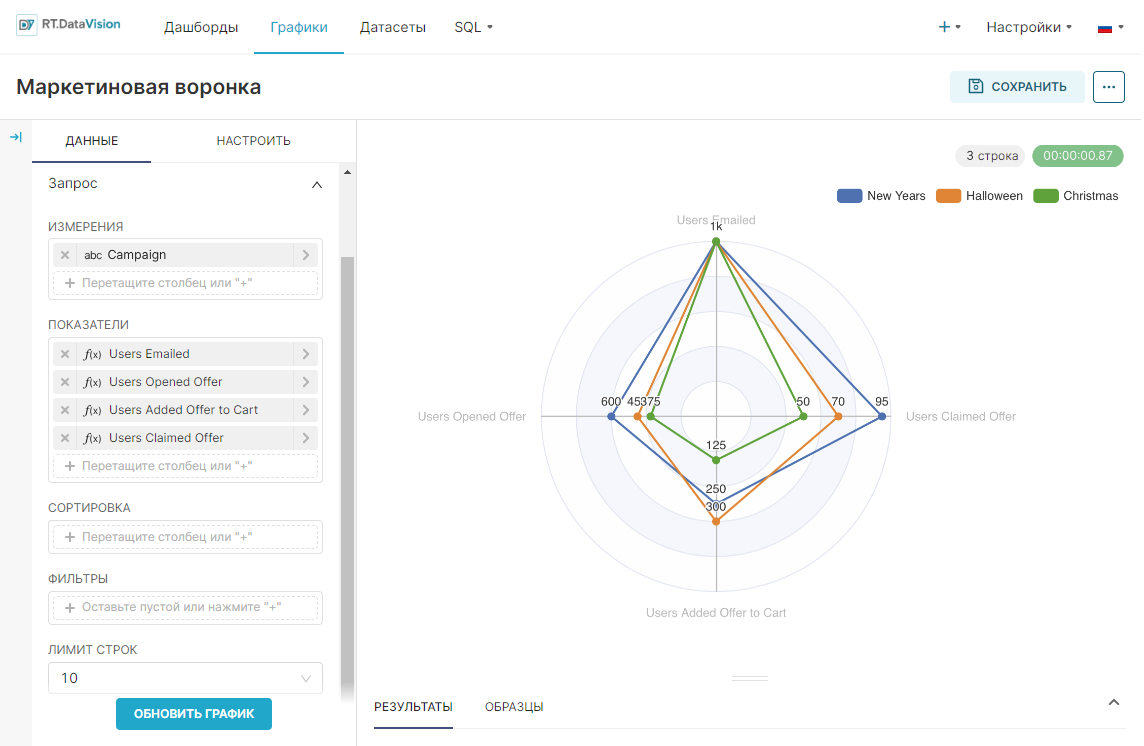
¶ 5.11.3. Настройка радарного графика
На вкладке Настроить (Customize) можно найти ряд параметров для дальнейшей настройки радарного графика. Некоторые из вариантов:
- Цветовая схема (Color Scheme) — выбор цветовой палитры, используемой в графике;
- Легенда (Legend):
- Показать легенду (Show Legend) — флажок, который регулирует отображение легенды (содержащую размеры и цвета);
- Тип (Type) — выбор тип поведения прокрутки для легенды;
- Маржа (Margin) — дополнительный отступ в пикселях, который можно добавить для легенды;
- Метки (Labels):
- Показать метки (Show Labels) — флажок, который регулирует отображение значения метрик в виде меток;
- Положение метки (Label Position) — расположение меток;
- Формат числа (Number Format) — в каком формате необходимо отображать числа;
- Формат даты (Date Format) — в каком формате необходимо отображать даты;
- Радар (Radar):
- Круглая форма радара (Circle Radar Shape) — флажок, регулирующий включение круговой формы графика в качестве фона.
¶ 5.12. Древовидный график (Tree Chart)
Древовидный график (Tree Chart) превосходно визуализирует иерархию. Пример графика:
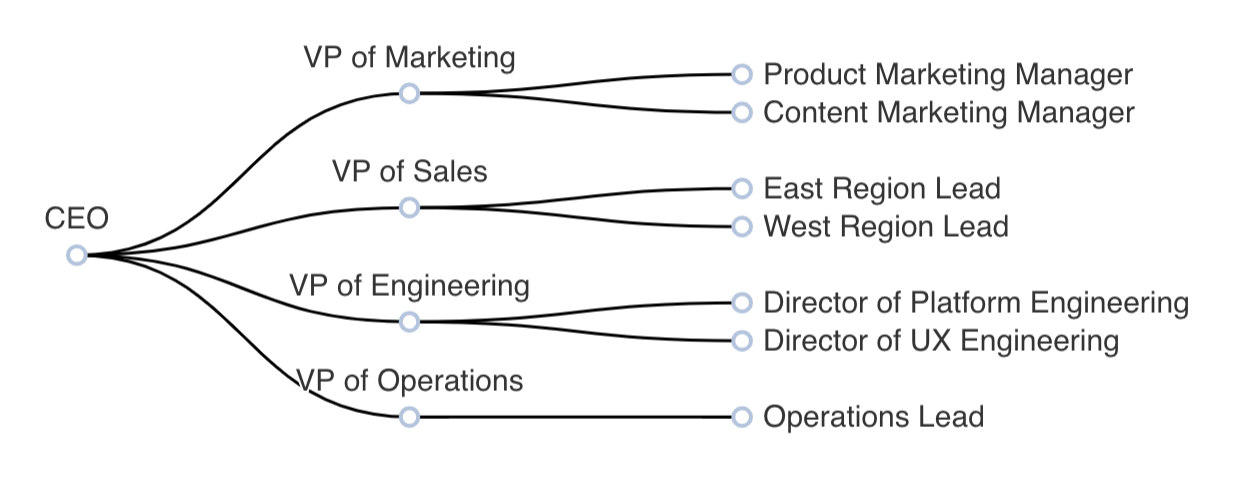
¶ 5.12.1. Создание древовидного графика
Создание древовидного графика похоже на создание графа, но с одним исключением: древовидные графики обеспечивают иерархию, а графы — нет. Для создания по-прежнему нужны узлы (или круги) и рёбра (или соединительные линии между кругами), но и также нужна дополнительная информация об иерархии. Пример того, как два ребра и соединительное ребро визуализируются в RT.DataVision и исходных данных, из которых оно получено:
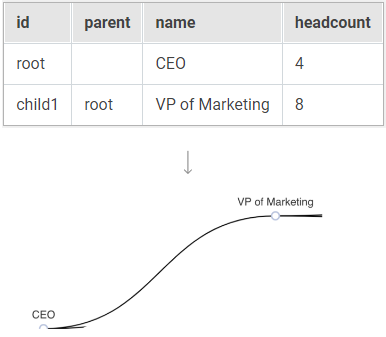 |
|
Схема, которая демонстрирует полный жизненный цикл того, как данные передаются из базы данных в RT.DataVision при создании древовидного графика:
| Исходные данные |
 |
| Значения в Исследовать (Explore) |
 |
| Сгенерированный запрос |
|
| Финальные данные |
 |
Если данные не сформированы таким образом и нет возможности изменить данные на уровне базы данных, то рекомендуется изменить форму данных в SQL Lab и опубликовать результат в виде виртуального датасета.
¶ 5.12.2. Настройка графика
На вкладке Настроить (Customize) находится ряд параметров для дальнейшей настройки древовидного графика.
- Расположение деревьев (Tree Layout) — по умолчанию Ортогональный (Orthogonal), но при желании можно переключиться на более круговую (Радиальный (Radial)) компоновку;
- Ориентация деревьев (Tree Orientation) — выберите один из 2 вариантов горизонтального дерева (Слева направо (Left to Right), Справа налево (Right to Left)) и 2 варианта вертикального дерева (Сверху вниз (Top to Bottom), Снизу вверх (Bottom to Top));
- Положение метки узла (Node Label Position) — выберите, где необходимо разместить метки для узлов по отношению к самим узлам (Слева (Left), Верхний (Top), Нижняя (Bottom), Справа (Right));
- Положение дочерней метки (Child Label Position) — выберите, необходимо разместить метки для дочерних узлов (Слева (Left), Верхний (Top), Нижняя (Bottom), Справа (Right));
- Упор на (Emphasis) — определите отображение визуального акцента при наведении курсора (Предок (Ancestor), Потомок (Descendant));
- Символ (Symbol) — определите использование символа для представления каждого узла;
- Размер символа (Symbol Size) — ползунок для выбора размера каждого символа (представляющего каждый узел);
- Включить роуминг графа (Enable Graph Roaming) — если при визуализации большого количества узлов и рёбер наблюдается замедление при масштабировании и перемещении, то рекомендуется отключить некоторые варианты поведения:
- Только перемещение (Move only) — пользователи графиков могут щёлкать и перетаскивать представление графика, но не увеличивать или уменьшать масштаб;
- Только шкала (Scale only) — пользователи графиков могут увеличивать или уменьшать масштаб, но не могут щёлкать и перетаскивать представление графика;
- Масштабировать и перемещать (Scale and Move) — пользователи графиков могут как увеличивать или уменьшать масштаб, так и щёлкать и перетаскивать для перемещения по представлению графика;
- Отключен (Disabled) — фиксированный вид графика, без масштабирования или перемещения.
¶ 5.13. Диаграмма области (Area Chart)
Диаграмма области (Area Chart) лучше всего подходит для понимания того, как отношения, пропорции или проценты меняются с течением времени. Примеры различных графиков с областями:
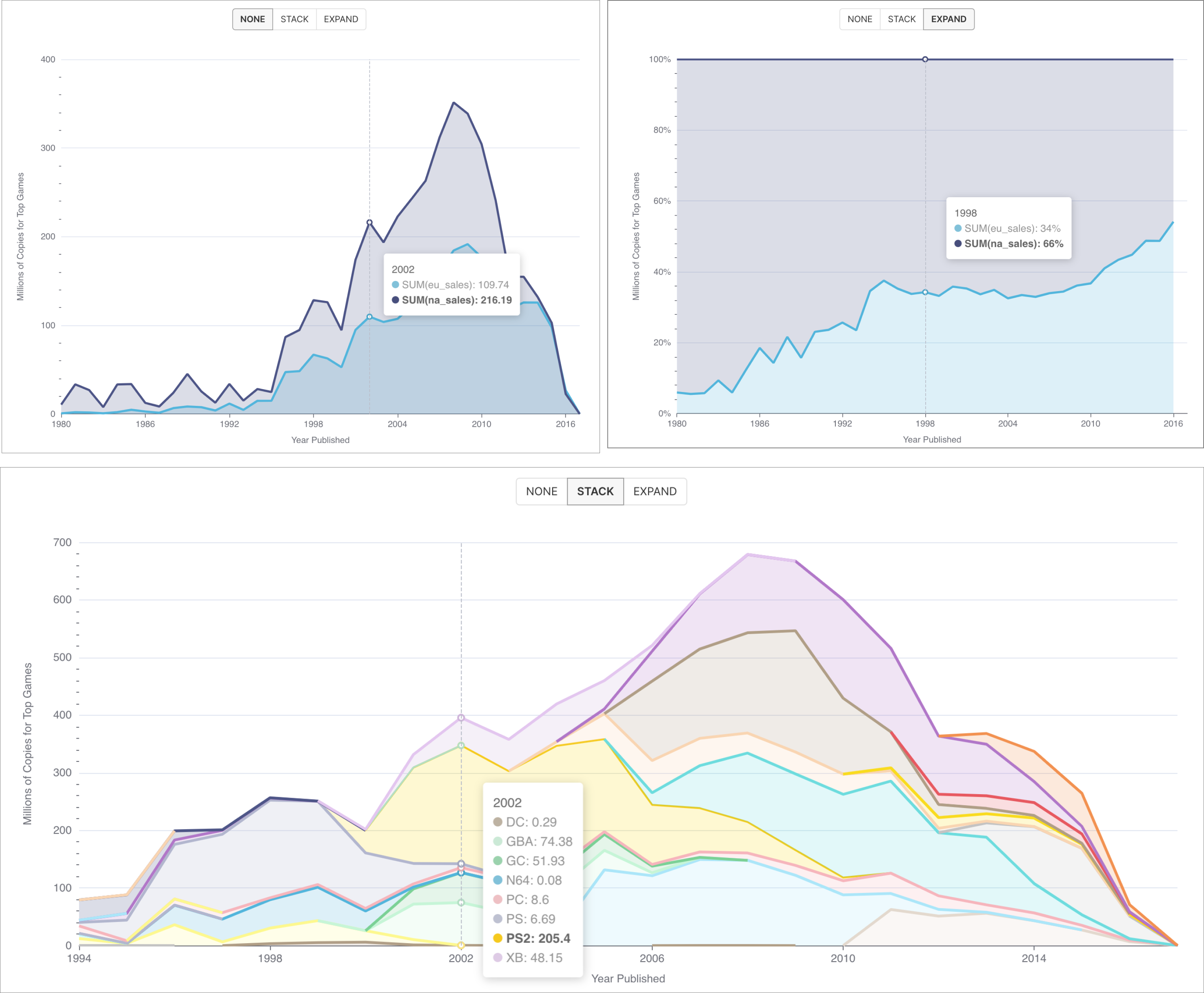
¶ 5.13.1. Создание графика
В настоящее время RT.DataVision имеет несколько параметров для графика с областями временных рядов в средстве выбора визуализации:
- Диаграмма области (Area Chart);
- Area Chart (legacy).
Рекомендуется использовать тип визуализации Диаграмма области (Area Chart), так как он более новый и поддерживает больше функций.
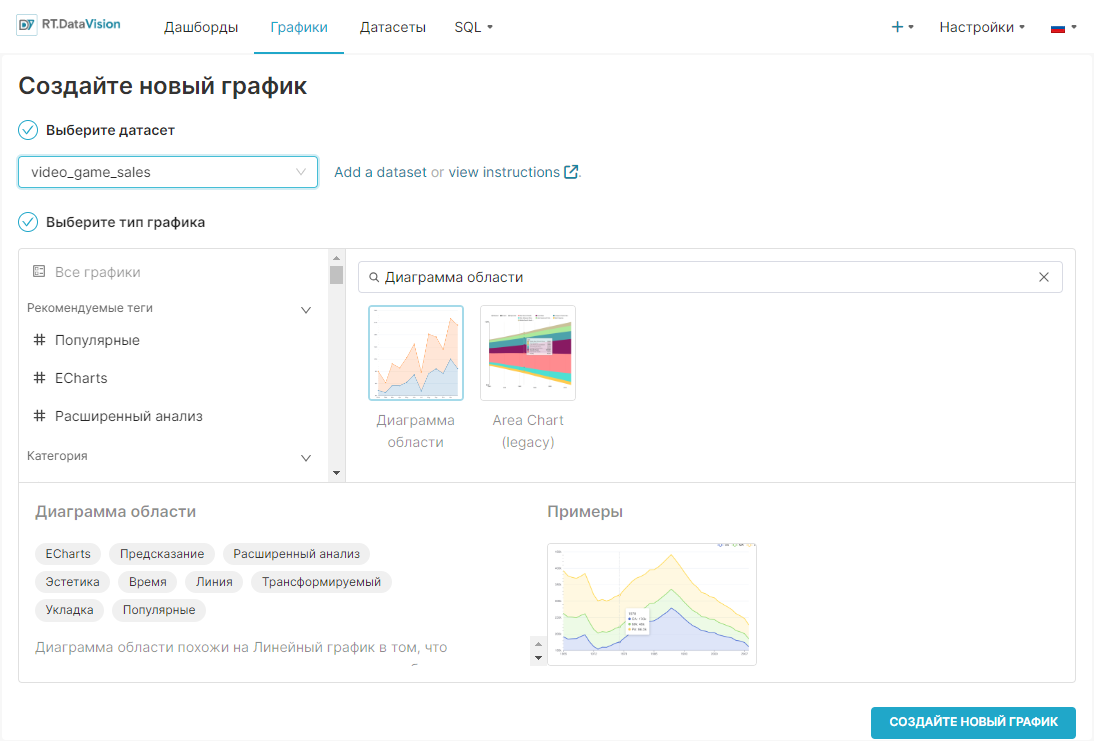
Для создания графика с областями временных рядов необходимо определить следующие значения:
- Столбец, используемый в качестве временной оси X;
- Метрики, визуализируемые на оси Y;
- Столбцы для группировки/классификации метрик.
Все параметры расположены на вкладке Данные (Data) в разделе Исследовать (Explore).
¶ 5.13.2. Простой график с областями (без измерений)
Ниже приведён простой график с областями, на котором показана одна метрика, меняющаяся во времени:
Значения в Исследовать (Explore), используемые для создания такого графика:
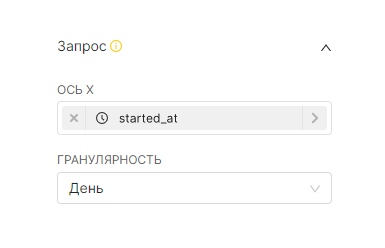 |
Временная ось X:
|
 |
Изменяющиеся во времени метрики по оси Y:
|
|
Сгенерированный SQL-запрос |
¶ 5.13.3. График с областями (с измерениями)
Ниже приведён график, аналогичный приведённому выше, но с добавленным измерением.
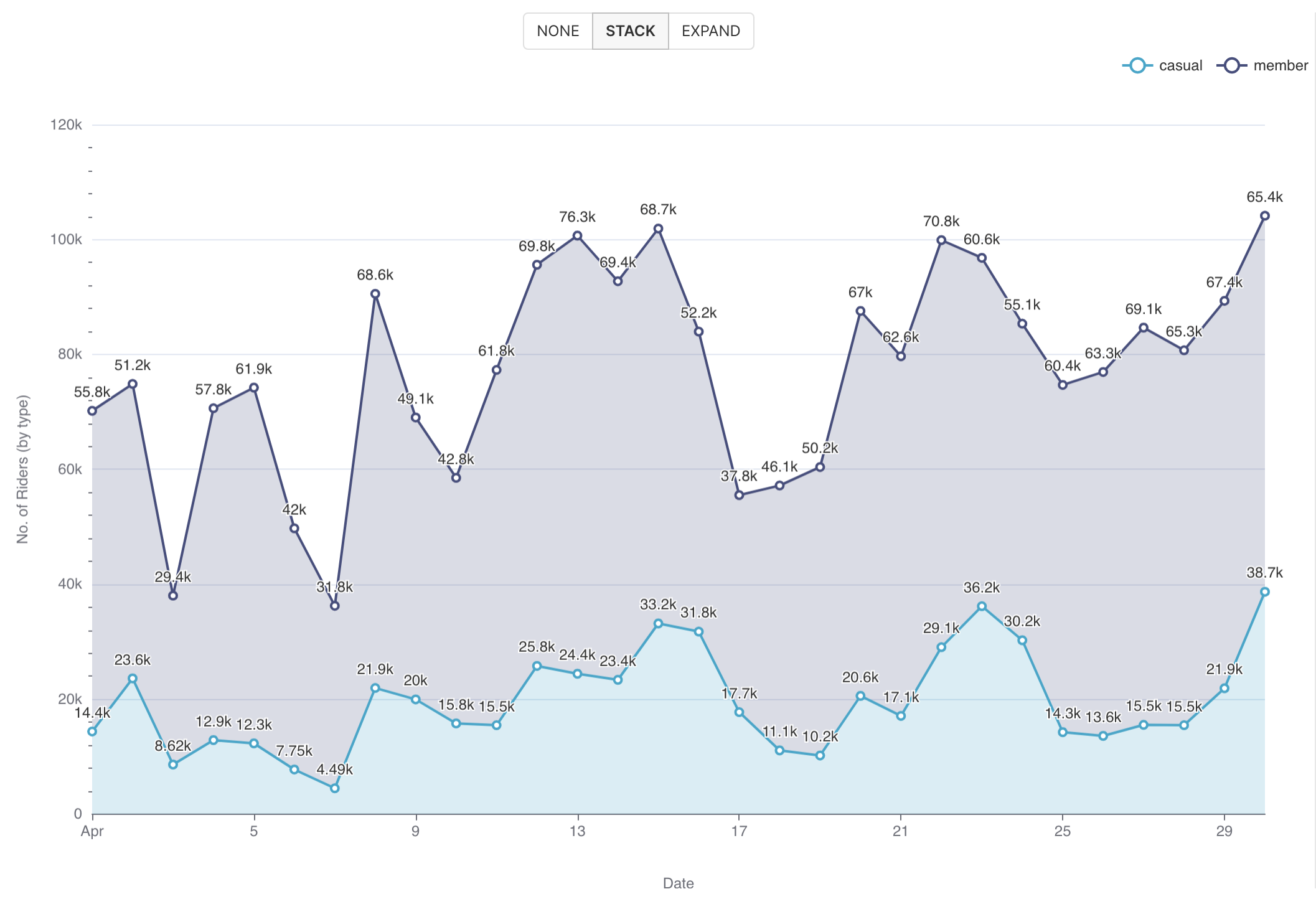
Чтобы создать такой график, использованы те же выборки из первого графика, но добавлены следующие дополнительные выборки:
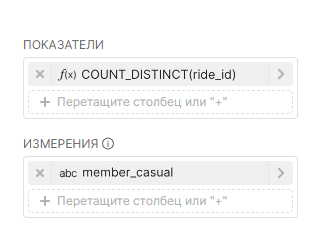 |
Измерения (Dimensions):
|
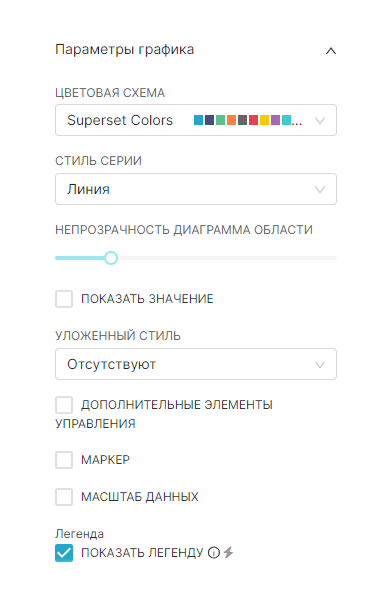 |
Параметры вкладки Настроить (Customize):
|
|
Сгенерированный SQL-запрос |
¶ 5.13.4. Расширенная аналитика
Как и большинство визуализаций временных рядов в RT.DataVision, график с областями временных рядов поддерживает функции расширенной аналитики.
¶ 5.14. Гистограмма временных рядов (Time-series Bar Chart)
Гистограмма временных рядов (Time-series Bar Chart) превосходно демонстрирует изменения с течением времени. Во многих областях различие между дискретными и непрерывными значениями довольно тонкое. Примеры графиков:
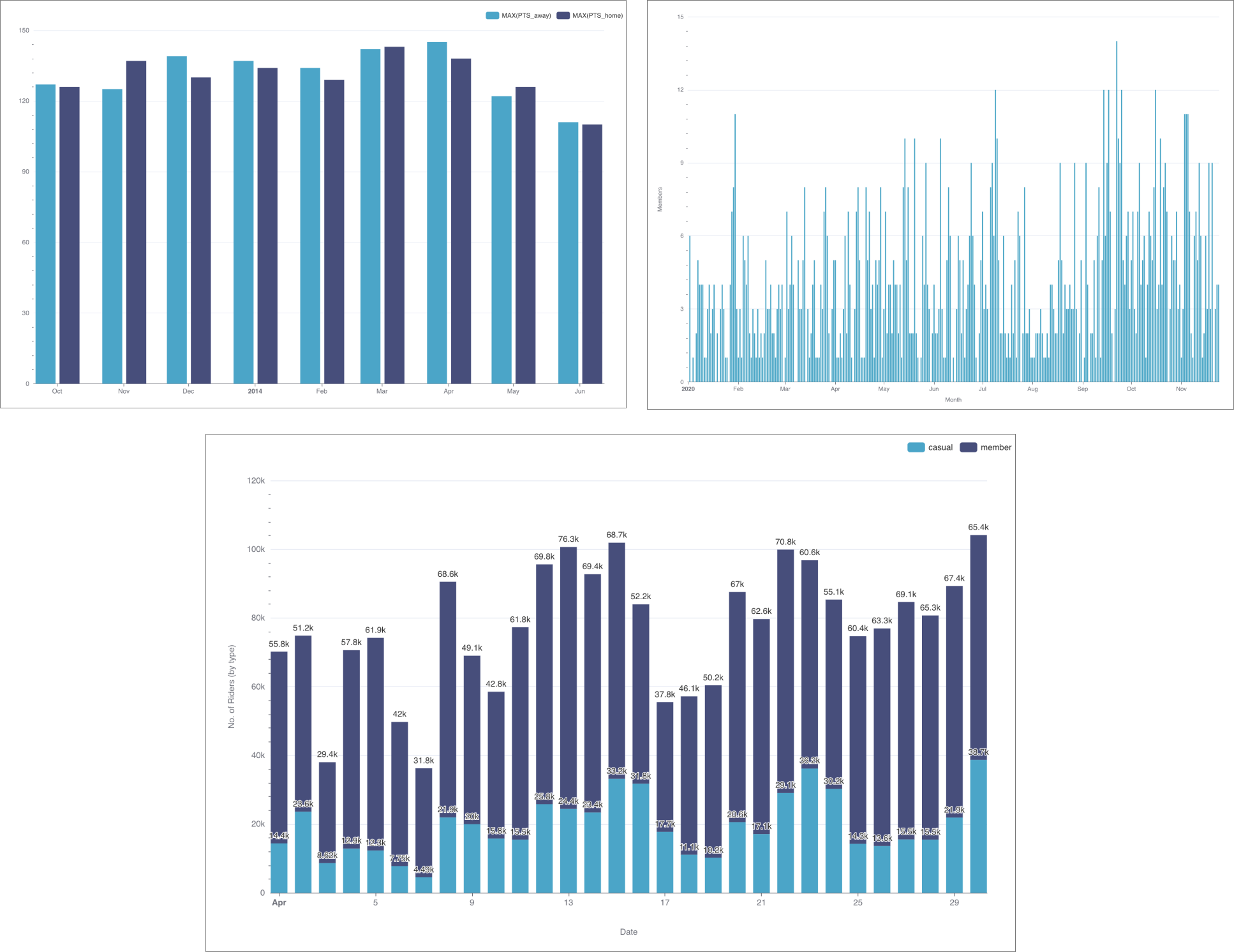
¶ 5.14.1. Создание гистограммы временных рядов
Для создания гистограммы временных рядов необходимо определить следующие значения:
- Столбец, используемый в качестве временной оси X;
- Метрики, визуализируемые на оси Y;
- Столбцы для группировки/классификации метрик.
Все параметры расположены на вкладке Данные (Data) в разделе Исследовать (Explore).
¶ 5.14.2. Простая гистограмма (без измерений)
Пример простого графика, показывающий изменение одной метрики с течением времени:
Значения в Исследовать (Explore), используемые для создания такого графика:
 |
Временная ось X:
|
 |
Изменяющиеся во времени метрики по оси Y:
|
|
Сгенерированный SQL-запрос |
¶ 5.14.3. Гистограмма (с измерениями)
Пример графика, аналогичный приведённому выше, но с добавленным измерением:
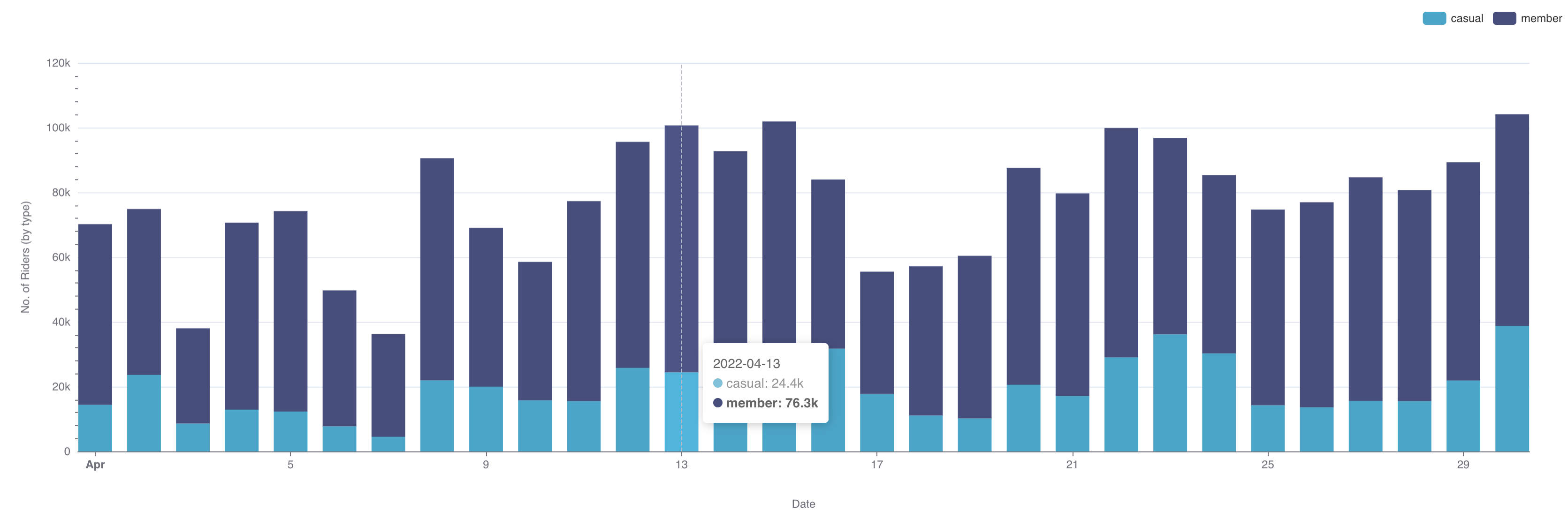
Чтобы создать такой график, использованы те же выборки из первого графика, но добавлены следующие дополнительные выборки:
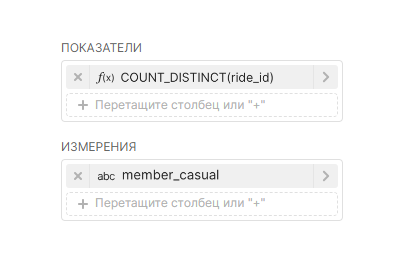 |
Измерения (Dimensions):
|
|
Сгенерированный SQL-запрос |
¶ 5.14.4. Расширенная аналитика
Как и большинство визуализаций временных рядов в RT.DataVision, график с областями временных рядов поддерживает функции расширенной аналитики.
¶ 5.15. Точечный график временных рядов (Time-series Scatter Plot)
Точечный график временных рядов (Time-series Scatter Plot) превосходно демонстрирует изменения во времени, особенно для непрерывных значений. Примеры графиков:
¶ 5.15.1. Создание точечного графика временных рядов
Для создания точечного графика временных рядов необходимо определить следующие значения:
- Столбец, используемый в качестве временной оси X;
- Метрики, визуализируемые на оси Y;
- Столбцы для группировки/классификации метрик.
Все параметры расположены на вкладке Данные (Data) в разделе Исследовать (Explore).
¶ 5.15.2. Простой точечный график (без измерений)
Пример простого точечного графика, показывающий изменение одной метрики с течением времени:
Значения в Исследовать (Explore), используемые для создания такого графика:
 |
Временная ось X:
|
 |
Изменяющиеся во времени метрики по оси Y:
|
|
Сгенерированный SQL-запрос |
¶ 5.15.3. Точечный график (с измерениями)
Пример графика, аналогичный приведённому выше, но с добавленным измерением:
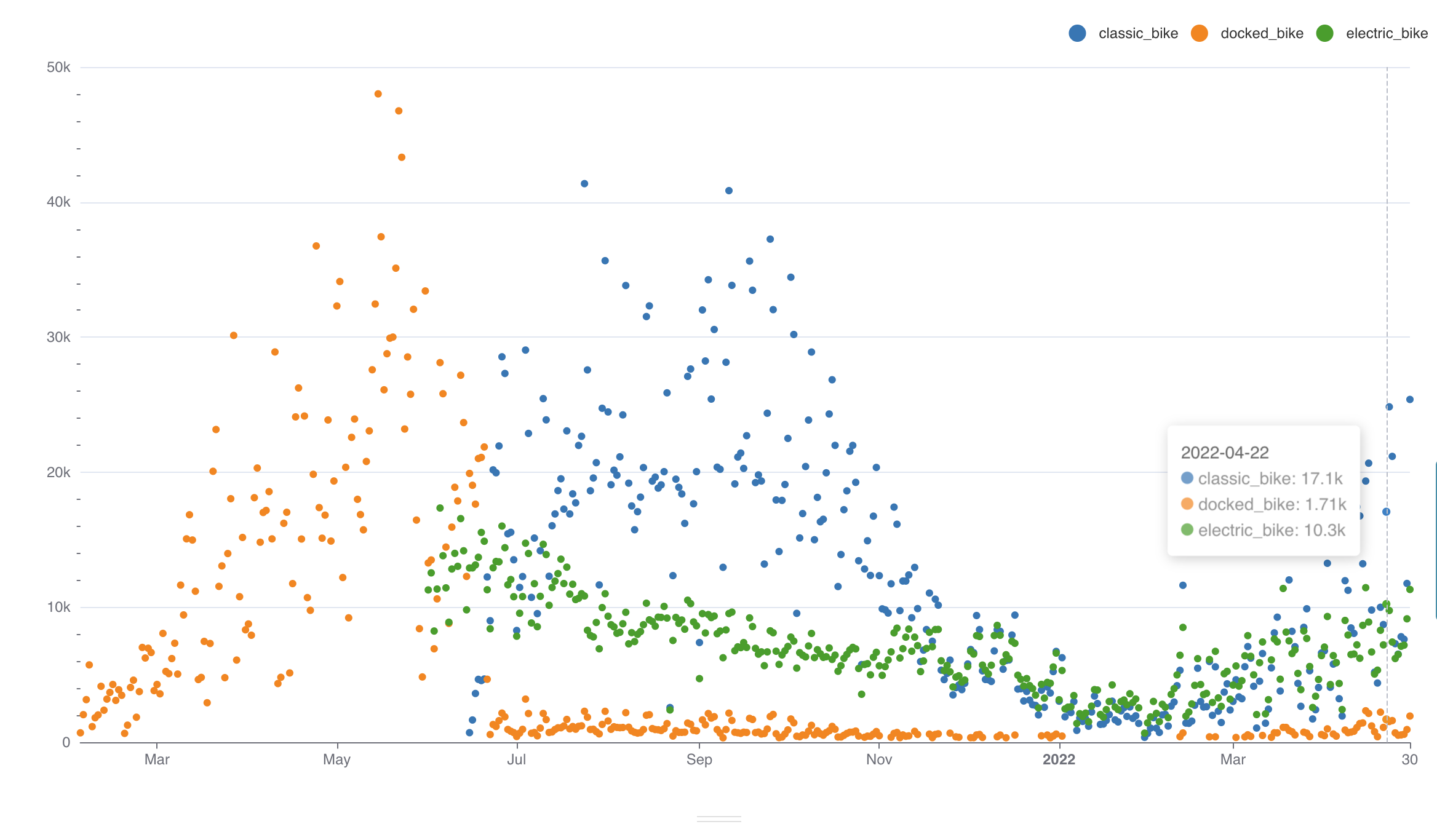
Чтобы создать такой график, использованы те же выборки из первого графика, но добавлены следующие дополнительные выборки:
 |
Измерения (Dimensions):
|
|
Сгенерированный SQL-запрос |
¶ 5.15.4. Расширенная аналитика
Как и большинство визуализаций временных рядов в RT.DataVision, график с областями временных рядов поддерживает функции расширенной аналитики.
¶ 5.16. Плавные линии (Smooth Line)
Плавные линии (Smooth Line) превосходно демонстрирует изменения во времени, особенно для непрерывных значений. Примеры графиков:
¶ 5.16.1. Создание плавного линейного графика временных рядов
Для создания плавного графика временных рядов необходимо определить следующие значения:
- Столбец, используемый в качестве временной оси X;
- Метрики, визуализируемые на оси Y;
- Столбцы для группировки/классификации метрик.
Все параметры расположены на вкладке Данные (Data) в разделе Исследовать (Explore).
¶ 5.16.2. Простой плавный график (без измерений)
Пример простого плавного графика, показывающий изменение одной метрики с течением времени:
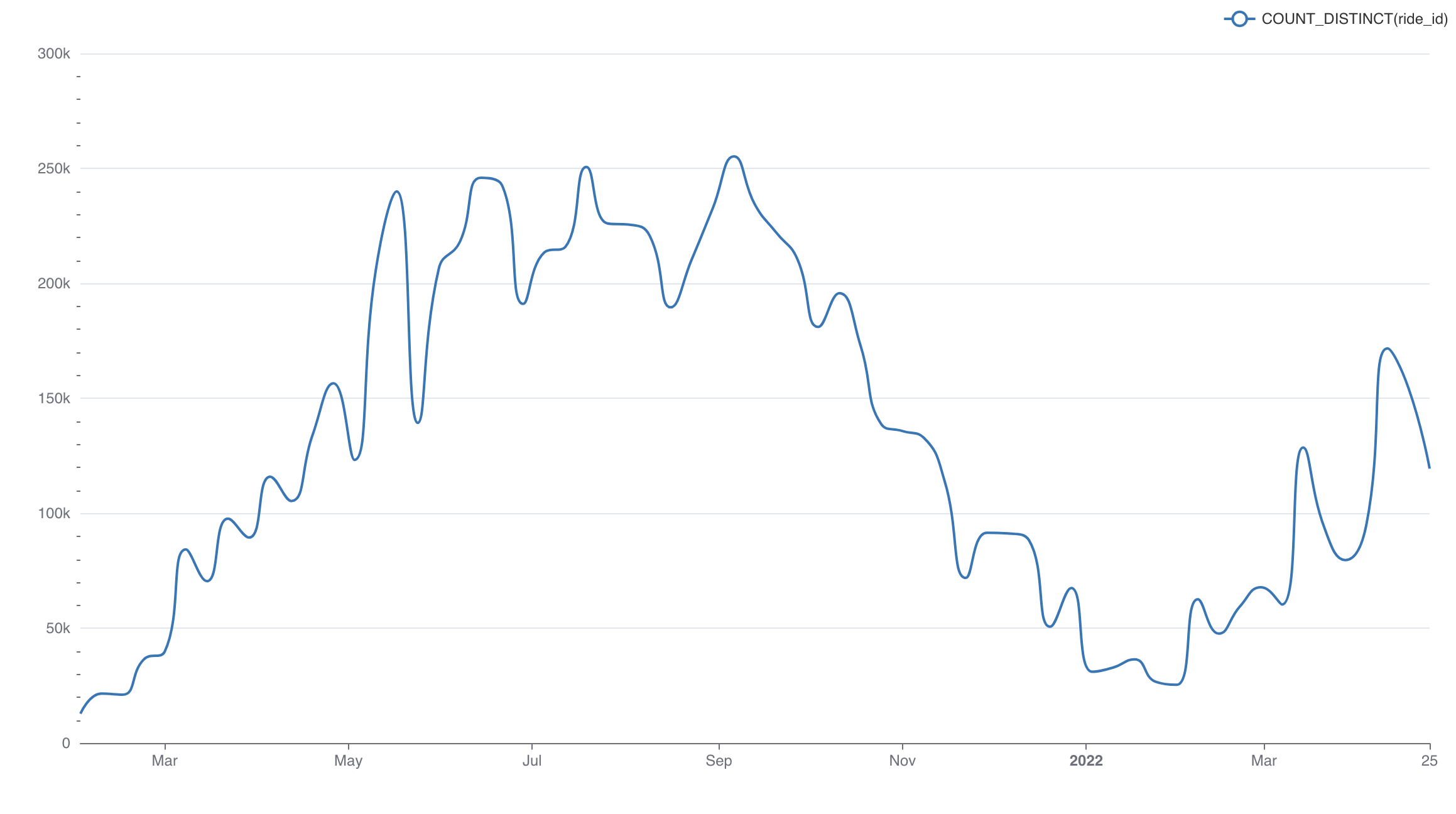
Значения в Исследовать (Explore), используемые для создания такого графика:
 |
Временная ось X:
|
 |
Изменяющиеся во времени метрики по оси Y:
|
|
Сгенерированный SQL-запрос |
¶ 5.16.3. Гладкий линейный график (с измерениями)
Пример графика, аналогичный приведённому выше, но с добавленным измерением:
Чтобы создать такой график, использованы те же выборки из первого графика, но добавлены следующие дополнительные выборки:
|
|
Измерения (Dimensions):
|
|
Сгенерированный SQL-запрос |
¶ 5.16.4. Расширенная аналитика
Как и большинство визуализаций временных рядов в RT.DataVision, график с областями временных рядов поддерживает функции расширенной аналитики.
¶ 5.17. Ступенчатый график (Stepped Line)
Ступенчатый график (Stepped Line) превосходно демонстрирует изменения во времени, особенно для непрерывных значений. Примеры графиков:
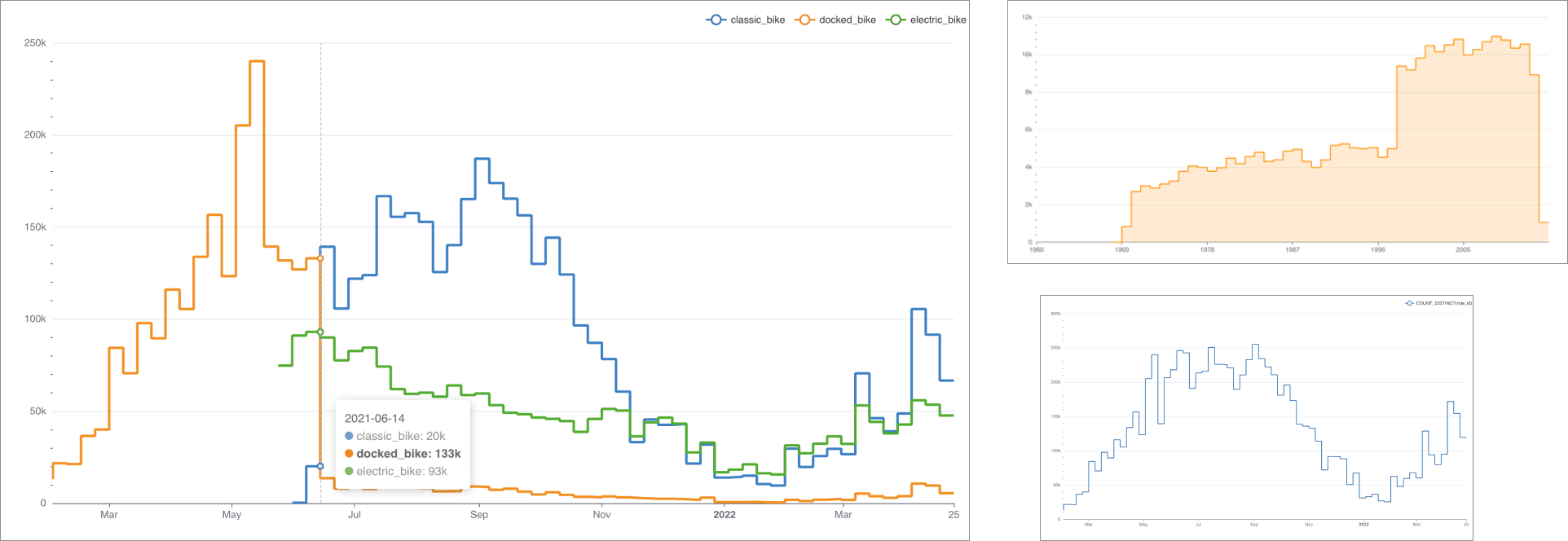
¶ 5.17.1. Создание ступенчатого графика
Для создания ступенчатого графика необходимо определить следующие значения:
- Столбец, используемый в качестве временной оси X;
- Метрики, визуализируемые на оси Y;
- Столбцы для группировки/классификации метрик.
Все параметры расположены на вкладке Данные (Data) в разделе Исследовать (Explore).
¶ 5.17.2. Простой ступенчатый график (без измерений)
Пример простого ступенчатого графика, показывающий изменение одной метрики с течением времени:
Значения в Исследовать (Explore), используемые для создания такого графика:
|
|
Временная ось X:
|
|
|
Изменяющиеся во времени метрики по оси Y:
|
|
Сгенерированный SQL-запрос |
¶ 5.17.3. Ступенчатый линейный график (с измерениями)
Пример графика, аналогичный приведённому выше, но с добавленным измерением.
Чтобы создать такой график, использованы те же выборки из первого графика, но добавлены следующие дополнительные выборки:
|
|
Измерения (Dimensions):
|
|
Сгенерированный SQL-запрос |
¶ 5.17.4. Расширенная аналитика
Как и большинство визуализаций временных рядов в RT.DataVision, график с областями временных рядов поддерживает функции расширенной аналитики.
¶ 5.18. Таблица (Table Chart)
Таблица (Table Chart) позволяет формировать графики в виде таблиц, которые схожи с таблицами в базах данных. Этот тип визуализации отлично подходит для демонстрации сырых и агрегированных данных в знакомом формате. Примеры графиков:
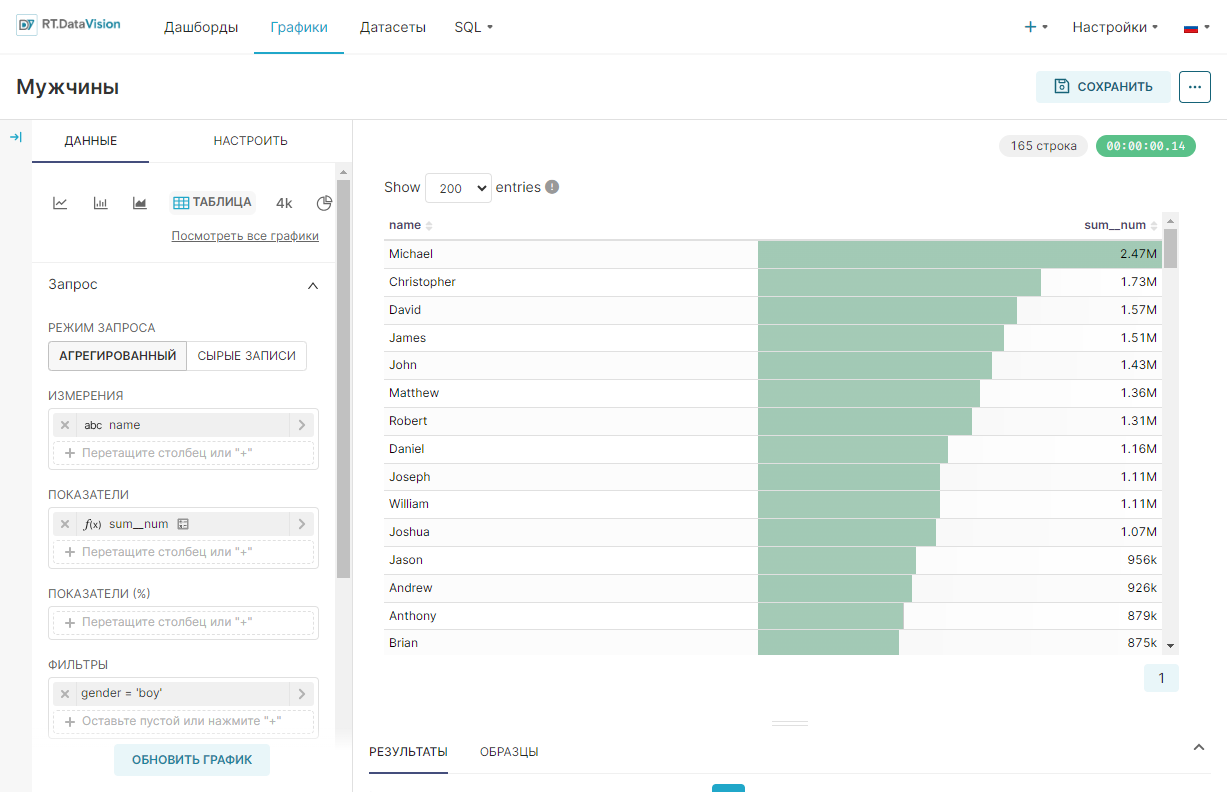
¶ 5.18.1. Общая информация
¶ 5.18.1.1. Типы таблиц
При создании графика можно увидеть несколько разных типов таблиц:
- Таблица (Table);
- Сводная таблица (Pivot Table);
- Таблица временных рядов (Time-series Table);
- Pivot Table (legacy).
В этом разделе рассмотрен классический типе визуализации Таблица (Table).
¶ 5.18.1.2. Агрегированные или сырые данные
Тип визуализации Таблица (Table) позволяет либо продемонстрировать сырые данные непосредственно из базы данных, либо с применением агрегации. Для этого на вкладке Данные (Data) имеется переключатель Режим запроса (Query Mode), который устанавливается в режим Агрегированный (Aggregate) или Сырые записи (Raw Records).
¶ 5.18.2. Создание таблицы из сырых данных
Следующий пример представляет собой таблицу, которая демонстрирует 10 строк и 3 определённых столбцов из базовой таблицы birth_names в базе данных:
Для формирования графика достаточно указать значения в поле Столбцы (Columns). Значения в Исследовать (Explore), используемые для создания такого графика:
 |
Параметры Исследовать (Explore):
|
|
Сгенерированный SQL-запрос:
|
¶ 5.18.3. Создание таблицы из агрегированных данных
В качестве альтернативы можно применять агрегатные функции к своим данным, чтобы вместо сырых данных отображать агрегированные значения в таблице. Пример графика с агрегированными значениями:
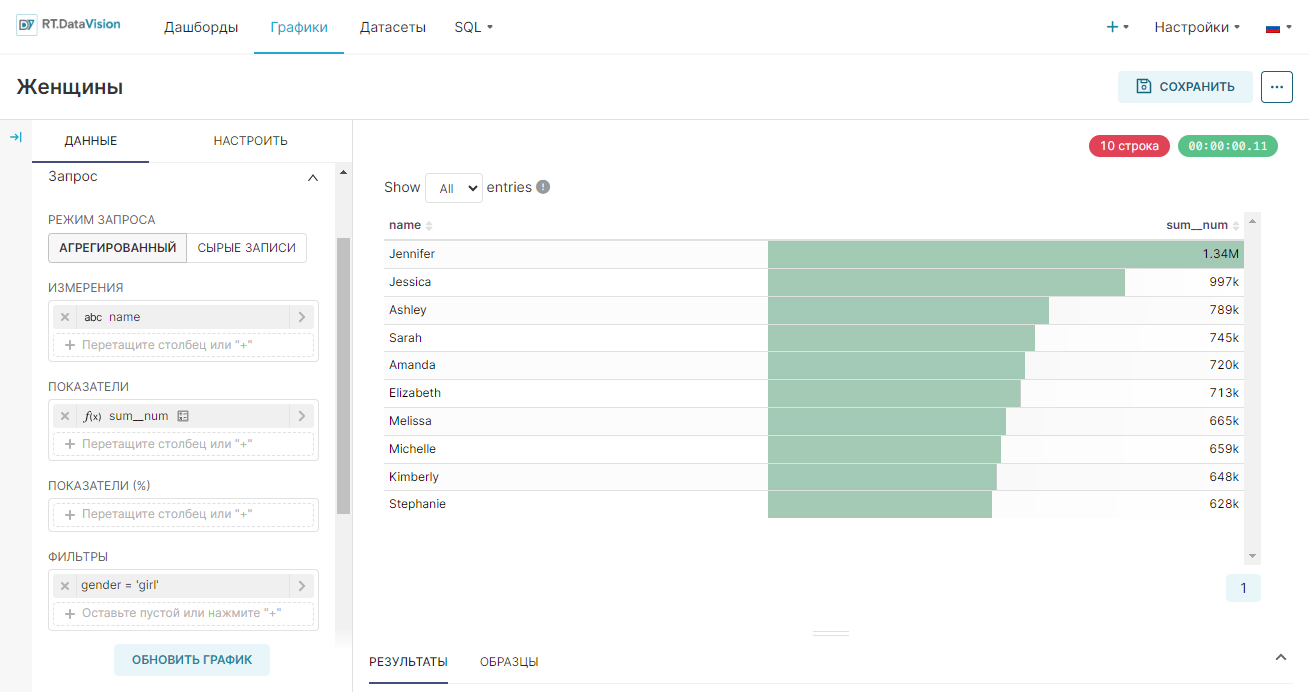
Кроме изменения Режим запроса (Query Mode) на Агрегированный (Aggregate), также необходимо указать Измерения (Dimensions) и Показатели (Metrics).
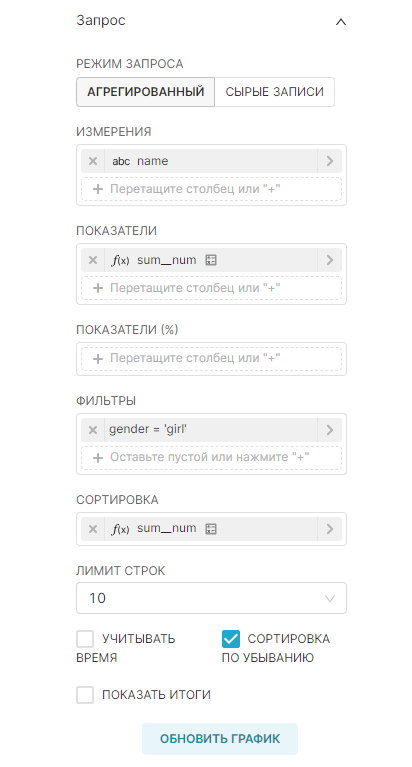 |
Параметры Исследовать (Explore):
|
|
Сгенерированный SQL-запрос:
|
¶ 5.18.4. Настройка таблицы
Можно дополнительно визуально адаптировать график, используя следующие параметры на вкладке Настроить (Customize):
- Формат метки времени (Timestamp Format) — выберите необходимый формат D3 для отметок даты и времени или Адаптивное форматирование (Adaptive Formatting);
- Окно поиска (Search Box) — установите флажок, если необходимо отображение строки поиска для пользователя;
- Заполнение ячейки (Cell Bars) — установите флажок, чтобы в ячейках таблицы с числовыми значениями метрик отображались столбцы гистограммы (т.е. будут затенены величиной значения). Если флажок не установлен, то метрики отображаются просто числом. Существует возможность изменить цвета столбцов ячеек с помощью собственного CSS:
- Перейдите к необходимому дашборду;
- Щёлкните Редактирование дашборда (Edit Dashboard);
- Щёлкните (...) и выберите Редактировать CSS (Edit CSS);
- Измените цвет фона класса .cell-bar — чтобы применить разные цвета для положительных и отрицательных столбцов, используйте .cell-bar.positive и .cell-bar.negative.
.cell-bar {
background: red;
opacity: 50%;
}
- Выравнивание +/- (Align +\-) — установите флажок, если необходимо выравнивать фоновый график как с положительными, так и с отрицательными значениями на 0;
- Цвет +\- (Color +\-) — установите флажок, чтобы ячейки с числами окрашивались в разные цвета для положительных и отрицательных значений;
- Разрешить перестановку столбцов (Allow Columns to be Rearranged) — установите флажок, чтобы позволить пользователю перетаскивать заголовки таблицы, для изменения порядка столбцов в таблице. Данная установка не повлияет на порядок столбцов при повторном открытии графика пользователем;
- Настройте столбцы (Customize Columns) — настройте дополнительные параметры отображения каждого столбца в таблице: ширина столбца и выравнивание текста;
- Условное форматирование (Conditional Formatting) — установите условное цветовое форматирование для числовых столбцов, например, как показано ниже:
¶ 5.19. Древовидная диаграмма (Treemap)
Древовидная диаграмма (Treemap) использует масштабированные прямоугольники для визуализации одной и той же метрики в нескольких разных группах. Существует возможность дополнительно разбить по слоям свою древовидную карту и добавить иерархию, используя столбец измерения. Примеры графиков:
¶ 5.19.1. Создание базовой древовидной карты
В настоящее время RT.DataVision предлагает несколько типов древовидных карт при их создании:
- Древовидная диаграмма (Treemap);
- Treemap (legacy).
Рекомендуется использовать тип визуализации Древовидная диаграмма (Treemap), так как он более новый и поддерживает больше функций.
Для создания древовидной карты необходимо определить:
- Метрики, которые необходимо визуализировать в виде прямоугольников;
- Измерения, которые необходимо использовать для разделения.
Пример простой древовидной карты:
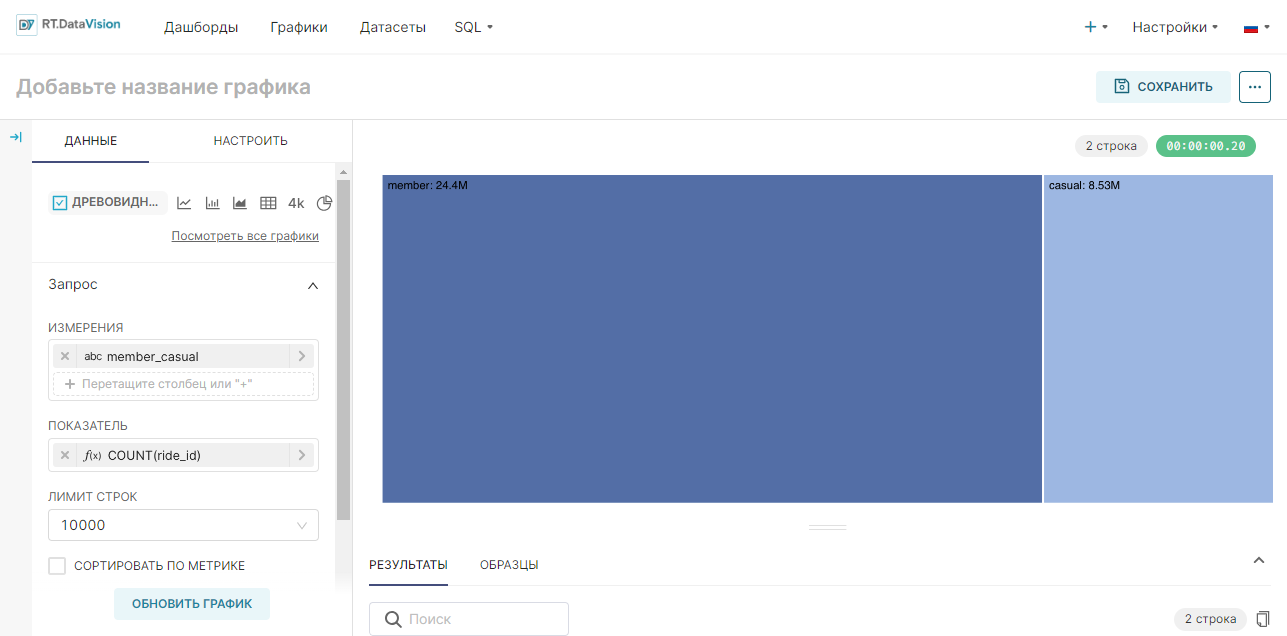
Значения в Исследовать (Explore), используемые для создания такого графика:
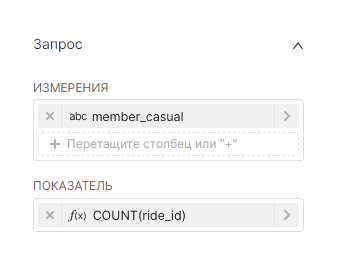 |
Параметры в Исследовать (Explore):
|
|
Сгенерированный SQL-запрос |
¶ 5.19.2. Создание иерархической древовидной карты
Существует возможность добавить слои иерархии в древовидную карту, выбрав несколько столбцов измерения. Пример графика:
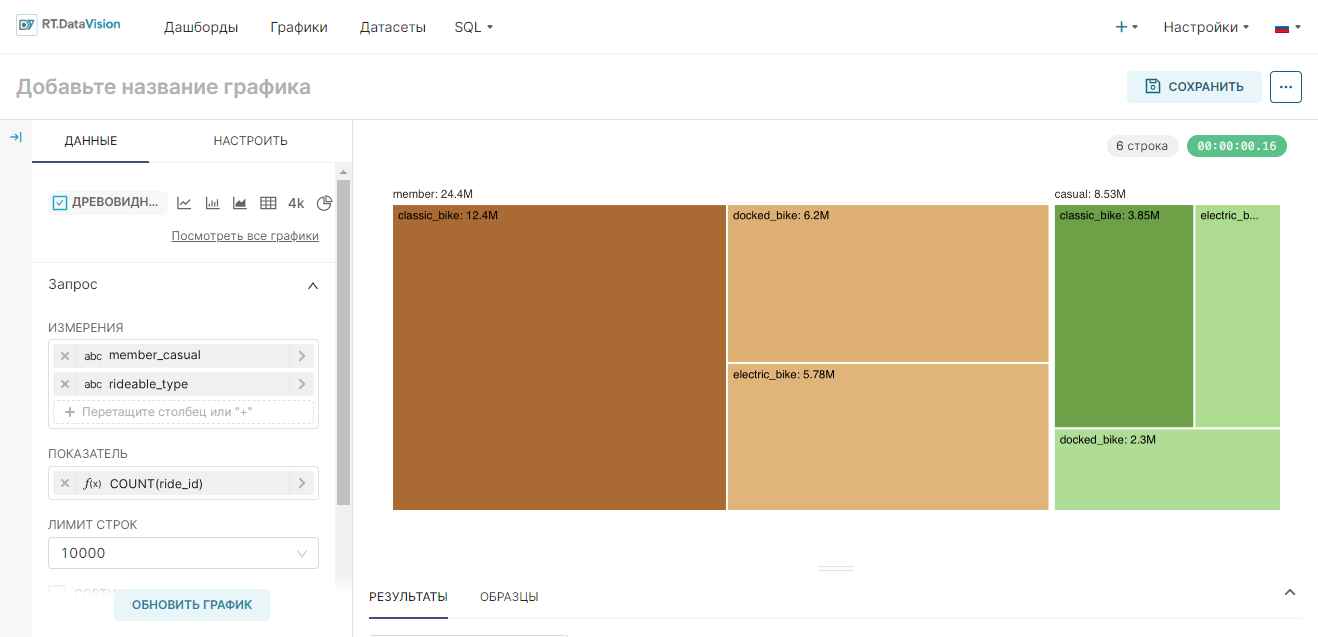
Значения в Исследовать (Explore), используемые для создания такого графика:
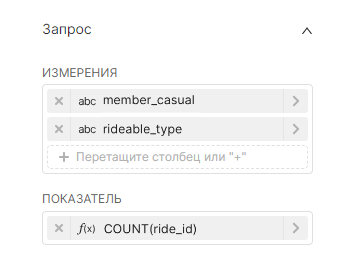 |
Параметры в Исследовать (Explore):
|
|
Сгенерированный SQL-запрос |
¶ 5.19.3. Настройка древовидной карты
Можно дополнительно визуально адаптировать график, используя следующие параметры на вкладке Настроить (Customize):
- Цветовая схема (Color Scheme) — выберите цветовую палитру, которую необходимо использовать в своём графике;
- Метки (Labels):
- Показать метки (Show Labels) — флажок, регулирующий отображение значений метрик в виде меток;
- Показать верхние метки (Show Upper Labels) — флажок, регулирующий отображение меток родительских квадратов в иерархической древовидной карте;
- Формат числа (Number Format) — в каком формате необходимо отображать числа;
- Формат даты (Date Format) — в каком формате необходимо отображать даты.
¶ 5.20 Диаграмма Waterfall (Waterfall Chart, каскадная диаграмма, бридж)
Диаграмма Waterfall (Waterfall Chart) — это тип диаграммы в RT.DataVision, позволяющий отображать постепенное изменение показателя в количественном выражении под влиянием положительных и отрицательных факторов. Также этот вид диаграмм называют "каскадной диаграммой" или "бриджем". Диаграмму Waterfall (Waterfall Chart) можно использовать для аналитики, включая анализ акций и эффективности инвестиций, поскольку она визуализирует последовательные изменения показателя, показывая влияние различных факторов на итоговое значение.
Диаграмма Waterfall (Waterfall Chart) часто используется для финансового анализа, оценки инвестиций, анализа отклонений бюджета.
¶ 5.20.1 Примеры использования Диаграммы Waterfall (Waterfall Chart)
Диаграмму Waterfall (Waterfall Chart) можно применять для:
- План-факт анализа финансовых показателей.
- Факторного анализа отклонений бюджета.
- Оценки динамики изменений выручки или прибыли по месяцам.
- Визуализации влияния отдельных факторов на итоговый результат.
Например, при анализе финансового результата можно отобразить влияние отдельных факторов, таких как изменения цен, объемов продаж и операционных расходов, на итоговую прибыль.
¶ 5.20.2 Пример Диаграммы Waterfall (Waterfall Chart)
Для примера рассмотрим диаграмму, которая показывает влияние стажа сотрудников на оплату труда. Столбцы диаграммы складываются или вычитаются последовательно, что помогает увидеть вклад каждой категории в общий показатель.
В данном примере:
- Размер (Dimension) — отдел (department).
- Нарушения (Breakdowns) — пол (gender).
- Показатель (Metric) — сумма зарплат сотрудников, при этом зарплаты сотрудников с опытом менее 5 лет учитываются со знаком "минус".
SUM(CASE WHEN experience < 5 THEN -salary ELSE salary END)
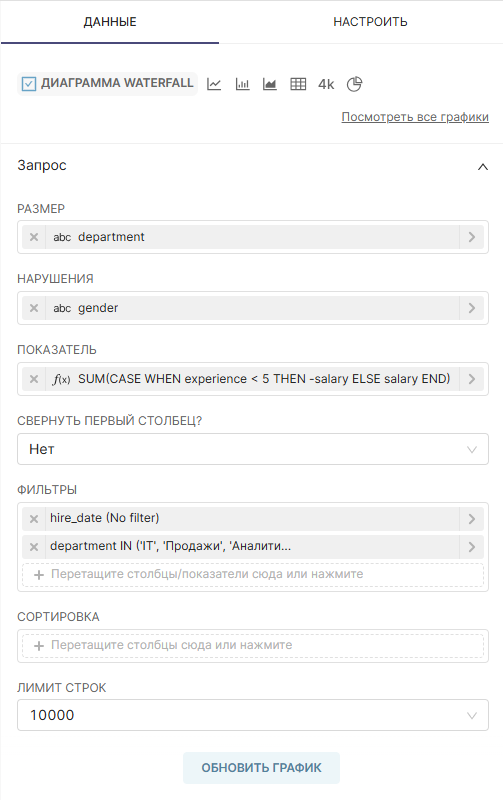
Таким образом, SQL-запрос в поле Показатель (Metric) помогает выделить влияние сотрудников с разным уровнем опыта на общий фонд оплаты труда:
- Если в каком-то отделе преобладают сотрудники с небольшим опытом (<5 лет), то их зарплаты будут уменьшать итоговую сумму.
- Если в отделе больше опытных сотрудников (≥5 лет), их зарплаты будут увеличивать итоговую сумму.
В результате диаграмма показывает не просто общие зарплаты, а баланс между опытными и менее опытными сотрудниками.
Как читать диаграмму:
- Первый столбец в группе каждого отдела представляет зарплаты женщин (Ж) и может быть направлен вверх (если сотрудники с опытом ≥5 лет) или вниз (если <5 лет).
- Следующий столбец — зарплаты мужчин (М), которые также могут увеличивать или уменьшать суммарное значение.
- Итоговый столбец отдела (жёлтый) показывает общую сумму зарплат, полученную после сложения и вычитания предыдущих значений.
- Ось X представляет отделы и пол сотрудника, ось Y — значения зарплат.
- Общая сумма зарплат формируется последовательно: итог одного отдела становится отправной точкой для следующего.
Примеры интерпретации данных:
- В отделе Аналитика зарплата мужчин добавляет 137k, затем зарплата женщин увеличивает сумму ещё на 230k, в результате общий итог для отдела — 367k.
- В отделе Продажи к уже накопленной сумме 367k добавляется зарплата мужчин 156k, но затем вычитается зарплата женщин -94k. В результате общий итог для отдела Продажи — 429k.
- В отделе IT к накопленной сумме 429k добавляется зарплата мужчин 683k, затем зарплаты женщин 148k, и в результате общий итог — 1.26M.
Таким образом, каждый столбец вносит свой вклад в итоговую сумму отдела, а диаграмма позволяет наглядно оценить, какие факторы (пол, опыт работы) оказывают большее влияние на общий фонд заработной платы.
¶ 5.20.3 Создание диаграммы Waterfall (Waterfall Chart)
Для создания новой диаграммы Waterfall (Waterfall Chart):
1. На верхней панели интерфейса RT.DataVision выберите раздел Графики (Chart).
2. Нажмите кнопку + График (+ Chart).
3. Выберите необходимый датасет, содержащий данные для построения диаграммы в поле Выберите датасет (Choose a Dataset).
4. Выберите тип визуализации Диаграмма Waterfall (Waterfall Chart) в разделе Выберите тип графика (Choose Chart Type).
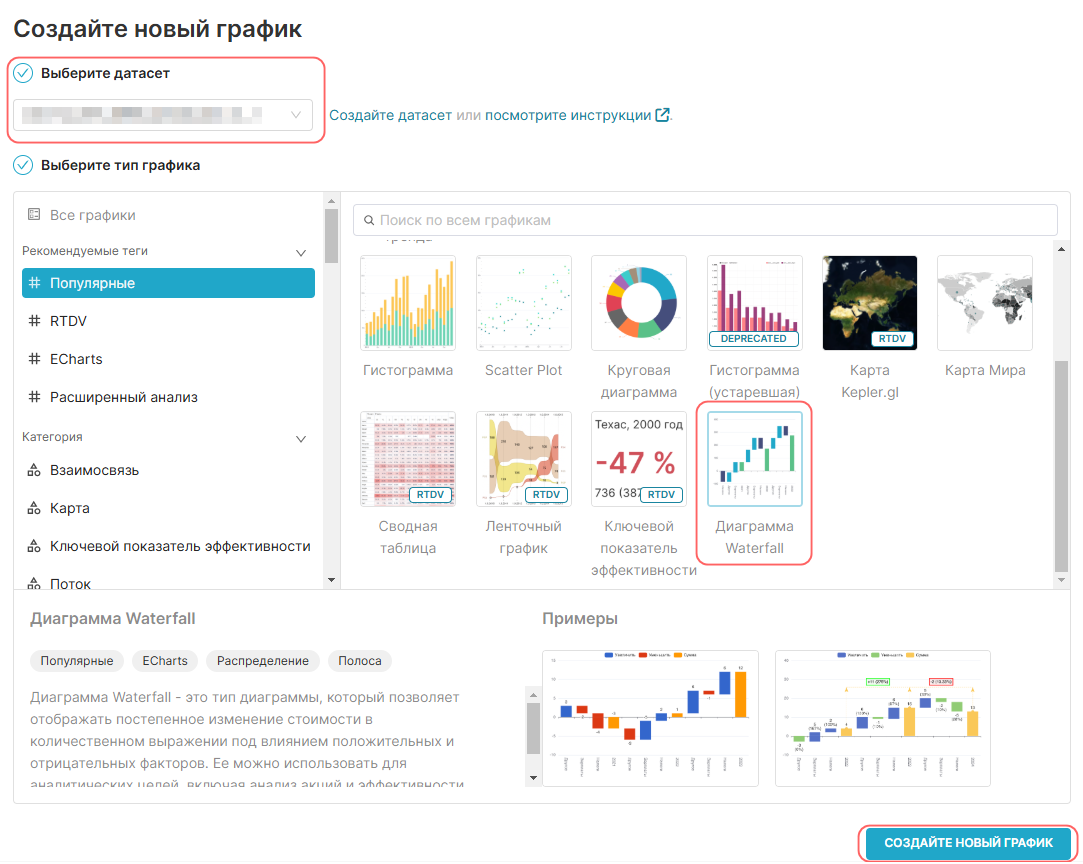
5. Нажмите кнопку Создайте новый график (Create a new chart).
6. Настройте необходимые параметры диаграммы на вкладке Данные (Data):
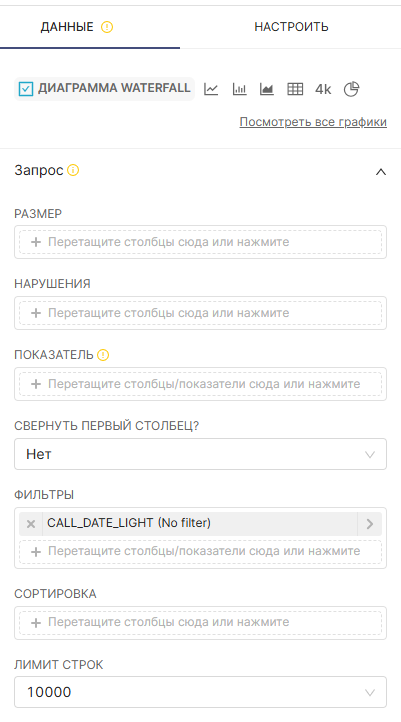
- Размер (Dimension) — задаёт основную категорию группировки данных. Например, если анализируется выручка по регионам, в качестве размера можно выбрать Регион.
- Нарушения (Breakdowns) — определяет детализацию данных внутри каждой группы. Например, если размер — Регион, можно разбить данные по Продуктам.
- Показатель (Metric) — определяет числовое значение для отображения. Например, Выручка, Количество заказов. Можно использовать агрегирование, например, Сумма продаж.
- Свернуть первый столбец? (Collapse first series?) — выберите Нет, если первый столбец имеет ненулевое значение, например, плановый показатель. Если первый столбец должен начинаться с нуля, выберите Да.
- Фильтры (Filters) — позволяют отобрать нужные данные, например, отфильтровать только продажи за определённый период или только по определённым регионам.
- Сортировка (Sort by) — задаёт порядок отображения столбцов, например, по убыванию выручки или по дате.
7. Настройте необходимые параметры диаграммы на вкладке Настроить (Customize):
- Цветовая схема (Color Scheme) — настройка цветов для элементов диаграммы.
- Показать разницу между столбцами (Show difference between bars) — включение отображения разницы между соседними столбцами. Если включено, между соседними столбцами отображается разница значений, что помогает анализировать изменения.
- Показать разницу между итоговыми значениями (Show difference between totals) — отображение разницы между начальным и конечным значением. Если включено, отображается разница между начальным и конечным значением, например, между выручкой в начале и конце периода.
- Показать значение (Show Value) — включение подписей значений на графике. Если включено, над столбцами диаграммы отображаются их числовые значения.
- Показать легенду (Show legend) — отображение легенды диаграммы.
- Насыщенная всплывающая подсказка (Rich tooltip) — отображение списка всех серий при наведении.
- Ось X (X Axis):
- Метка оси X (X Axis Label) — укажите название оси X, например, Периоды или Регион.
- X Расположение галочек (X Tick Layout) — выберите один из вариантов расположения подписей столбцов:
- auto — автоматическое расположение.
- flat — горизонтальные подписи.
- 45° — наклонные подписи под углом 45 градусов.
- 90° — вертикальные подписи.
- staggered — чередующееся расположение подписей.
- Ось Y (Y Axis):
- Метка оси Y (Y Axis Label) — укажите название оси Y, например, Выручка или Затраты.
- Отформатировать разные цифры итога (Format total`s diffrent numbers)— выберите способ отображения итоговых значений, например, в формате валюты или процентов.
- Формат оси Y (Y Axis Format) — выберите вариант форматирования чисел оси Y.
- Границы оси Y (Y Axis Bounds) — задайте минимальное и максимальное значение оси Y, например, от 0 до 100000 для отображения продаж в рублях.
8. Нажмите Создать диаграмму (Create chart) для её отображения.
Диаграмма Waterfall (Waterfall Chart) в RT.DataVision поддерживает несколько режимов отображения. Данные могут визуализироваться за один или несколько периодов, что удобно для анализа динамики изменений.
Итоговые столбцы уменьшаются для лучшего восприятия. Масштаб оси Y не обязательно начинать с нуля — при необходимости он корректируется для акцентирования небольших колебаний.
Столбцы диаграммы сортируются по выбранному полю, а разница между уровнями значений отображается отдельно, что помогает выявлять тенденции.
¶ 5.20.4 Дополнительные пояснения по Waterfall Chart
Первый столбец может отображать плановое или начальное значение показателя, последний — его фактическое или конечное значение.
Промежуточные столбцы представляют количественные (или стоимостные) значения факторов, оказывающих влияние на показатель.
Промежуточные столбы могут быть с отрицательным значением, если отображаемый фактор оказал убыточное влияние, либо с положительным, если влияние было прибыльным.
¶ 6. Создание дашборда
Дашборды — это мощные средства визуализации, позволяющие убедительно отображать факты, демонстрировать изменения ключевых показателей эффективности в различных сценариях, согласовывать бизнес-инициативы с визуальными метриками, основанными на данных.
В этом разделе описываются следующие действия с дашбордами:
- Добавление и удаление графиков на/из дашбордов;
- Настройка дашбордов с помощью CSS;
- Просмотр базового SQL-кода графика;
- Редактирование свойств дашбордов, например владельцев;
- Предоставление доступа к графикам и дашбордам.
¶ 6.1. Общая информация
¶ 6.1.1. Добавление графика на дашборд
Существует несколько способов добавления графика на дашборд:
- При сохранении графика;
- При редактировании дашборда;
- При создании нового графика из пустого дашборда.
¶ 6.1.1.1. При сохранении графика
Для добавления графика на дашборд при сохранении графика:
1. Выберите выберите Сохранить (Save) на странице просмотра графика .

2. Укажите или измените название графика в поле Название графика (Chart Name) в открывшемся окне Сохранить график (Save chart).
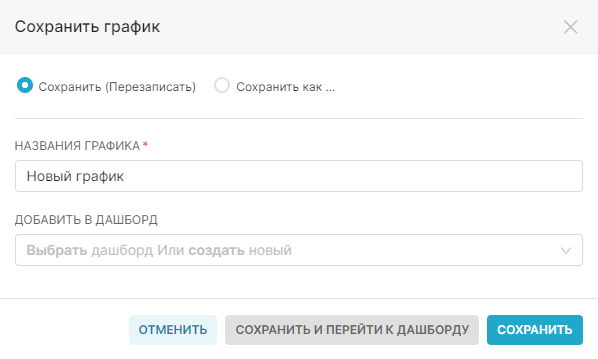
3. Заполните в поле Добавить в дашборд (Add to dashboard):
- Для добавления графика в новый дашборд укажите название дашборда, который необходимо создать, в поле Добавить в дашборд (Add to dashboard).
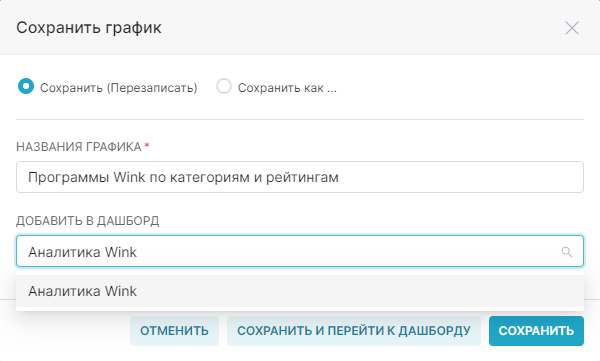
- Для добавления графика в уже существующий дашборд выберите необходимый дашборд из выпадающего списка в поле Добавить в дашборд (Add to dashboard).
4. Нажмите кнопку Сохранить (Save) или Сохранить и перейти к дашборду (Save & go to dashboard) для перехода к указанному дашборду.
¶ 6.1.1.2. При редактировании дашборда
Для добавления графика на дашборд при редактировании дашборда:
1. Перейдите в раздел Дашборды (Dashboard).
2. Выберите необходимый дашборд и нажмите кнопку Редактирование Дашборда (Edit dashboard).
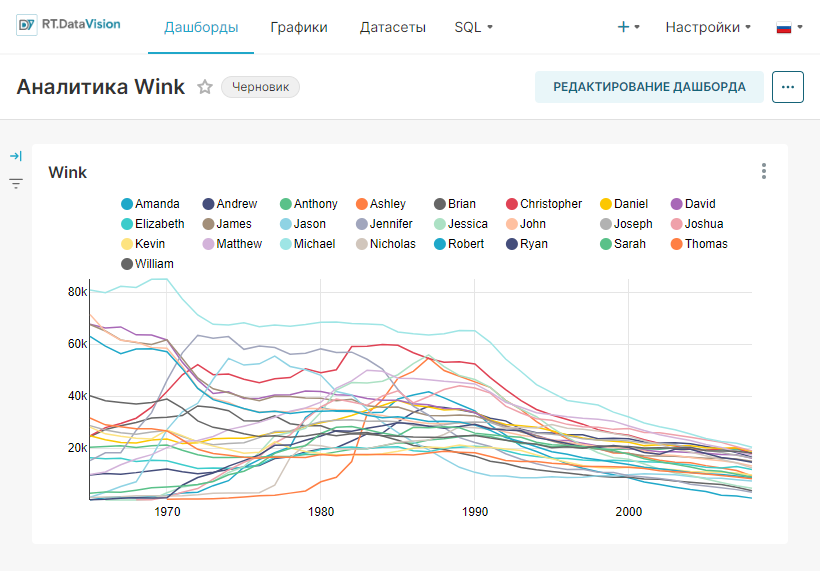
3. Выберите вкладку Графики (Chart). Вкладка Графики (Chart) содержит список всех доступных графиков (которые вы создали или к которым у вас есть доступ, т.е. член вашей команды предоставил общий доступ к своему графику).
4. Перетащите карточку с графиком в свободное место на дашборде для добавления.
¶ 6.1.1.3. Создание нового графика из пустого дашборда
¶ 6.1.1.3.1. При создании нового дашборда
Для добавления нового графика на дашборд при создании дашборда:
1. Перейдите в раздел Дашборды (Dashboard).
2. Нажмите кнопку +Дашборд (+Dashboard).
3. Нажмите кнопку + Создайте новый график (Create a new chart).
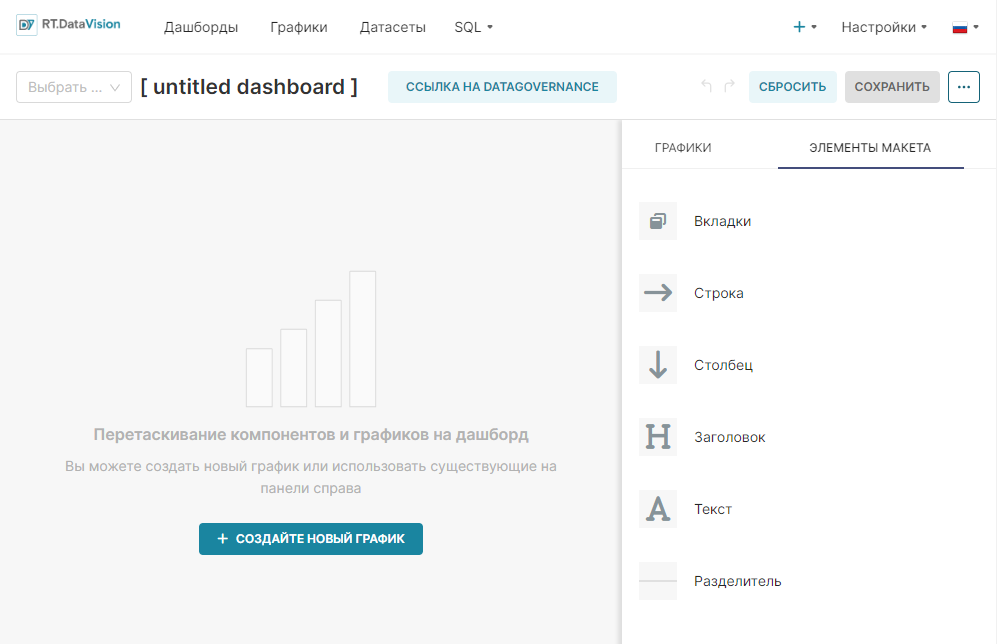
4. Приступите к процессу создания нового графика (см. раздел Создание графиков).
¶ 6.1.1.3.2. При загрузке пустого дашборда
Для добавления нового графика на пустой дашборд.
1. Перейдите в раздел Дашборды (Dashboard).
2. Выберите пустой дашборд.
3. Нажмите кнопку Редактирование Дашборда (Edit dashboard).
4. Нажмите кнопку + Создайте новый график (Create a new chart).
4. Приступите к процессу создания нового графика (см. раздел Создание графиков).
¶ 6.1.2. Удаление графика
Для удаления графика из дашборда:
1. Перейдите в раздел Дашборды (Dashboard).
2. Выберите необходимый дашборд и нажмите кнопку Редактирование Дашборда (Edit dashboard).
3. Нажмите на значок корзины в правом верхнем углу графика, который необходимо удалить.
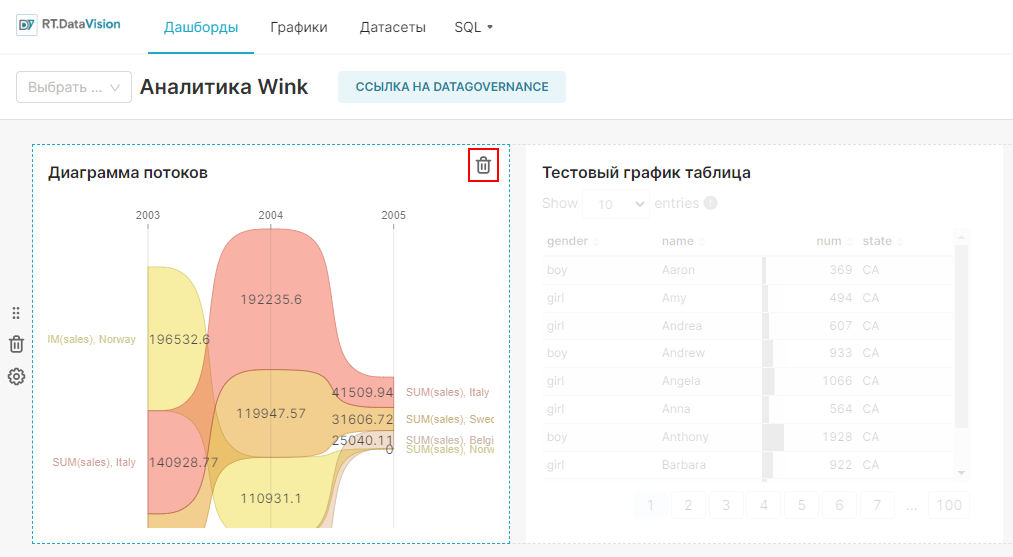
Для удаления всей строки графиков, нажмите на значок корзины в крайней левой части строки.
Примечание. Выбор значка корзины просто удаляет график(-и) с дашборда, но не из RT.DataVision.
¶ 6.1.3. Параметры дашборда
¶ 6.1.3.1. Через режим редактирования
Нажмите значок с многоточием (…) в режиме редактирования, чтобы просмотреть следующие параметры:
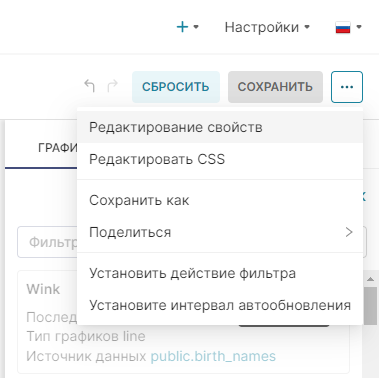
- Редактирование свойств (Edit dashboard properties) – открывает окно редактирования свойств дашборда;
- Редактировать CSS (Edit CSS) – загружает Live CSS Editor, который можно использовать для внесения специальных изменений в таблицу стилей в среде редактирования в реальном времени (т.е. изменения, применяемые в режиме реального времени);
- Сохранить как (Save as) – сохраняет дашборд в файле с другим именем;
- Поделиться (Share):
- Скопировать ссылку на дашборд (Copy permalink to clipboard) – копирует ссылку на общий дашборд в буфер обмена системы;
- Поделиться по электронной почте (Share permalink by email) – запускает клиент электронной почты по умолчанию в системе и составляет новое сообщение с указанием URL-адреса вашего дашборда;
- Установить действие фильтра (Set filter mapping) — включает настройку областей фильтра;
- Установить интервал автообновления (Set auto-refresh interval) — регулирует частоту автоматического обновления дашборда. Возможные варианты включают секунды (10 или 30), минуты (1, 5 или 30) или часы (1, 6, 12 или 24).
Примечание. Частота обновления будет применяться только к текущему сеансу. Если вместо этого необходимо установить постоянное автоматическое обновление, то потребуется изменить JSON Metadata в Dashboard properties. Для этого установите значение (в секундах) для параметра refresh_frequency (значение по умолчанию — 0). Например, для частоты обновления 1 час, установите значение параметра 3600.
¶ 6.1.3.2. Через экран Dashboards
Дополнительные параметры, доступные на экране Дашборды (Dashboard), включают:
- Обновить дашборд (Refresh dashboard) — обновляет все графики дашборда (т.е. получает все данные);
- Полноэкранный режим (Enter fullscreen) — перезагружает дашборд в полноэкранном режиме, т.е. без верхней панели инструментов. Повторно выберите Полноэкранный режим (Enter fullscreen), чтобы вернуться к виду по умолчанию;
- Сохранить как (Save as) – сохраняет дашборд в файле с другим именем;
- Сохранить как изображение (Download as image) – загружает изображение всего дашборда в формате JPEG;
- Экспорт в .PDF (Export to .PDF) – загружает данные графика в вашу систему в формате PDF;
- Поделиться (Share):
- Скопировать ссылку на дашборд (Copy permalink to clipboard) – копирует ссылку на общий дашборд в буфер обмена системы;
- Поделиться по электронной почте (Share permalink by email) – запускает клиент электронной почты по умолчанию в системе и составляет новое сообщение с указанием URL-адреса вашего дашборда;
- Встраивание дашборда (Embed dashboard)— позволяет настроить дашборд для отображения во внешнем веб-приложении;
- Настройте отчет по электронной почте (Set up an email report) – открывает окно планирования новой рассылки отчета по электронной почте;
- Установить интервал автообновления (Set auto-refresh interval) — регулирует частоту автоматического обновления дашборда. Возможные варианты включают секунды (10 или 30), минуты (1, 5 или 30) или часы (1, 6, 12 или 24).
Примечание. Частота обновления будет применяться только к текущему сеансу. Если вместо этого необходимо установить постоянное автоматическое обновление, то потребуется изменить JSON Metadata в Dashboard properties. Для этого установите значение (в секундах) для параметра refresh_frequency (значение по умолчанию — 0). Например, для частоты обновления 1 час, установите значение параметра 3600.
¶ 6.1.4. Изменение свойств дашборда
Для изменения свойств дашборда:
1. Перейдите в режим редактирования дашборда.
2. Нажмите на значок с многоточием (…) и выберите Редактирование свойств (Edit dashboard properties).
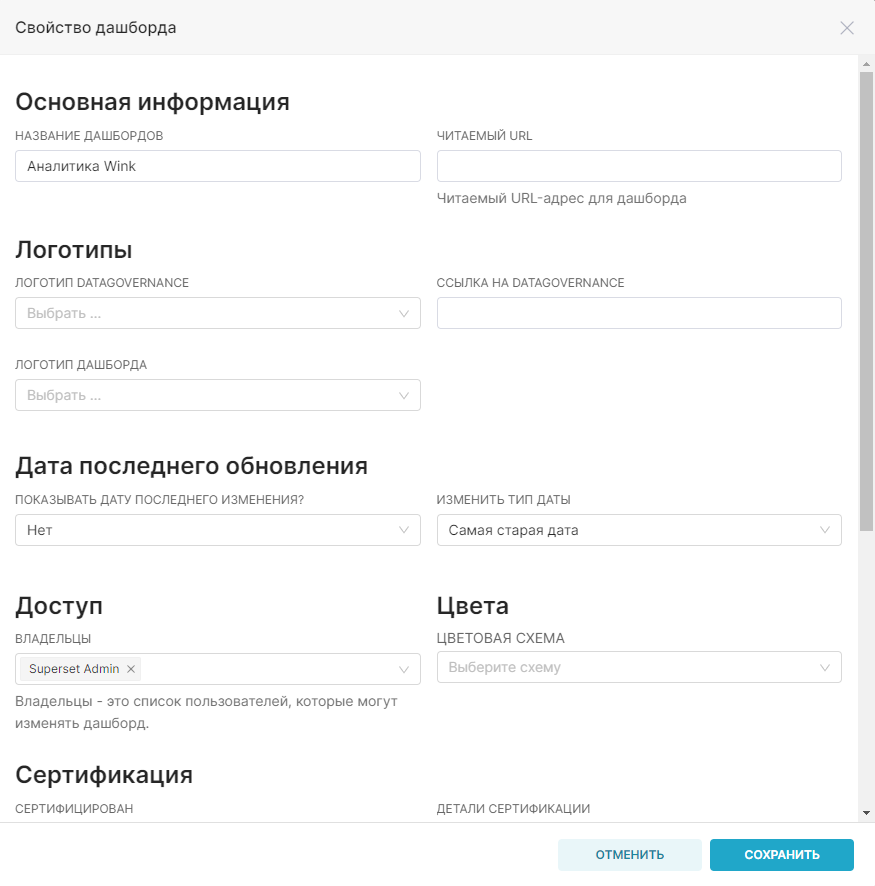
В открывшемся окне доступны для редактирования следующие поля:
- Основная информация (Basic information):
- Название дашбордов (Title) — заголовок дашборда;
- Читаемый URL (URL slug) – URL-адрес для дашборда;
- Логотипы (Logos):
- Логотип DATAGOVERNANCE (DATAGOVERNANCE logo) – выбор логотипа DATAGOVERNANCE;
- Ссылка на DATAGOVERNANCE (URL to DATAGOVERNANCE ) – URL-адрес ссылки на DATAGOVERNANCE;
- Логотип дашборда (Dashboard Icon) – выбор логотипа дашборда;
- Дата последнего обновления (Last update date):
- Показывать дату последнего изменения? (Show Last Update Data?) – настройка отображения даты актуальности дашборда;
- Изменить тип даты (Update Date Type) – настройка отображения старой или новой даты.
- Доступ (Access):
- Владельцы (Owners) – назначение/удаление доступа к дашборду;
- Цвета (Colors):
- Цветовая схема (Color Scheme) – выбор цветовой схемы для графика дашборда;
- Сертификация (Certification):
- Сертифицирован (Certified By) –лицо или группа, сертифицировавшие данную приборную панель;
- Детали сертификации (Certification Details) – дополнительная информация для отображения во всплывающей подсказке сертификации;
- Расширенные (Advanced):
- JSON Метаданные (JSON Metadata) — если развернуть заголовок Расширенные (Advanced), появится панель JSON Метаданные. Эта область предназначена для опытных пользователей, которые могут изменить определённые параметры дашборда.
¶ 6.1.5. Параметры графика
В режиме просмотра (т.е. без редактирования) выберите значок с вертикальным многоточием на графике, чтобы отобразить список параметров, относящихся к графику:
- Принудительное обновление (Forse refresh) – обновляет информацию на графике;
- Полноэкранный режим (Enter fullscreen) — перезагружает дашборд в полноэкранном режиме, т.е. без верхней панели инструментов. Повторно выберите (Exit fullscreen), чтобы вернуться к виду по умолчанию;
- Редактирование графика (Edit chart) – открывает окно редактирования графика;
- Скопировать запрос (View query) – открывает окно с SQL-запросом графика;
- Просмотреть как таблицу (View as table) – открывает окно с данными графика;
- Поделиться (Share):
- Скопировать ссылку на дашборд (Copy permalink to clipboard) – копирует ссылку на общий дашборд в буфер обмена вашей системы;
- Поделиться по электронной почте (Share permalink by email) – запускает клиент электронной почты по умолчанию в вашей системе и составляет новое сообщение с указанием URL-адреса вашего дашборда;
- Скачать (Download):
- Экспорт в .CSV (Export to .CSV) – загружает данные графика в вашу систему в формате CSV;
- Экспорт в .XLSX (Export to .XLSX) – загружает данные графика в вашу систему в формате XLSX;
- Экспорт в полный .CSV (Export to full .CSV) – загружает данные графика в вашу систему в формате CSV;
- Сохранить как изображение (Download as image) – загружает изображение всего дашборда в формате JPEG;
- Экспорт в .PDF (Export to .PDF) – загружает данные графика в вашу систему в формате PDF.
¶ 6.2. Свойства дашборда
¶ 6.2.1. Общая информация
Дашборд — это визуальное представление нескольких датасетов. В RT.DataVision дашборд представляет собой набор графиков. Дашборды обладают уникальной способностью рассказывать историю, комбинируя различные типы графиков для изложения фактов.
Дашборд может дать командам возможность представлять презентации на основе данных, а также позволить организациям отслеживать информацию на основе динамических данных.
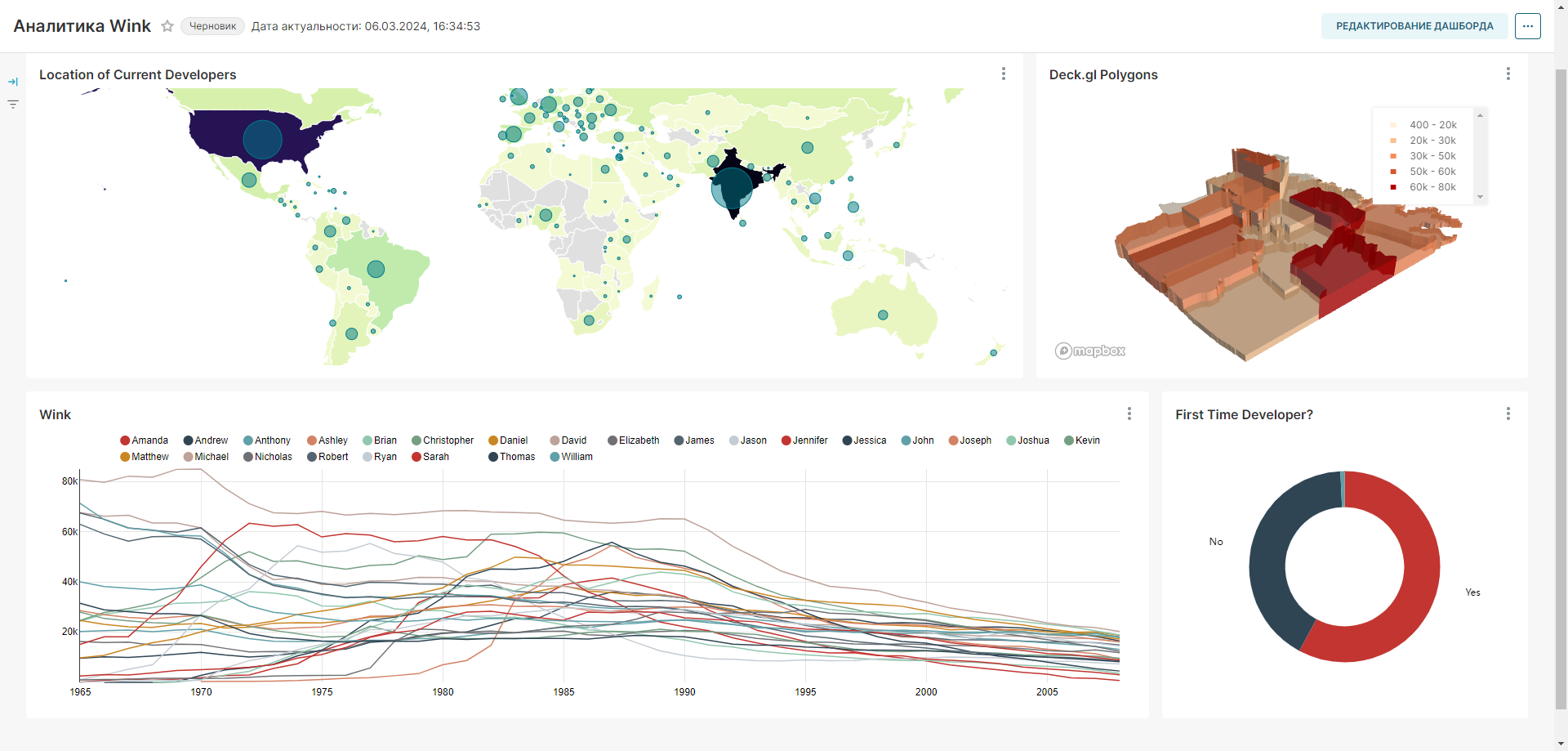
¶ 6.2.2. Типы дашбордов
Существует два типа дашбордов:
- Описательный дашборд — этот тип дашборда идеально подходит для привлекательного, убедительного и пояснительного контента. Этот тип дашборда обычно не используют ключевые показатели эффективности или измерения, а скорее текст или данные на основе содержимого для предоставления информации. Следующий дашборд, который показывает популярные имена при рождении в США, использует в основном исторические данные и является примером описательного дашборда.
- Метрический дашборд — этот тип дашборда идеально подходит для мониторинга, анализа производительности, просмотра элементов и отображений стандартного анализа. Он использует метрики, ключевые показатели эффективности и измерения, которые можно фильтровать, что позволяет пользователям предоставлять различные аспекты информации в зависимости от потребностей. На следующем дашборде показаны данные о продажах автомобилей и используются графики на основе метрик, такие как гистограммы, таблица и круговой график, для передачи количественных данных.
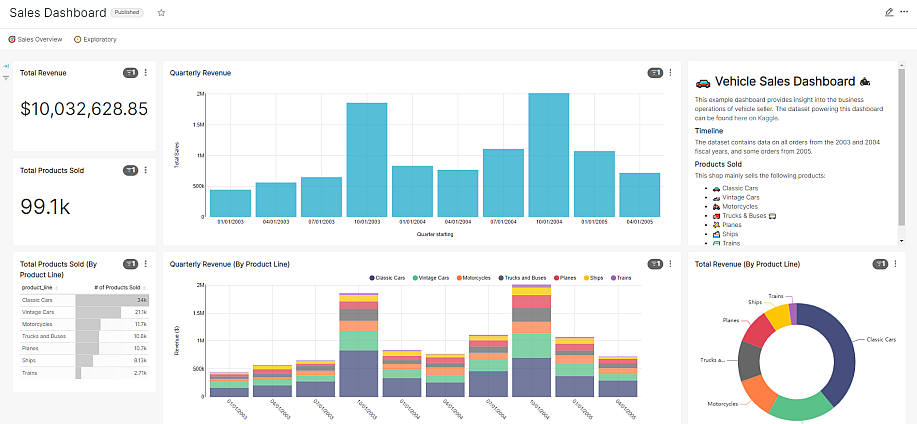
¶ 6.2.3. Терминология дашборда
- Data (Данные) — подтверждение фактами;
- Analytics (Аналитика) — вычисление точек данных для обнаружения;
- Performance (Производительность) — мониторинг тенденций или отношений;
- KPI — ключевые индикаторы прогресса;
- Metrics (Метрики) — числовые агрегации и ассоциации.
¶ 6.2.4. Сценарии использования
| Дашборд | Цель |
|---|---|
| Monitoring (Мониторинг) |
|
| Performance (Производительность) |
|
| Item Browsing (Просмотр элементов) |
|
| Canned Analysis (Стандартный анализ) |
|
| Static Display (Статическое отображение) |
|
¶ 6.3. Настройка дашбордов
Выполните настройку своих дашбордов, чтобы улучшить взаимодействие с пользователем и лучше соответствовать внешнему виду организации.
¶ 6.3.1. Элементы макета дашборда
RT.DataVision имеет множество элементов макета, которые можно использовать для организации и сегментации вашего контента на дашбордах.
Для добавления элементов перейдите на вкладку Элементы макета (Layout Elements) и перетащите необходимые элементы на дашборд:
Наведите указатель мыши на элемент, чтобы просмотреть доступные параметры. Обратите внимание, что можно использовать Прозрачный (Transparent) или Белый (White) фон для Строк (Rows), Столбцов (Columns):
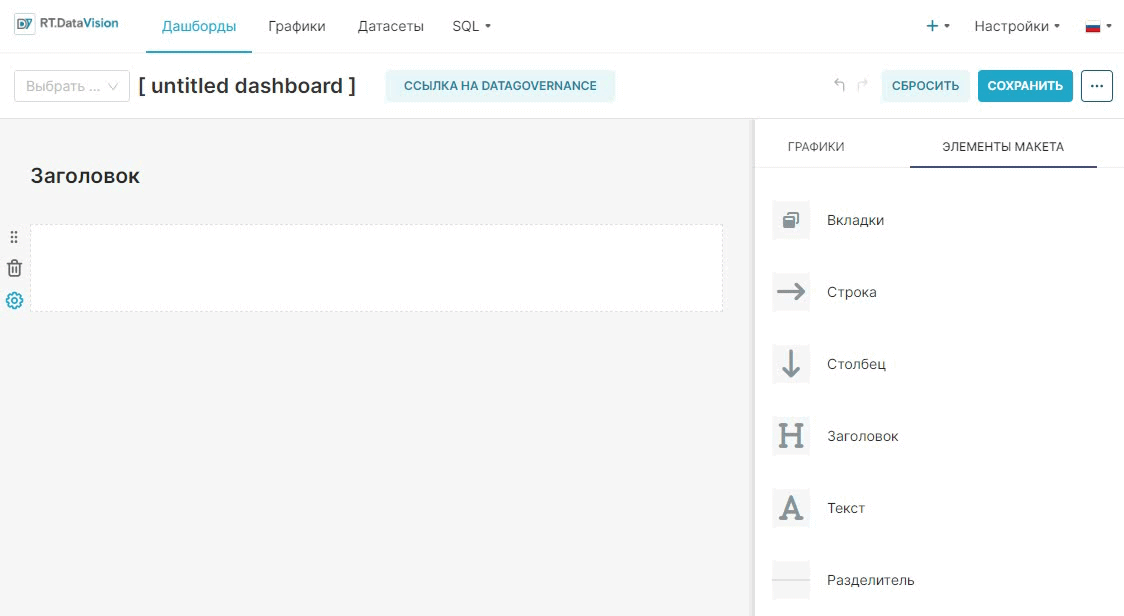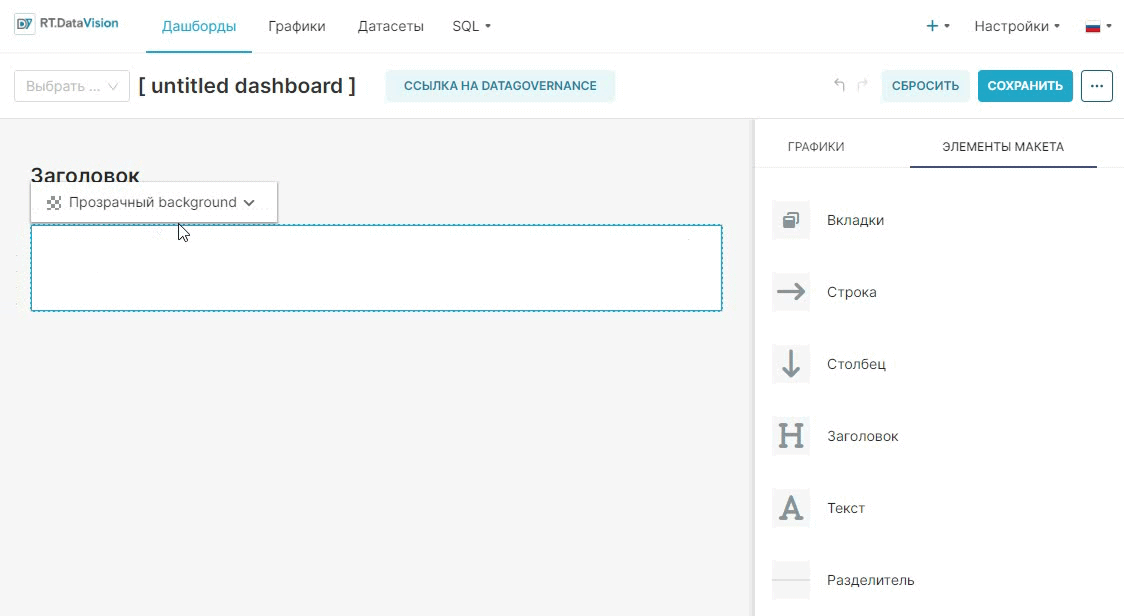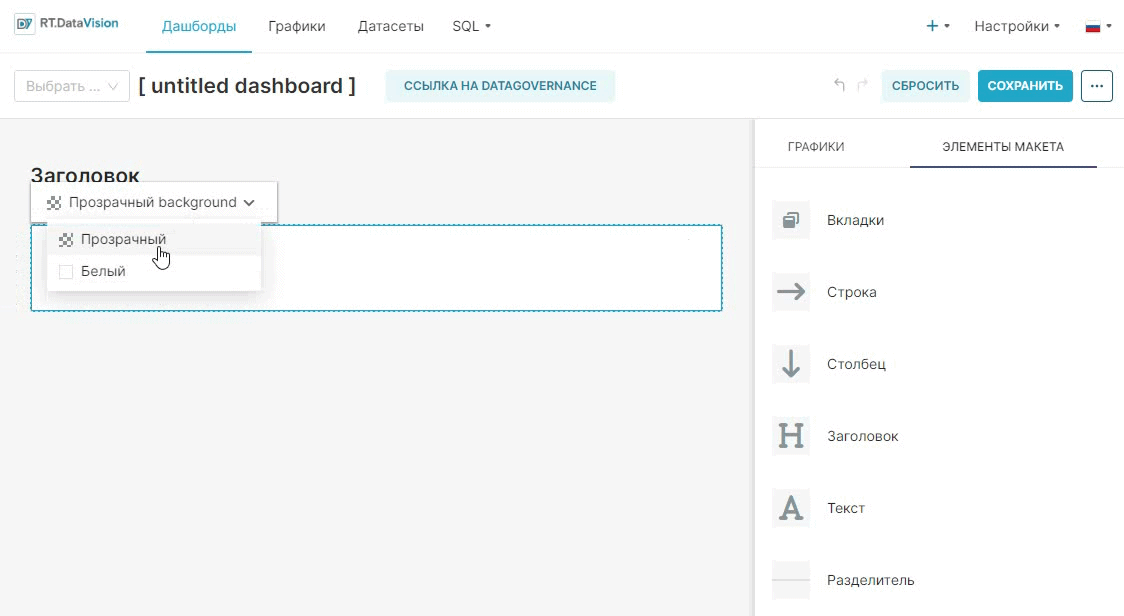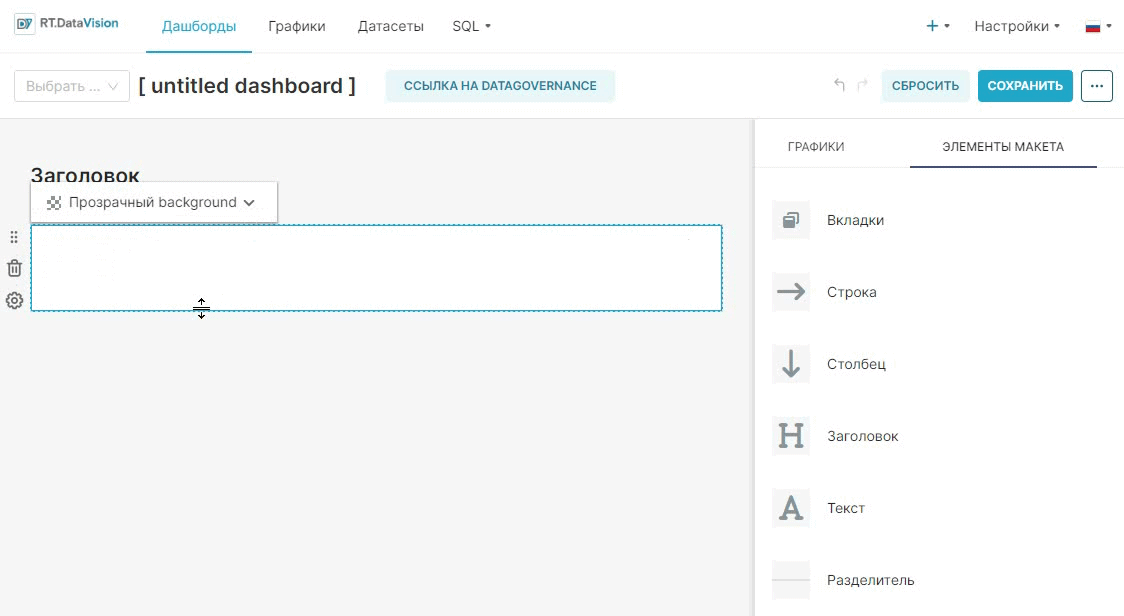
Доступные элементы:
 |
Вкладки (Tabs) очень полезны для разделения графиков на разные группы. |
 |
Заголовок (Header) используется для добавления заголовков. |
 |
Разделитель (Divider) полезен, чтобы изолировать части дашборда. |
 |
Строка (Rows) и Столбец (Columns) могут быть добавлены для дальнейшей настройки макета графика. |
¶ 6.3.2. Добавление изображений на дашборд
RT.DataVision позволяет добавлять изображения на основе URL-адреса на дашборд.
Для добавления изображения с компьютера:
- Загрузите нужное изображение в приложение облачного хостинга (например, Google Диск);
- После загрузки на Google Диск измените настройки общего доступа на Anyone with the link;
- Скопируйте URL-адрес изображения. Он должен иметь следующую структуру — https://drive.google.com/file/d/{{FileID}}/view?usp=sharing.
- Получите {{FileID}} по ссылке и замените его на эту структуру — https://drive.google.com/uc?export=view&id={{FileID}}. Используйте эту ссылку, чтобы добавить изображение на дашборд, выполнив следующие действия.
Существует два способа добавления изображения на дашборд:
1. С использованием HTML:
Это самый простой способ добавить изображение на дашборд:
1.1. Добавьте элемент Markdown на дашборд.
1.2. Создайте на нём новый тег <img>,
<img src="{{Image URL}}" style="width:{{Width}};height:{{Height}}">где замените:
- {{Image URL}} — ссылкой на ваше изображение (убедитесь, что изображение доступно из интернета);
- {{Width}} — желаемой шириной изображения (в пикселях или %);
- {{Height}} — нужной высотой (в пикселях или %).
Обратите внимание, что если вы установите ширину и высоту на 100%, размер изображения будет соответствовать блоку Markdown, что позволит вам контролировать размер изображения с помощью размера элемента Markdown.
2. С использованием Markdown и CSS:
2.1. Добавьте элемент Markdown на дашборд.
2.2. Используйте приведённый ниже синтаксис, чтобы добавить изображение,
где замените:
- {{Image Name}} — заголовком для этого изображения (будет использоваться в CSS для его стилизации);
- {{Image URL}} — ссылкой на ваше изображение (убедитесь, что изображение доступно из интернета).
Можно настроить стиль изображения (включая размер) с помощью CSS. Для этого:
- Нажмите на три многоточия (...) в правом верхнем углу и выберите Редактировать CSS (Edit CSS).
- Используйте синтаксис ниже, чтобы изменить размер изображения,
img[alt={{Image Name}}] {
width: {{Width}};
height: {{Height}};
}где замените:
- {{Image Name}} — заголовком, указанным в элементе Markdown;
- {{Width}} — с желаемой шириной изображения (в пикселях или %);
- {{Height}} — с нужной высотой (в пикселях или %).
¶ 6.3.3. Цветовые палитры
При создании графика необходимо указать для него цветовую палитру. На уровне дашборда можно указать единую цветовую палитру, которая будет использоваться всеми графиками на вашем дашборде — цветовая палитра графика по-прежнему будет использоваться при просмотре графика или на других дашбордах. Для этого:
- Получите доступ к дашборду.
- Нажмите Редактирование дашборда (Edit Dashboard) в правом верхнем углу.
- Нажмите на три многоточия (...) и выберите Редактирование свойств (Edit properties).
- Выберите палитру в раскрывающемся списке Цветовая схема (Color scheme).
- Сохраните изменения.
RT.DataVision будет использовать один и тот же цвет для метрик/измерений, отображаемых на нескольких графиках (на одной вкладке). Если необходимо лучше контролировать столбцы, применяемые к каждому измерению, то можно вручную указать шестнадцатеричные цветовые коды в метаданных JSON панели мониторинга. Для этого:
- Получите доступ к дашборду.
- Нажмите Редактирование дашборда (Edit Dashboard)) в правом верхнем углу.
- Нажмите на три многоточия (...) и выберите Редактирование свойств (Edit properties).
- Разверните раздел Расширенные (Advanced).
- Создайте новый раздел внутри JSON Метаданные (JSON metadata) с именем label_colors, указав нужные цвета для каждой метрики/измерения. Например:
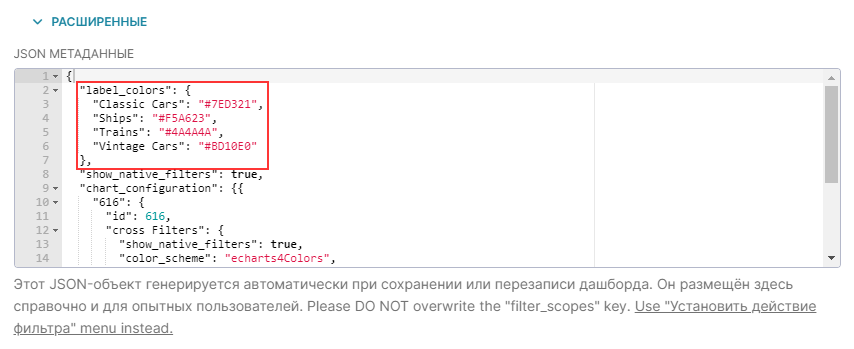
¶ 6.3.3.1. Создание новой цветовой палитры
Существует возможность добавить и настроить собственную цветовую схему для создания графиков и дашбордов, соответствующих внешнему виду бренда.
В RT.DataVision можно создать два типа цветовых палитр:
- Категориальный — цветовые шкалы, которые различают категории, не имеющие внутреннего порядка;
- Последовательный — цветовые шкалы градиента, которые переходят от яркого к темному или наоборот.
Для добавления новой цветовой палитры:
1. На странице настроек команды нажмите Manage Team. Нажмите +Add New, чтобы создать новую цветовую палитру.
2. Назначьте Name своей цветовой палитре и выберите тип палитры.
3. Определите цветовую схему.
- Для категориальной цветовой палитры — добавьте не менее 6 цветов, чтобы создать палитру;
- Для последовательной цветовой палитры — определите самые тёмные и самые светлые цвета. Вы также можете добавить средний цвет в качестве опции.
4. Когда закончите, нажмите Save.
¶ 6.4 Экспорт дашборда в PDF
В RT.DataVision предусмотрена функция экспорта дашбордов в формат PDF, что позволяет пользователям сохранять и делиться аналитическими отчетами в удобном виде.
Примечание. Доступность опции экспорта в PDF зависит от настройки ENABLE_PDF_EXPORT. Если опция недоступна, проверьте конфигурацию параметров или обратитесь к администратору для её активации.
Для экспорта дашборда:
1. Перейдите в раздел Дашборды.
2. Нажмите на название необходимого дашборда, чтобы открыть его.
3. Нажмите на значок с тремя точками в правом верхнем углу.
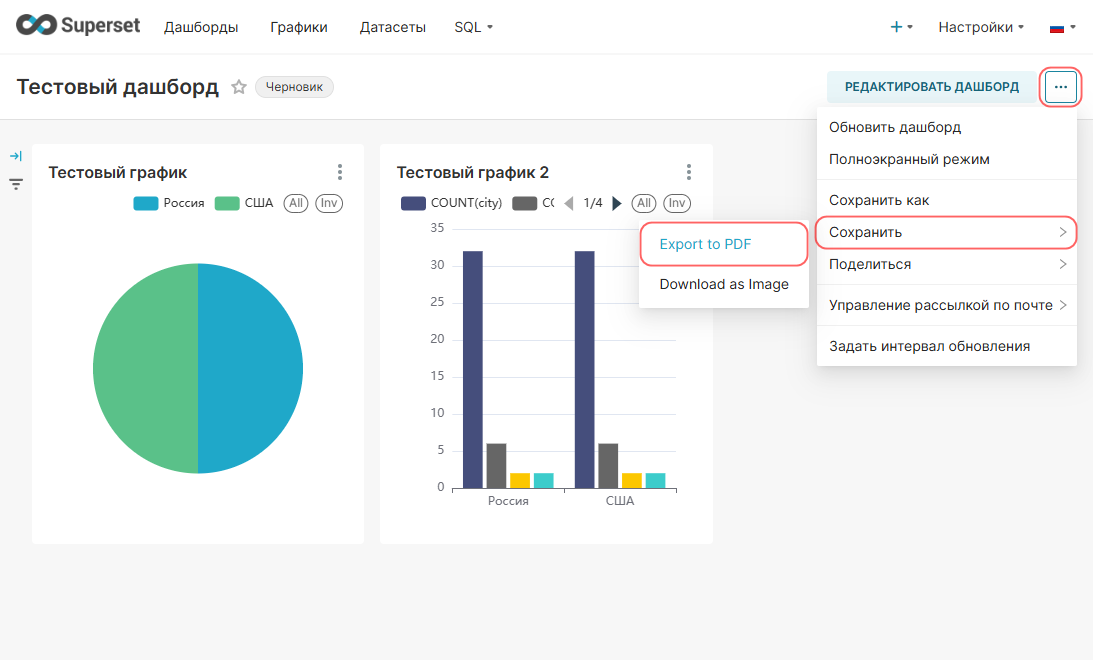
4. Выберите пункт Сохранить → Экспорт в PDF.
Файл в формате PDF загрузится автоматически.
¶ 7. Фильтрация дашбордов
¶ 7.1. Общая информация
Фильтры дашбордов RT.DataVision предлагают функции фильтрации данных в сочетании с простым в использовании интуитивно понятным интерфейсом. На любом дашборде можно развернуть боковую панель Фильтры (Filters), чтобы быстро применить различные фильтры ко всем графикам на дашборде.
Типы фильтров Значение (Value) позволяют указать любое значение для любого столбца в датасете, предоставляя значительную свободу действий с точки зрения предложения различных фильтров. Фильтры Числовой диапазон (Numerical range) предлагают простой способ определить диапазон числовых значений, таких как данные о ценах или диапазоны по годам. Кроме того, RT.DataVision предлагает ряд фильтров на основе времени: Период времени (Time Range), Столбец с временем (Time Column) и Гранулярность времени (Time Grain), которые позволяют фильтровать все графики на основе столбца времени датасета.
Как базовые, так и расширенные параметры конфигурации позволяют вывести фильтры на новый уровень с точки зрения параметров фильтрации и удобства использования.
Приведённые ниже инструкции ссылаются на дашборд USA Births Names, который является примером дашборда, доступным для всех новых предустановленных учётных записей.
¶ 7.1.1. Навигация к фильтрам дашборда
Для доступа к фильтрам дашборда:
1. Выберите Дашборды (Dashboards) на верхней панели инструментов. Появится список всех доступных дашбордов.
2. Запустите любой дашборд (например Births names), выбрав его имя под заголовком столбца Название Дашбордов (Title).
3. Нажмите на стрелку вправо в левой части формы.
Примечание. Боковая панель Фильтр (Filter) может быть скрыта (см. п. 7.11.9. Скрытие боковой панели фильтрации). В таком случае, значок стрелки и фильтра будут отсутствовать на дашборде.
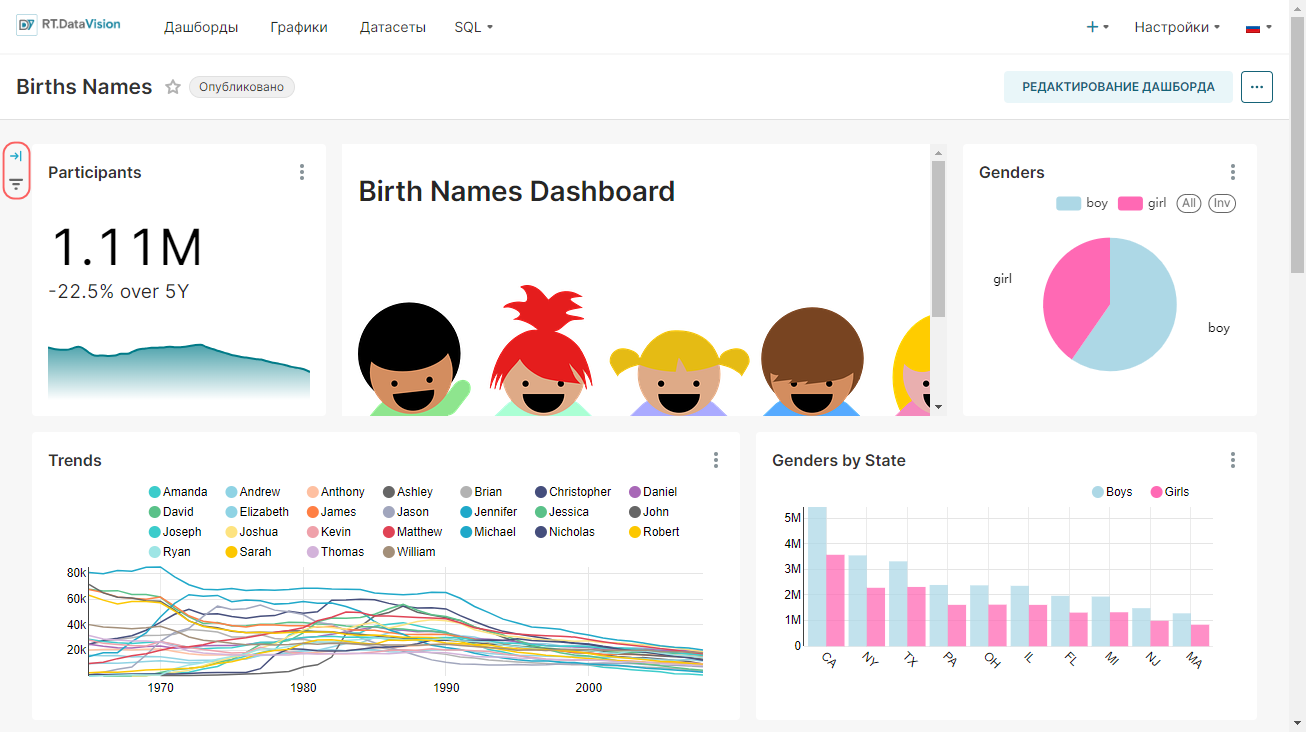
Отобразится боковая панель Фильтры (Filters). Чтобы убрать боковую панель Фильтры (Filters), нажмите на стрелку влево.
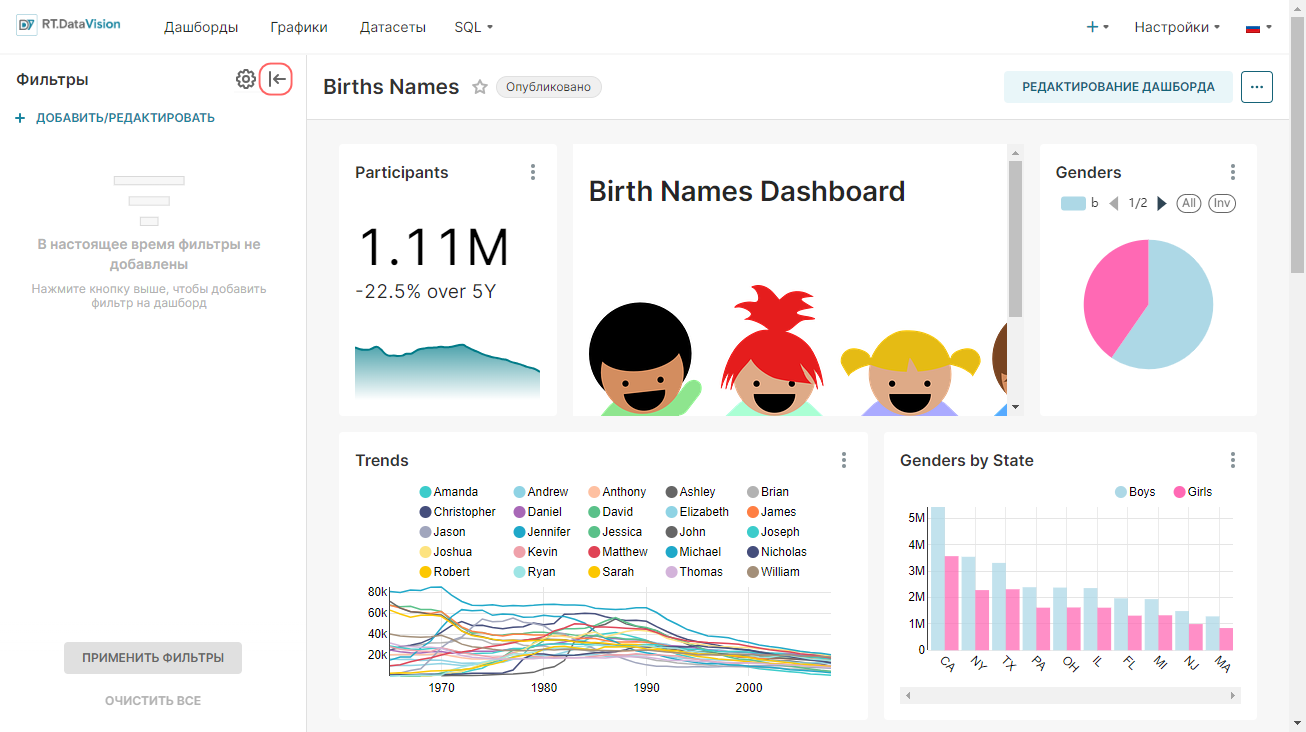
¶ 7.1.2. Доступ к конфигурации фильтра
Для настройки нового фильтра нажмите кнопку +Добавить/Редактировать (Add/Edit Filters).
Откроется окно Добавление и редактирование фильтров (Add and edit filters).
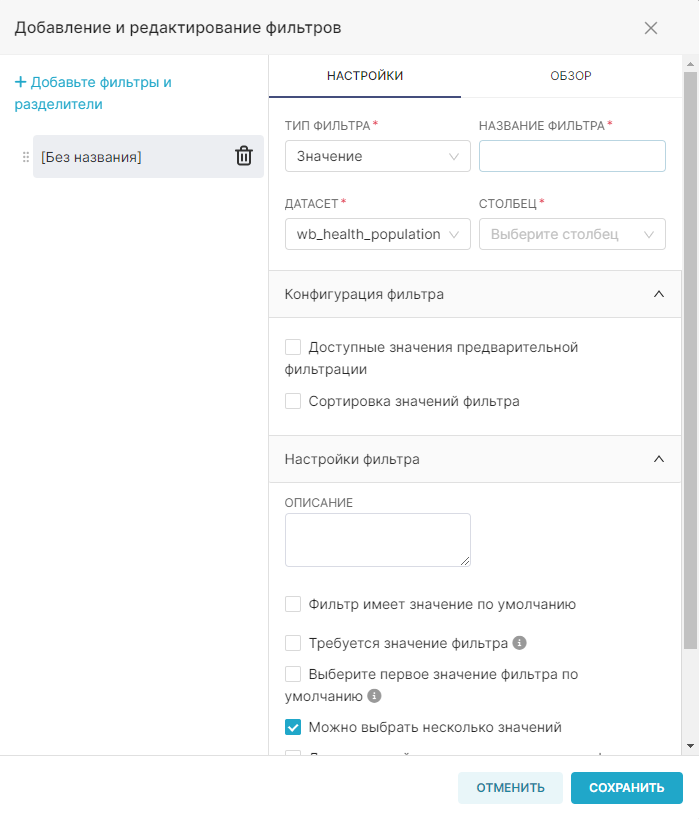
¶ 7.2. Типы фильтров
¶ 7.2.1. Общая информация
В этом разделе описаны различные типы фильтров, которые можно применять к графикам на дашборде.
¶ 7.2.2. Типы фильтров
В окне Добавление и редактирование фильтров (Add and edit filters) расположены две вкладки: Настроить (Settings) и Обзор (Scoping). .
Первый раздел вкладки Настроить (Settings) состоит из четырех обязательных полей:
- Тип фильтра (Filter Type) — выбор тип фильтра. Опции включают: Значение (Value), Числовой диапазон (Numerical range), Период времени (Time Range), Столбец с временем (Time Column), Гранулярность времени (Time Grain) (отдельные описания приведены в разделах 7.2.3 - 7.2.7);
- Датасет (Dataset) — выбор датасета, который необходимо использовать для графика на дашборде. По умолчанию все датасеты, связанные с графиками дашборда, будут доступны для выбора. Это поле появляется, когда выбраны фильтры типа Значение (Value), Числовой диапазон (Numerical range), Столбец с временем (Time Column) или Гранулярность времени (Time Grain);
- Название фильтра (Filter Name) — имя нового фильтра. Обычно оно коррелирует с выбором, сделанным в последующем поле Столбец (Column);
- Столбец (Column) — выбор столбца, к которому необходимо применить фильтр. Это поле появляется, когда выбран тип поля Значение (Value) или Числовой диапазон (Numerical range).
Ниже описаны доступные типы фильтров из поля Тип фильтра (Filter Type).
¶ 7.2.3. Тип фильтра Значение (Value)
Этот тип фильтра создаёт раскрывающееся меню, заполненное всеми доступными значениями, связанными с выбранным столбцом (поле Столбец (Column)).
Например: если выбрать тип фильтра Значение (Value) и в поле Столбец (Column) выбрать gender, то на дашборде появится раскрывающееся меню фильтра, позволяющее выполнять фильтрацию по полу. При применении все графики на дашборде будут отображать данные только в соответствии с выбранным фильтром gender.
Пример такой конфигурации:
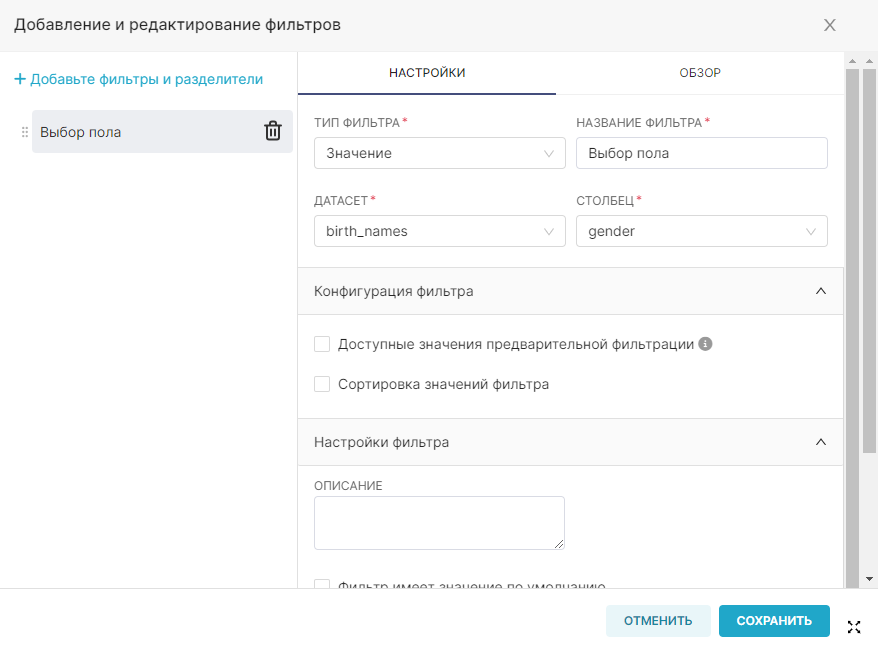
Раскрывающийся фильтр под названием Выбор пола в поле Фильтры (Filter Name) выглядит следующим образом:
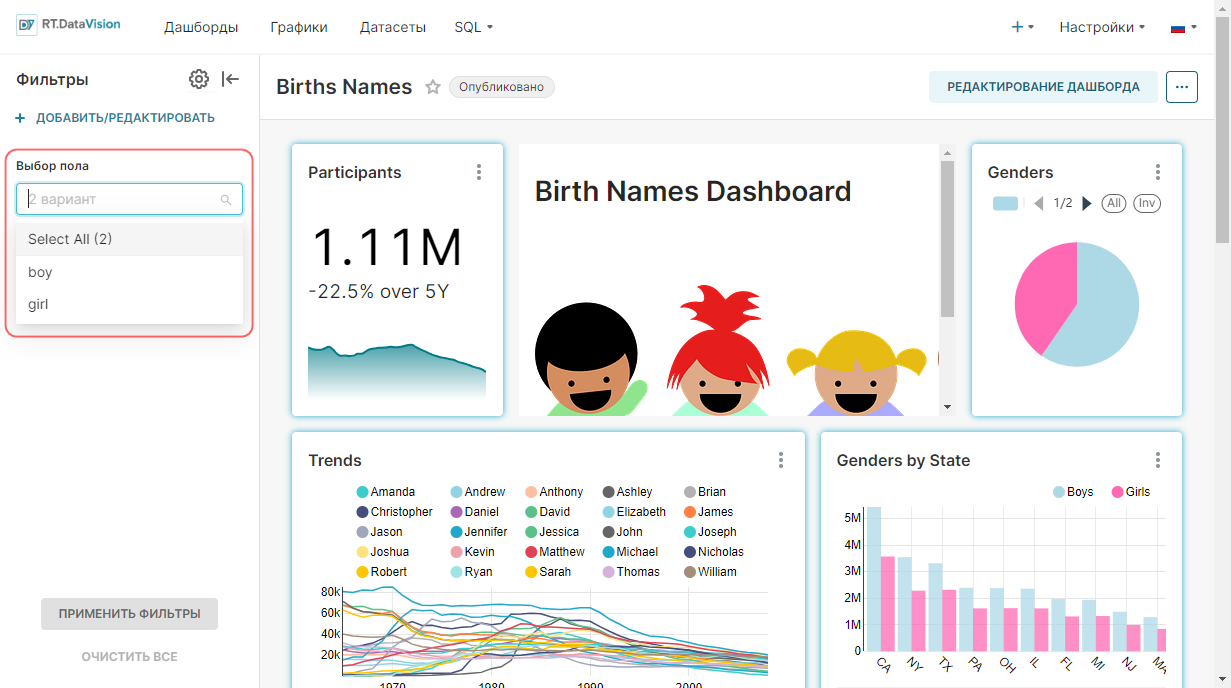
Для применения фильтра выберите значение и нажмите кнопку Применить фильтры (Apply Filters). Графики на дашборде обновятся и отобразят отфильтрованные данные.
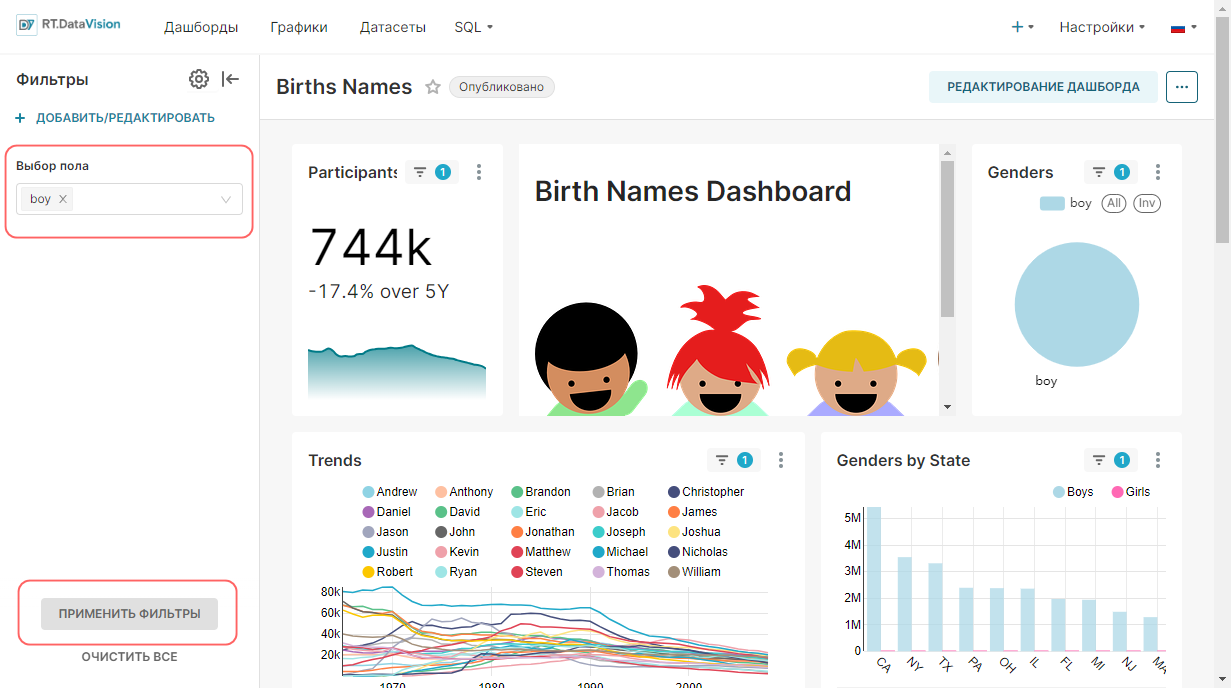
¶ 7.2.4. Тип фильтра Числовой диапазон (Numerical range)
Этот тип фильтра создаёт ползунок диапазона, который позволяет указать начальную и конечную точки на основе числовых значений, доступных из данных в выбранном столбце.
Например: если выбрать тип фильтра Числовой диапазон (Numerical range) и в поле Столбец (Column) выбрать num, то появится фильтр ползунка диапазона, который позволит выбрать начальный и конечный диапазоны. При применении все графики на дашборде будут отображать только данные, относящиеся к выбранному фильтру диапазона количества рождённых детей.
Пример такой конфигурации:
Фильтр ползунка диапазона под названием Выбор диапазона в поле Фильтры (Filter Name) выглядит следующим образом:
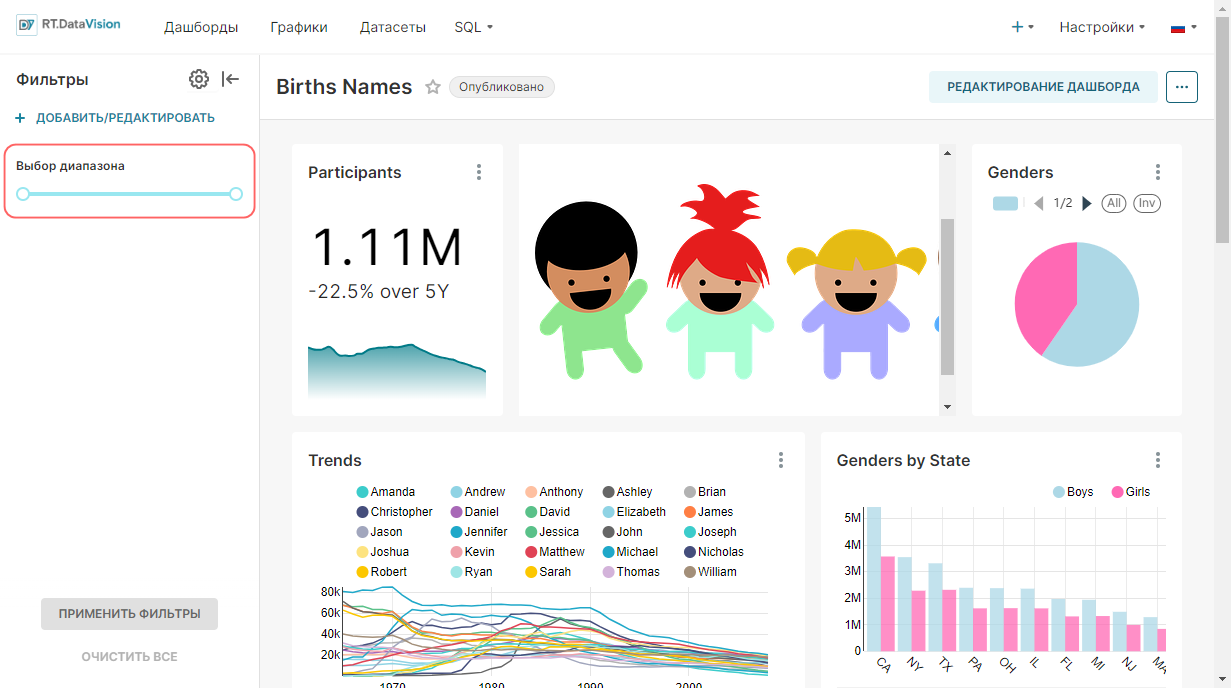
Необходимый диапазон регулируется с помощью перемещения ползунков:
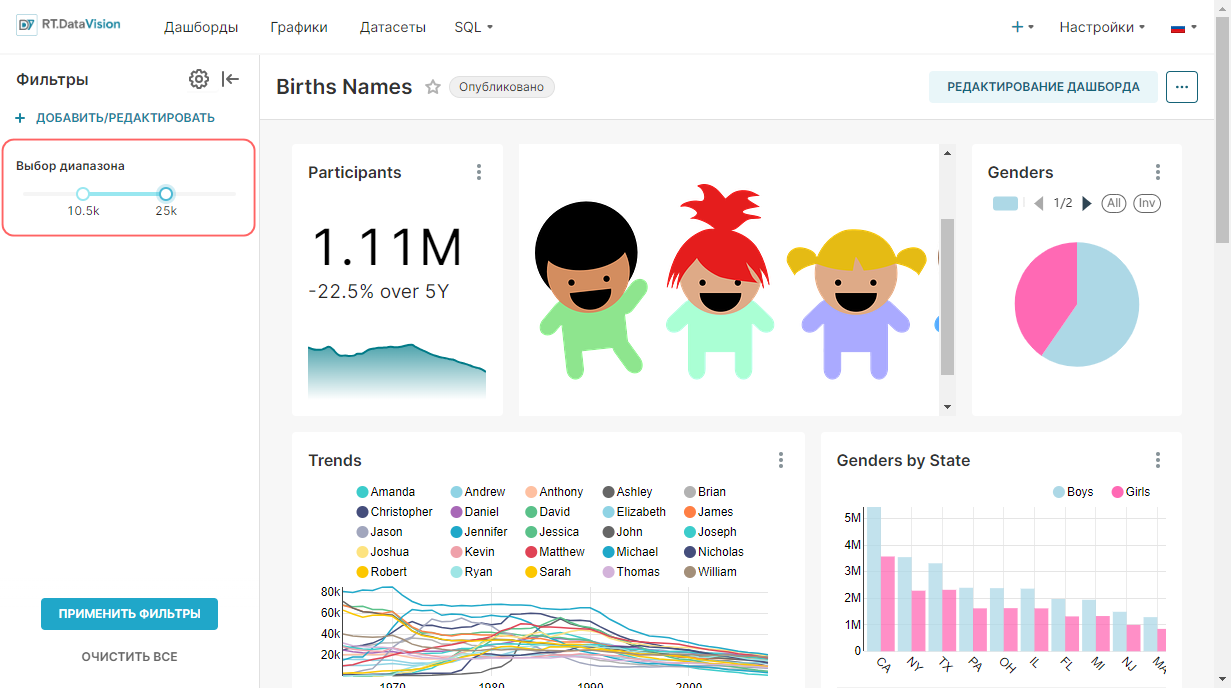
Обратите внимание, что можно просмотреть минимальное значение ползунка, наведя курсор на крайнюю левую опорную точку. В примере ниже минимальное значение — 5:
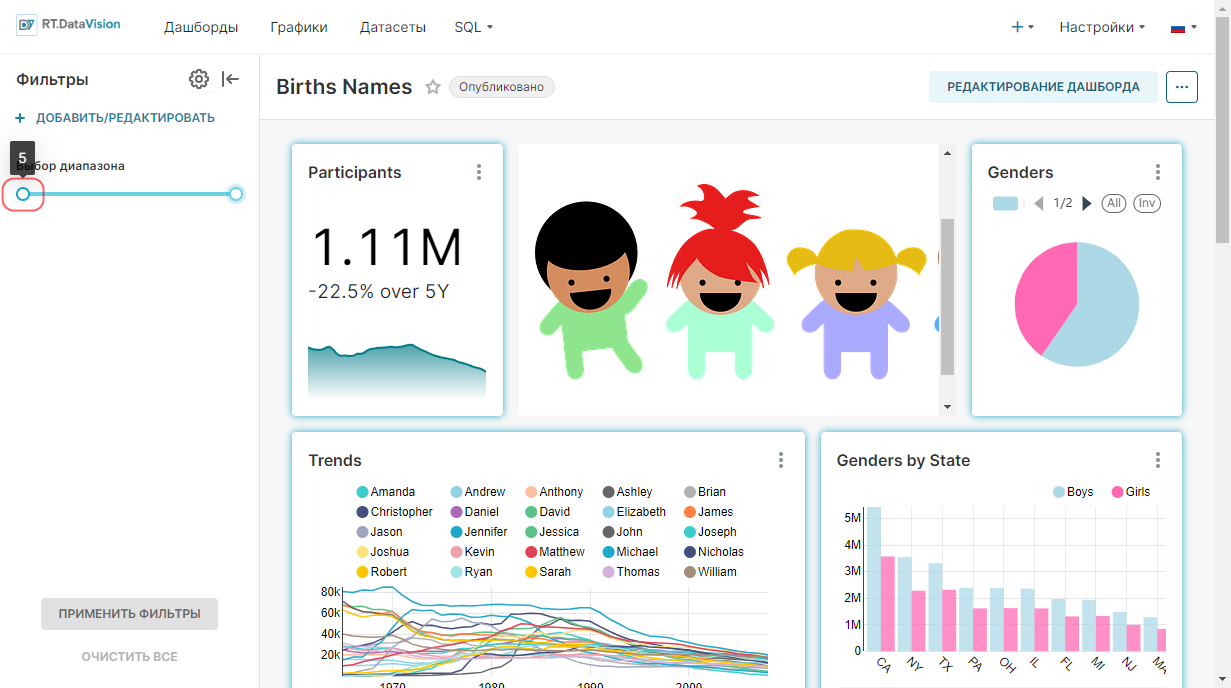
Для просмотра максимального значения ползунка наведите курсор на крайнюю правую опорную точку. В примере ниже максимальное значение — 37.3k:
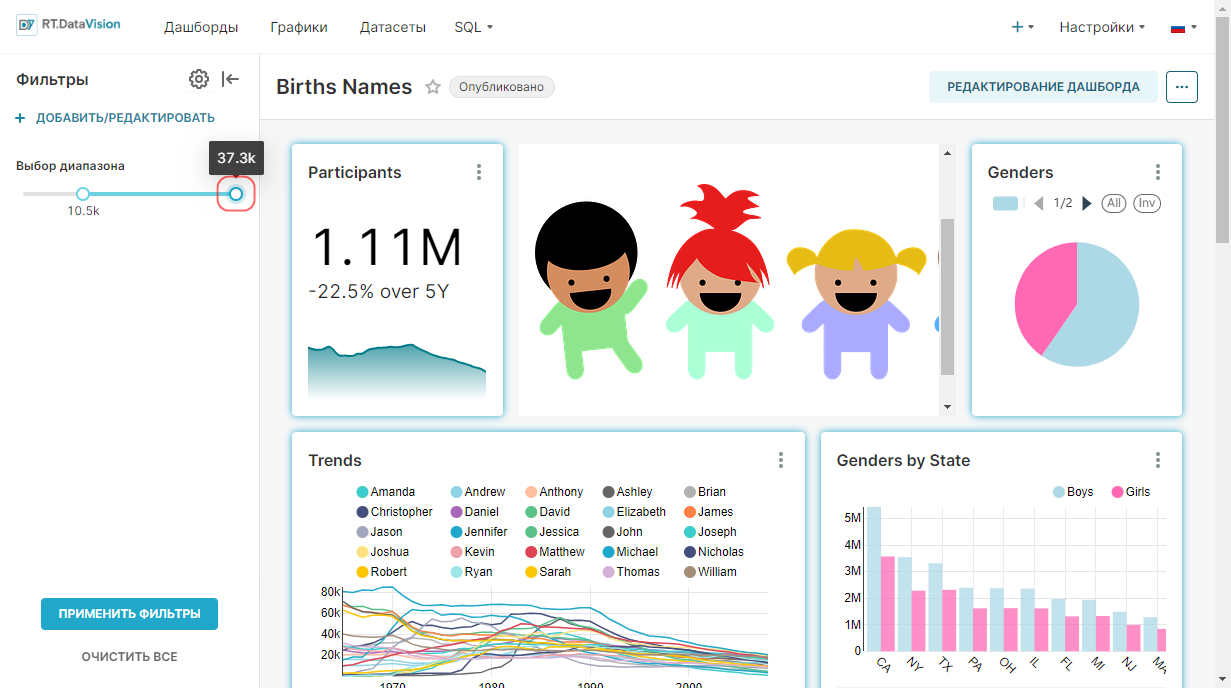
Для применения фильтра определите числовой диапазон и нажмите кнопку Применить фильтры (Apply Filters). Графики на дашборде обновятся и отобразят отфильтрованные данные.
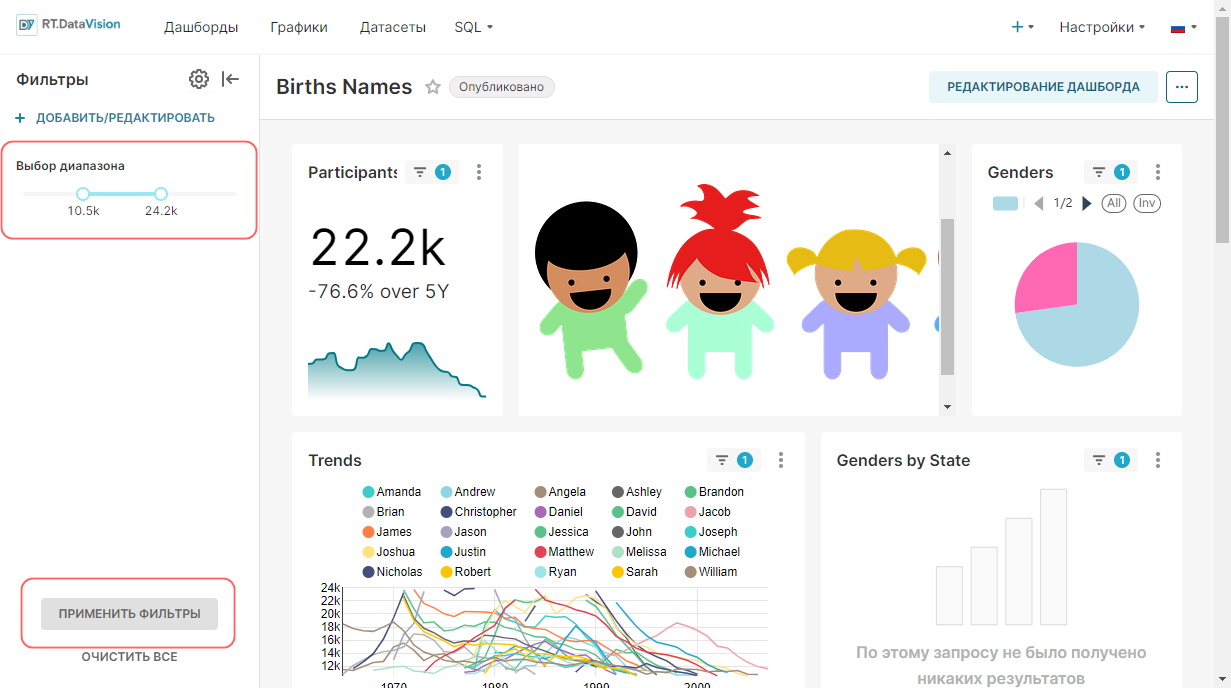
¶ 7.2.5. Тип фильтра Период времени (Time Range)
Этот тип фильтра создаёт фильтр-кнопку, при выборе которой запускается функция редактирования временного диапазона RT.DataVision. Аналогично полю Период времени (Time Range), используемому при создании нового графика.
Пример конфигурации:
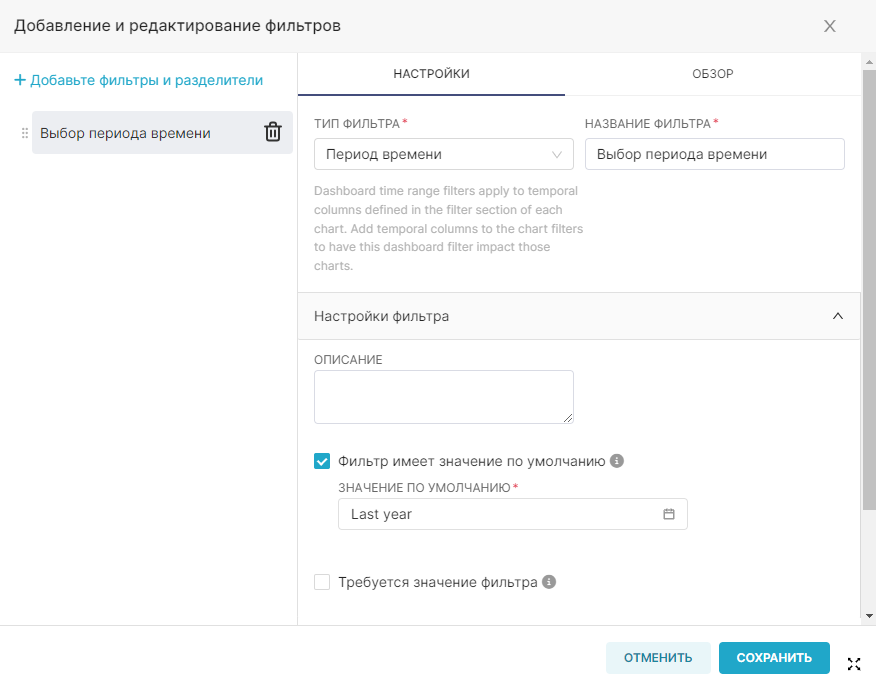
В этом примере указано значение по умолчанию Последний год (Last year) и указано имя фильтра Выбор периода времени.
Для применения фильтра выберите и настройте диапазон времени и нажмите кнопку Применить фильтры (Apply Filters). Графики на дашборде обновятся и отобразят отфильтрованные данные.
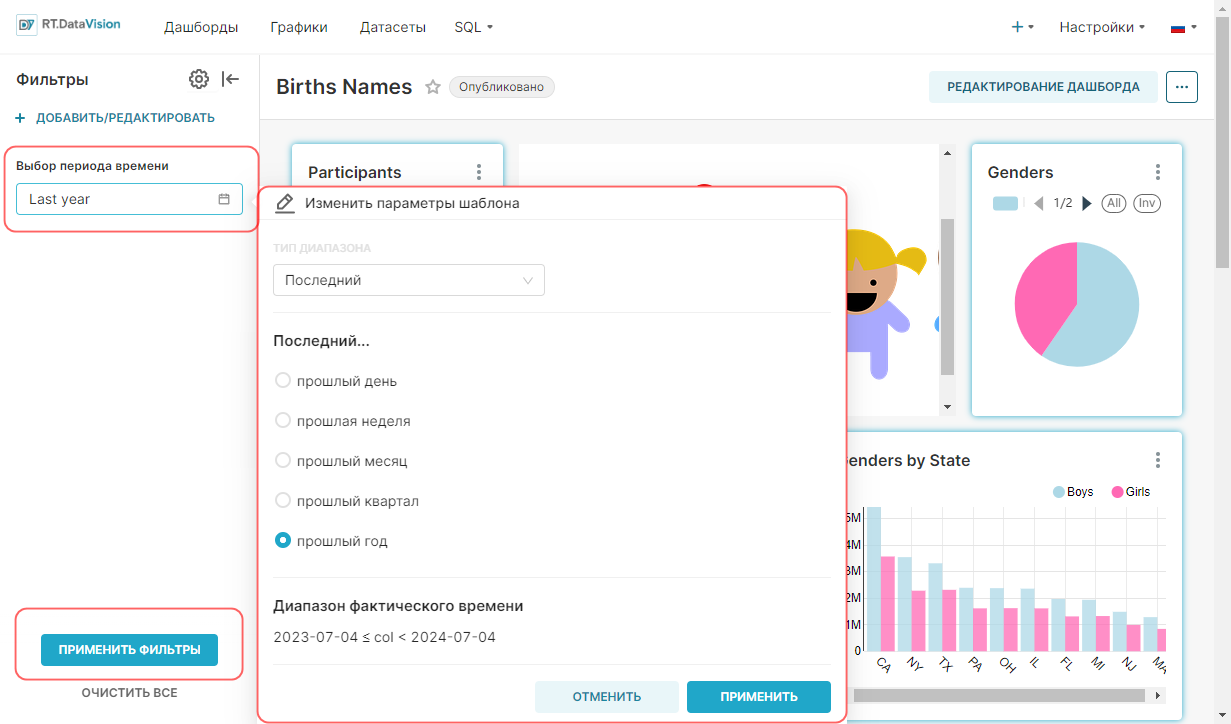
¶ 7.2.6. Тип фильтра Столбец с временем (Time Column)
Этот тип фильтра создаёт раскрывающееся меню, позволяющее выбрать новый столбец времени на уровне панели мониторинга, который перезапишет любые существующие столбцы времени, определённые на уровне графике.
Тип фильтра Столбец с временем (Time Column) лучше всего использовать, когда в выбранном датасете есть несколько столбцов времени. Во многих случаях в датасете будет только один столбец времени (выбранный по умолчанию), что исключает необходимость в этом типе фильтра.
Пример конфигурации:
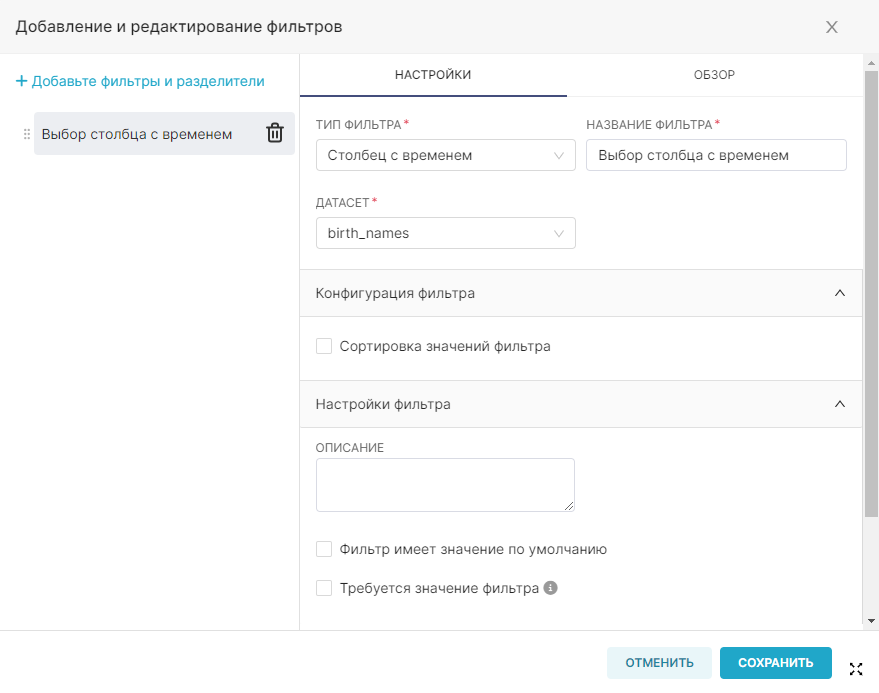
Раскрывающийся фильтр под названием Выбор столбца с временем в поле Фильтры (Filter Name) выглядит следующим образом:
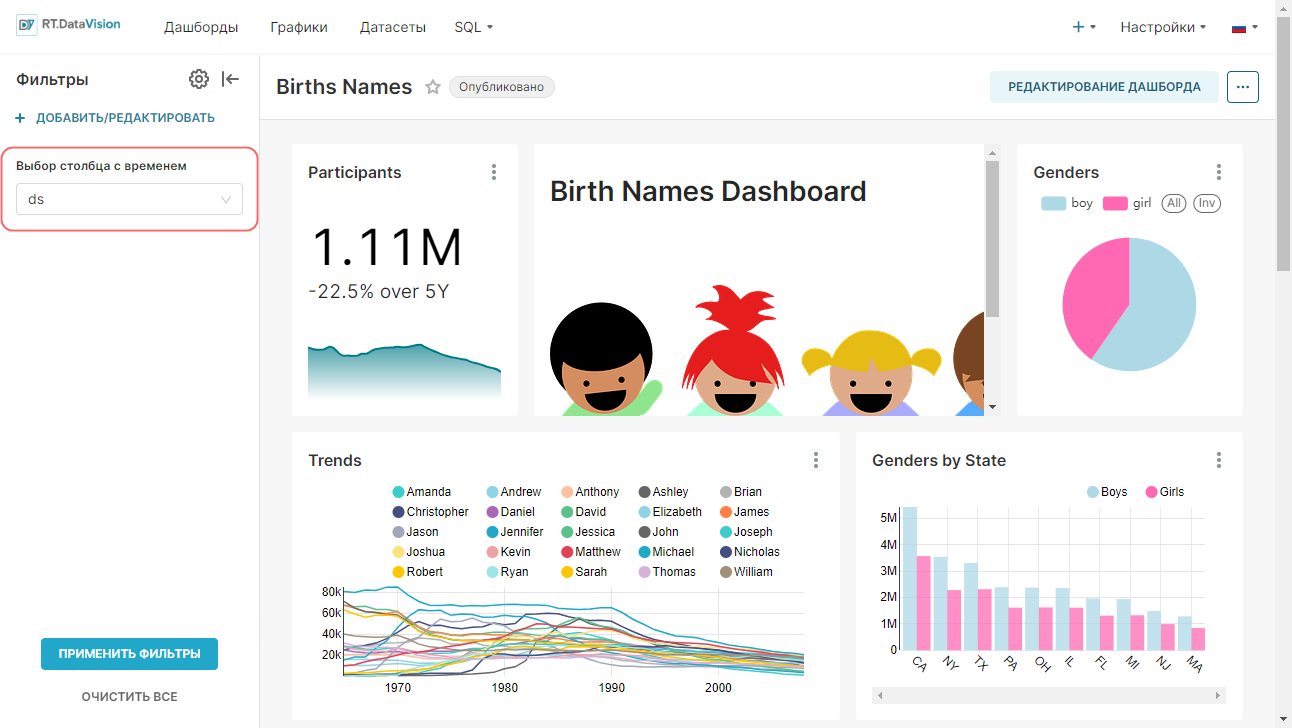
Для применения фильтра выберите параметр столбца времени и нажмите кнопку Применить фильтры (Apply Filters). Графики на дашборде обновятся и отобразят отфильтрованные данные.
¶ 7.2.7. Тип фильтра Гранулярность времени (Time Grain)
Этот тип фильтра создаёт раскрывающийся список, позволяющий выбрать степень детализации времени. При применении все метки времени группируются на основе выбранного временного интервала.
Пример конфигурации:
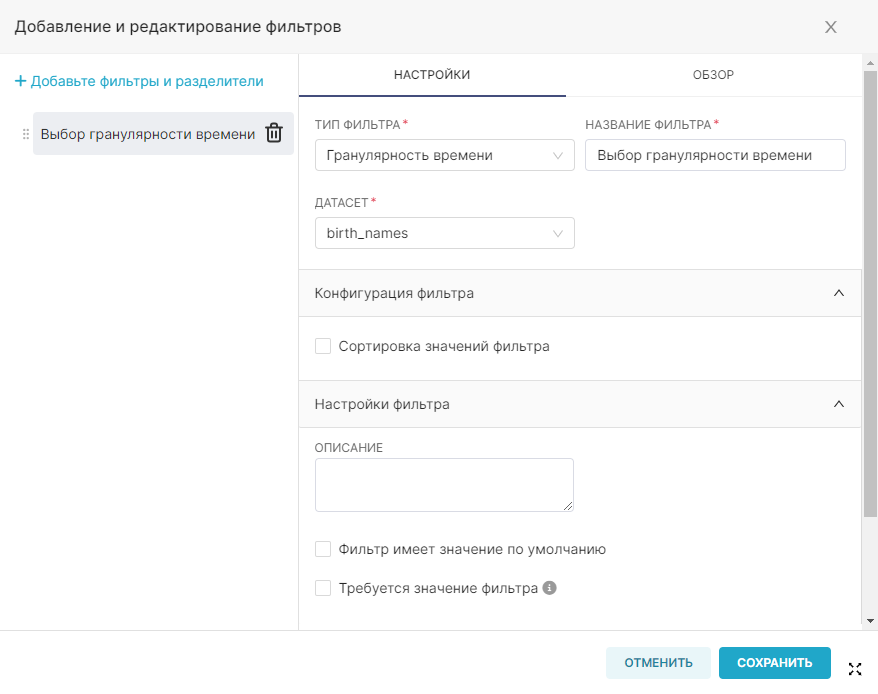
Раскрывающийся фильтр под названием Выбор гранулярности времени в поле Фильтры (Filter Name) выглядит следующим образом:
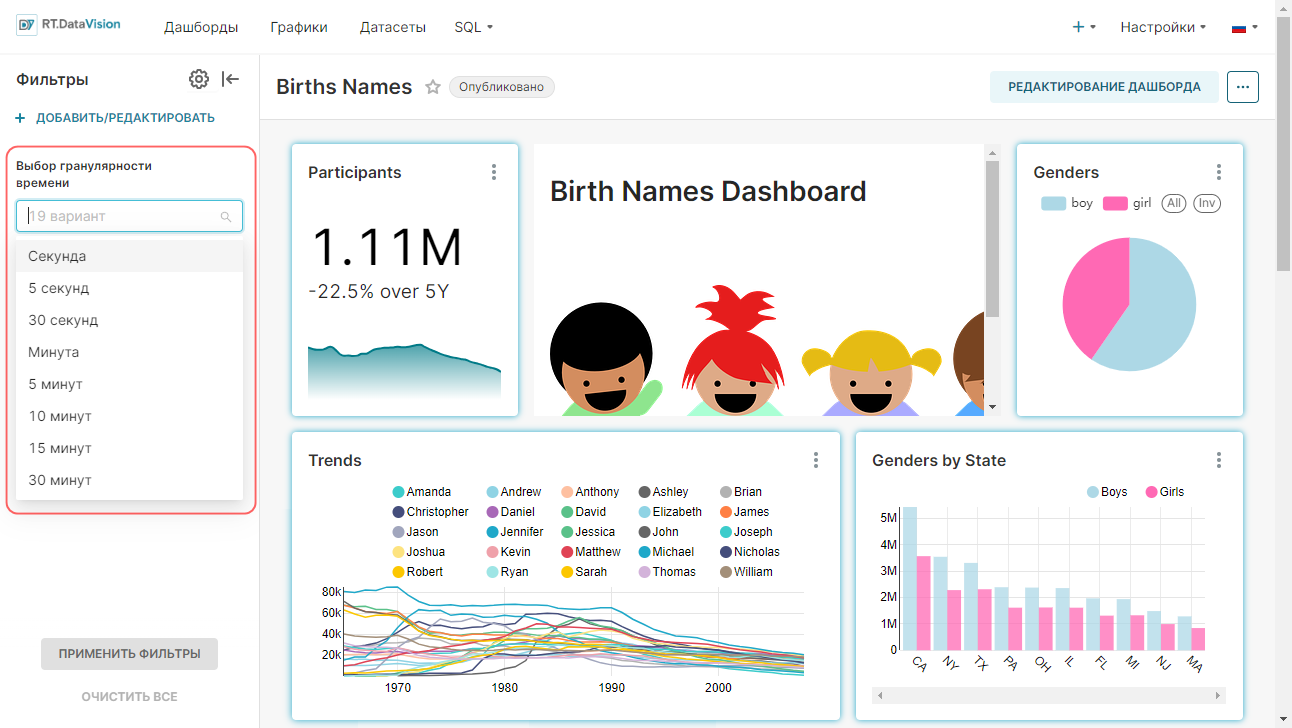
Для применения группировки детализации времени на уровне дашборда выберите гранулярность времени и нажмите кнопку Применить фильтры (Apply Filters). Графики на дашборде обновятся и отобразят сгруппированные данные.
¶ 7.3. Фильтр “родитель-потомок”
¶ 7.3.1. Общая информация
В этом разделе описана настройка фильтра “родитель-потомок”, используя параметр конфигурации Values are dependent on other filters. Фильтр “родитель-потомок” используется для создания связи между фильтрами. Эта конфигурация превращает существующий фильтр в подфильтр родителя.
¶ 7.3.2. Параметры конфигурации фильтра
Для этих типов фильтров доступны следующие параметры конфигурации:
| Value | Numerical Range | Time Range | Time Column | Time Grain | |
|---|---|---|---|---|---|
| “Родитель-потомок” | + | ||||
| Доступные значения предварительной фильтрации | + | + | |||
| Сортировка значений фильтра | + | + | + | + | |
| Единственное значение | + |
¶ 7.3.3. Подготовка
Для настройки фильтра “родитель-потомок” прежде необходимо подготовить два фильтра Значение (Value):
1. Создайте фильтр типа Значение (Value) с названием Выбор региона, который использует столбец state. Для настройки установите флажок Можно выбрать несколько значений (Can select multiple values) на панели Настройки фильтра (Filter Settings).
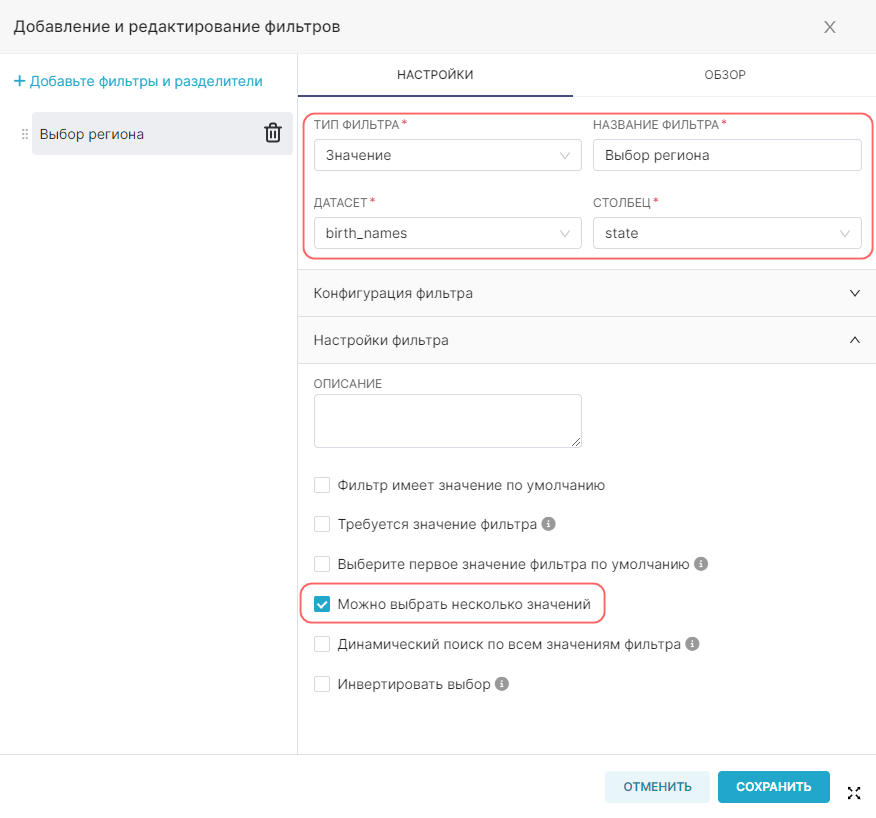
2. Нажмите кнопку Сохранить (Save).
3. Нажмите кнопку + Добавить/Редактировать (+ Add/Edit Filters).
4. Нажмите кнопку + Добавьте фильтры и разделители (+ Add filters and dividers) и выберите Фильтр (Filter) в окне Добавление и редактирование фильтра (+ Add and edit filters).
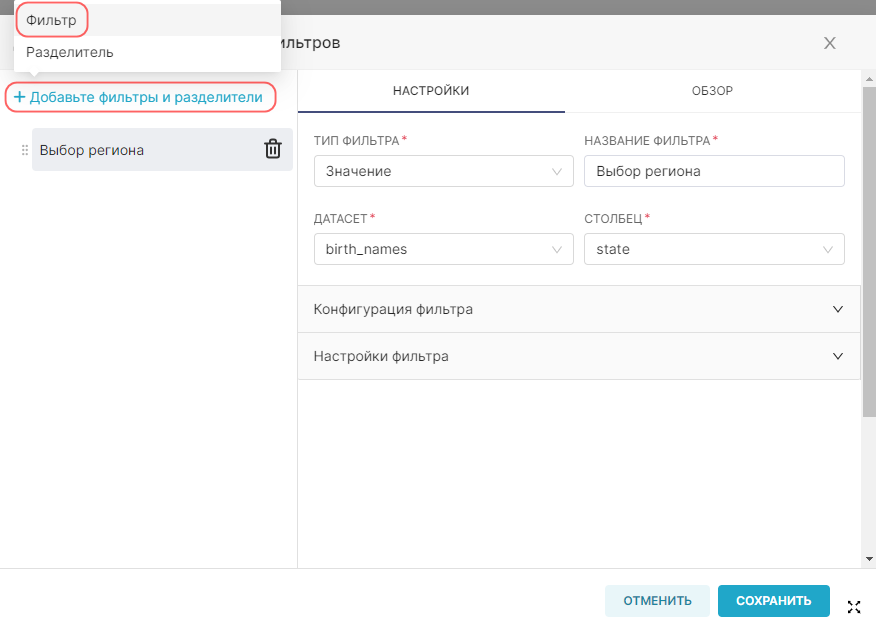
5. Создайте ещё один фильтр типа Значение (Value) с названием Выбор имени, который использует столбец name. Также, выберите параметр Можно выбрать несколько значений (Can select multiple values) на панели Настройки фильтра (Filter Settings)..
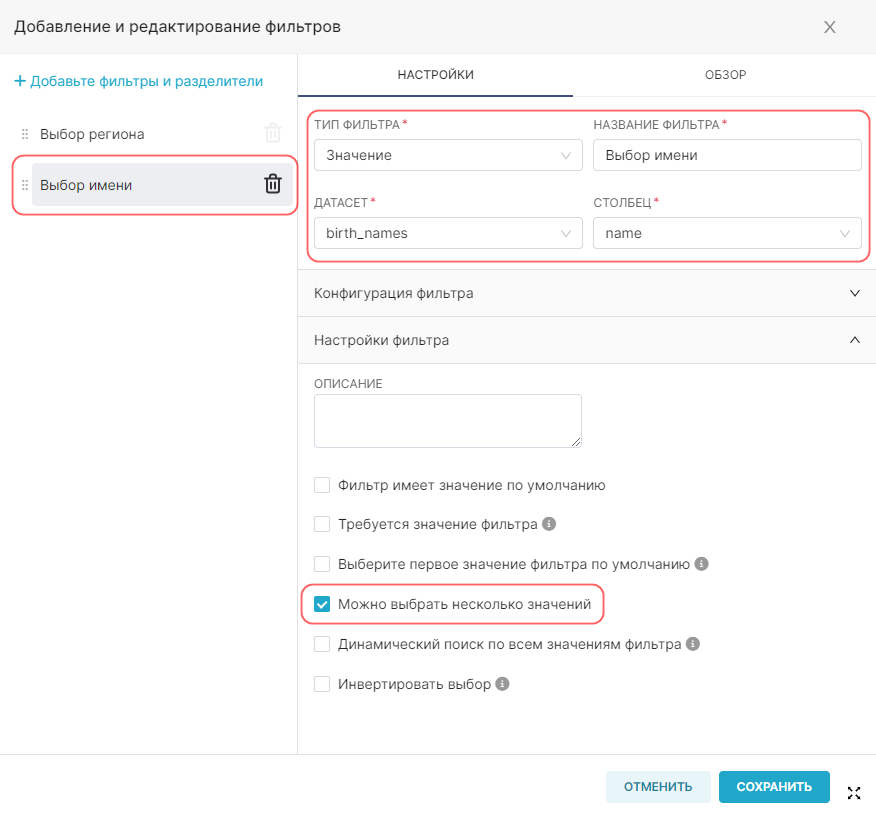
6. Нажмите кнопку Сохранить (Save).
В результате выполненных действий на дашборд добавлены два фильтра Выбор региона и Выбор имени:
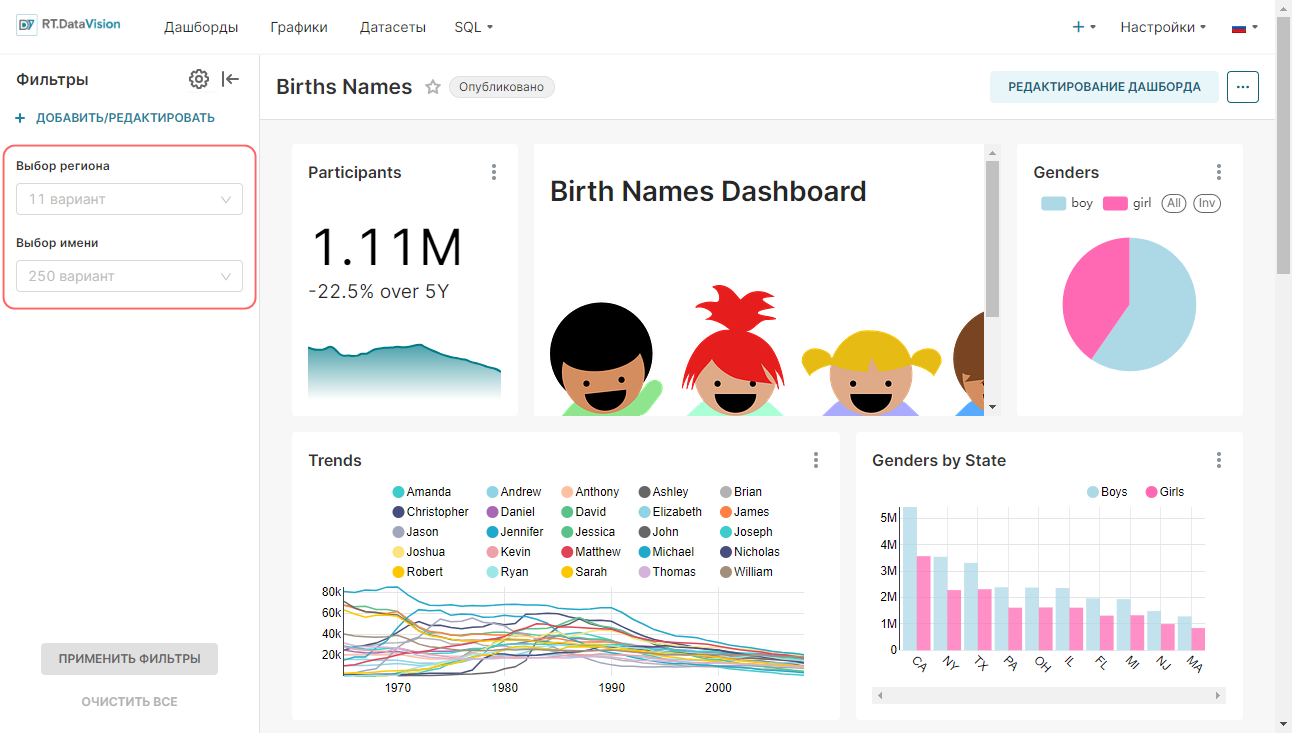
На этом этапе подготовительная работа для создания зависимости “родитель-потомок” завершена. Далее будет рассмотрена работа каждого параметра конфигурации.
¶ 7.3.4. Создание отношение “родитель-потомок”
Примечание. Опция доступна для типа фильтра Значение (Value).
Эта опция используется для превращения фильтра в подфильтр существующего фильтра. В этом примере будет создан фильтр name подфильтром фильтра state (т.е. фильтр state станет родительским). Такая схема позволит пользователям выбрать один или несколько регионов, и уточнить выборку, предложив выбрать одно или несколько имён в выбранном регионе.
Для создания отношения “родитель-потомок”:
1. Выберите фильтр Выбор имени.
2. Установите признак Значения зависят от других фильтров (Values are dependent on other filters) на панели Конфигурация фильтра (Filter Configuration).
3. Укажите значение Выбор региона в качестве родительского фильтра в поле Значения зависят от (Values Dependent On)
4. Нажмите кнопку Сохранить (Save).
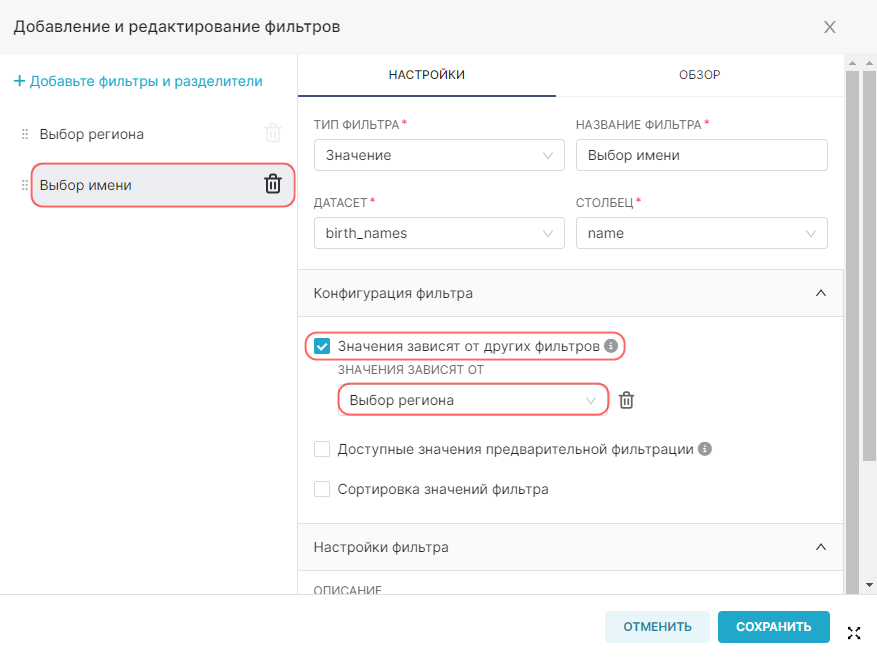
В разделе фильтров панели инструментов количество доступных параметров отображается в каждом раскрывающемся поле. На приведённом ниже рисунке представлен 11 вариантов регионов и 250 вариантов имён:
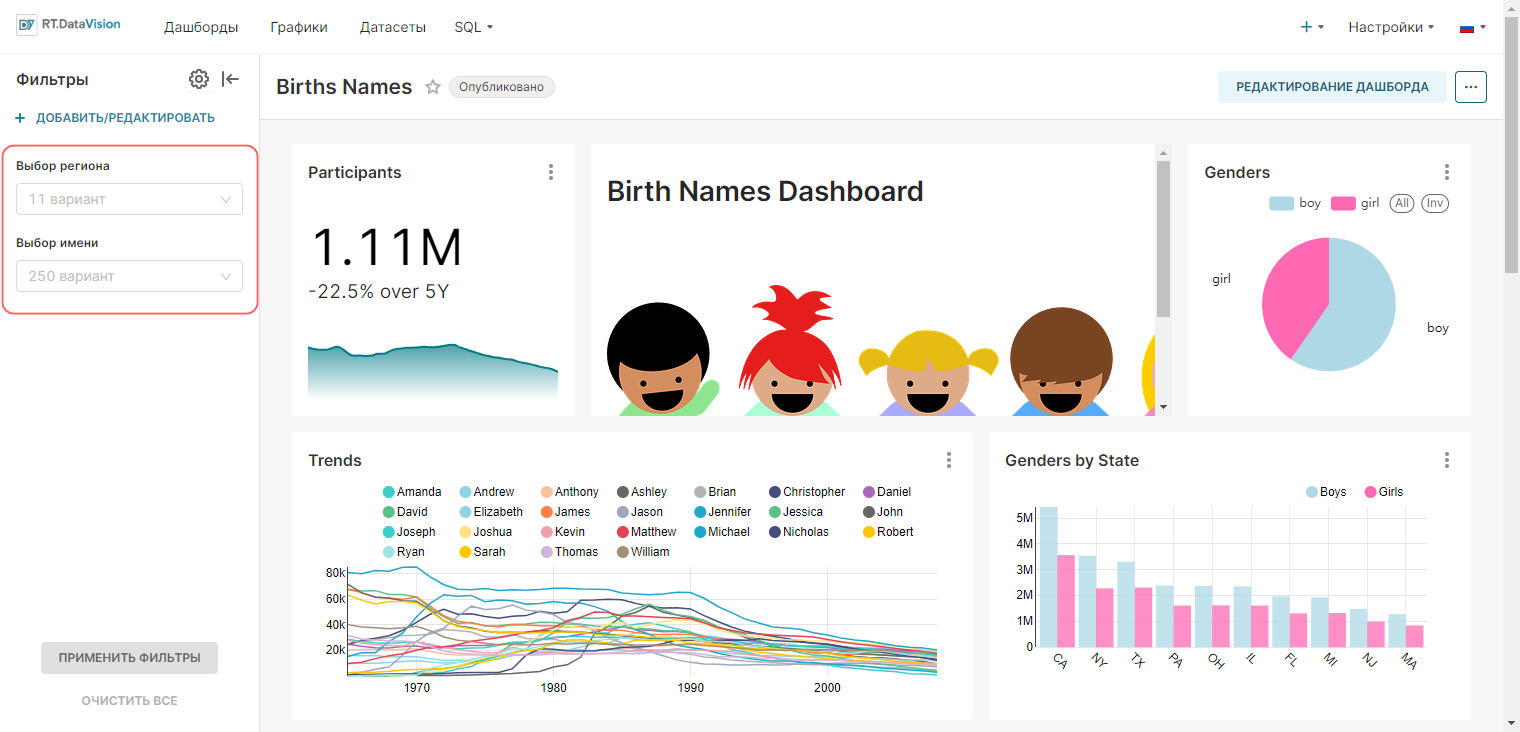
Родительский фильтр — Выбор региона, поэтому при выборе региона (например, MI) поле Выбор имени автоматически обновляется и отображает только те имена, которые использовались в выбранном регионе. В примере ниже в регионе MI использовались 243 имени:
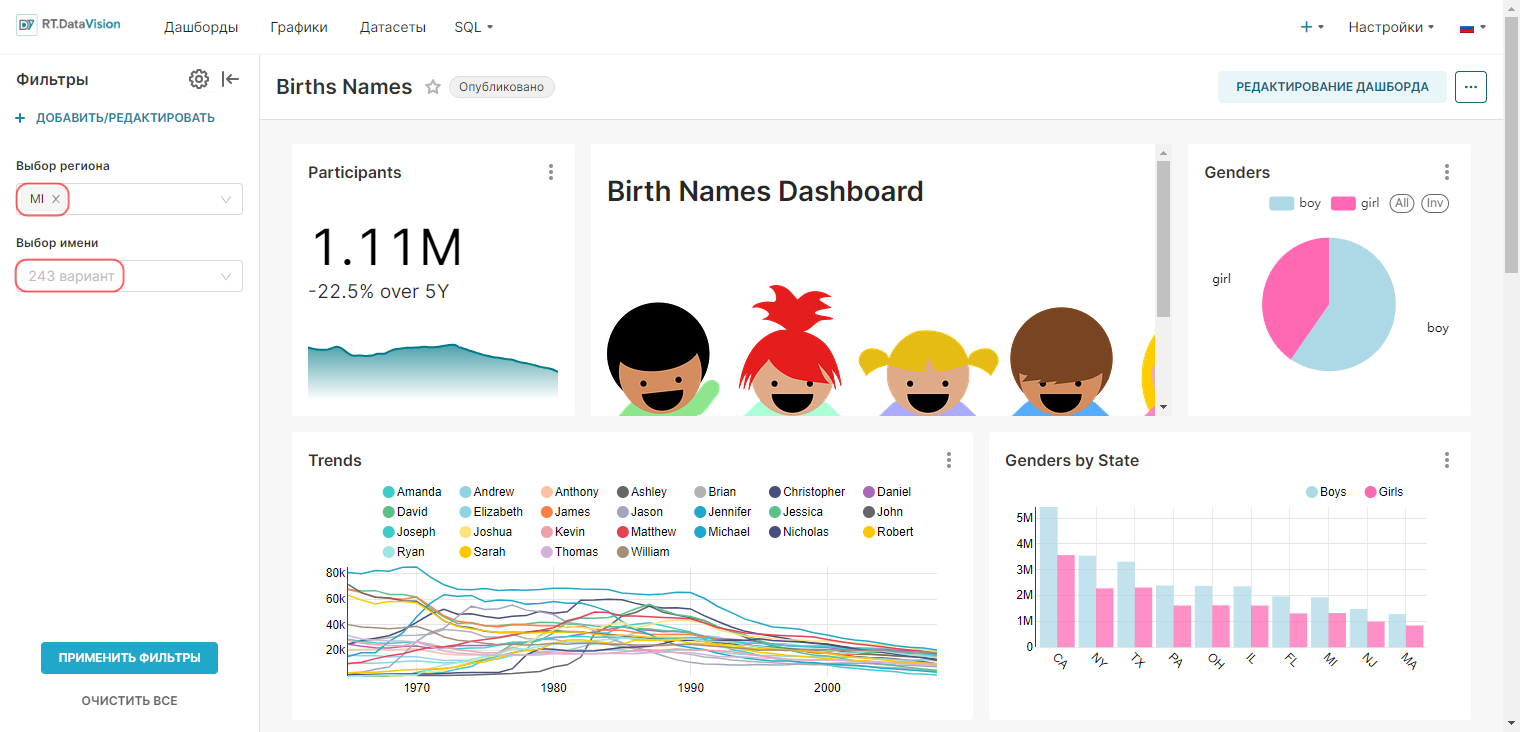
Поле Выбор имени позволяет выбрать более одного параметра (например, Aaron, Abigail и Adam) из-за включенного признака Можно выбрать несколько значений (Can select multiple values). После выбора имен необходимо нажать кнопку Применить фильтры (Apply Filters). Графики дашборда обновятся и отобразят результаты, соответствующие выбранным критериям:
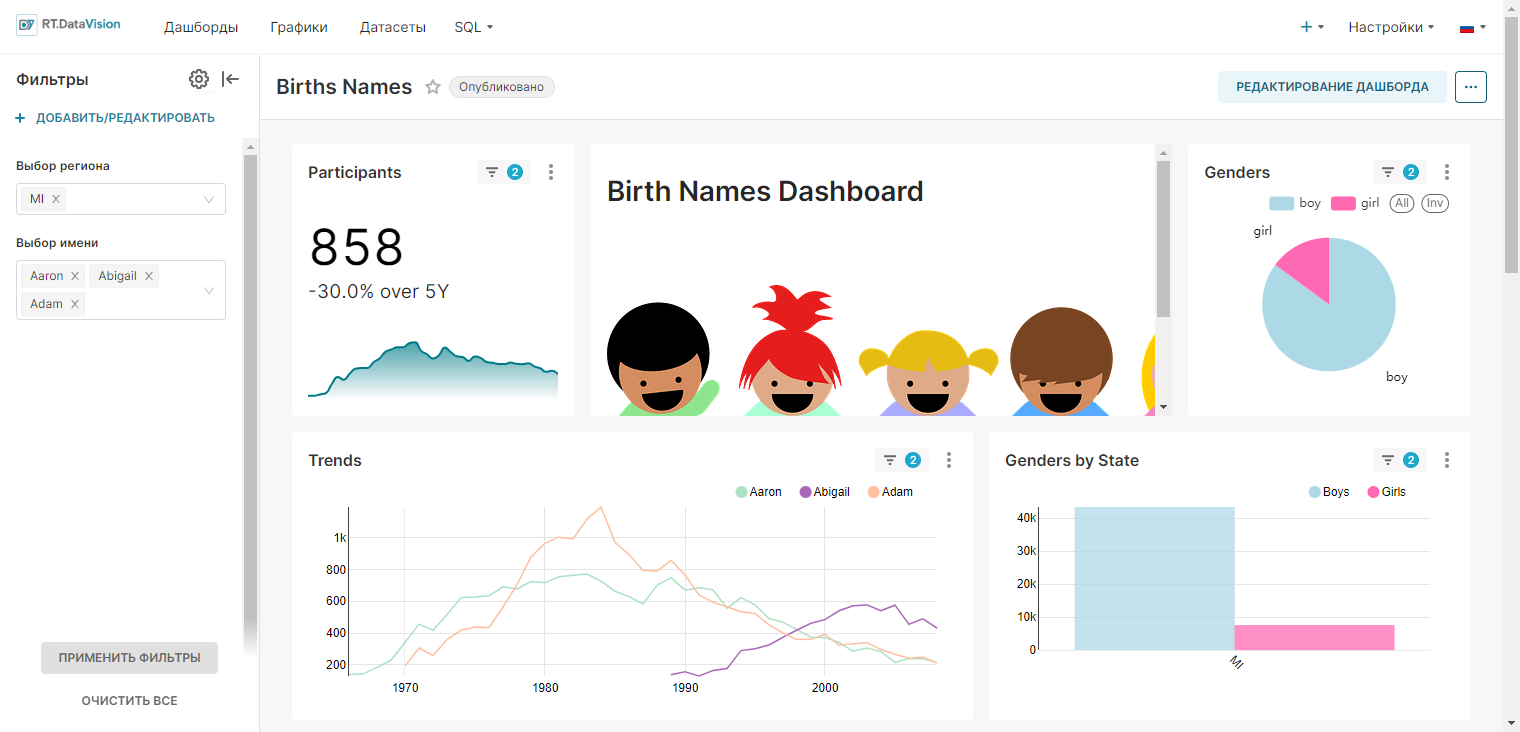
Фильтры “родитель-потомок” позволяют пользователям детализировать и уточнять свои выборки, создавая необходимые связи между несколькими фильтрами.
¶ 7.4. Данные предварительной фильтрации
¶ 7.4.1. Общая информация
В этом разделе описано ограничение доступности значений в фильтре с помощью параметра конфигурации Доступные значения предварительной фильтрации (Pre-filter available values).
¶ 7.4.2. Параметры конфигурации фильтра
Для этих типов фильтров доступны следующие параметры конфигурации:
| Значение (Value) | Числовой диапазон (Numerical range) | Период времени (Time Range) | Столбец с временем (Time Column) | Гранулярность времени (Time Grain) | |
|---|---|---|---|---|---|
| “Родитель-потомок” | + | ||||
| Доступные значения предварительной фильтрации | + | + | |||
| Сортировка значений фильтра | + | + | + | + | |
| Единственное значение | + |
¶ 7.4.3. Данные предварительной фильтрации
Примечание. Опция доступна для следующих типов фильтров: Значение (Value), Числовой диапазон (Numerical range)
В разделе 7.3 Фильтр “родитель-потомок” использовался признак Значения зависят от других фильтров (Values are dependent on other filters) для создания отношения “родитель-потомок” между фильтрами значений Выбор региона и Выбор имени. В фильтре Выбор региона все доступные значения регионов были представлены в виде выбираемых опций в раскрывающемся списке (например, CA, FL, IL и т.д.). Если необходимо, например, отображать только значения самых густонаселённых регионов в фильтре Выбор региона, то можно использовать признак Доступные значения предварительной фильтрации (Pre-filter available values). Этот параметр ограничивает количество выбираемых значений в фильтре.
Как это работает:
1. Выберите созданный ранее фильтр Выбор региона на панели Конфигурация фильтра (Filter Configuration) и установите признак Доступные значения предварительной фильтрации (Pre-filter available values). Появится поле Предварительный фильтр (Pre-Filter).
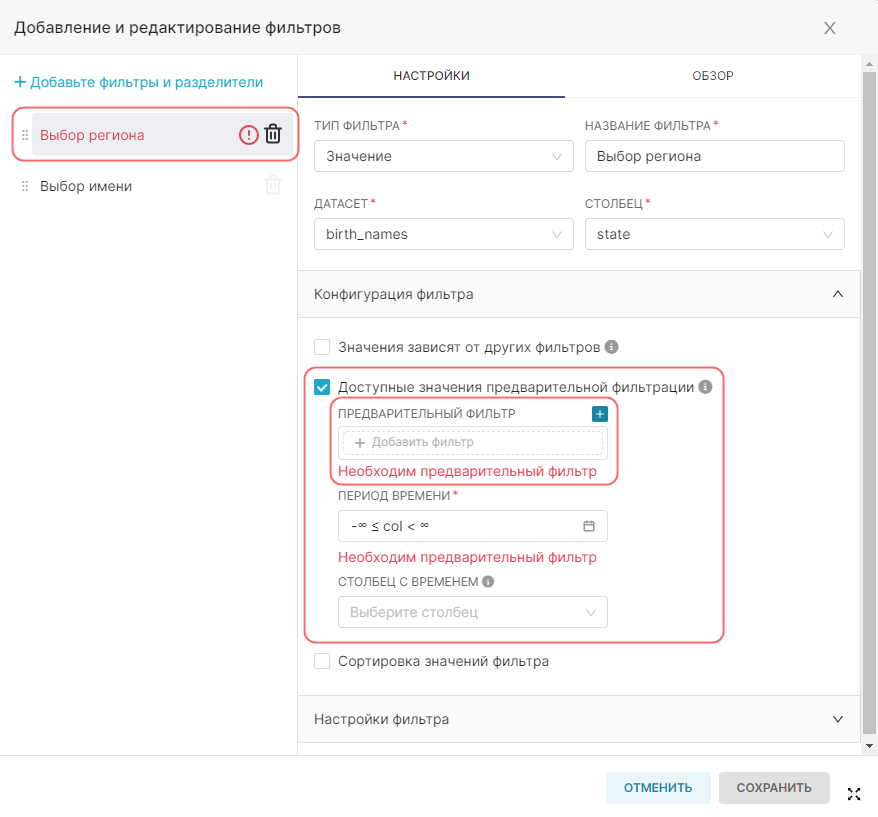
2. Нажмите кнопку + Добавить фильтр (+ Add filter) в поле Предварительный фильтр (Pre-Filter). Появится подменю с парой вкладок: Простые (Simple) и Пользовательский SQL (Custom SQL).
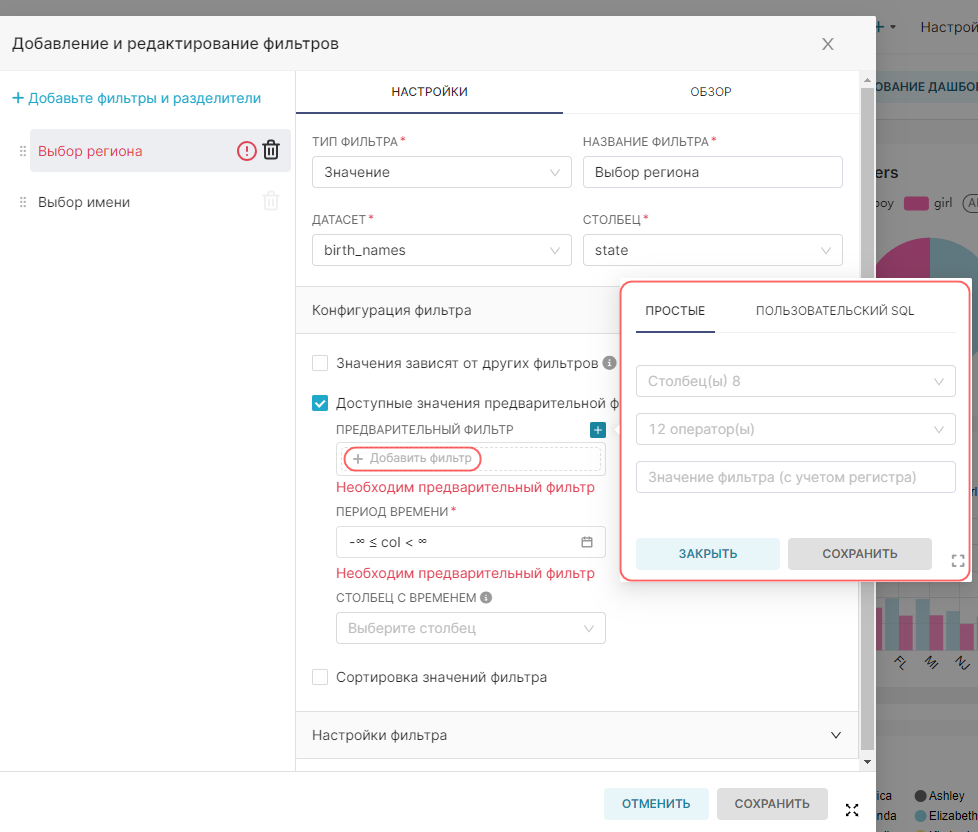
Вкладка Простые (Simple) позволяет сопоставить столбец с определённым значением с помощью операторов (например, “равно”, “не равно”, “<”, “>” и т.д.). Вкладка Пользовательский SQL (Custom SQL) позволяет ввести собственный код SQL, чтобы указать предварительно отфильтрованные значения для столбца.
Например, если необходимо ограничить параметры только CA, TX, NY и FL, то для этого выберите столбец state, оператор In (поскольку вариантов будет несколько) и значения CA, TX, NY и FL. Если необходимо также фильтровать по временному диапазону, то нажмите кнопку Без фильтра (No filter) и настройте соответствующие параметры.
3. Нажмите кнопку Сохранить (Save) для предварительного фильтра.
4. Нажмите кнопку Сохранить (Save) для фильтра в целом.
Данная конфигурация выглядит следующим образом:
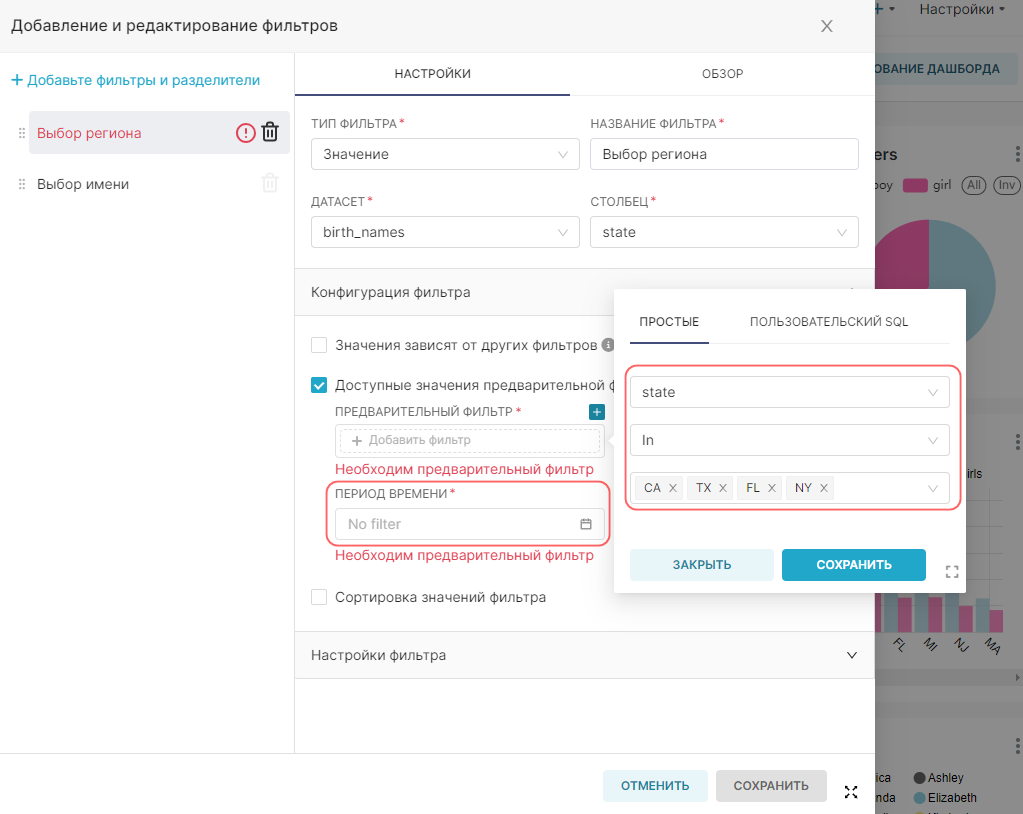
Фильтр Выбор региона теперь отображает только четыре предварительно отфильтрованных значения:
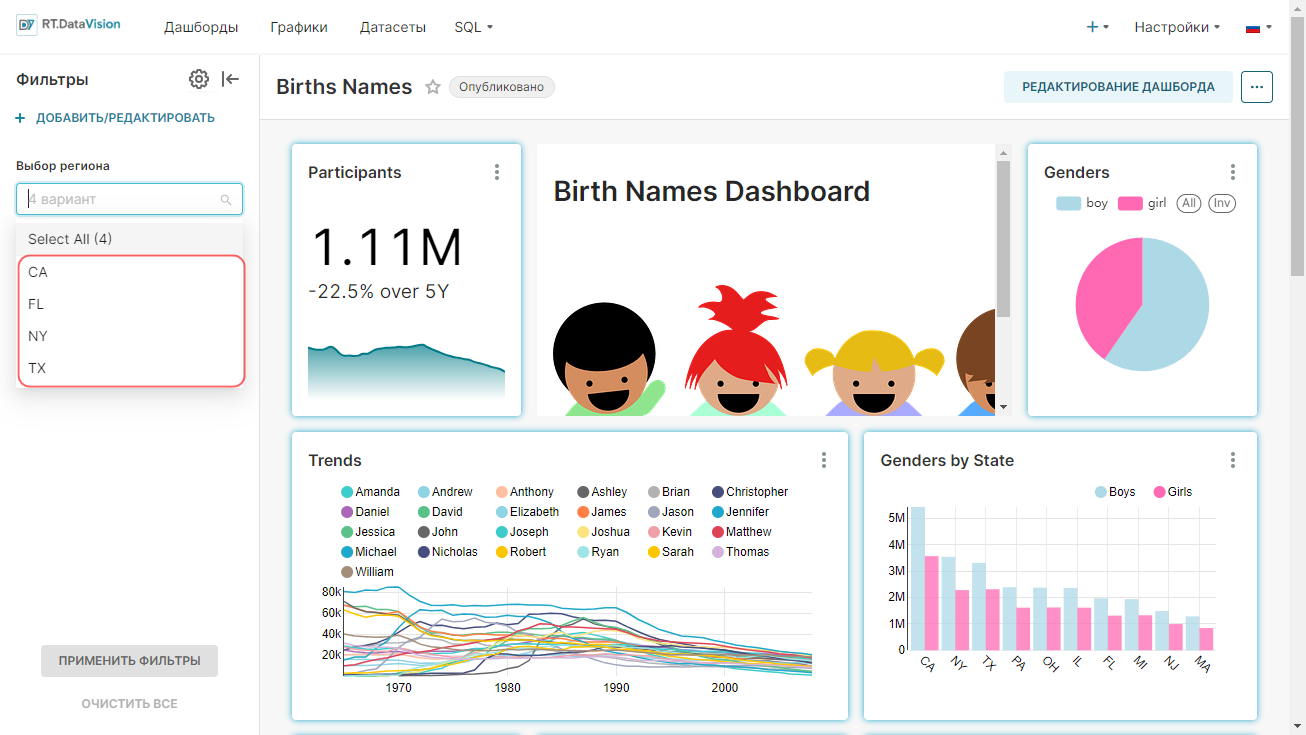
¶ 7.5. Сортировка значений фильтра
¶ 7.5.1. Общая информация
В этом разделе описано использование параметра конфигурации Сортировка значений фильтра (Sort filter values) для сортировки данных в порядке возрастания или убывания, а также сортировка по выбранной метрике.
¶ 7.5.2. Параметры конфигурации фильтра
Для этих типов фильтров доступны следующие параметры конфигурации:
| Значение (Value) | Числовой диапазон (Numerical range) | Период времени (Time Range) | Столбец с временем (Time Column) | Гранулярность времени (Time Grain) | |
|---|---|---|---|---|---|
| “Родитель-потомок” | + | ||||
| Доступные значения предварительной фильтрации | + | + | |||
| Сортировка значений фильтра | + | + | + | + | |
| Единственное значение | + |
¶ 7.5.3. Сортировка значений фильтра
Примечание. Опция доступна для следующих типов фильтров: Значение (Value), Период времени (Time Range), Столбец с временем (Time Column), Гранулярность времени (Time Grain).
Параметр Сортировка значений фильтра (Sort filter values) позволяет сортировать значения в столбце фильтра по возрастанию или убыванию, а также сортировать по доступной метрике из датасета. Для использования этой функции:
1. Выберите Сортировка значений фильтра (Sort filter values).
2. Укажите как должны сортироваться значения: Сортировка по возрастанию (Sort ascending) или Сортировка по убыванию (Sort descending). Также, существует возможность сортировать по метрике датасета.
В примере ниже отсортирован фильтр Выбор региона по убыванию значений метрики sum__num. Конфигурация выглядит следующим образом:
Фильтр Выбор региона на дашборде будет отображать значения регионов в порядке убывания значений выбранной метрики, т.е. наверху списка будут отображаться регионы с наибольшим количеством зарегистрированных рождений.
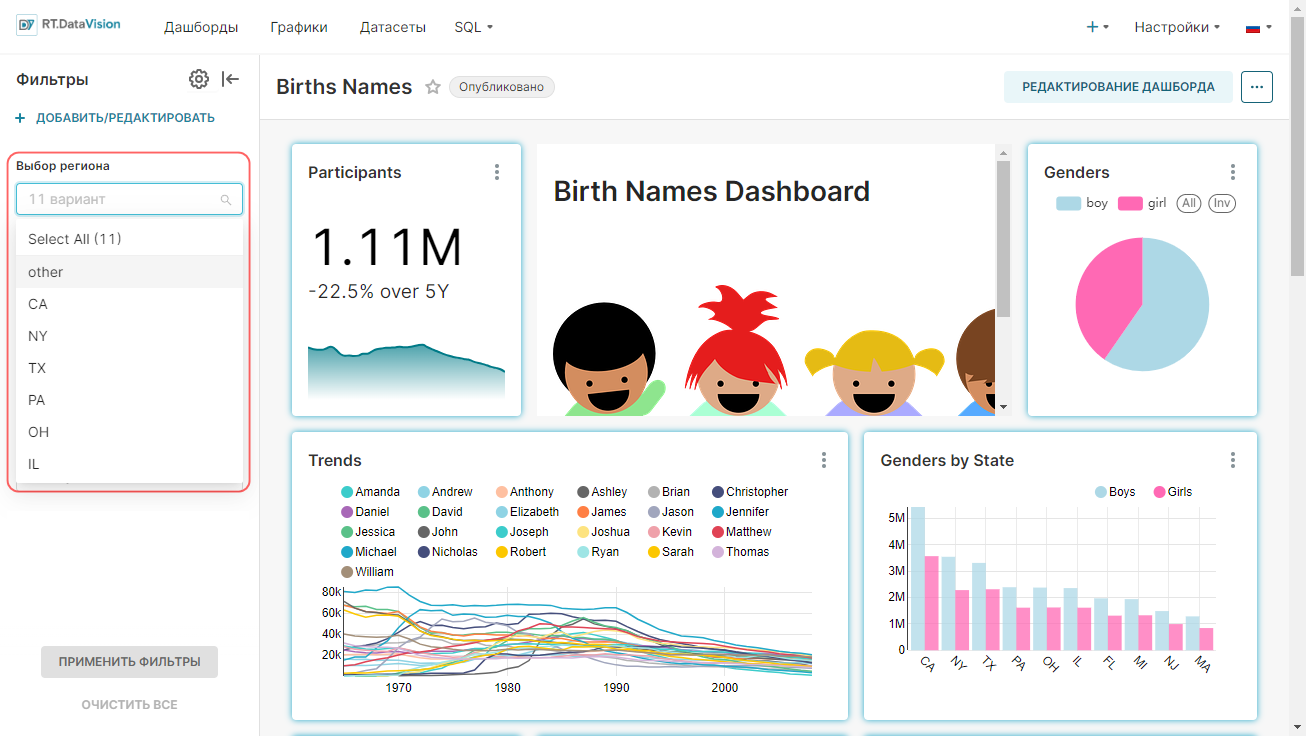
¶ 7.6. Диапазон единственного значения
¶ 7.6.1. Общая информация
В этом разделе описан параметр конфигурации Единое значение (Single value), который относится к фильтру Числовой диапазон (Numerical range) и используется для настройки одного типа значения для минимальных, максимальных и точных значений.
¶ 7.6.2. Параметры конфигурации фильтра
Для этих типов фильтров доступны следующие параметры конфигурации:
| Значение (Value) | Числовой диапазон (Numerical range) | Период времени (Time Range) | Столбец с временем (Time Column) | Гранулярность времени (Time Grain) | |
|---|---|---|---|---|---|
| “Родитель-потомок” | + | ||||
| Доступные значения предварительной фильтрации | + | + | |||
| Сортировка значений фильтра | + | + | + | + | |
| Единственное значение | + |
¶ 7.6.3. Диапазон единственного значения
Примечание. Опция доступна для этого типа фильтра: Числовой диапазон (Numerical range).
Параметр Единое значение (Single value) относится к числовым диапазонам и используется для ограничения числа или диапазона, которые можно указать в фильтре числового диапазона. При использовании необходимо убедится, что выбран тип фильтра Числовой диапазон (Numerical range).
На панели Конфигурация фильтра (Filter Configuration) выберите Единое значение (Single value) и укажите тип единственного значения:
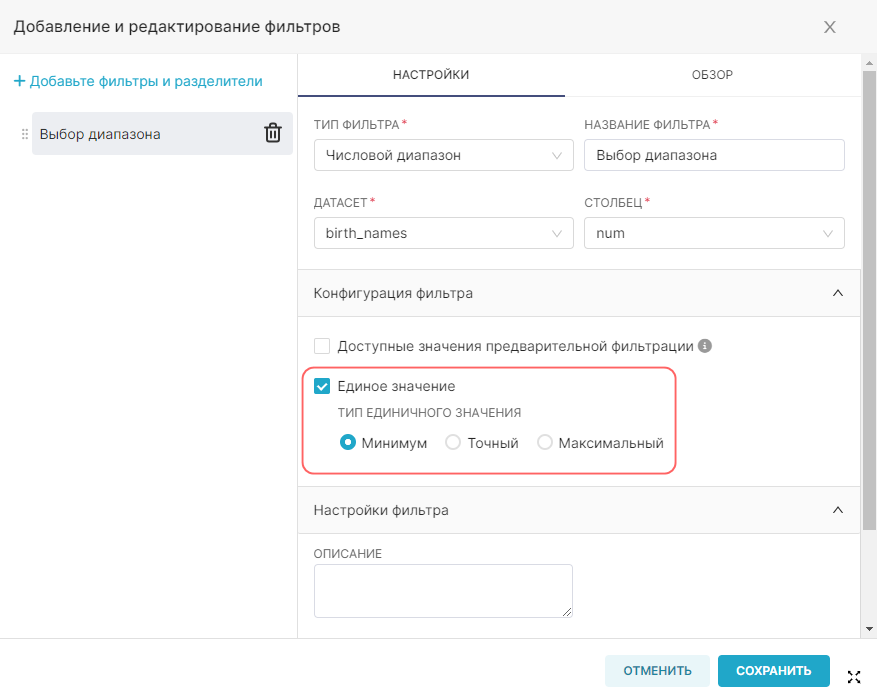
- Минимум (Minimum) — в фильтре числового диапазона есть только один ползунок, и он используется для выбора минимума (т.е. начальной точки) для диапазона. Например, если выбрано 11.4k, то все значения, большие или равные 11.4k, будут применены фильтром. Обратите внимание, что есть синяя подсветка, которая визуально отображает отфильтрованный диапазон.
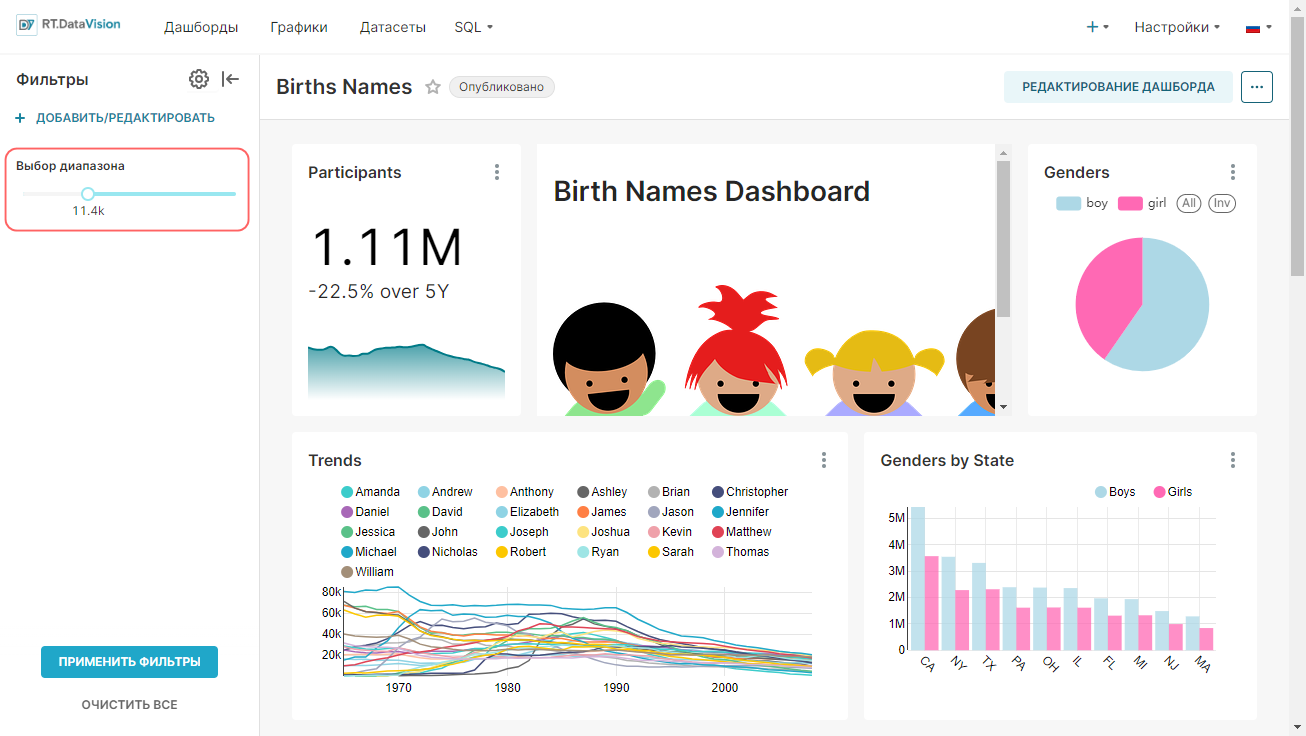
- Точный (Exact) — в фильтре числового диапазона есть только один ползунок, и он используется для выбора точного значения. Будут включены только данные графика, соответствующие выбранному значению. В этом случае синим подсвечивается только сам ползунок.
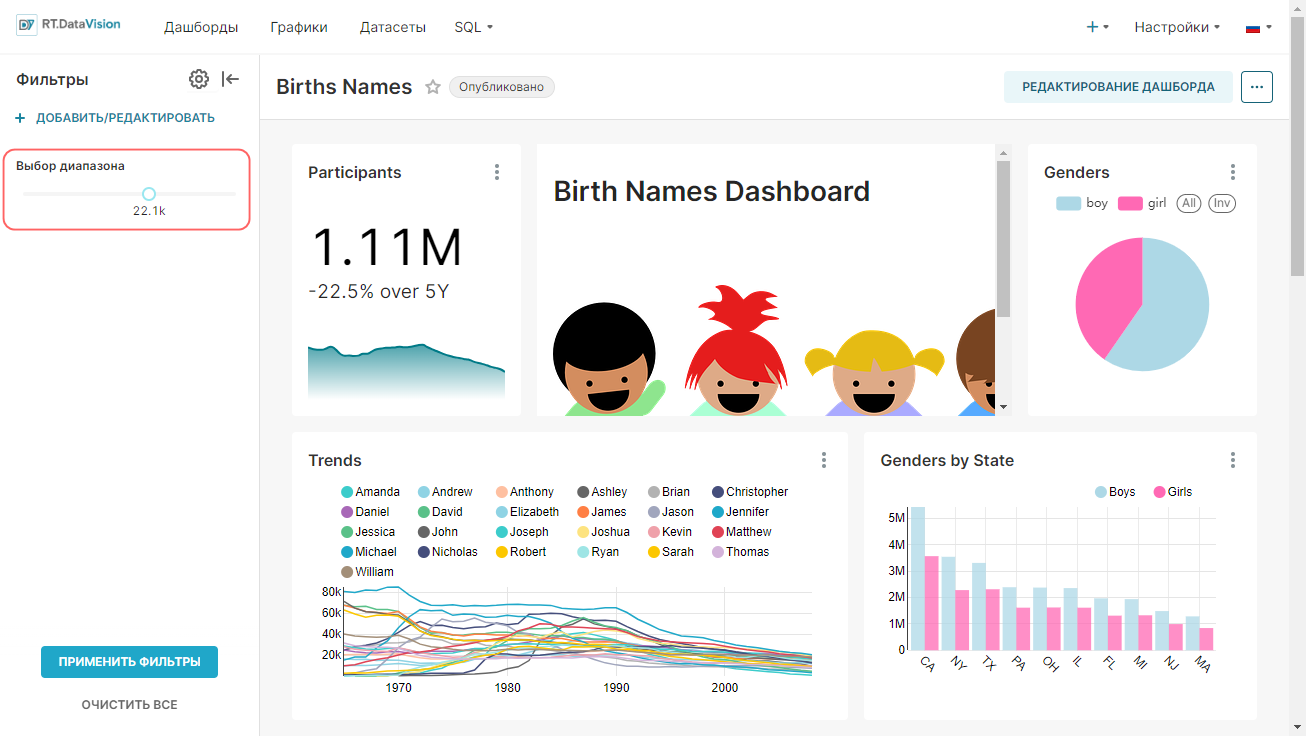
- Максимальный (Maximum) — в фильтре числового диапазона есть только один ползунок, и он используется для выбора максимума (т.е. конечной точки) диапазона. Например, если выбрано 28.7k, то все значения, меньшие или равные 28.7k, будут применены фильтром. Обратите внимание, что есть синяя подсветка, которая передаёт отфильтрованный диапазон.
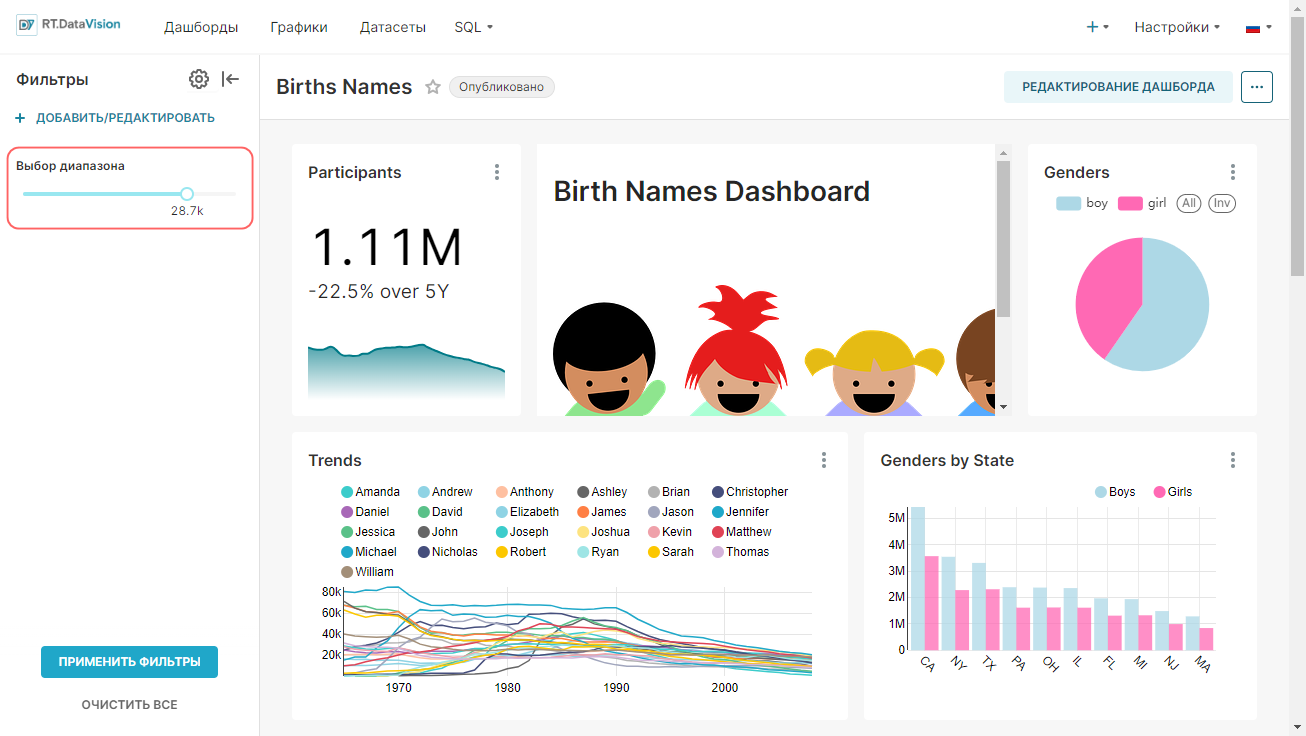
¶ 7.7. Подсказка фильтра
¶ 7.7.1. Общая информация
В этом разделе описано использование параметра Описание (Description) для создания всплывающей подсказки фильтра. Этот параметр полезен для объяснения назначения конкретных фильтров.
¶ 7.7.2. Настройки фильтра
Для этих типов фильтров доступны следующие параметры настройки:
| Значение (Value) | Числовой диапазон (Numerical range) | Период времени (Time Range) | Столбец с временем (Time Column) | Гранулярность времени (Time Grain) | |
|---|---|---|---|---|---|
| Описание | + | + | + | + | + |
| Значения по умолчанию | + | + | + | + | + |
| Требуемое значение | + | + | + | + | + |
| Выбор первого значения по умолчанию | + | ||||
| Выбор нескольких значений | + | ||||
| Динамический поиск | + | ||||
| Обратный выбор | + |
¶ 7.7.3. Подсказка фильтра (описание)
Примечание. Опция доступна для следующих типов фильтров: Все.
Параметр Описание (Description) используется для создания значка всплывающей подсказки, который показывает описательный текст при наведении курсора.
Для добавления подсказки/описания:
- Введите краткое описание фильтра в поле Описание (Description).
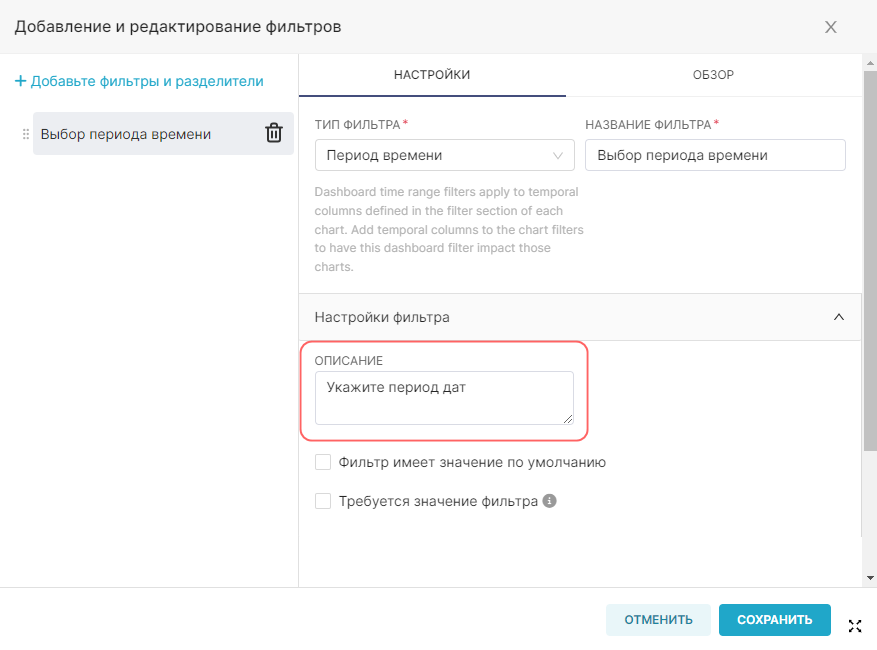
2. Нажмите кнопку Сохранить (Save).
Пример подсказки/описания:
¶ 7.8. Управление значениями
¶ 7.8.1. Общая информация
В этом разделе описаны следующие настройки фильтров, позволяющие управлять значениями в фильтрах:
- Значение по умолчанию и выбор нескольких значений;
- Обязательное значение фильтра;
- Выбор первого значения фильтра по умолчанию;
- Динамический поиск по всем значениям фильтра;
- Обратный выбор.
¶ 7.8.2. Настройки фильтра
Для этих типов фильтров доступны следующие параметры настройки:
| Значение (Value) | Числовой диапазон (Numerical range) | Период времени (Time Range) | Столбец с временем (Time Column) | Гранулярность времени (Time Grain) | |
|---|---|---|---|---|---|
| Описание | + | + | + | + | + |
| Значения по умолчанию | + | + | + | + | + |
| Обязательное значение | + | + | + | + | + |
| Выбор первого значения по умолчанию | + | ||||
| Выбор нескольких значений | + | ||||
| Динамический поиск | + | ||||
| Обратный выбор | + |
¶ 7.8.3. Значения по умолчанию и выбор нескольких значений
Примечание. Для этих типов фильтров доступны параметры: Все (значения по умолчанию) | Значение (Value) (выбор нескольких значений).
Параметр Фильтр имеет значение по умолчанию (Filter has default value) позволяет выбрать значения по умолчанию для фильтра. При выборе этого параметра отобразиться раскрывающееся меню Значение по умолчанию (Default Value), которое заполняется данными из выбора, сделанного в поле Столбец (Column) (при использовании типов фильтров Значение (Value) и Числовой диапазон (Numerical range)).
Если выбран тип фильтра Период времени (Time Range), то можно выбрать значение диапазона времени по умолчанию. Если выбран тип фильтра Столбец с временем (Time Column), то можно выбрать значение столбца времени по умолчанию и так далее.
Необходимо выбрать параметр, который будет применяться в качестве значения по умолчанию.
Примечание. Если необходимо разрешить выбор более одного значения по умолчанию, то установите флажок Можно выбрать несколько значений (Can select multiple values).
Например, создайте фильтр Выбор региона с типом Значение (Value), использующий столбец state. Включив параметр Можно выбрать несколько значений (Can select multiple values), можно указать несколько значений по умолчанию в поле Фильтр имеет значение по умолчанию (Filter has default value). В этом примере выбраны регионы NY, CA и TX.
Пример такой конфигурации:
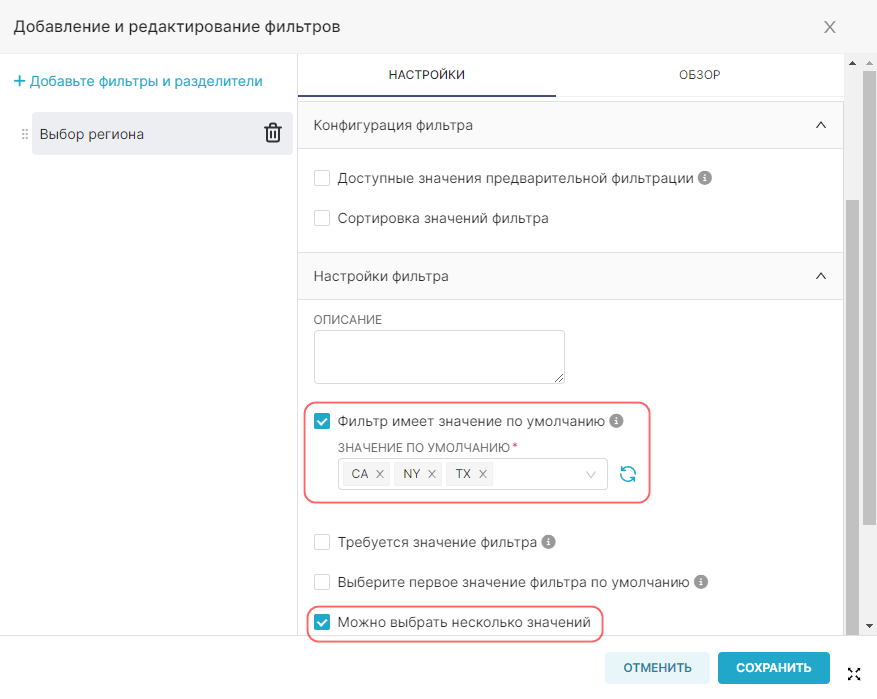
Фильтр Выбор региона будет иметь три предварительно выбранных значения по умолчанию:
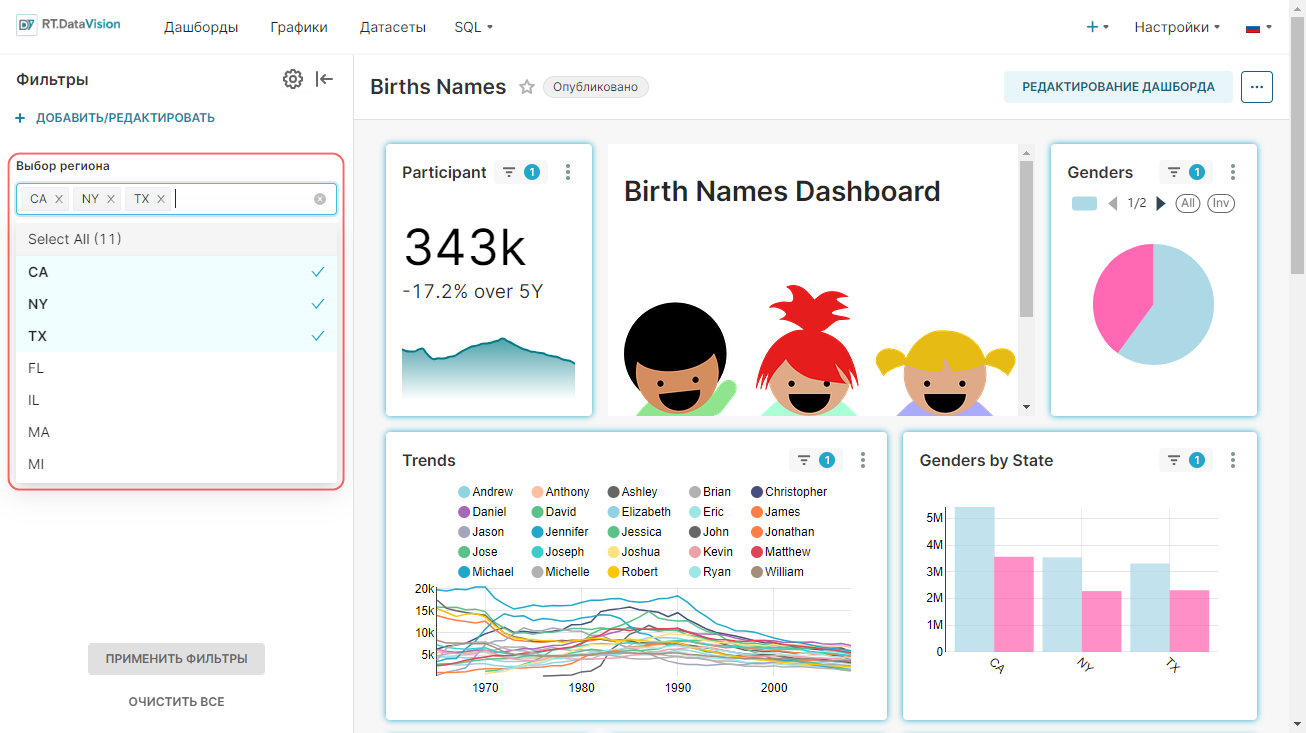
¶ 7.8.4. Обязательное значение фильтра
Примечание. Опция доступна для следующих типов фильтров: Все.
Если включён параметр Требуется значение фильтра (Filter value is required), то необходимо обязательно указать параметр фильтра, а после применить фильтр. Данный параметр работает только в паре с включённым параметром Фильтр имеет значение по умолчанию (Filter has default value), т.е. если включён первый параметр, то обязательно необходимо включить второй и указать в нём значения по умолчанию. Это сделано для повышения производительности, чтобы пользователь случайно не выполнил большой запрос.
Пример такой конфигурации:
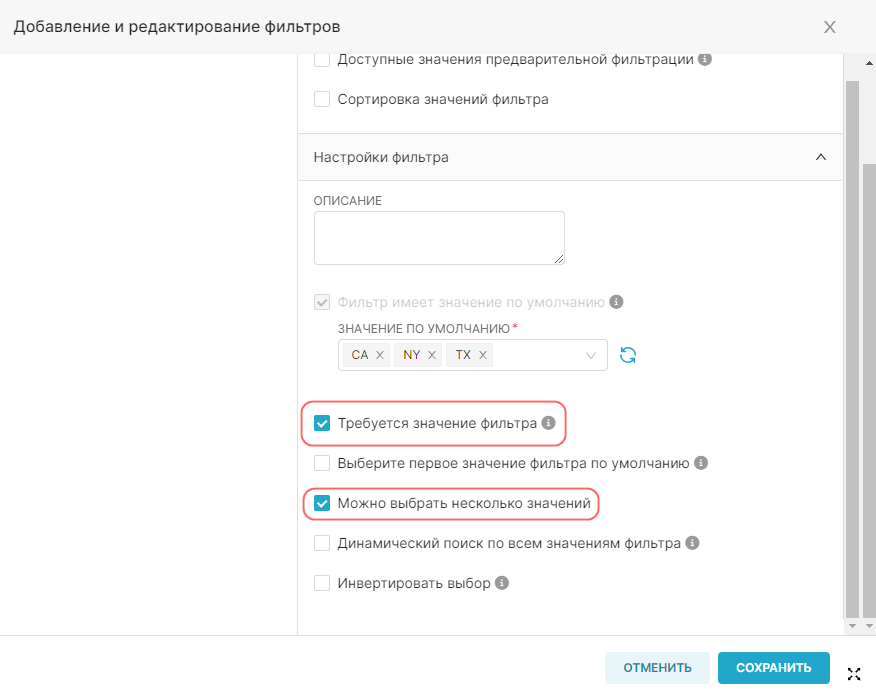
¶ 7.8.5. Выбор первого значения фильтра по умолчанию
Примечание. Опция доступна для этого типа фильтра: Значение (Value).
Параметр Выберите первое значение фильтра по умолчанию (Select first filter value by default) выбирает первый элемент, который появится в данных столбца, и отображает его как значение по умолчанию для фильтра. При использовании этого параметра поле Фильтр имеет значение по умолчанию (Filter has default value) не может быть установлено.
Параметр Выберите первое значение фильтра по умолчанию (Select first filter value by default) в основном используется как средство предотвращения случайного повторного выполнения затратных запросов на дашборде.
Параметр целесообразно применять в тех случаях, когда в качестве данных для дашборда используется датасет с часто изменяющимися значениями, например, дома для продажи на изменчивом рынке. Этот параметр позволяет RT.DataVision динамически выбирать первое значение, которое появляется в данных.
Пример конфигурации фильтра Выбор региона с включенным параметром Выберите первое значение фильтра по умолчанию (Select first filter value by default):
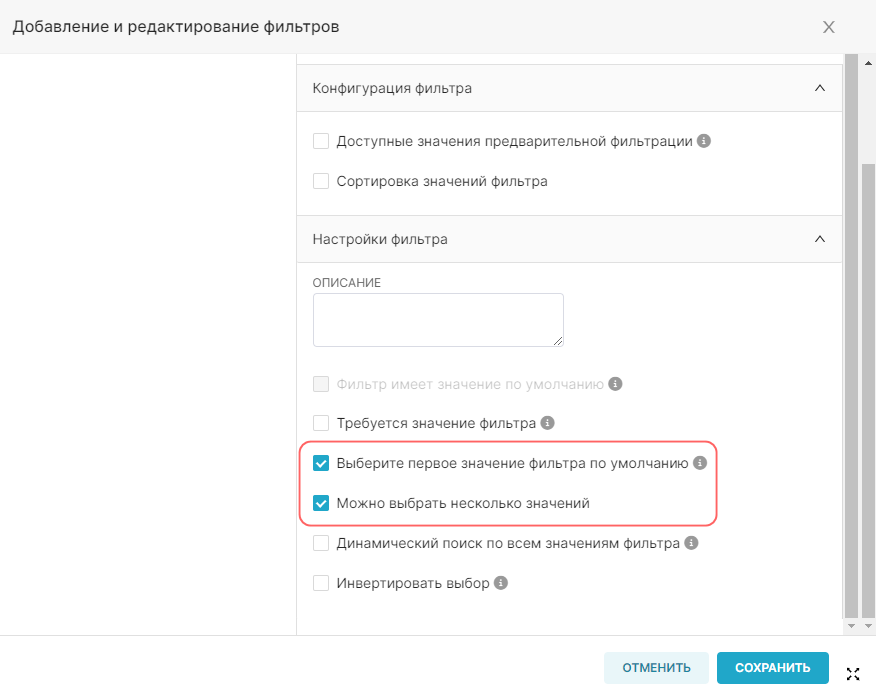
Первое значение данных в столбце state — CA. После сохранения значение CA автоматически предварительно выбирается в качестве значения по умолчанию для фильтра Выбор региона.
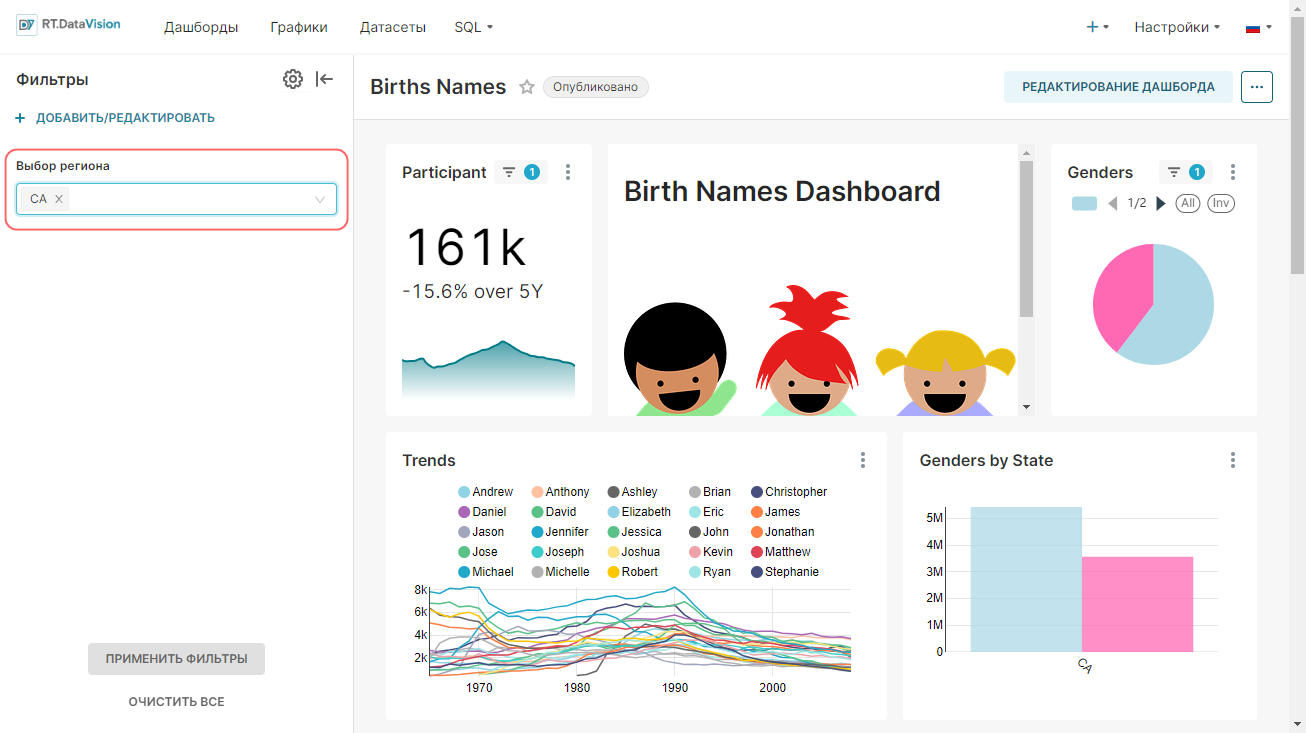
¶ 7.8.6. Динамический поиск по всем значениям фильтра
Примечание. Опция доступна для этого типа фильтра: Значение (Value).
Этот параметр включает динамический поиск при выборе значения фильтра (т.е. значения, соответствующие тексту при его вводе, будут отображаться как доступные для выбора значения).
Этот параметр расширенной настройки лучше всего использовать при работе с большим датасетом. По умолчанию каждый фильтр загружает не более 1000 вариантов при загрузке страницы. Если в столбце более 1000 значений, то включите параметр Динамический поиск по всем значениям фильтра (Dynamically search all filter values), чтобы поддерживать большие датасеты и сделать процесс выбора значений более удобным для конечного пользователя.
Внимание. Использование этого параметра может увеличить нагрузку на базу данных.
Пример конфигурации:
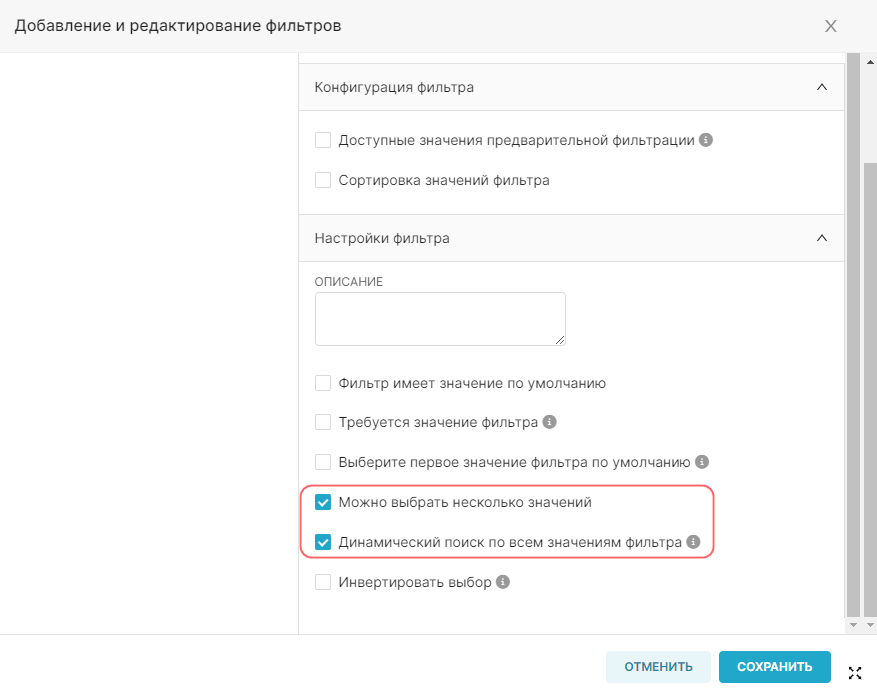
Раскрывающийся фильтр Выбор региона в поле Фильтры (Filter Name) выглядит следующим образом:
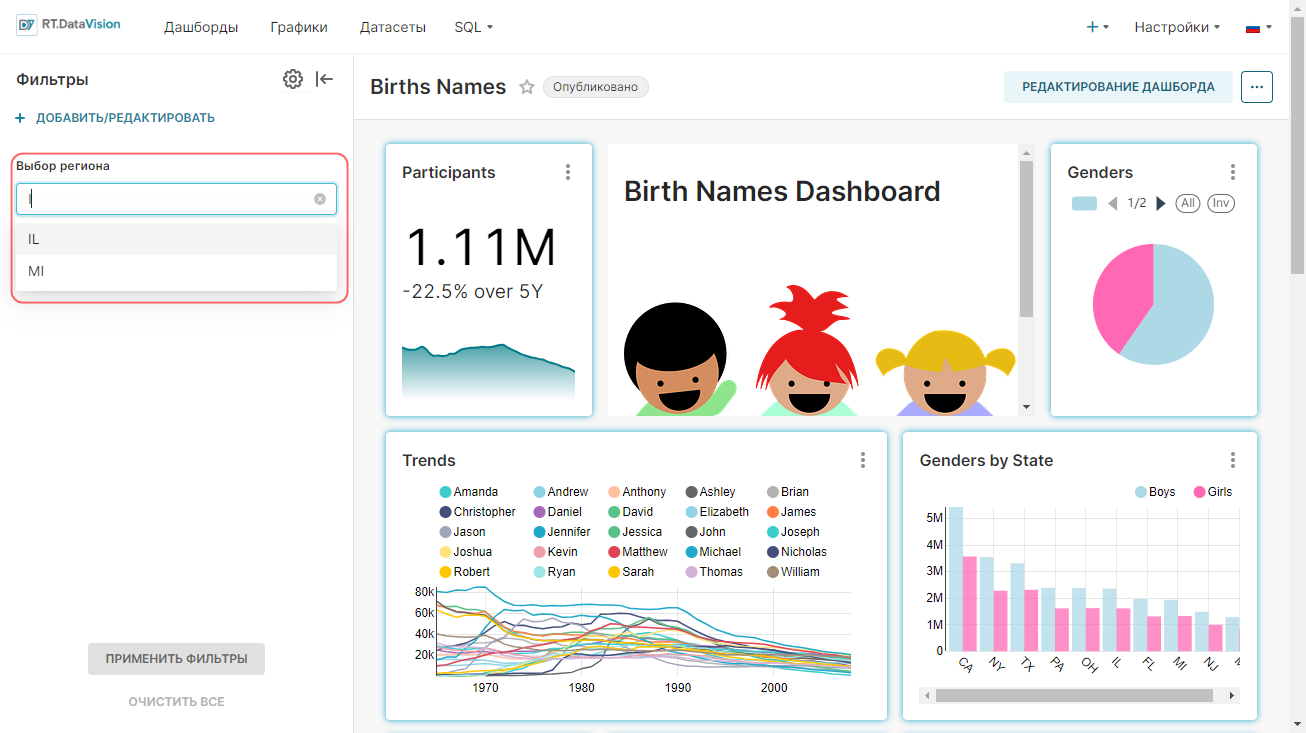
¶ 7.8.7. Обратный выбор
Примечание. Опция доступна для этого типа фильтра: Значение (Value).
Параметр обратного выбора позволяет исключить значения из фильтра, т.е. фильтровать по всем значениям, кроме выбранных.
Выберите параметр Inverse selection и сохраните настройки:
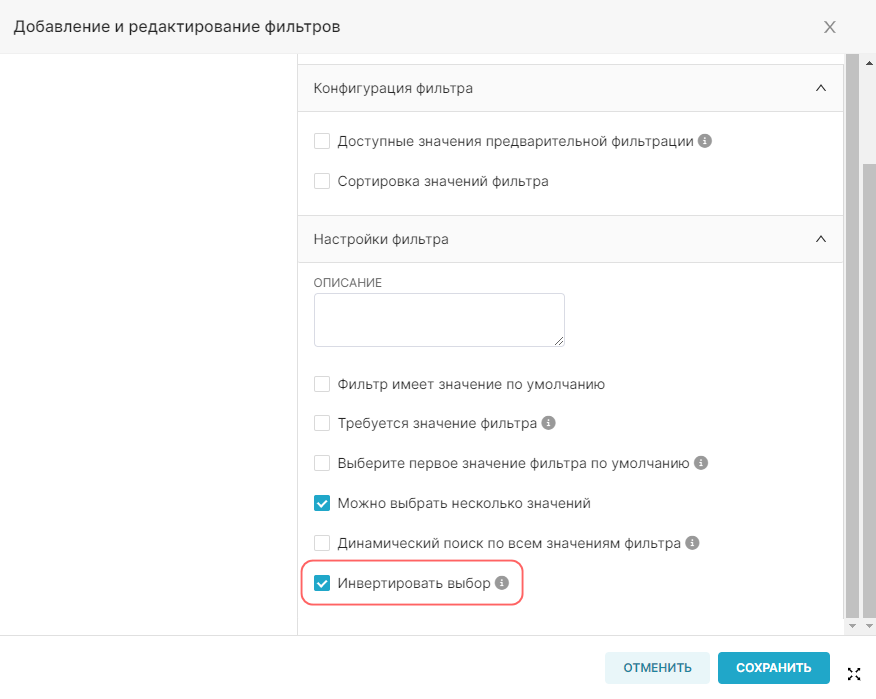
В приведённом ниже примере выбраны значения регионов CA, TX и NY. Обратите внимание на значок в виде кружка с полосой рядом с выбранными значками. При применении этого фильтра на дашборде будут отображаться все значения штатов, кроме тех, что были выбраны в фильтре.
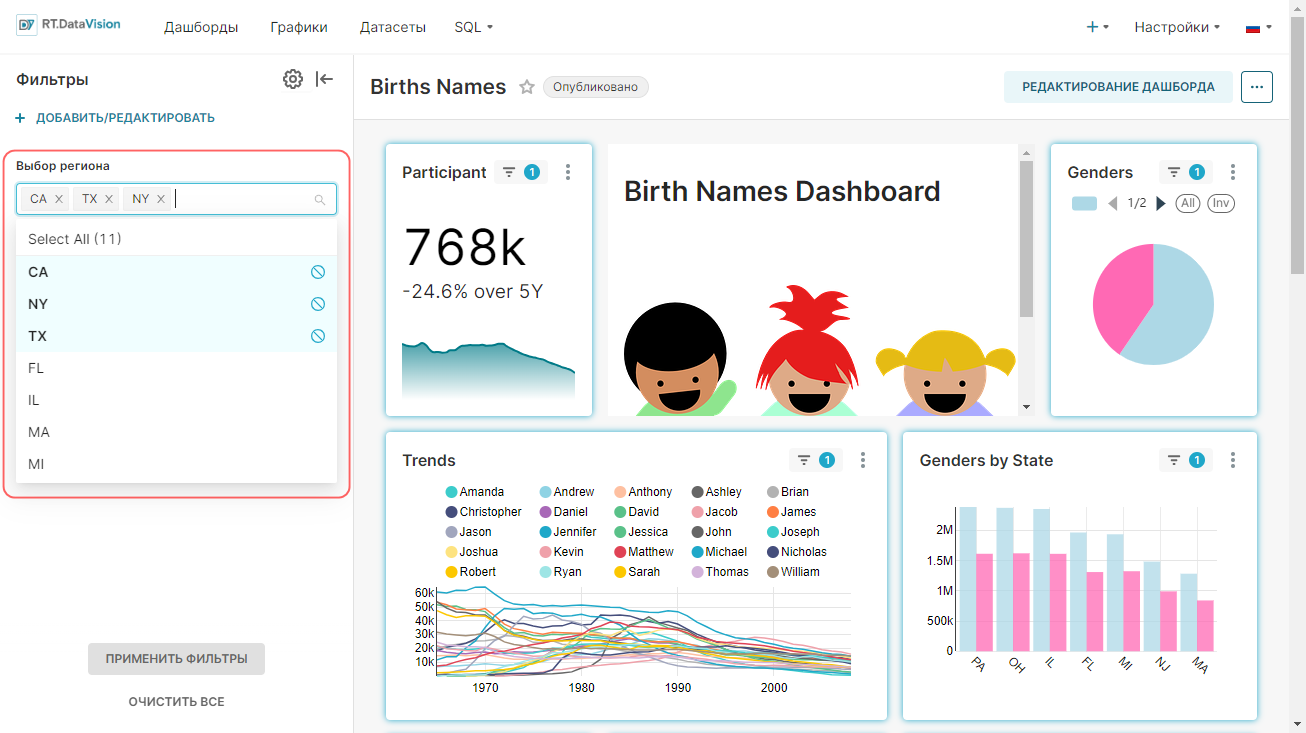
Чтобы отменить выбранное значение, просто выберите его повторно.
¶ 7.9. Область действия фильтра
¶ 7.9.1. Общая информация
В этом разделе описана концепция области действия, доступ к которой можно получить через вкладку Обзор (Scoping) окна Добавление и редактирование фильтра (Add and edit filters) для большинства типов фильтров, и её способностью обеспечивать контроль над применением фильтров к определённым графикам.
Чтобы получить доступ к вкладке Обзор (Scoping), откройте панель фильтров на дашборде и выберите + Добавить/Редактировать (+ Add/Edit Filters). В окне Фильтры (Filters) выберите фильтр, для которого необходимо настроить область действия, а затем перейдите на вкладку Обзор (Scoping).
Чтобы изменить область действия кросс-фильтра, см. раздел Кросс-фильтрация.
¶ 7.9.2. Область действия фильтра
Область действия обеспечивает детальный контроль над тем, какие графики подлежат применённому фильтру. Чтобы получить доступ к параметрам области действия, выберите вкладку Обзор (Scoping), как описано выше.
Область действия фильтров по умолчанию зависит от типа фильтра:
- Тип Гранулярность времени (Time Grain) — по умолчанию применяется ко всем графикам;
- Типы Значение (Value), Числовой диапазон (Numerical range), Столбец с временем (Time Column) и Период времени (Time Range) — применяются ко всем графикам, основанным на указанном датасете по умолчанию.
Если используемый дашборд основан на нескольких датасетах, то можно изменить область действия фильтра, чтобы его можно было использовать для всех графиков с общим именем столбца.
Например, если есть два датасета, лежащих в основе графиков (Глобальные продажи транспортных средств и Данные Всемирного банка), и эти датасеты имеют одно и то же имя столбца (country_abrv), то можно расширить область применения фильтра значений страны, чтобы применить его ко всем графикам, которые используют эти два датасета.
Область действия по умолчанию можно изменить, перейдя на вкладку Обзор (Scoping).
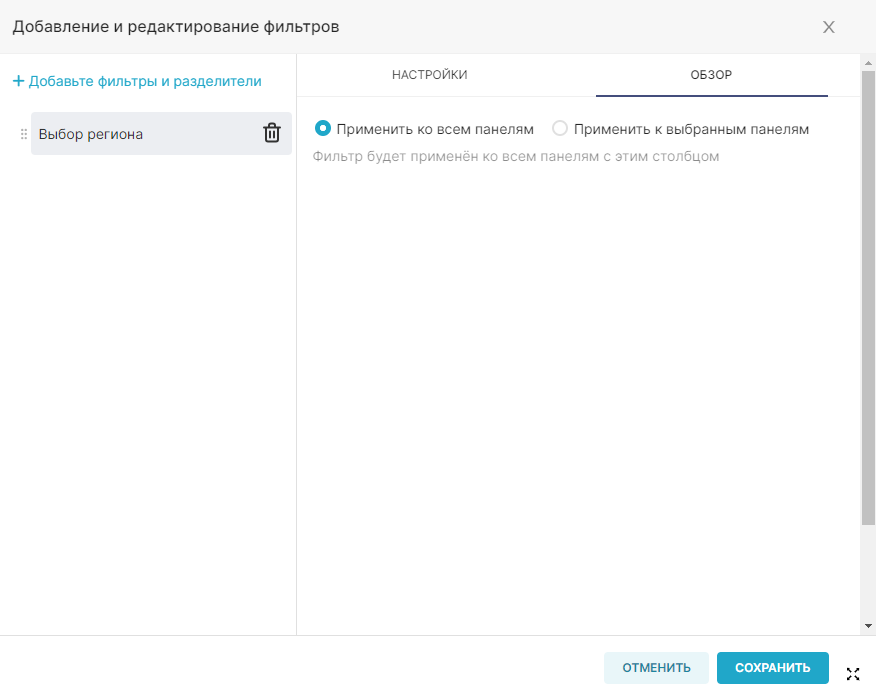
Чтобы указать отдельные графики, которые можно фильтровать, выберите Применить к выбранным панелям (Apply to specific panels).
Все графики и вкладки на дашборде будут отображены и представлены в формате иерархической структуры с установленным флажком для каждой из них.
Чтобы защитить график от фильтрации снимите соответствующий флажок. В приведённом ниже примере отменен выбор графика Genders by State, чтобы он при любой фильтрации отображал данные об именах в разрезе регионов.
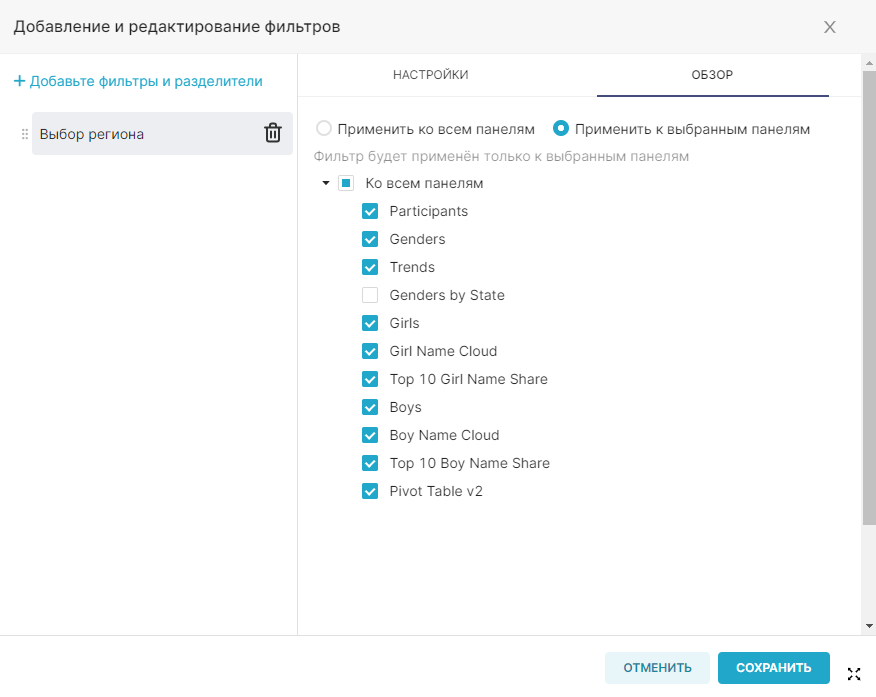
¶ 7.10. Перекрестная фильтрация
¶ 7.10.1. Общая информация
В этом разделе описана перекрестная фильтрация, которая позволяет вычленить элемент данных из графика (например, строку из таблицы, фрагмент из кругового графика), а затем применить его в качестве фильтра ко всем подходящим графикам на дашборде.
¶ 7.10.2. Подходящие графики
Использование перекрестной фильтрации поддерживают следующие графики:
- Все электронные графики (eCharts);
- Все графики временных рядов (Time Series Charts);
- Сводная таблица (Pivot Table);
- Таблица (Table Chart).
¶ 7.10.3. Включение\отключение перекрестной фильтрации
По умолчанию перекрестная фильтрация применяется ко всем подходящим графикам.
¶ 7.10.3.1 Включение\отключение перекрестной фильтрации на дашборде
Для включения или отключения перекрестной фильтрации на дашборде:
1. Перейдите в необходимый дашборд.
2. Нажмите на значок шестерёнки, расположенной на боковой панели Фильтр (Filter)
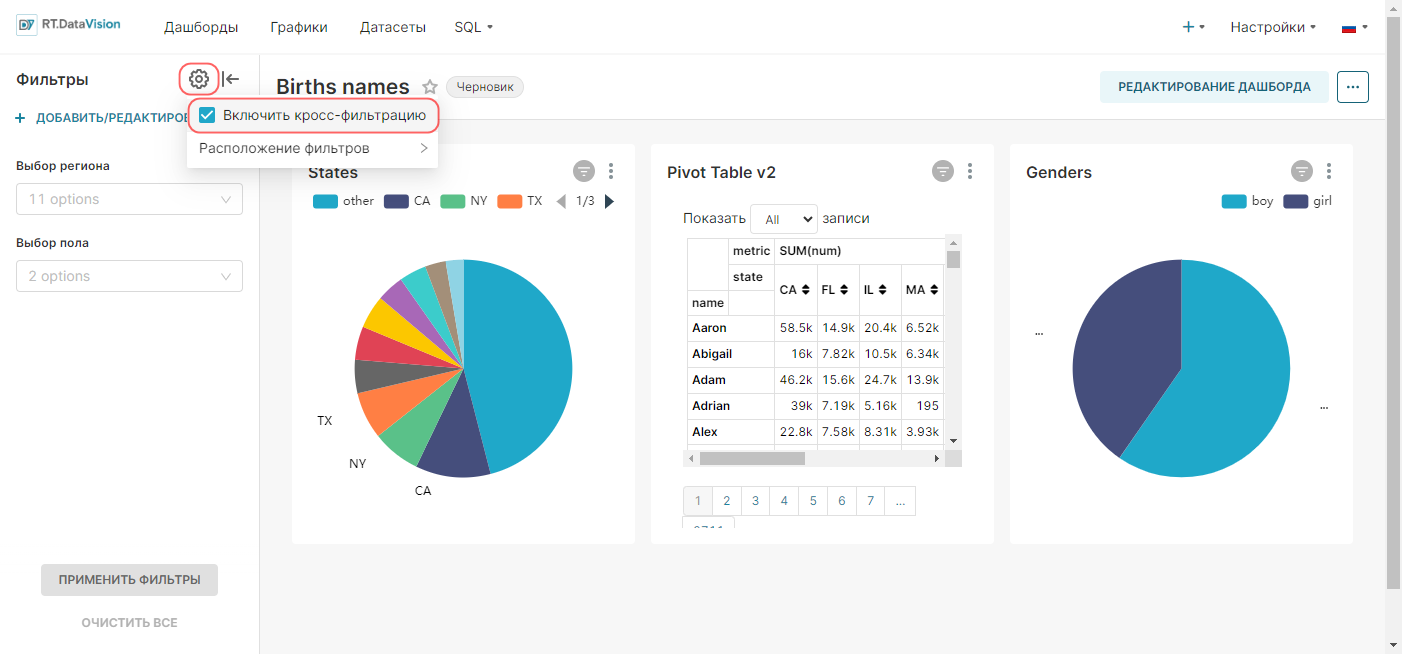
3. Установите или снимите признак Включить кросс-фильтрацию (Enable cross-filtering).
¶ 7.10.3.2 Включение\отключение перекрестной фильтрации на графике
Для включения или отключения перекрестной фильтрации на графике:
1. Перейдите в необходимый дашборд.
2. Нажмите на значок с вертикальным многоточием на графике и выберите Перекрестная фильтрация (Cross Filter Scoping).
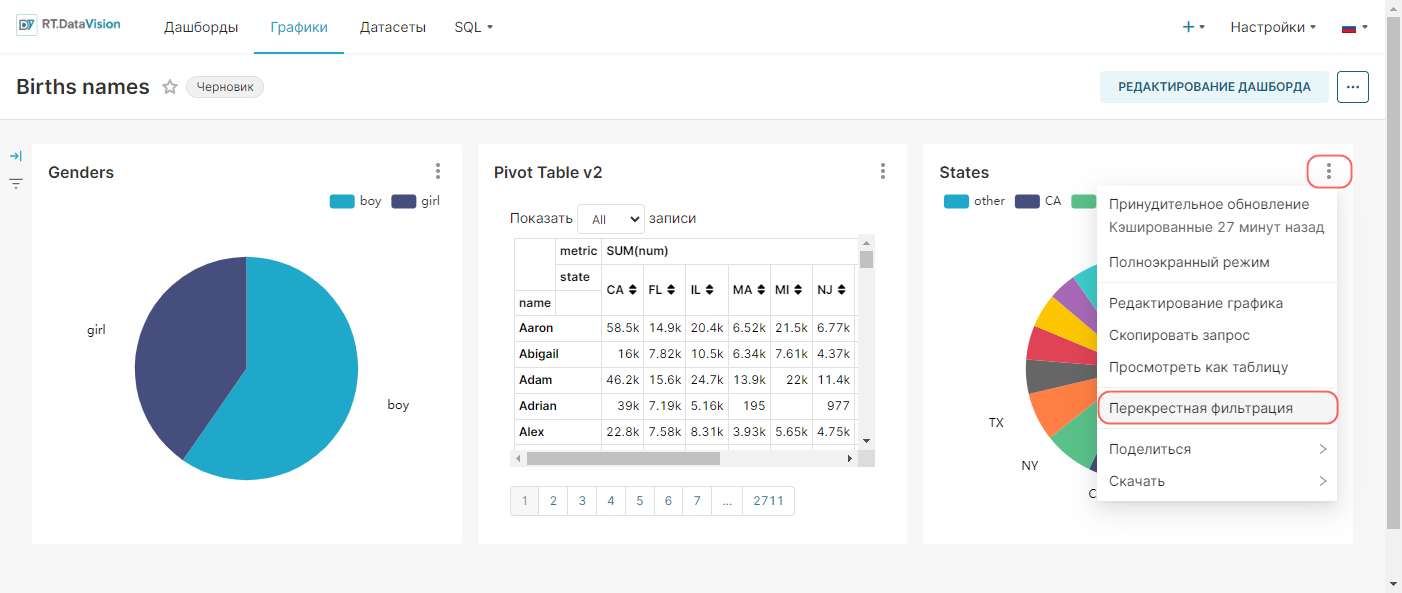
3. Настройте перекрестную фильтрацию в открывшемся окне. Выберите один из следующих вариантов:
- Применить ко всем панелям (Apply to all panels) – фильтрация будет применена ко всем графикам;
- Применить к выбранным панелям (Apply to specific panels) – фильтрация будет применена только к выбранным графикам. Оставьте отмеченными те графики, к которым должна быть применена перекрестная фильтрация.
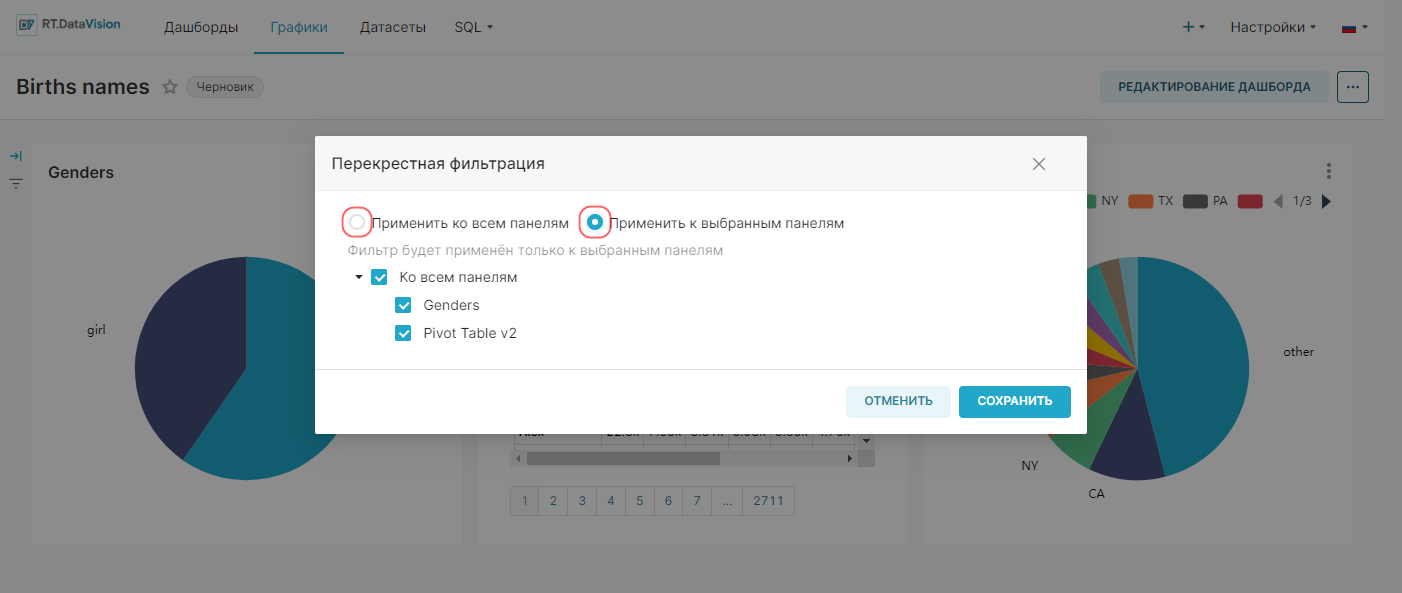
4. Сохраните изменения настройки графика с помощью кнопки Сохранить (Save).
Повторите этот процесс для любых других графиков, где необходимо использовать перекрестную фильтрацию.
¶ 7.10.4. Применение
Для демонстрации использования перекрестной фильтрации, можно выполнить пошаговое руководство, в котором будет применена фильтрация к трём графикам: одна Сводная таблица (Pivot Table) и два Круговых графика (Pie Chart).
В графиках используются данные датасета birth_names, сводная таблица Pivot Table v2 отображает количество зарегистрированных имён в разрезе регионов и имён, а круговые графики отображают общее количество регистраций имён по регионам (States) и в разрезе полов (Genders).
Перекрестная фильтрация включена для всех трёх графиков.
На круговом графике Genders, наведите курсор на сектор графика girl и выберите его.
Выбранный фильтр girl будет применён к двум другим графикам. Круговой график States и сводная таблица Pivot Table v2 будут обновлены, чтобы отразить применённый фильтр:
Добавьте дополнительный перекрестный фильтр, выбрав NY на круговом графике States:
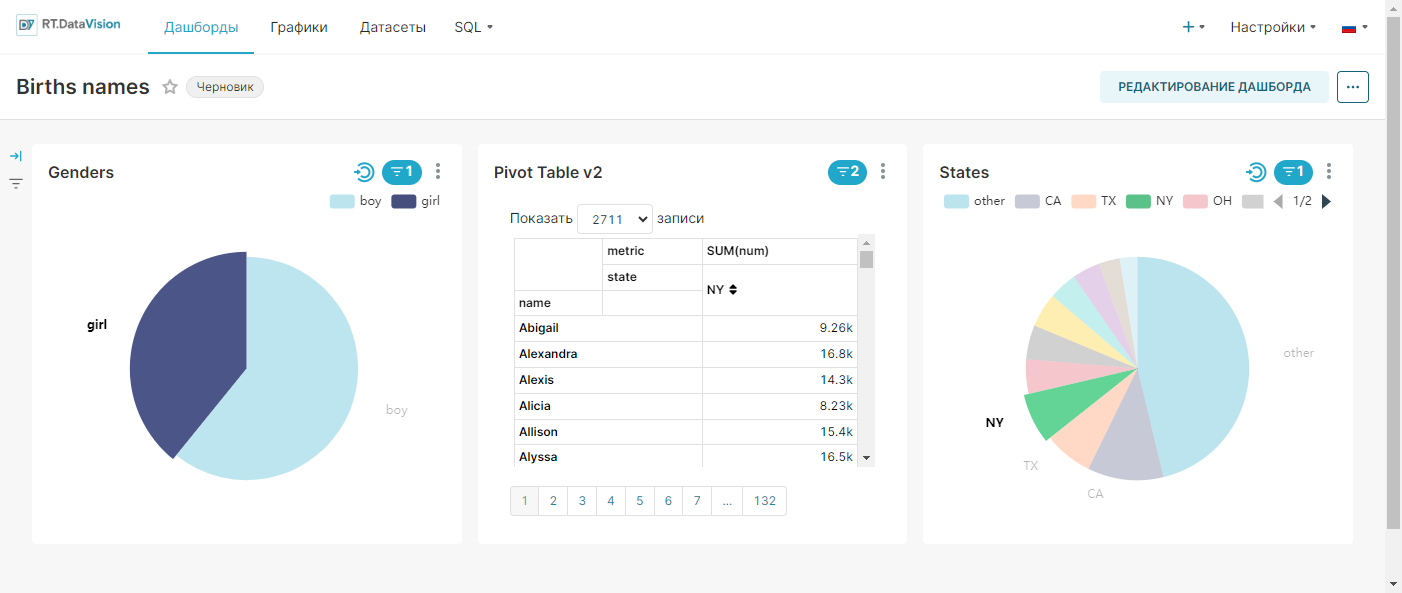
Оба фильтра — по одному из каждого кругового графика — применяются к сводной таблице. Теперь в сводной таблице показано количество зарегистрированных женских имён в выбранном регионе.
Применённые фильтры демонстрируется значком с маленькой цифрой “2”, который показывает количество фильтров, применяемых в настоящее время к графику.
¶ 7.10.5. Отключение кросс-фильтра для графика
Чтобы отключить перекрестную фильтрацию для графика, выберите круглый значок включения\выключения. При этом фильтр удаляется для всех графиков, к которым он был применён.
¶ 7.11. Управление фильтрами
¶ 7.11.1. Общая информация
В этом разделе описаны функции управления фильтрами, доступные в RT.DataVision.
Эти функции включают:
- Добавление фильтра и разделителя;
- Удаление фильтра;
- Просмотр применённых фильтров (через значок графика);
- Просмотр конфигурации и области действия фильтра;
- Очистка всех фильтров;
- Подсветка активного фильтра;
- Фильтр вне области действия;
- Скрытие боковой панели фильтрации.
¶ 7.11.2. Добавление фильтра и разделителя
В окне Добавление и редактирование фильтра (Add and edit filters) нажмите кнопку + Добавьте фильтры и разделители (+ Add filters and dividers) и выберите Фильтр (Filter). На панели Фильтры (Filters) появится новый фильтр с названием для заполнения [Без названия] ([untitled]).
Разделитель (Divider) — это текстовое поле, содержащее заголовок и необязательное описание, которое можно использовать для описания представленных на дашборде наборов фильтров или просто для разделения фильтров.
¶ 7.11.3. Удаление фильтра
Чтобы удалить фильтр, на панели Фильтры (Filters) выберите у необходимого фильтра значок корзины.
После нажатия на значок корзины RT.DataVision предложит отменить удаление фильтра. Для отмены удаления выберите Восстановление фильтра (Restore Filter). В противном фильтр будет удален. Также, для отмены удаления можно воспользоваться кнопкой Отменить? (Undo?).
Примечание. Функции Отменить? (Undo?) и Восстановление фильтра (Restore Filter) появляются на 5 секунд, после чего фильтр удаляется.
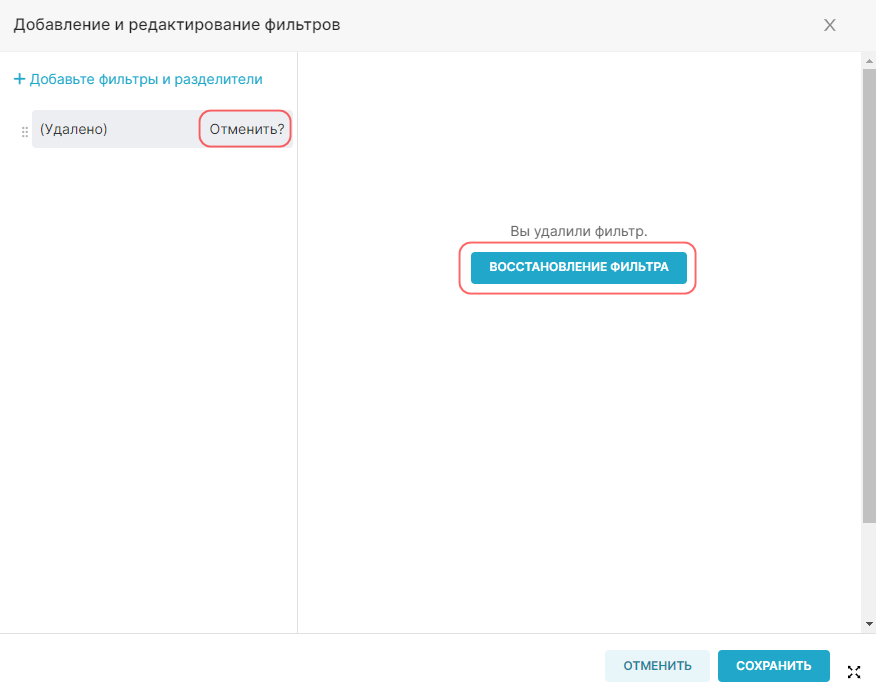
¶ 7.11.4. Просмотр применённых фильтров (через значок графика)
Для просмотра фильтров, которые были применены к определённому графику, можно выбрать значок фильтра на самом графике. Значок расположен в правом верхнем углу каждого графика и отображает число — это количество фильтров, которые были применены к этому графику.
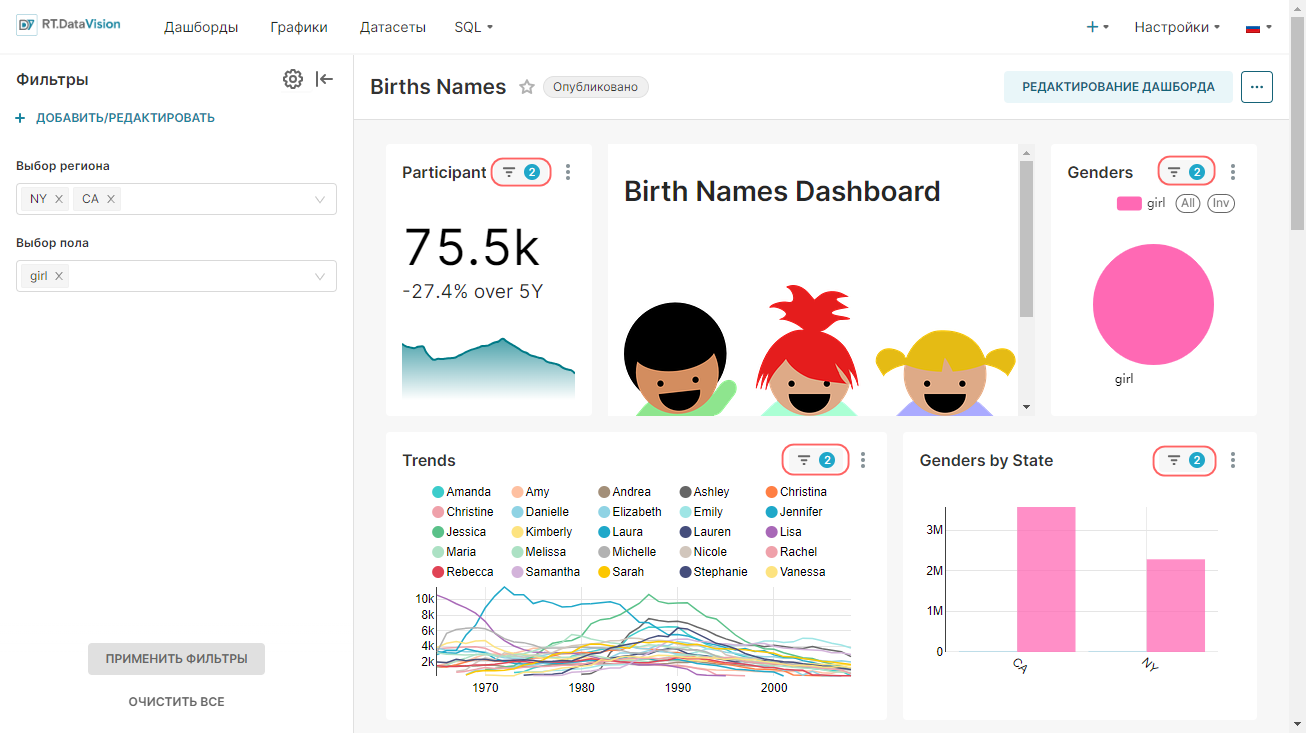
При выборе этого значка появляется всплывающая подсказка, отображающая применённые фильтры. На приведённом ниже рисунке были применены два фильтра Выбор региона и Выбор пола.
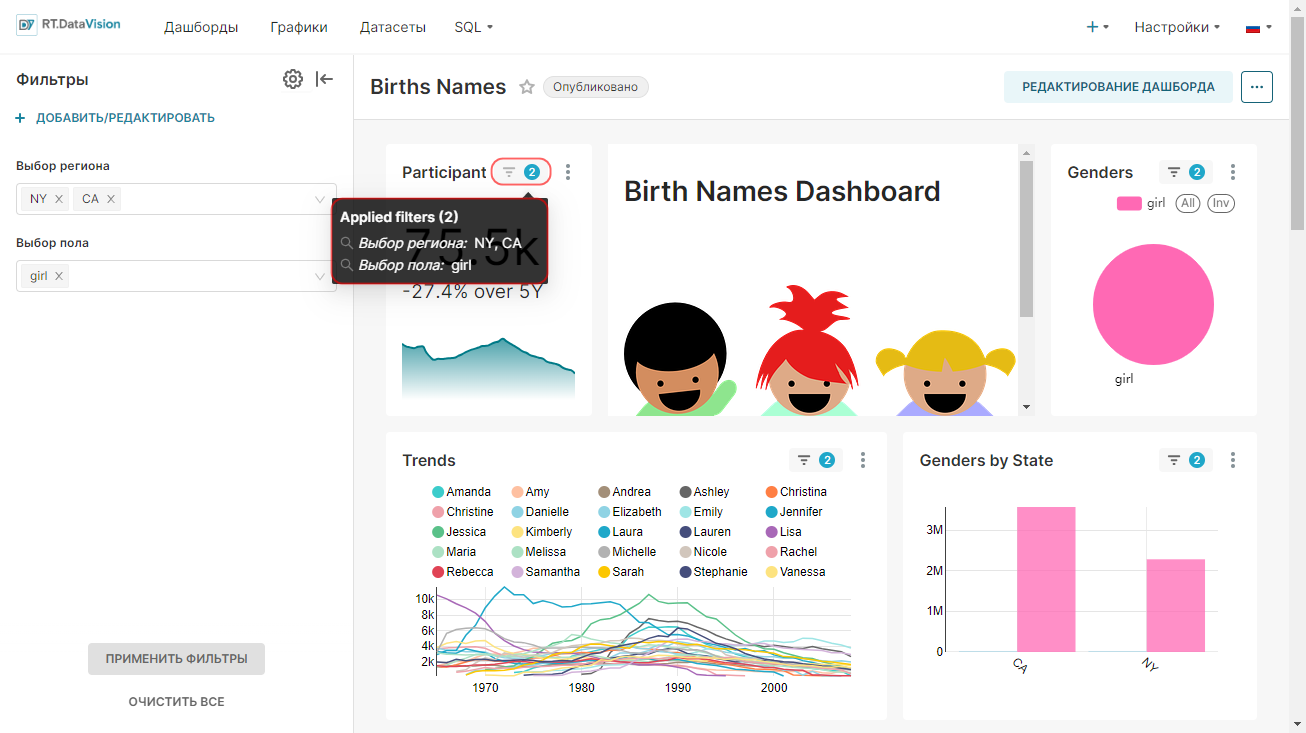
¶ 7.11.5. Просмотр конфигурации и области действия фильтра
Для просмотра информации о конфигурации фильтра и деталях области действия, необходимо навести курсор на наименование фильтра. Появится всплывающее окно с этими данными.
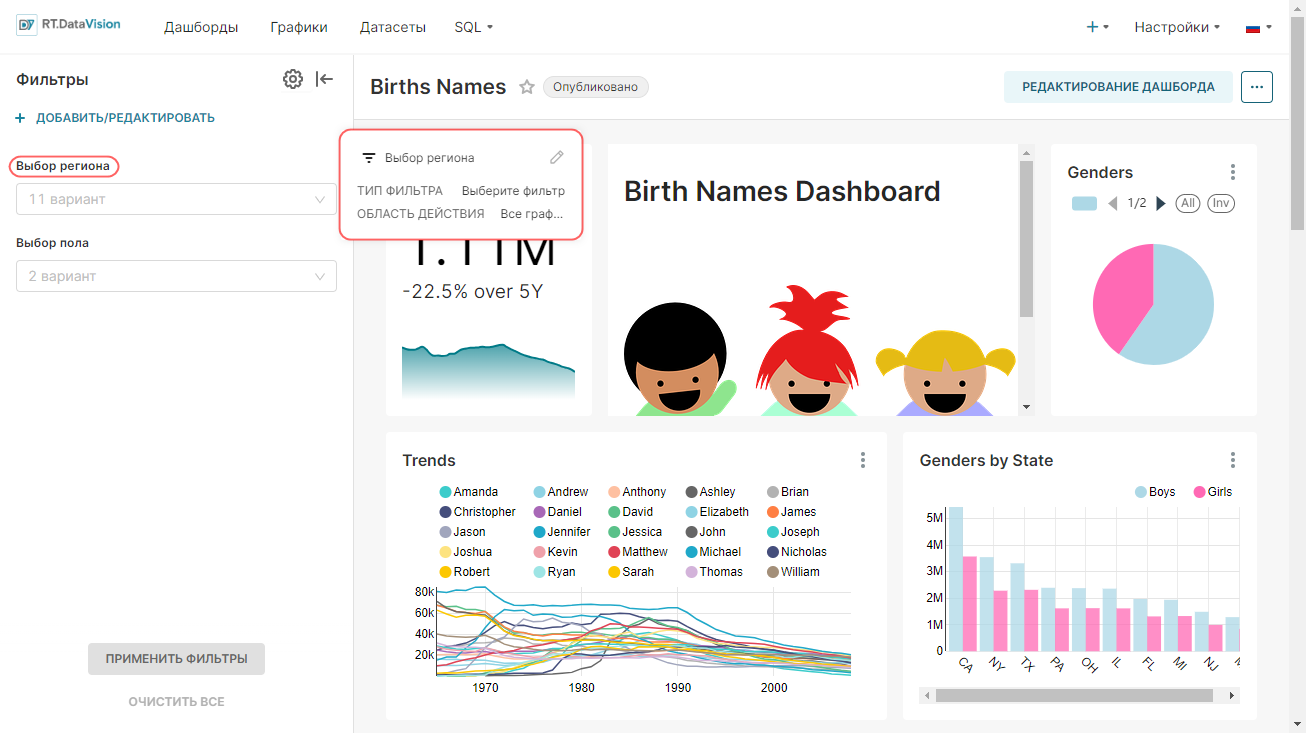
¶ 7.11.6. Очистка всех фильтров
При очистке всех фильтров удаляются выбранные значения фильтров, но не сами фильтры. Чтобы очистить все фильтры, на дашборде нажмите кнопку Очистить все (Clear All).
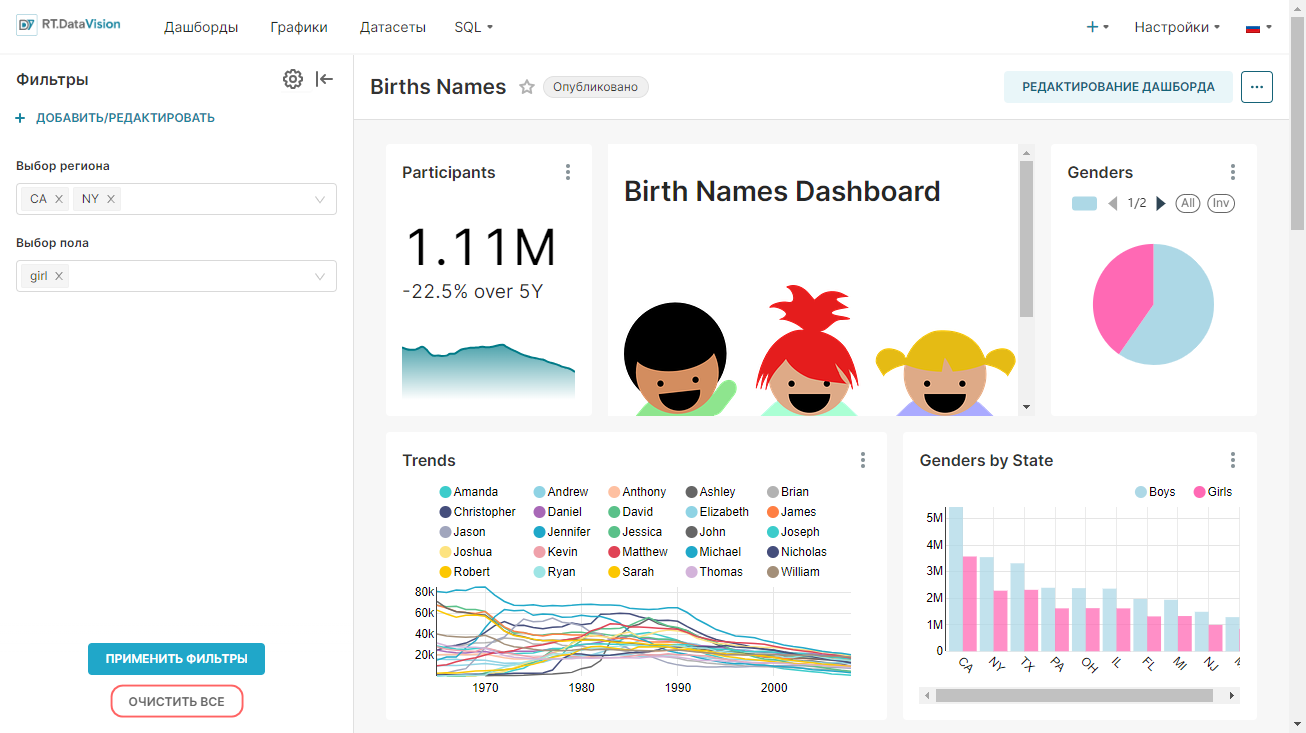
После очистки все выбранные значения в фильтрах удалятся.
Примечание. Кнопка Очистить все (Clear All) удаляет только выбранные значения в фильтрах, но не удаляет фильтры дашборда. Для удаления фильтра нажмите кнопку + Добавить/Редактировать (+ Add/Edit Filters) и в окне Добавление и редактирование фильтра (Add and edit filters) выберите значок корзины, соответствующий фильтру, который необходимо удалить.
¶ 7.11.7. Подсветка активного фильтра
Чтобы быстро сопоставить фильтры с графиками и вкладками, RT.DataVision автоматически применяет подсветку в виде синей рамки к графикам и вкладкам, которые включают данные из выбранного фильтра.
В качестве примера рассмотрим эту функцию на дашборде Births Names. Для проверки функции используем фильтр Выбор региона для фильтрации по регионам.
Ниже на рисунке дашборд без выбранного фильтра (т.е. курсор не наведён на фильтр) — обратите внимание, что синих светящихся рамок нет.
После перемещения курсора на раскрывающий список значений фильтра (или нажатия) графики и вкладки (при наличии) будут выделены светящейся синей рамкой:
¶ 7.11.8. Фильтр вне области действия
Если все данные из фильтра отображаются на вкладке, отличной от активной вкладки, то этот фильтр считается вне области действия и отображается в разделе Фильтры выходят за рамки (Filters out of scope).
В приведённом ниже примере есть два фильтра, данные которых представлены на Вкладке 1, а Вкладка 2 пустая.
При выборе Вкладки 2 появляется панель Фильтры выходят за рамки (Filters out of scope), содержащая фильтры с данными на неактивной Вкладке 1.
Раздел Фильтры выходят за рамки (Filters out of scope) является индикатором того, что отфильтрованные данные располагаются на других вкладках.
¶ 7.11.9. Скрытие боковой панели фильтрации
Видимость боковой панели Фильтр (Filter) можно изменять с помощью JSON Метаданные (JSON Metadata). Для изменения видимости:
1. Перейдите в режим редактирования на необходимом дашборде.
2. Нажмите на значок многоточия (…) в правом верхнем углу формы и выберите Редактирование свойств (Edit properties).
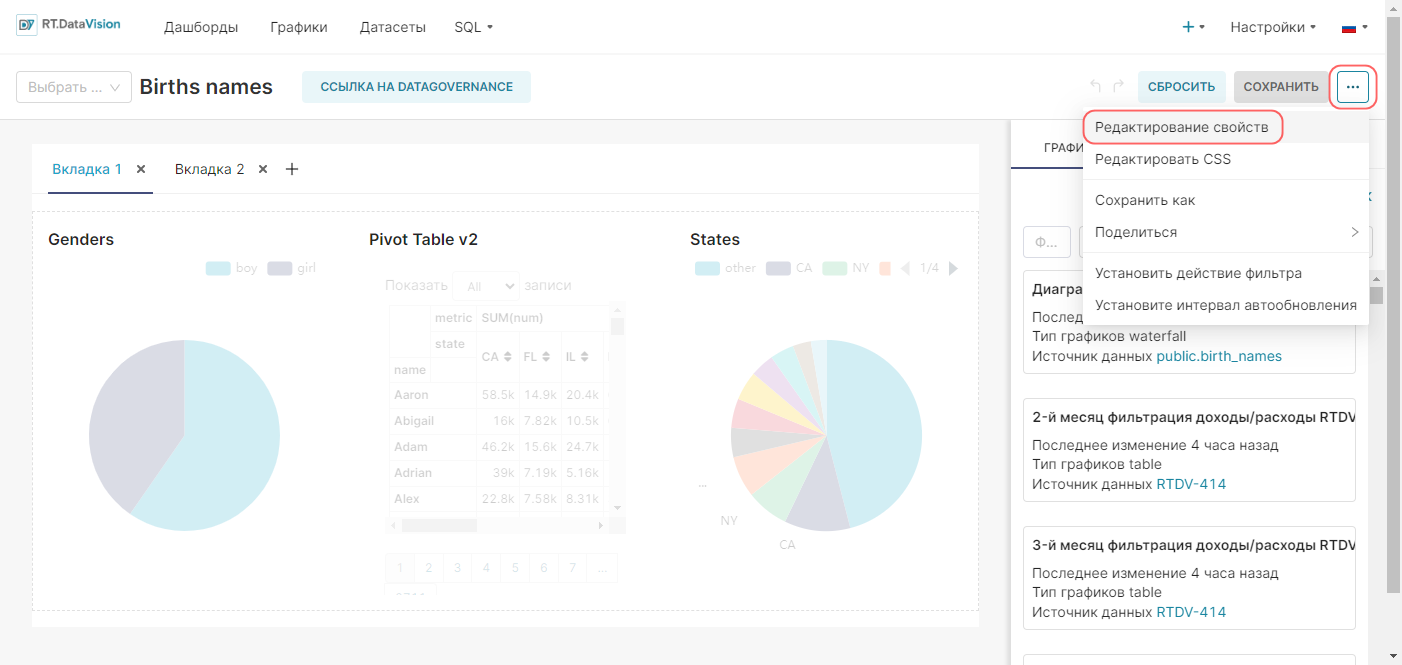
3. Разверните раздел Расширенные (Advanced) в открывшемся окне.
4. Найдите параметр show_native_filters в поле JSON Метаданные (JSON Metadata). Видимость фильтра регулирует этот параметр. По умолчанию установлено значение true. Изменение его на false скрывает боковую панель Фильтр (Filter).
5. Измените значение параметра и нажмите кнопку Применить (Apply).
6. Сохраните изменения на дашборде.
Видимость боковой панели Фильтр (Filter) на выбранном дашборде изменена.
¶ 8. Создание SQL-запросов и анализ данных
Раздел SQL — рабочее пространство, в котором пользователи могут анализировать данные и метаданных подключённых БД и строить к ним сложные SQL-запросы, а результаты выполнения запросов сразу использовать для построения графика или сохранить в виде датасета, таблицы или CSV. Сами запросы тоже могут быть сохранены, поддерживаться в актуальном состоянии и использоваться в дальнейшем.
Раздел SQL состоит из трёх компонентов:
- Лаборатория SQL (SQL Lab) — инструмент формирования и выполнения SQL-запросов для получения данных, на которых можно строить график.
- Сохранённые запросы (Saved Queries) — место хранения всех сохранённых запросов пользователя.
- История запросов (Query History) — лог формирования и выполнения исторических запросов пользователя.
Ключевые особенности раздела SQL включают:
- Формирование SQL-запросов к любым базам данных, к которым выполнено подключение в RT.DataVision.
- Просмотр метаданных БД: таблицы, столбцы, индексы и партиции.
- Одновременная работа с несколькими запросами на нескольких вкладках.
- Поддержка долго выполняющихся запросов.
- Наличие поискового движка для поиска исторических запросов.
- Поддержка создания шаблонов с использованием языка шаблонов Jinja, который позволяет использовать макросы в коде SQL.
Внимание. Для улучшения и корректности работы в Лаборатории SQL, должны или могут быть выполнены следующие настройки:
- Активируйте необходимые фича-флаги. Фича-флаги включают\выключают дополнительные функции работы Лаборатории SQL, такие как использование шаблонов Jinja, возможность полной выгрузки данных. Подробности см. в п. 1.11 Фича-флаги в Инструкции администратора.
- Для каждой подключённой БД установите необходимые расширенные настройки её взаимодействия с Лабораторией SQL. Подробнее см. в п. 10.4.2 Расширенные параметры Лаборатории SQL в Инструкции администратора.
- Чтобы избежать таймаута выполнения длительных запросов, настройте асинхронное выполнение запросов в Лаборатории SQL с помощью параметра конфигурации SQLLAB_ASYNC_TIME_LIMIT_SEC. Подробности см. в п. 6 Асинхронные запросы через Celery в Инструкции администратора.
- Для увеличения производительности системы настройте кэширование результатов запросов в Лаборатории SQL с помощью параметра конфигурации RESULTS_BACKEND. Подробности см. в п. 6 Асинхронные запросы через Celery в Инструкции администратора.
- Для валидации запросов в реальном времени настройте SQL-валидаторы. Подробности см. в последних абзацах п. 8.1 Шаблоны Jinja в Инструкции администратора.
- В случае использования шлюза или прокси-сервера (например, Nginx) настройте параметр конфигурации SUPERSET_WEBSERVER_TIMEOUT, который позволит избежать их таймаута. Подробности см. в п. 14.3 Почему таймаут запросов истёк? в Инструкции администратора.
Примечание. Лаборатория SQL (SQL Lab) спроектирована как открытая среда, позволяющая демократизировать запросы к данным без ограничений безопасности на уровне строк (RLS). Таким образом, по умолчанию правила RLS не применяются в Лаборатории SQL (SQL Lab).
Чтобы включить применение правил RLS в Лаборатории SQL, активируйте фича-флаг RLS_IN_SQLLAB. Подробнее о фича-флагах см. в п. 1.11 Фича-флаги в Инструкции администратора.
Либо вы можете выбрать, какие базы данных будут доступны в Лаборатории SQL, или предоставить пользователю ограниченный доступ к функциям с помощью ролей доступа к данным. Подробнее про предоставление доступа см. в п. 12 Безопасность и управление доступом в Инструкции администратора.
¶ 8.1 Лаборатория SQL
Лаборатория SQL (SQL Lab) позволяет формировать SQL-запрос к данным подключённых БД, а полученные результаты сохранять в форме датасета\таблицы\CSV или сразу использовать для построения графика. По сути Лаборатория SQL является инструментом подготовки, очистки, агрегации данных для дальнейшего успешного построения на них графиков.
Чтобы открыть Лабораторию SQL:
- На верхней панели инструментов выберите SQL > Лаборатория SQL (SQL Lab).
- Если вы находитесь на этапе построения графика, то можно вернуться на предыдущий этап формирования данных для графика и скорректировать запрос под новые потребности. Для этого на странице создания графика выберите (⋯) > Запуск в SQL Lab (Run in SQL Lab).
¶ 8.1.1 Интерфейс
Лаборатория SQL состоит из четырёх компонентов:
- Вкладки — внутри Лаборатории SQL можно открывать условное бесконечное число вкладок. Одна вкладка предназначена для одного запроса.
- Браузер таблиц — навигатор для выбора данных для запроса (БД > схема > таблица) и просмотра метаданных выбранной таблицы.
- Текстовый редактор — поле для написания запроса с дополнительными возможностями и панель управления запросом.
- Вьювер запросов — средство просмотра данных таблицы-источника и результатов выполнения запроса, а также панели управления этими данными.

¶ 8.1.1.1 Вкладки
Вы можете открыть несколько вкладок Лаборатории SQL (SQL Lab) и на каждой вкладке запустить отдельный запрос.
Контекстное меню вкладки ( ⋮ ) позволяет переименовать, дублировать или закрыть вкладку, скрыть Браузер таблиц, чтобы освободить больше места для Текстового редактора и Вьювера запросов.
Кнопка ➕, расположенная справа от всех вкладок, добавляет новую вкладку.

¶ 8.1.1.2 Браузер таблиц
Позволяет просмотреть подключённые базы данных, схемы и таблицы, которые они содержат.
Когда таблица выбрана, её метаданные (список столбцов и типы данных) отображаются ниже.
Кнопки управления отображением таблиц отображаются при наведении курсора на название таблицы и позволяют получить ключи и индексы таблицы, отсортировать столбцы в алфавитном порядке, скопировать в буфер обмена SQL-запрос, использованный для получения столбцов, свернуть или убрать информацию о метаданных таблицы.
Для принудительного обновления метаданных (схем и таблиц) подключённой БД у этих полей располагается кнопка 🔄.
При выборе таблицы её данные будут автоматически подгружены и размещены на вкладке Предварительный просмотр (Preview) во Вьювере запросов.
Внимание. Чтобы подключённая база данных была доступна для выбора в Лаборатории SQL (SQL Lab), необходимо проставить отметку в поле Раскрыть базу данных в SQL Lab (Expose database in SQL Lab) в настройках подключения БД (подробнее см. в п. 10.4.2 Расширенные параметры Лаборатории SQL в Инструкции администратора).

¶ 8.1.1.3 Текстовый редактор
Текстовый редактор — типичный редактор SQL с поддержкой Jinja. Вы пишете запрос и выполняете его, а результаты запроса отображаются ниже, во Вьювере запросов.
Текстовый редактор поддерживает обработку только одного запроса. Если вы внесёте несколько запросов, то будет выполнен только один, последний запрос. Для выполнения нескольких запросов, используйте вкладки (см. п. 8.1.1 Вкладки).
Поиск по запросу выводится сочетанием Ctrl-F. Для замены слов в запросе в окне запроса необходимо щёлкнуть значок + и ввести слово в поле Replace with.
Для создания нового параметра Jinja необходимо в Текстовом редакторе щёлкнуть (⋯) > Параметры (Parameters) и в окне определить параметры.
Параметры определяются как {"параметр"}: {"значение"}, где {{ параметр }} преобразуется в значение при использовании в запросе.
Существуют предопределённые параметры, которые доступны сразу, например:
- {{ current_user }} — возвращает имя пользователя, вошедшего в RT.DataVision.
- {{ current_user_id }} — идентификатор пользователя, который в данный момент выполнил вход в RT.DataVision.
Подробнее о работе с шаблонами Jinja см. в п. 4 Использование Jinja-шаблонов.

Управление работой с запросами осуществляется с помощью кнопок:
- Выполнить (Run) для запуска запроса. После запуска запрос сохраняется в Истории запросов (Query History).
- Выполнить (Run) > Создать таблицу как (Create Tabla As)\Создать представление как (Create View As) для сохранения результатов запроса в качестве физической таблицы\представления в подключённой БД.
- Limit для ограничения количества выводимых в результате выполнения запроса записей.
- Сохранить (Save) для сохранения запроса в Сохранённых запросах (Saved Queries).
- Сохранить (Save) > Save dataset для сохранения результатов выполнения запроса в качестве виртуального датасета и дальнейшего построения графика на его основе.
- Скопировать ссылку (Copy link) для предоставления общего доступа к запросу.
- (⋯) > Автозаполнение (Autocomplete). Включает\отключает предложения по ключевым словам SQL, объектам и функциям при создании запроса.
- (⋯) > Параметры (Parameters) позволяет использовать синтаксис шаблонов Jinja для назначения набора параметров в формате JSON.
¶ 8.1.1.4 Вьювер запросов
Вьювер запросов состоит из трёх частей, отображаемых в виде вкладок:
1. Результаты (Results) вашего текущего запроса, запущенного в Текстовом редакторе.
Результаты можно отфильтровать, указав в свободной форме значение фильтра в поле Результаты фильтрации (Filter Results). Данная фильтрация не влияет на сохранение результатов и их использование для построения графика. Она служит только для облегчения анализа результатов выполнения запросов.
Управлять результатами можно кнопками:
- Создать диаграмму (Create chart) позволяет сначала сохранить результат в качестве виртуального датасета, а затем открыть окно построения графика на сохранённом датасете.
- Скачать в CSV (Download to CSV) выгружает результат выполнения запроса в формате CSV.
- Полная выгрузка в CSV выгружает в формате CSV полные исходные данные таблицы, к которой обращается запрос.
- Скопировать в буфер обмена (Copy to clipboard) копирует результат запроса в формате JSON.

2. История запросов (Query history) позволяет просмотреть метаинформацию о недавно выполненных запросах в хронологическом порядке (основная информация, состояние (успешно\ошибка), время начала и продолжительность выполнения, прогресс (если всё ещё выполняется) и прочая).
Для каждого запроса доступны следующие функции:
- ✏️ помещает выбранный запрос в Текстовый редактор, очищая имеющийся запрос в редакторе.
- ➕ помещает на новую вкладку выбранный запрос и выполняет его.
- 🗑️ удаляет выбранный запрос из Истории запросов.

3. Предпросмотр (Preview) выводит данные таблицы, выбранной в Браузере таблиц.
Эта вкладка создаётся автоматически, когда выбирается таблица в Браузере таблиц. Вы можете выбрать несколько таблиц, для каждой будет создана вкладка Предпросмотр. Обратите внимание, что к выводу количества строк таблицы применяется лимит.
Данные таблицы можно отфильтровать, указав в свободной форме значение фильтра в поле Результаты фильтрации (Filter Results). Данная фильтрация не влияет на копирования данных в буфер обмена. Она служит только для облегчения анализа данных таблицы.
С помощью кнопки Скопировать в буфер обмена (Copy to clipboard) копирует данные исходной таблицы с применённым лимитом в формате JSON.

¶ 8.1.2 Ограничения Лаборатории SQL
При выполнении запросов в Лаборатории SQL, учитывайте следующие ограничения:
1. Если в Лаборатории SQL в Тестовом редакторе указаны несколько запросов, будет выполнен только один запрос и показан только его результат (последний запрос в списке).
2. Запрос может истечь, если он не вернул значения из базы данных (время ожидания по умолчанию составляет 6 часов) или если истекло время ожидания запроса веб-сервера.
3. Запросы ограничивают количество результирующих строк, извлекаемых из базы данных. Это потому что:
- Получение большого количества данных из базы данных — это затратно по ресурсам;
- Ограничение количества строк предотвращает длительные запросы к базе данных;
- Чтобы избежать случайного выбора SELECT * FROM для таблицы, состоящей из миллионов строк, что может привести к остановке базы данных.
4. Запрос может завершиться с ошибкой, если он ссылается на таблицу\столбец, которых уже нет в подключённой БД. Необходимо изменить запрос, например, удалить столбец из запроса.
5. Запрос даже не будет отправлен в базу данных, если в нём отсутствуют обязательные параметры. Вам следует определить все параметры, указанные в запросе, в валидном документе JSON.
¶ 8.1.3 Формирование и выполнение запроса
Чтобы сформировать и выполнить запрос, выполните:
1. Войдите в Лабораторию SQL и щёлкните ➕ справа от вкладок для создания новой вкладки. Или, находясь в Сохранённых запросах или Истории запросов, щёлкните + Запрос (+ Query) наверху справа (в этом случае сразу создастся новая вкладка).
2. В Браузере таблиц последовательно выберите подключённую БД, схему, а затем таблицу. Вы можете обновить метаданные БД, нажав кнопки 🔄 напротив полей выбора схемы и таблицы. Это обезопасит вас от формирования запроса к уже несуществующим данным.
При выборе таблицы, во Вьювере запросов будет создана новая вкладка Предпросмотр (Preview), содержащая исходные данные таблицы (с применённым лимитом вывода строк). Удостоверьтесь, что выбранная таблица содержит необходимые для запроса данные.
Внимание. Чтобы подключённая база данных была доступна для выбора в Лаборатории SQL (SQL Lab), необходимо проставить отметку в полях Раскрыть базу данных в SQL Lab (Expose database in SQL Lab) и Разрешите исследовать эту базу данных (Allow this database to be explored) в настройках подключения БД (подробнее см в п. 10.4.2 Расширенные параметры Лаборатории SQL в Инструкции администратора).
3. В Текстовом редакторе сформируйте запрос. Помните, что на одной вкладке можно сформировать только один запрос.
Внимание. Чтобы в Лаборатории SQL (SQL Lab) можно было использовать DML для управления подключённой БД с помощью операторов, отличных от SELECT, таких как UPDATE, DELETE и CREATE таблицы, необходимо проставить отметку в поле Разрешить DML (Allow DML) в настройках подключения БД (подробнее см в п. 10.4.2 Расширенные параметры Лаборатории SQL в Инструкции администратора).
Вы можете использовать Jinja-шаблоны в своём запросе. Подробнее см. в п. 4 Использование Jinja-шаблонов.
Внимание. Чтобы Jinja-шаблоны стали доступны для использования в запросе, активируйте фича-флаг ENABLE_TEMPLATE_PROCESSING. Подробнее о фича-флагах см. в п. 1.11 Фича-флаги в Инструкции администратора.
4. Выполните запрос, щёлкнув Выполнить (Run). Так вы сможете проверить корректность его выполнения, а также залогировать его в Истории запросов (и в случае утери запроса восстановить его).
Запросы, которые не были выполнены и\или сохранены, могут быть утеряны, т.к. они привязаны к текущей сессии браузера. Если текущая сессия была закрыта (истекло время жизни сессии, были удалены куки браузера), данные о невыполненном и\или несохранённом запросе пропадут.
5. Если запрос выполнен успешно, то во Вьювере запросов на вкладке Результаты (Results) появятся данные, сформированные по результату выполнения запроса. Проверьте их на соответствие своим ожиданиям.
Дайте название успешно выполненному запросу: на вкладке запроса нажмите ( ⋮ ) > Переименовать вкладку (Rename Tab), а в открывшемся окне внесите название и нажмите Ok.

6. Далее вы можете выполнить следующие действия с полученными результатами запроса:
- Создать график на результатах запроса — вы сохраните результаты выполнения запроса как виртуальный датасет и сразу перейдёте к созданию графика. Подробности см. в п. 8.1.4 Создание графика на результатах запроса.
- Сохранить результаты в качестве виртуального датасета — вы сможете сохранить результат выполнения запроса в качестве нового виртуального датасета или перезаписать уже имеющийся и вернуться к построению графика позже. Виртуальный датасет будет сохранён в разделе Датасеты (Datasets). Подробности см. в п. 8.1.5 Сохранение результата запроса как датасет.
- Сохранить результаты как таблицу\представление в БД — если запрос является сложным, то рациональней его результаты сохранить в качестве новой таблицы\представления в БД, а затем сформировать запрос к ней. Подробности см. в п. 8.1.6 Сохранение результата запроса как таблица\представление.
- Сохранить результаты на ПК в формате CSV — если вы хотите дополнительно сохранить результат к себе на ПК, либо использовали RT.DataVision как средство для получения данных из необходимой БД для рабочих задач. Подробности см. в п. 8.1.7 Сохранение результата запроса в формате CSV.
¶ 8.1.4 Создание графика на результатах запроса
После формирования и выполнения запроса вы можете сразу приступить к построению графика на его результатах. Для этого выполните:
1. Во Вьювере запросов на вкладке Результаты (Results) нажмите кнопку Создать диаграмму (Create chart).
2. Откроется окно Сохранить или перезаписать датасет (Save or Overwrite Dataset):
- Если вы хотите сохранить результат выполнения запроса в качестве нового виртуального датасета, выберите опцию Сохранить как новый (Save as New), в текстовом поле рядом укажите название датасета.
- Если вы хотите обновить уже существующий виртуальный датасет полученным результатом выполнения запроса, выберите Перезаписать существующий (Overwrite Existing) и из выпадающего списка рядом выберите перезаписываемый датасет.
Нажмите Сохранить и исследовать (Save & Explore) или Перезаписать и исследовать (Overwrite & Explore) в зависимости от выбранной опции. Датасет будет сохранён\переписан. Вы можете найти его в разделе Датасеты (Datasets).
Примечание. Вы можете дополнительно настроить семантический слой для сохранённого\перезаписанного виртуального датасета. Подробнее см. в п. 5.4 Настройка семантического слоя.

3. Откроется окно создания графика. В качестве данных, на которых предполагается строить график, будет выбран сохранённый\перезаписанный датасет.
Подробнее о построении графиков см. п. 6 Создание графиков, а информацию о типах визуализации см. в п. 7 Типы визуализации графиков.

¶ 8.1.5 Сохранение результата запроса как датасет
Следует помнить, что графики в RT.DataVision корректно создавать на основе датасета. Поэтому сохранение результата запроса в виде виртуального датасета является логичным действием. Кроме того вы можете трансформировать датасет (например, изменить типы данных, преобразовать формат дат и пр.) и более точно его настроить для получения данных для графика (добавить виртуальные метрики и виртуальные расчётные столбцы, как описано в п. 5.4 Настройка семантического слоя).
Чтобы сохранить сформированный запрос в качестве виртуального датасета, выполните:
1. В Текстовом редакторе нажмите значок 🔽 у кнопки Сохранить (Save), а затем щёлкните отобразившуюся Save Dataset.
2. Отобразится окно для настройки сохранения. Выберите один из вариантов:
- Сохранить как новый (Save as New). Если вы сформировали запрос впервые для графика, то сохраните его результат в новом датасете. В текстовом поле укажите название датасета, затем нажмите Сохранить и исследовать (Save & Explore).
- Перезаписать существующий (Overwrite Existing). Если вы внесли изменения уже в существующий датасет и не хотите сохранять его предыдущую версию, то перезапишите его. В выпадающем списке рядом выберите перезаписываемый датасет. Затем нажмите Перезаписать и исследовать (Overwrite & Explore).
3. Результат запроса будет сохранён как виртуальный датасет и сразу будет открыт в окне создания графика. Датасет вы можете найти, щёлкнув на верхней панели Датасеты (Datasets) и найдя его в отобразившемся списке.
¶ 8.1.6 Сохранение результата запроса как таблица\представление
Функции CREATE TABLE AS (CTAS)\CREATE VIEW AS (CVAS) позволяет создать новую таблицу\представление на основе SQL-запроса. Материализацию SQL-запроса в таблицу стоит использовать при сложных запросах (много JOIN и агрегаций), которые снижают производительность RT.DataVision. Таблица\представление будет сохранена в той же схеме подключённой БД, в которой хранятся данные, используемые для запроса.
Затем необходимо обращаться к созданной таблице\представлению с запросом, и уже этот результат сохранить в качестве датасета и строить на его данных график.
Внимание. Чтобы использовать эту функцию, её необходимо включить на уровне подключённой БД:
- Перейдите в список подключённых БД. Он находится здесь: Настройки (Settings) > Database Connections.
- Найдите нужную БД и откройте её в режиме редактирования с помощью значка ✏️.
- Откроется окно редактирования БД. Перейдите на вкладку Расширенные (Advanced), затем разверните группу параметров Лаборатория SQL (SQL Lab).
- Проставьте флажки у параметров Раскрыть базу данных в SQL Lab (Expose database in SQL Lab), Разрешить CREATE TABLE AS (Allow CREATE TABLE AS) и Разрешить CREATE TABLE AS (Allow CREATE VIEW AS), а затем сохраните изменения, щёлкнув Сохранить (Save).
- После выполненной настройки в Редакторе SQL появятся кнопки Создать таблицу как (Create Table As) и Создать представления как (Create View As) (они отображаются, если щёлкнуть значок 🔽 у кнопки Сохранить (Save).
Внимание. Поскольку CREATE TABLE принадлежит к категории SQL DDL. В частности, в PostgreSQL DDL является транзакционным. Это означает, что для правильного использования этой функции вам необходимо установить для параметра autocommit значение true в параметрах вашего движка. Для этого выполните:
- Откройте список подключённых БД, который находится по пути: Настройки (Settings) > Database Connections.
- Настраиваемую базу данных откройте в режиме редактирования, щёлкнув значок ✏️.
- В открывшемся окне выберите вкладку Расширенные (Advanced) и разверните группу Другое (Other).
- В поле параметра Параметры движка (Engine Parameters) укажите следующее и затем нажмите Финиш (Finish) для сохранения настройки.
{ ... "engine_params": {"isolation_level":"AUTOCOMMIT"}, ... }
Чтобы сохранить результат запроса в качестве таблицы\представления, выполните:
- В Текстовом редакторе нажмите значок 🔽 у кнопки Сохранить (Save), а затем щёлкните отобразившуюся кнопку Создать таблицу как (Create Table As) или Создать представление как (Create View As).
- В отобразившемся окне укажите имя создаваемой таблицы и выберите Сохранить (Save). Теперь вы можете сформировать запрос к созданной таблице\представлению без снижения производительности системы.

¶ 8.1.7 Сохранение результата запроса в формате CSV
Если вам необходимо для рабочих задач произвести выгрузку результата запроса в формате CSV на свой ПК, выполните:
- Во Вьювере запросов на вкладке Результаты (Results) нажмите Скачать в CSV (Download to CSV).
- Результат запроса будет сохранён на ПК в формате CSV.
¶ 8.1.8 Копирование результата запроса в буфер обмена
Чтобы скопировать результат запроса в буфер обмена для последующего его использования в месте, отличном от RT.DataVision, выполните:
- Во Вьювере запросов на вкладке Результаты (Results) нажмите
¶ 8.1.9 Сохранение кода запроса в Сохранённых запросах
Чтобы не потерять запрос, сохраните его код в Сохранённых запросах. Для этого:
- Щёлкните Сохранить (Save) в Текстовом редакторе.
- В открывшемся окне укажите название запроса и опционально описание, затем щёлкните Сохранить (Save).
- Запрос будет сохранён. Его вы можете найти в разделе Сохранённые запросы (Saved Queries). Подробнее о сохранённых запросах см. в п. 8.2 Сохранённые запросы.
¶ 8.1.10 Сохранение кода запроса в Истории запросов
Чтобы сохранить код сформированного запроса в Истории запросов, выполните:
- После формирования запроса нажмите Выполнить (Run) в Текстовом редакторе.
- Выполненный код запроса будет сохранён в разделе История запросов (Query History). Каждое выполнение запроса создаёт новую запись в Истории запросов. Подробнее об истории запросов см. в п. 8.3 История запросов.
¶ 8.1.11 Полная выгрузка данных исходной таблицы
Внимание. Чтобы полная выгрузка стала доступна, активируйте фича-флаг ALLOW_FULL_CSV_EXPORT. Подробнее о фича-флагах см. в п. 1.11 Фича-флаги в Инструкции администратора.
Если вы хотите сохранить все записи таблицы, к которой сформирован запрос, в формате CSV на свой ПК, выполните:
- Во Вьювере запросов на вкладке Результаты (Results) нажмите Полная выгрузка в CSV.
- Спустя время на ПК будут выгружены все записи таблицы, к которой обращается запрос.
¶ 8.1.12 Использование шаблонов Jinja
Внимание. Чтобы шаблоны Jinja стали доступны для использования в Лаборатории SQL, активируйте фича-флаг ENABLE_TEMPLATE_PROCESSING. Подробнее о фича-флагах см. в п. 1.11 Фича-флаги в Инструкции администратора.
Шаблоны Jinja позволяют использовать python-код в запросах в Лаборатории SQL. Подробности работы с шаблонами см. в п. 4 Использование Jinja-шаблонов.
Чтобы назначить параметры в формате JSON с использованием шаблонов Jinja, выполните:
- В Текстовом редакторе щёлкните (⋯) > Параметры (Parameters).
- Откроется окно. Внесите параметры и нажмите Сохранить (Save).

¶ 8.2 Сохранённые запросы
SQL-запросы, сохранённые в Лаборатории SQL (SQL Lab), появятся в разделе SQL > Сохранённые запросы (Saved Queries). Сохранённые запросы видны только владельцу запроса, но ими можно поделиться с помощью URL-адреса для совместной работы с другими участниками команды.
Вы можете управлять сохранёнными запросами: просматривать, редактировать, удалять точечно и массово, делиться ими для совместной работы, экспортировать.
Чтобы открыть список сохранённых запросов:
- На верхней панели инструментов выберите SQL > Сохранённые запросы (Saved Queries).
- Откроется список сохранённых запросов, который имеет представление таблицы со следующими полями:
- Имя (Name) сохранённого запроса.
- База данных (Database), связанная с запросом.
- Схема (Schema), связанная с запросом [опционально].
- Таблицы (Tables) — таблица или датасет, связанные с запросом.
- Дата создания (Created On) — как давно был создан запрос.
- Последнее изменение (Modified) — сколько времени прошло с момента последнего изменения.
- Действия (Actions) — список доступных действий с запросом:
- Значок предпросмотра 👓. Открывает окно предпросмотра запроса.
- Значок редактирования ✏️. Открывает запрос в Лаборатории SQL для внесения корректировок.
- Значок копирования 📋. Копирует URL запроса, чтобы вы могли поделиться им с коллегами.
- Значок экспорта ⬆️. Сохраняет на ПК ZIP-архив с запросом.
- Значок удаления 🗑️. Удаляет запрос из Сохранённых.
Чтобы сузить сохранённые запросы, вы можете использовать фильтры База данных (Database) и\или Схема (Schema). Кроме того, сохранённые запросы можно искать с помощью поля Поиск (Search). А по графам таблицы можно отсортировать список запросов.

¶ 8.2.1 Открытие Лаборатории SQL
Из раздела Сохранённые запросы вы можете сразу открыть Лабораторию SQL и приступить к формированию запроса. Для этого выполните:
- Выберите + Запрос (+ Query).
- Появится страница Лаборатории SQL с новой пустой вкладкой без названия. Подробнее о работе в Лаборатории SQL см. в п. 8.1 Лаборатория SQL.
- Чтобы сохранить созданный запрос в Сохранённые запросы, см. п. 8.1.9 Сохранение кода запроса в Сохранённых запросах.
¶ 8.2.2 Предпросмотр запроса
Чтобы вывести на экран окно предпросмотра сохранённого запроса:
- Выберите значок бинокля 👓.
- Появится окно предварительного просмотра запроса. В окне предпросмотра доступны следующие функции:
- Значок копирования 📋. Этот значок появляется при наведении курсора на текст запроса. Щёлкните значок, чтобы скопировать текст запроса в буфер обмена.
- Предыдущий (Previous). Просмотр предыдущего сохранённого запроса из списка сохранённых.
- Следующий (Next). Просмотр следующего сохранённого запроса из списка сохранённых.
- Открыть в SQL Lab (Open in SQL Lab). Запускает сохранённый запрос в Лаборатории SQL.

¶ 8.2.3 Редактирование запроса
Чтобы отредактировать сохранённый запрос:
- Выберите значок карандаша ✏️.
- Сохранённый запрос будет запущен в Лаборатории SQL для редактирования. Подробнее о работе в Лаборатории SQL см. в п. 8.1 Лаборатория SQL.
- Закончив внесение изменений, в Текстовом редакторе выберите Сохранить (Save). Или воспользуйтесь альтернативными способами сохранения запроса (см. последние абзацы в п. 8.1.3 Формирование и выполнение запроса).
¶ 8.2.4 Совместная работа над запросом
Сохранённые запросы видны только владельцу. Чтобы поделиться сохранённым запросом:
- Выберите значок копирования URL запроса 📋.
- В правом нижнем углу появится уведомление с подтверждением копирования URL-адреса. Этот URL-адрес запускает Лабораторию SQL с сохранённым запросом.
Общий сохранённый запрос может быть изменён и сохранён любым, у кого есть его URL-адрес. Но сохранится такой запрос в Сохранённых запросах только у владельца.
¶ 8.2.5 Экспорт запроса
Чтобы экспортировать сохранённый запрос:
- Выберите значок ⬆️.
- Запрос будет сохранён на ПК в формате ZIP-архива.
¶ 8.2.6 Удаление сохранённого запроса
Чтобы удалить запрос из Сохранённых запросов:
- Выберите значок 🗑️.
- Появится панель Удалить запрос? (Delete Query?). Для подтверждения введите УДАЛИТЬ в поле ввода текста и выберите Удалить (Delete).
¶ 8.2.7 Массовые действия
Инструмент Групповой выбор (Bulk Select) позволяет удалять или экспортировать несколько сохранённых запросов.
- Выберите Групповой выбор (Bulk Select).
- Установите флажки для каждого удаляемого\экспортируемого запроса или, чтобы выбрать все запросы, установите флажок в столбце заголовка.
- Чтобы массово удалить запросы, щёлкните Удалить (Delete), а в окне подтверждения введите УДАЛИТЬ в поле ввода текста и выберите Удалить (Delete). Чтобы массово экспортировать выбранные запросы на ПК, нажмите Экспорт (Export): сохранённые запросы будут заархивированы в формате ZIP, и начнётся загрузка на ПК.

¶ 8.3 История запросов
Все запросы, выполненные в Лаборатории SQL, хранятся в разделе SQL > История запросов (Query History).
В Истории запросов логируется выполнение всех запросов пользователя, как принудительно сохранённых, так и не сохранённых. Т.е. если вы разыскиваете запрос, который забыли сохранить, он точно будет здесь (при условии что вы запускали запрос).
Из Истории запросов вы можете управлять историческими запросами: найти необходимый запрос, просмотреть детали выполнения запроса, запустить запрос.
Чтобы перейти к Истории запросов:
- На верхней панели инструментов выберите SQL > История запросов (Query History).
- Откроется История запросов, которая имеет представление таблицы со следующими полями:
- Время (Time) — дата и время выполнения SQL-запроса.
- Имя таблицы (Tab Name) — имя вкладки SQL-запроса, если оно определено.
- База данных (Database), связанная с запросом.
- Схема (Schema) , связанная с запросом.
- Таблицы (Tables), связанные с запросом.
- Пользователь (User), создавший и запустивший запрос.
- Строки (Rows) — количество строк, созданных в результате выполнения запроса.
- SQL — начальные строки SQL запроса. Щёлкните, чтобы просмотреть весь запрос.
- Действия (Actions) — щёлкните на значок ↗️, чтобы запустить запрос в Лаборатории SQL.
Чтобы найти нужный исторический запрос, вы можете использовать фильтры:
- База данных (Database), связанная с искомым запросом.
- Состояние (State) выполнения запроса. Возможные значений: Failed (запрос был выполнен с ошибкой) или Success (запрос был успешно выполнен).
- Пользователь (User), создавший запрос.
- Период времени (Time Range) — необходимо установить Start Date (начальная дата) и End Date (конечная дата), будут отображаться запросы, выполненные в этом интервале.
Кроме того, исторические запросы можно искать с помощью поля Поиск по тексту запроса (Search). А по графам таблицы можно отсортировать список запросов.

¶ 8.3.1 Просмотр кода запроса
Чтобы просмотреть код исторического запроса:
- Щёлкните у запроса текстовое поле в графе SQL.
- Появится окно предварительного просмотра запроса. Окно содержит два запроса: Пользовательский запрос (User Query) (запрос, заданный пользователем) и Выполненный запрос (Executed Query) (фактически выполненный запрос).
В окне предпросмотра доступны следующие функции:
- Значок копирования 📋. Этот значок появляется при наведении курсора на текст запроса. Щёлкните значок, чтобы скопировать текст выбранного вида (пользовательского или выполненного) запроса в буфер обмена.
- Предыдущий (Previous). Просмотр предыдущего исторического запроса из списка запросов.
- Следующий (Next). Просмотр следующего исторического запроса из списка запросов.
- Открыть в SQL Lab (Open in SQL Lab). Запускает выбранный вид запроса в Лаборатории SQL.

¶ 8.3.2 Открытие запроса в Лаборатории SQL
Чтобы открыть исторический запрос в Лаборатории SQL (SQL Lab):
- Щёлкните значок ↗️ у запроса в графе Действия (Actions).
- Запрос будет скопирован на новую вкладку в Лаборатории SQL. При копировании запрос выполнен не будет, чтобы пользователь сразу мог приступить к корректировке исторического запроса, не дожидаясь окончания его выполнения.
¶ 9. Использование Jinja-шаблонов для фильтрации данных
Рассмотрим пример использования шаблонов Jinja в RT DataVision для фильтрации данных. Для этого будем использовать таблицу video_game_sales из БД examples. Задача: отобразить жанры и количество видеоигр на выбранных платформах. Для получения этих данных составим следующий запрос:
WITH calculation as (
SELECT count(*), genre
FROM "video_game_sales"
WHERE platform in ('PS3', 'PS4')
GROUP BY genre
)
SELECT * FROM calculationПри создании виртуального датасета с помощью этого запроса результатом будет только два столбца — count и genre. В этом случае создать фильтр platform, без использования шаблона Jinja, не получится. Но при добавлении в запрос шаблона Jinja и выполнении его в Лаборатории SQL никакого результата не будет, поскольку нет фильтров для передачи значений. Выполненный запрос в итоге будет выглядеть следующим образом:
WITH calculation as (
SELECT count(*), genre
FROM "video_game_sales"
WHERE platform in ('')
GROUP BY genre
)
SELECT * FROM calculationДля решения данной проблемы (возможности создания фильтра по platform) необходимо:
- Шаг 1. Создать датасет с SQL-запросом без шаблона Jinja;
- Шаг 2. Изменить созданный датасет, включив в него шаблон Jinja;
- Шаг 3. Добавить график в дашборд;
- Шаг 4. Настроить требуемый фильтр.
¶ Шаг 1. Создание датасета
Для создания датасета:
- Перейдите в SQL → Лаборатория SQL.
- Выберите базу данных, схему и таблицу.

3. Для создания нового датасета используйте SQL-запрос со значением для platform:
WITH calculation as (
SELECT count(*), genre
FROM "video_game_sales"
WHERE platform in ('PS4')
GROUP BY genre
)
SELECT * FROM calculation4. Нажмите Выполнить, а затем Сохранить датасет. Появится окно Сохранить или перезаписать датасет.

5. Назовите новый датасет “Фильтрация с помощью Jinja” и нажмите Сохранить и исследовать.
После создания датасета откроется вкладка создания графика.
¶ Шаг 2. Включение шаблона Jinja в датасет
Для включения шаблона Jinja в созданный датасет:
- На вкладке создания графика откройте форму редактирования датасета.

2. Разблокируйте возможность внесения изменений.

3. В разделе SQL замените platform in ('PS4') на:
platform in ({{ "'" + "', '".join(filter_values('platform')) + "'" }}) 4. Нажмите кнопку Сохранить.
После сохранения изменений в датасете и обновлении графика отобразится сообщение "По этому запросу не было получено результатов". Это ожидаемо, так как график еще не настроен.

Структура данного шаблона Jinja:
- Начало — {{ "'" + "', '".join( и конец ) + "'" }} — отвечают за объединение. Эта структура позволяет фильтровать несколько значений.
- filter_values('Column-Name') — это функция, которая будет искать значение фильтра. Column-Name, в данном случае, это platform.
¶ Шаг 3. Добавление графика в дашборд
Для добавления графика в дашборд:
1. Нажмите кнопку Сохранить.
2. Нажмите кнопку Сохранить и перейти к новому дашборду в окне сохранения графика.

¶ Шаг 4. Настройка фильтра
Для настройки фильтра:
- Нажмите кнопку + ДОБАВИТЬ/РЕДАКТИРОВАТЬ в разделе Фильтры. Откроется окно добавления и редактирования фильтров.
- Заполните следующие поля:
Имя фильтра – введите имя фильтра. В этом примере был создан фильтр, который отображает платформы для видео игр, поэтому указано название Платформа.
Датасет – необходимо выбрать фактический источник данных для внутреннего запроса — video_game_sales.
Столбец – выберите значение platform. Именно оно определяет имя столбца в шаблоне Jinja. - Перейдите на вкладку Обзор и убедитесь, что фильтр сопоставлен с графиком.
- Нажмите кнопку Сохранить .

Для проверки работы фильтра Платформа выбираем платформы PC, PS4 и XOne и нажимаем Применить фильтры. График отобразит жанры и количество видеоигр доступных только на выбранных платформах.

Для просмотра внутреннего запроса нажмите на значок вертикального многоточия на графике, и выберите Скопировать запрос.

Теперь запрос обновляется, и включает значения фильтра Platform.